This page describes how service accounts are used in Cloud Data Fusion. For more information, see Use service accounts.
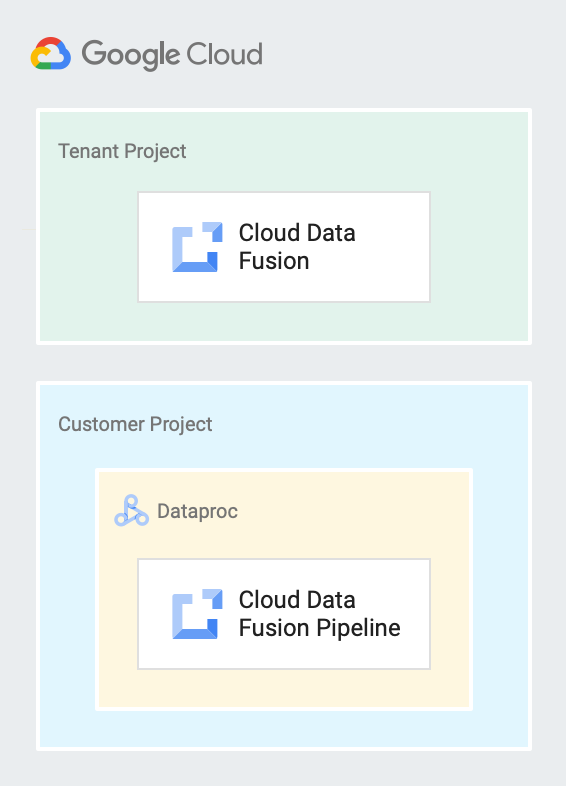
Tenant and customer projects
Cloud Data Fusion sets up service accounts to access resources in the following projects:
- Tenant project
Cloud Data Fusion creates a tenant project to hold the resources and services it needs to manage pipelines on your behalf. For example: running pipelines on your Dataproc clusters that reside in your customer project. A tenant project is not exposed to you, but when you create a private instance, you might need to use the tenant project name to set up VPC peering.
For more information, see the Service Infrastructure documentation about tenant projects.
- Customer project
You create and own this project. By default, Cloud Data Fusion creates an ephemeral Dataproc cluster in this project to run the your pipelines.
The following diagram shows a Cloud Data Fusion instance running in a tenant project and a pipeline running on a Dataproc cluster in a customer project.
Service accounts in Cloud Data Fusion
A service account provides an identity for Cloud Data Fusion, which gives Cloud Data Fusion access to your resources.
When you enable the Cloud Data Fusion API and create a Cloud Data Fusion instance, a service account is added to your project to access resources like Service Networking, Dataproc, Cloud Storage, BigQuery, Spanner, and Bigtable. This service account is called the Cloud Data Fusion API Service Agent. Roles are automatically granted to this service agent.
A service account is identified by its email address, which is unique to the account.
The following types of service accounts are used in Cloud Data Fusion. For more information, see Types of service accounts.
| Service account | Description |
|---|---|
service-CUSTOMER_PROJECT_NUMBER@gcp-sa-
datafusion.iam.gserviceaccount.com |
The service agent, called the Cloud Data Fusion API Service Agent, which Cloud Data Fusion creates to gain access to customer resources so that it can act on the customer's behalf. It is used in the tenant project to access customer project resources. For example, Preview runs in memory instead of in a Dataproc cluster. The
Cloud Data Fusion API Service Agent
( |
CUSTOMER_PROJECT_NUMBER-
compute@developer.gserviceaccount.com |
The default Compute Engine service account that Cloud Data Fusion creates to deploy jobs that access other Google Cloud resources. By default, it attaches to a Dataproc cluster VM to enable Cloud Data Fusion to access Dataproc resources during a pipeline run. In the Cloud Data Fusion Enterprise edition, you can run pipelines from a user-managed service account by creating a profile from the Cloud Data Fusion console→System Admin→Configuration tab and adding the custom service account. In versions 6.2.3 and later, you can choose a custom service account to attach to the Dataproc cluster when creating a Cloud Data Fusion instance. For more information, see Service accounts in Dataproc. |
What's next
- Learn about controlling access to data.
- Give Service Account User permissions.
- See Cloud Data Fusion pricing.