Security recommendations
For workloads that require a strong security boundary or isolation, consider the following:
To enforce strict isolation, place security-sensitive workloads in a different Google Cloud project.
To control access to specific resources, enable role-based access control in your Cloud Data Fusion instances.
To ensure that the instance isn't publicly accessible and to reduce the risk of sensitive data exfiltration, enable internal IP addresses and VPC service controls (VPC-SC) in your instances.
Authentication
The Cloud Data Fusion web UI supports authentication mechanisms supported by Google Cloud console, with access controlled through Identity and Access Management.
Networking controls
You can create a private Cloud Data Fusion instance, which can be connected to your VPC Network through VPC peering or Private Service Connect. Private Cloud Data Fusion instances have an internal IP address, and aren't exposed to the public internet. Additional security is available using VPC Service Controls to establish a security perimeter around a Cloud Data Fusion private instance.
For more information, see the Cloud Data Fusion networking overview.
Pipeline execution on pre-created internal IP Dataproc clusters
You can use a private Cloud Data Fusion instance with the remote Hadoop provisioner. The Dataproc cluster must be on the VPC network peered with Cloud Data Fusion. The remote Hadoop provisioner is configured with the internal IP address of the master node of the Dataproc cluster.
Access control
Managing access to the Cloud Data Fusion instance: RBAC-enabled instances support managing access at a namespace level through Identity and Access Management. RBAC-disabled instances only support managing access at an instance level. If you have access to an instance, you have access to all pipelines and metadata in that instance.
Pipeline access to your data: Pipeline access to data is provided by granting access to the service account, which can be a custom service account that you specify.
Firewall rules
For a pipeline execution, you control ingress and egress by setting the appropriate firewall rules on the customer VPC on which the pipeline is being executed.
For more information, see Firewall rules.
Key storage
Passwords, keys, and other data are securely stored in Cloud Data Fusion and encrypted using keys stored in Cloud Key Management Service. At runtime, Cloud Data Fusion calls Cloud Key Management Service to retrieve the key used to decrypt stored secrets.
Encryption
By default, data is encrypted at rest using Google-owned and Google-managed encryption keys, and in transit using TLS v1.2. You use customer-managed encryption keys (CMEK) to control the data written by Cloud Data Fusion pipelines, including Dataproc cluster metadata and Cloud Storage, BigQuery, and Pub/Sub data sources and sinks.
Service accounts
Cloud Data Fusion pipelines execute in Dataproc clusters in the customer project, and can be configured to run using a customer-specified (custom) service account. A custom service account must be granted the Service Account User role.
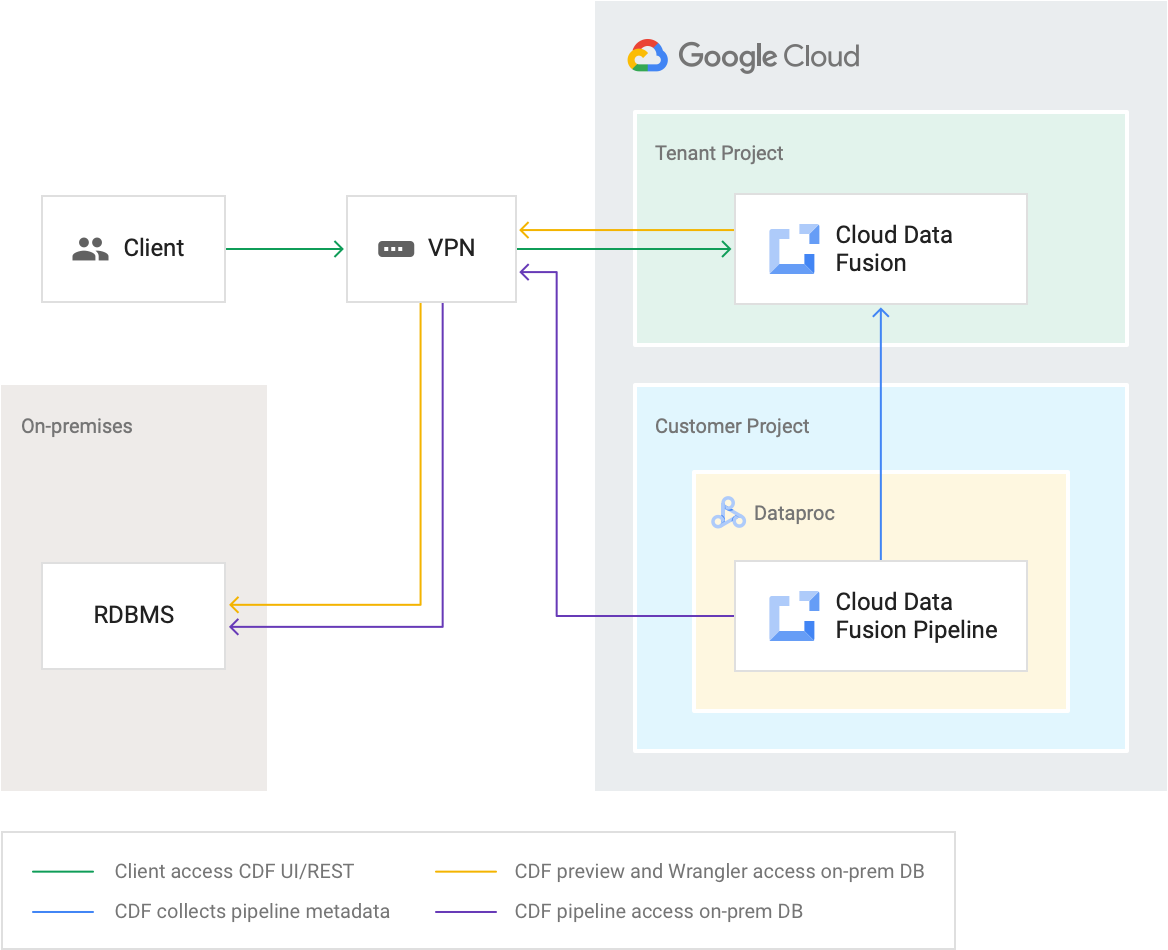
Projects
Cloud Data Fusion services are created in Google-managed tenant projects that users can't access. Cloud Data Fusion pipelines execute on Dataproc clusters inside customer projects. Customers can access these clusters during their lifetime.
Audit logs
Cloud Data Fusion audit logs are available from Logging.
Plugins and artifacts
Operators and Admins should be wary of installing untrusted plugins or artifacts, as they might present a security risk.
Workforce identity federation
Workforce identity federation users can perform operations in Cloud Data Fusion, such as creating, deleting, upgrading, and listing instances. For more information about limitations, see Workforce identity federation: supported products and limitations.