Zusammenfassung
In diesem Tutorial werden Sie durch das Bereitstellen und Ausführen von Llama 3.1- und Llama 3.2-Modellen mit vLLM in Vertex AI geführt. Es ist für die Verwendung mit zwei separaten Notebooks vorgesehen: Llama 3.1 mit vLLM bereitstellen zum Bereitstellen von Llama 3.1-Nur-Text-Modellen und Multimodales Llama 3.2 mit vLLM bereitstellen zum Bereitstellen von multimodalen Llama 3.2-Modellen, die sowohl Text- als auch Bildeingaben verarbeiten. Die auf dieser Seite beschriebenen Schritte zeigen Ihnen, wie Sie die Modellinferenz auf GPUs effizient handhaben und Modelle für verschiedene Anwendungen anpassen. Sie erhalten die Tools, mit denen Sie erweiterte Language Models in Ihre Projekte einbinden können.
Am Ende dieser Anleitung wissen Sie, wie Sie:
- Vordefinierte Llama-Modelle von Hugging Face mit vLLM-Container herunterladen.
- Diese Modelle auf GPU-Instanzen in Google CloudVertex AI Model Garden mit vLLM bereitstellen.
- Modelle effizient bereitstellen, um eine große Anzahl von Inferenzanfragen zu verarbeiten.
- Inferenz für Nur-Text-Anfragen sowie Text- und Bildanfragen ausführen.
- Sie setzen alles wieder zurück.
- Bereitstellung debuggen.
Wichtige vLLM-Funktionen
| Feature | Beschreibung |
|---|---|
| PagedAttention | Ein optimierter Aufmerksamkeitsmechanismus, der den Arbeitsspeicher während der Inferenz effizient verwaltet. Unterstützt die Textgenerierung mit hohem Durchsatz durch dynamische Zuweisung von Arbeitsspeicherressourcen, was die Skalierbarkeit für mehrere gleichzeitige Anfragen ermöglicht. |
| Kontinuierliche Batchverarbeitung | Fasst mehrere Eingabeanfragen in einem einzelnen Batch für die parallele Verarbeitung zusammen, wodurch die GPU-Auslastung und der Durchsatz maximiert werden. |
| Token-Streaming | Ermöglicht die Ausgabe von Tokens in Echtzeit während der Textgenerierung. Ideal für Anwendungen, die eine niedrige Latenz erfordern, z. B. Chatbots oder interaktive KI-Systeme. |
| Modellkompatibilität | Unterstützt eine Vielzahl vortrainierter Modelle in gängigen Frameworks wie Hugging Face Transformers. Dadurch wird die Integration und das Experimentieren mit verschiedenen LLMs erleichtert. |
| Mehrere GPUs und Hosts | Ermöglicht effizientes Bereitstellen von Modellen, indem die Arbeitslast auf mehrere GPUs auf einer einzelnen Maschine und auf mehrere Maschinen in einem Cluster verteilt wird. Dadurch werden Durchsatz und Skalierbarkeit erheblich gesteigert. |
| Effiziente Bereitstellung | Bietet eine nahtlose Integration mit APIs wie OpenAI Chat Completions, was die Bereitstellung für Produktionsanwendungsfälle vereinfacht. |
| Nahtlose Integration mit Hugging Face-Modellen | vLLM ist mit dem Format für Hugging Face-Modellartefakte kompatibel und unterstützt das Laden von HF. So lassen sich Llama-Modelle zusammen mit anderen beliebten Modellen wie Gemma, Phi und Qwen in einer optimierten Umgebung bereitstellen. |
| Community-basiertes Open-Source-Projekt | vLLM ist Open Source und fördert Community-Beiträge, was zu einer kontinuierlichen Verbesserung der Effizienz der LLM-Bereitstellung führt. |
Google Vertex AI vLLM Customizations: Enhance performance and integration
Die vLLM-Implementierung in Google Vertex AI Model Garden ist keine direkte Integration der Open-Source-Bibliothek. In Vertex AI wird eine angepasste und optimierte Version von vLLM verwendet, die speziell auf die Verbesserung von Leistung, Zuverlässigkeit und nahtloser Integration in Google Cloudzugeschnitten ist.
- Leistungsoptimierungen:
- Paralleles Herunterladen aus Cloud Storage:Das Laden und Bereitstellen von Modellen wird erheblich beschleunigt, da Daten parallel aus Cloud Storage abgerufen werden können. Dadurch wird die Latenz reduziert und die Startgeschwindigkeit verbessert.
- Verbesserungen der Funktionen:
- Dynamisches LoRA mit erweitertem Caching und Cloud Storage-Unterstützung:Die dynamischen LoRA-Funktionen werden durch lokale Festplatten-Caching-Mechanismen und eine robuste Fehlerbehandlung erweitert. Außerdem wird das Laden von LoRA-Gewichten direkt aus Cloud Storage-Pfaden und signierten URLs unterstützt. Dies vereinfacht die Verwaltung und Bereitstellung benutzerdefinierter Modelle.
- Llama 3.1/3.2-Parsing für Funktionsaufrufe:Implementiert ein spezielles Parsing für Llama 3.1/3.2-Funktionsaufrufe, wodurch die Robustheit beim Parsen verbessert wird.
- Prefix-Caching für Hostspeicher:Der externe vLLM unterstützt nur das Prefix-Caching für GPU-Speicher.
- Spekulatives Decodieren:Dies ist ein vorhandenes vLLM-Feature, aber Vertex AI hat Experimente durchgeführt, um leistungsstarke Modelleinrichtungen zu finden.
Diese Vertex AI-spezifischen Anpassungen sind für den Endnutzer oft transparent und ermöglichen es Ihnen, die Leistung und Effizienz Ihrer Llama 3.1-Bereitstellungen in Vertex AI Model Garden zu maximieren.
- Einbindung in das Vertex AI-Ökosystem:
- Unterstützung von Vertex AI-Vorhersage-Ein-/Ausgabeformaten:Sorgt für nahtlose Kompatibilität mit Vertex AI-Vorhersage-Ein-/Ausgabeformaten und vereinfacht die Datenverarbeitung und Integration mit anderen Vertex AI-Diensten.
- Vertex-Umgebungsvariablen: Vertex AI-Umgebungsvariablen (
AIP_*) werden für die Konfiguration und Ressourcenverwaltung berücksichtigt und genutzt. Dadurch wird die Bereitstellung optimiert und ein einheitliches Verhalten in der Vertex AI-Umgebung sichergestellt. - Verbesserte Fehlerbehandlung und Robustheit:Umfassende Fehlerbehandlung, Ein-/Ausgabevalidierung und Serverbeendigungsmechanismen sorgen für Stabilität, Zuverlässigkeit und nahtlosen Betrieb in der verwalteten Vertex AI-Umgebung.
- Nginx-Server für die Funktion:Integriert einen Nginx-Server über dem vLLM-Server, was die Bereitstellung mehrerer Replikate ermöglicht und die Skalierbarkeit und Hochverfügbarkeit der Serving-Infrastruktur verbessert.
Zusätzliche Vorteile von vLLM
- Benchmark-Leistung: vLLM bietet im Vergleich zu anderen Bereitstellungssystemen wie Hugging Face Text-Generation-Inference und FasterTransformer von NVIDIA eine wettbewerbsfähige Leistung in Bezug auf Durchsatz und Latenz.
- Einfache Bedienung: Die Bibliothek bietet eine unkomplizierte API für die Integration in bestehende Workflows. So können Sie sowohl Llama 3.1- als auch Llama 3.2-Modelle mit minimalem Aufwand bereitstellen.
- Erweiterte Funktionen: vLLM unterstützt das Streamen von Ausgaben (Generieren von Antworten Token für Token) und verarbeitet Prompts mit variabler Länge effizient, wodurch die Interaktivität und Reaktionsfähigkeit in Anwendungen verbessert werden.
Eine Übersicht über das vLLM-System finden Sie in diesem Artikel.
Unterstützte Modelle
vLLM unterstützt eine große Auswahl an modernen Modellen, sodass Sie das Modell auswählen können, das am besten zu Ihren Anforderungen passt. In der folgenden Tabelle finden Sie eine Auswahl dieser Modelle. Eine umfassende Liste der unterstützten Modelle, einschließlich der Modelle für die reine Textinferenz und die multimodale Inferenz, finden Sie auf der offiziellen vLLM-Website.
| Kategorie | Modelle |
|---|---|
| Meta AI | Llama 3.3, Llama 3.2, Llama 3.1, Llama 3, Llama 2, Code Llama |
| Mistral AI | Mistral 7B, Mixtral 8x7B, Mixtral 8x22B und ihre Varianten (Instruct, Chat), Mistral-tiny, Mistral-small, Mistral-medium |
| DeepSeek AI | DeepSeek-V3, DeepSeek-R1, DeepSeek-R1-Distill-Qwen-1.5B, DeepSeek-R1-Distill-Qwen-7B, DeepSeek-R1-Distill-Llama-8B, DeepSeek-R1-Distill-Qwen-14B, DeepSeek-R1-Distill-Qwen-32B, DeepSeek-R1-Distill-Llama-70B, Deepseek-vl2-tiny, Deepseek-vl2-small, Deepseek-vl2 |
| MosaicML | MPT (7B, 30B) und Varianten (Instruct, Chat), MPT-7B-StoryWriter-65k |
| OpenAI | GPT-2, GPT-3, GPT-4, GPT-NeoX |
| Together AI | RedPajama, Pythia |
| Stability AI | StableLM (3B, 7B), StableLM-Alpha-3B, StableLM-Base-Alpha-7B, StableLM-Instruct-Alpha-7B |
| TII (Technology Innovation Institute) | Falcon 7B, Falcon 40B und Varianten (Instruct, Chat), Falcon-RW-1B, Falcon-RW-7B |
| BigScience | BLOOM, BLOOMZ |
| FLAN-T5, UL2, Gemma (2B, 7B), PaLM 2, | |
| Salesforce | CodeT5, CodeT5+ |
| LightOn | Persimmon-8B-base, Persimmon-8B-chat |
| EleutherAI | GPT-Neo, Pythia |
| AI21 Labs | Jamba |
| Cerebras | Cerebras-GPT |
| Intel | Intel-NeuralChat-7B |
| Andere bekannte Modelle | StarCoder, OPT, Baichuan, Aquila, Qwen, InternLM, XGen, OpenLLaMA, Phi-2, Yi, OpenCodeInterpreter, Nous-Hermes, Gemma-it, Mistral-Instruct-v0.2-7B-Zeus, |
Erste Schritte mit Model Garden
Der vLLM Cloud-GPUs-Bereitstellungscontainer ist in Model Garden, dem Playground, der Ein-Klick-Bereitstellung und den Colab Enterprise-Notebook-Beispielen integriert. In dieser Anleitung wird die Llama-Modellfamilie von Meta AI als Beispiel verwendet.
Colab Enterprise-Notebook verwenden
Playground- und One-Click-Bereitstellungen sind ebenfalls verfügbar, werden in dieser Anleitung jedoch nicht beschrieben.
- Rufen Sie die Seite „Modellkarte“ auf und klicken Sie auf Notebook öffnen.
- Wählen Sie das Vertex Serving-Notebook aus. Das Notebook wird in Colab Enterprise geladen.
- Führen Sie das Notebook durch, um ein Modell mit vLLM bereitzustellen und Vorhersageanfragen an den Endpunkt zu senden.
Einrichtung und Anforderungen
In diesem Abschnitt werden die erforderlichen Schritte zum Einrichten Ihres Google Cloud-Projekts beschrieben. Außerdem wird erläutert, wie Sie dafür sorgen, dass Sie die erforderlichen Ressourcen zum Bereitstellen und Ausführen von vLLM-Modellen haben.
1. Abrechnung
- Abrechnung aktivieren: Die Abrechnung muss für Ihr Projekt aktiviert sein. Weitere Informationen finden Sie unter Abrechnung für ein Projekt aktivieren, deaktivieren oder ändern.
2. GPU-Verfügbarkeit und -Kontingente
- Wenn Sie Vorhersagen mit leistungsstarken GPUs (NVIDIA A100 80 GB oder H100 80 GB) ausführen möchten, müssen Sie die Kontingente für diese GPUs in der ausgewählten Region prüfen:
| Maschinentyp | Beschleunigertyp | Empfohlene Regionen |
|---|---|---|
| a2-ultragpu-1g | 1 NVIDIA_A100_80GB | us-central1, us-east4, europe-west4, asia-southeast1 |
| a3-highgpu-8g | 8 NVIDIA_H100_80GB | us-central1, us-west1, europe-west4, asia-southeast1 |
3. Google Cloud -Projekt einrichten
Führen Sie das folgende Codebeispiel aus, um zu prüfen, ob Ihre Google Cloud Umgebung richtig eingerichtet ist. In diesem Schritt werden die erforderlichen Python-Bibliotheken installiert und der Zugriff auf Google Cloud Ressourcen eingerichtet. Zu den Aktionen gehören:
- Installation: Aktualisieren Sie die
google-cloud-aiplatform-Bibliothek und klonen Sie das Repository mit den Hilfsfunktionen. - Umgebung einrichten: Definieren von Variablen für die Google Cloud Projekt-ID, die Region und einen eindeutigen Cloud Storage-Bucket zum Speichern von Modellartefakten.
- API-Aktivierung: Aktivieren Sie die Vertex AI- und Compute Engine-APIs, die für die Bereitstellung und Verwaltung von KI-Modellen unerlässlich sind.
- Bucket-Konfiguration: Erstellen Sie einen neuen Cloud Storage-Bucket oder prüfen Sie einen vorhandenen Bucket, um sicherzustellen, dass er sich in der richtigen Region befindet.
- Vertex AI-Initialisierung: Initialisieren Sie die Vertex AI-Clientbibliothek mit den Einstellungen für Projekt, Standort und Staging-Bucket.
- Dienstkonto einrichten: Identifizieren Sie das Standarddienstkonto zum Ausführen von Vertex AI-Jobs und erteilen Sie ihm die erforderlichen Berechtigungen.
BUCKET_URI = "gs://"
REGION = ""
! pip3 install --upgrade --quiet 'google-cloud-aiplatform>=1.64.0'
! git clone https://github.com/GoogleCloudPlatform/vertex-ai-samples.git
import datetime
import importlib
import os
import uuid
from typing import Tuple
import requests
from google.cloud import aiplatform
common_util = importlib.import_module(
"vertex-ai-samples.community-content.vertex_model_garden.model_oss.notebook_util.common_util"
)
models, endpoints = {}, {}
PROJECT_ID = os.environ["GOOGLE_CLOUD_PROJECT"]
if not REGION:
REGION = os.environ["GOOGLE_CLOUD_REGION"]
print("Enabling Vertex AI API and Compute Engine API.")
! gcloud services enable aiplatform.googleapis.com compute.googleapis.com
now = datetime.datetime.now().strftime("%Y%m%d%H%M%S")
BUCKET_NAME = "/".join(BUCKET_URI.split("/")[:3])
if BUCKET_URI is None or BUCKET_URI.strip() == "" or BUCKET_URI == "gs://":
BUCKET_URI = f"gs://{PROJECT_ID}-tmp-{now}-{str(uuid.uuid4())[:4]}"
BUCKET_NAME = "/".join(BUCKET_URI.split("/")[:3])
! gsutil mb -l {REGION} {BUCKET_URI}
else:
assert BUCKET_URI.startswith("gs://"), "BUCKET_URI must start with `gs://`."
shell_output = ! gsutil ls -Lb {BUCKET_NAME} | grep "Location constraint:" | sed "s/Location constraint://"
bucket_region = shell_output[0].strip().lower()
if bucket_region != REGION:
raise ValueError(
"Bucket region %s is different from notebook region %s"
% (bucket_region, REGION)
)
print(f"Using this Bucket: {BUCKET_URI}")
STAGING_BUCKET = os.path.join(BUCKET_URI, "temporal")
MODEL_BUCKET = os.path.join(BUCKET_URI, "llama3_1")
print("Initializing Vertex AI API.")
aiplatform.init(project=PROJECT_ID, location=REGION, staging_bucket=STAGING_BUCKET)
shell_output = ! gcloud projects describe $PROJECT_ID
project_number = shell_output[-1].split(":")[1].strip().replace("'", "")
SERVICE_ACCOUNT = "your service account email"
print("Using this default Service Account:", SERVICE_ACCOUNT)
! gsutil iam ch serviceAccount:{SERVICE_ACCOUNT}:roles/storage.admin $BUCKET_NAME
! gcloud config set project $PROJECT_ID
! gcloud projects add-iam-policy-binding --no-user-output-enabled {PROJECT_ID} --member=serviceAccount:{SERVICE_ACCOUNT} --role="roles/storage.admin"
! gcloud projects add-iam-policy-binding --no-user-output-enabled {PROJECT_ID} --member=serviceAccount:{SERVICE_ACCOUNT} --role="roles/aiplatform.user"
Hugging Face mit Meta Llama 3.1, 3.2 und vLLM verwenden
Die Sammlungen Llama 3.1 und 3.2 von Meta bieten eine Reihe mehrsprachiger Large Language Models (LLMs), die für die hochwertige Textgenerierung in verschiedenen Anwendungsfällen entwickelt wurden. Diese Modelle sind vortrainiert und anhand von Anleitungen abgestimmt und eignen sich hervorragend für Aufgaben wie mehrsprachige Dialoge, Zusammenfassungen und die Suche nach Informationen durch Agents. Bevor Sie Llama 3.1- und 3.2-Modelle verwenden können, müssen Sie den Nutzungsbedingungen zustimmen, wie im Screenshot gezeigt. Die vLLM-Bibliothek bietet eine optimierte Open-Source-Bereitstellungsumgebung mit Optimierungen für Latenz, Speichereffizienz und Skalierbarkeit.
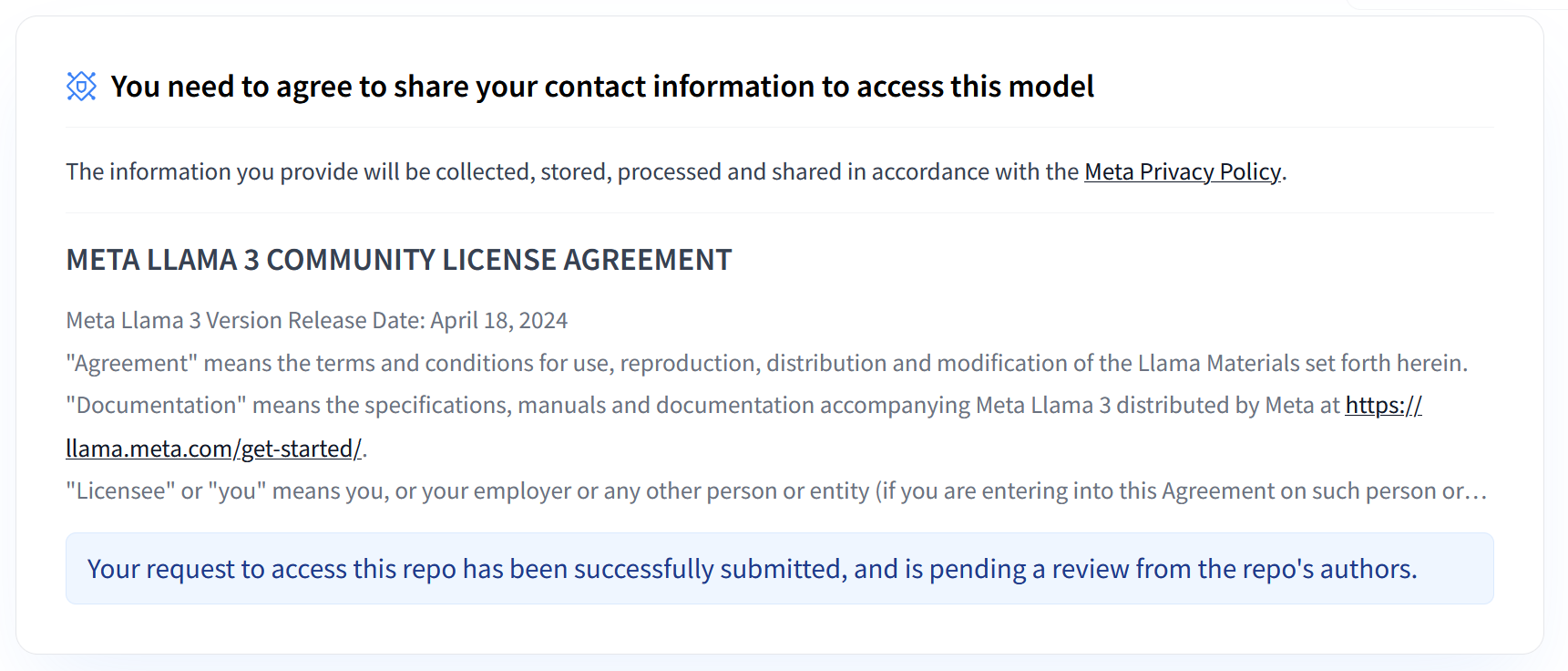 Abbildung 1: Meta LLama 3 Community-Lizenzvereinbarung
Abbildung 1: Meta LLama 3 Community-Lizenzvereinbarung
Übersicht über die Sammlungen für Meta Llama 3.1 und 3.2
Die Llama 3.1- und 3.2-Sammlungen sind jeweils für unterschiedliche Bereitstellungsskalen und Modellgrößen geeignet und bieten Ihnen flexible Optionen für mehrsprachige Dialogaufgaben und mehr. Weitere Informationen finden Sie auf der Seite Llama – Übersicht.
- Nur Text: Die Llama 3.2-Sammlung mehrsprachiger Large Language Models (LLMs) ist eine Sammlung vortrainierter und anweisungsorientierter generativer Modelle in den Größen 1B und 3B (Text-in/Text-Ausgang).
- Vision und Vision Instruct: Die Llama 3.2-Vision-Sammlung multimodaler Large Language Models (LLMs) ist eine Sammlung vortrainierter und anweisungsorientierter generativer Modelle für die Bildanalyse in den Größen 11B und 90B (Text + Bilder ein, Text aus). Optimierung: Wie Llama 3.1 sind die 3.2-Modelle für mehrsprachige Dialoge optimiert und erzielen bei Abruf- und Zusammenfassungsaufgaben gute Ergebnisse. Sie erreichen bei Standard-Benchmarks Spitzenwerte.
- Modellarchitektur: Llama 3.2 basiert auf einem autoregressiven Transformer-Framework, bei dem SFT und RLHF angewendet werden, um die Modelle auf Nützlichkeit und Sicherheit auszurichten.
Hugging Face-Nutzerzugriffstokens
Für diese Anleitung ist ein Lesezugriffstoken aus dem Hugging Face Hub erforderlich, um auf die erforderlichen Ressourcen zuzugreifen. So richten Sie die Authentifizierung ein:
 Abbildung 2: Einstellungen für das Hugging Face-Zugriffstoken
Abbildung 2: Einstellungen für das Hugging Face-Zugriffstoken
So generieren Sie ein Lesezugriffstoken:
- Rufen Sie die Einstellungen Ihres Hugging Face-Kontos auf.
- Erstellen Sie ein neues Token, weisen Sie ihm die Rolle „Lesen“ zu und speichern Sie das Token sicher.
Token verwenden:
- Verwenden Sie das generierte Token, um sich zu authentifizieren und bei Bedarf auf öffentliche oder private Repositorys zuzugreifen.
 Abbildung 3: Hugging Face-Zugriffstoken verwalten
Abbildung 3: Hugging Face-Zugriffstoken verwalten
So haben Sie die richtige Zugriffsebene ohne unnötige Berechtigungen. Diese Praktiken erhöhen die Sicherheit und verhindern, dass Tokens versehentlich offengelegt werden. Weitere Informationen zum Einrichten von Zugriffstokens finden Sie auf der Seite zu Hugging Face-Zugriffstokens.
Geben Sie Ihr Token nicht öffentlich oder online weiter. Wenn Sie Ihr Token während der Bereitstellung als Umgebungsvariable festlegen, bleibt es privat für Ihr Projekt. Vertex AI sorgt für Sicherheit, indem verhindert wird, dass andere Nutzer auf Ihre Modelle und Endpunkte zugreifen.
Weitere Informationen zum Schutz Ihres Zugriffstokens finden Sie unter Hugging Face-Zugriffstokens – Best Practices.
Nur-Text-Llama 3.1-Modelle mit vLLM bereitstellen
Für die Bereitstellung von Large Language Models in der Produktion bietet vLLM eine effiziente Bereitstellungslösung, die die Speichernutzung optimiert, die Latenz verringert und den Durchsatz erhöht. Daher eignet es sich besonders gut für die Verarbeitung der größeren Llama 3.1-Modelle sowie der multimodalen Llama 3.2-Modelle.
Schritt 1: Bereitzustellendes Modell auswählen
Wählen Sie die Llama 3.1-Modellvariante aus, die Sie bereitstellen möchten. Es sind verschiedene Größen und instruction-tuned Versionen verfügbar:
base_model_name = "Meta-Llama-3.1-8B" # @param ["Meta-Llama-3.1-8B", "Meta-Llama-3.1-8B-Instruct", "Meta-Llama-3.1-70B", "Meta-Llama-3.1-70B-Instruct", "Meta-Llama-3.1-405B-FP8", "Meta-Llama-3.1-405B-Instruct-FP8"]
hf_model_id = "meta-Llama/" + base_model_name
Schritt 2: Hardware und Kontingent für die Bereitstellung prüfen
Die Bereitstellungsfunktion legt die entsprechende GPU und den entsprechenden Maschinentyp basierend auf der Modellgröße fest und prüft das Kontingent in der jeweiligen Region für ein bestimmtes Projekt:
if "8b" in base_model_name.lower():
accelerator_type = "NVIDIA_L4"
machine_type = "g2-standard-12"
accelerator_count = 1
elif "70b" in base_model_name.lower():
accelerator_type = "NVIDIA_L4"
machine_type = "g2-standard-96"
accelerator_count = 8
elif "405b" in base_model_name.lower():
accelerator_type = "NVIDIA_H100_80GB"
machine_type = "a3-highgpu-8g"
accelerator_count = 8
else:
raise ValueError(f"Recommended GPU setting not found for: {accelerator_type} and {base_model_name}.")
So prüfen Sie, ob in der angegebenen Region ein GPU-Kontingent verfügbar ist:
common_util.check_quota(
project_id=PROJECT_ID,
region=REGION,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
is_for_training=False,
)
Schritt 3: Modell mit vLLM prüfen
Mit der folgenden Funktion wird das Modell in Vertex AI hochgeladen, die Bereitstellungseinstellungen werden konfiguriert und das Modell wird mit vLLM auf einem Endpunkt bereitgestellt.
- Docker-Image: Bei der Bereitstellung wird ein vorgefertigtes vLLM-Docker-Image für die effiziente Bereitstellung verwendet.
- Konfiguration: Konfigurieren Sie die Speicherauslastung, die Modelllänge und andere vLLM-Einstellungen. Weitere Informationen zu den vom Server unterstützten Argumenten finden Sie auf der offiziellen vLLM-Dokumentationsseite.
- Umgebungsvariablen: Legen Sie Umgebungsvariablen für die Authentifizierung und die Bereitstellungsquelle fest.
def deploy_model_vllm(
model_name: str,
model_id: str,
service_account: str,
base_model_id: str = None,
machine_type: str = "g2-standard-8",
accelerator_type: str = "NVIDIA_L4",
accelerator_count: int = 1,
gpu_memory_utilization: float = 0.9,
max_model_len: int = 4096,
dtype: str = "auto",
enable_trust_remote_code: bool = False,
enforce_eager: bool = False,
enable_lora: bool = False,
max_loras: int = 1,
max_cpu_loras: int = 8,
use_dedicated_endpoint: bool = False,
max_num_seqs: int = 256,
) -> Tuple[aiplatform.Model, aiplatform.Endpoint]:
"""Deploys trained models with vLLM into Vertex AI."""
endpoint = aiplatform.Endpoint.create(
display_name=f"{model_name}-endpoint",
dedicated_endpoint_enabled=use_dedicated_endpoint,
)
if "8b" in base_model_name.lower():
accelerator_type = "NVIDIA_L4"
machine_type = "g2-standard-12"
accelerator_count = 1
elif "70b" in base_model_name.lower():
accelerator_type = "NVIDIA_L4"
machine_type = "g2-standard-96"
accelerator_count = 8
elif "405b" in base_model_name.lower():
accelerator_type = "NVIDIA_H100_80GB"
machine_type = "a3-highgpu-8g"
accelerator_count = 8
else:
raise ValueError(f"Recommended GPU setting not found for: {accelerator_type} and {base_model_name}.")
common_util.check_quota(
project_id=PROJECT_ID,
region=REGION,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
is_for_training=False,
)
vllm_args = [
"python", "-m", "vllm.entrypoints.api_server",
"--host=0.0.0.0",
"--port=8080",
f"--model={model_id}",
f"--tensor-parallel-size={accelerator_count}",
"--swap-space=16",
f"--gpu-memory-utilization={gpu_memory_utilization}",
f"--max-model-len={max_model_len}", f"--dtype={dtype}",
f"--max-loras={max_loras}", f"--max-cpu-loras={max_cpu_loras}",
f"--max-num-seqs={max_num_seqs}", "--disable-log-stats"
]
if enable_trust_remote_code:
vllm_args.append("--trust-remote-code")
if enforce_eager:
vllm_args.append("--enforce-eager")
if enable_lora:
vllm_args.append("--enable-lora")
if model_type:
vllm_args.append(f"--model-type={model_type}")
env_vars = {
"MODEL_ID": model_id,
"DEPLOY_SOURCE": "notebook",
"HF_TOKEN": HF_TOKEN
}
model = aiplatform.Model.upload(
display_name=model_name,
serving_container_image_uri=VLLM_DOCKER_URI,
serving_container_args=vllm_args,
serving_container_ports=[8080],
serving_container_predict_route="/generate",
serving_container_health_route="/ping",
serving_container_environment_variables=env_vars,
serving_container_shared_memory_size_mb=(16 * 1024),
serving_container_deployment_timeout=7200,
)
print(f"Deploying {model_name} on {machine_type} with {accelerator_count} {accelerator_type} GPU(s).")
model.deploy(
endpoint=endpoint,
machine_type=machine_type,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
deploy_request_timeout=1800,
service_account=service_account,
)
print("endpoint_name:", endpoint.name)
return model, endpoint
Schritt 4: Deployment ausführen
Führen Sie die Bereitstellungsfunktion mit dem ausgewählten Modell und der ausgewählten Konfiguration aus. In diesem Schritt wird das Modell bereitgestellt und die Modell- und Endpunktinstanzen werden zurückgegeben:
HF_TOKEN = ""
VLLM_DOCKER_URI = "us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20241001_0916_RC00"
model_name = common_util.get_job_name_with_datetime(prefix=f"{base_model_name}-serve-vllm")
gpu_memory_utilization = 0.9
max_model_len = 4096
max_loras = 1
models["vllm_gpu"], endpoints["vllm_gpu"] = deploy_model_vllm(
model_name=common_util.get_job_name_with_datetime(prefix=f"{base_model_name}-serve"),
model_id=hf_model_id,
service_account=SERVICE_ACCOUNT,
machine_type=machine_type,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
gpu_memory_utilization=gpu_memory_utilization,
max_model_len=max_model_len,
max_loras=max_loras,
enforce_eager=True,
enable_lora=True,
use_dedicated_endpoint=use_dedicated_endpoint,
)
Nachdem Sie dieses Codebeispiel ausgeführt haben, wird Ihr Llama 3.1-Modell in Vertex AI bereitgestellt und ist über den angegebenen Endpunkt zugänglich. Sie können mit ihm für Inferenzaufgaben wie Textgenerierung, Zusammenfassung und Dialog interagieren. Je nach Modellgröße kann die Bereitstellung eines neuen Modells bis zu einer Stunde dauern. Sie können den Fortschritt bei der Onlinevorhersage prüfen.
 Abbildung 4: Llama 3.1-Bereitstellungsendpunkt im Vertex-Dashboard
Abbildung 4: Llama 3.1-Bereitstellungsendpunkt im Vertex-Dashboard
Vorhersagen mit Llama 3.1 in Vertex AI treffen
Nachdem Sie das Llama 3.1-Modell erfolgreich in Vertex AI bereitgestellt haben, können Sie Vorhersagen treffen, indem Sie Textprompts an den Endpunkt senden. In diesem Abschnitt finden Sie ein Beispiel für das Generieren von Antworten mit verschiedenen anpassbaren Parametern zur Steuerung der Ausgabe.
Schritt 1: Prompt und Parameter definieren
Richten Sie zuerst Ihren Text-Prompt und die Sampling-Parameter ein, um die Antwort des Modells zu steuern. Hier sind die wichtigsten Parameter:
prompt: Der Eingabetext, für den das Modell eine Antwort generieren soll. Beispiel: prompt = „Was ist ein Auto?“max_tokens: Die maximale Anzahl von Tokens in der generierten Ausgabe. Wenn Sie diesen Wert verringern, können Sie Zeitüberschreitungsprobleme vermeiden.temperature: Steuert die Zufälligkeit von Vorhersagen. Höhere Werte (z. B. 1, 0) erhöhen die Vielfalt, während niedrigere Werte (z. B. 0, 5) die Ausgabe fokussierter machen.top_p: Beschränkt den Stichprobenpool auf die höchste kumulative Wahrscheinlichkeit. Wenn Sie beispielsweise „top_p“ auf 0,9 festlegen, werden nur Tokens mit den obersten 90 % der Wahrscheinlichkeit berücksichtigt.top_k: Beschränkt die Stichprobenerhebung auf die k wahrscheinlichsten Tokens. Wenn Sie beispielsweise „top_k = 50“ festlegen, wird nur aus den 50 häufigsten Tokens gesampelt.raw_response: Wenn „True“, wird die Rohausgabe des Modells zurückgegeben. Wenn „False“, wird zusätzliche Formatierung mit der Struktur „Prompt:\n{prompt}\nOutput:\n{output}“ angewendet.lora_id(optional): Pfad zu LoRA-Gewichtungsdateien zum Anwenden von Gewichten für die Low-Rank Adaptation (LoRA). Dies kann ein Cloud Storage-Bucket oder eine Hugging Face-Repository-URL sein. Das funktioniert nur, wenn--enable-lorain den Bereitstellungsargumenten festgelegt ist. Dynamic LoRA wird für multimodale Modelle nicht unterstützt.
prompt = "What is a car?"
max_tokens = 50
temperature = 1.0
top_p = 1.0
top_k = 1
raw_response = False
lora_id = ""
Schritt 2: Vorhersageanfrage senden
Nachdem die Instanz konfiguriert wurde, können Sie die Vorhersageanfrage an den bereitgestellten Vertex AI-Endpunkt senden. In diesem Beispiel wird gezeigt, wie Sie eine Vorhersage treffen und das Ergebnis ausgeben:
response = endpoints["vllm_gpu"].predict(
instances=instances, use_dedicated_endpoint=use_dedicated_endpoint
)
for prediction in response.predictions:
print(prediction)
Beispielausgabe
Hier ein Beispiel dafür, wie das Modell auf den Prompt „Was ist ein Auto?“ reagieren könnte:
Human: What is a car?
Assistant: A car, or a motor car, is a road-connected human-transportation system
used to move people or goods from one place to another.
Zusätzliche Hinweise
- Moderation: Um für sichere Inhalte zu sorgen, können Sie den generierten Text mit den Textmoderationsfunktionen von Vertex AI moderieren.
- Zeitüberschreitungen behandeln: Wenn Probleme wie
ServiceUnavailable: 503auftreten, versuchen Sie, den Parametermax_tokenszu verringern.
Dieser Ansatz bietet eine flexible Möglichkeit, mit dem Llama 3.1-Modell zu interagieren, indem verschiedene Sampling-Techniken und LoRA-Adapter verwendet werden. Er eignet sich daher für eine Vielzahl von Anwendungsfällen, von der allgemeinen Textgenerierung bis hin zu aufgabenspezifischen Antworten.
Multimodale Llama 3.2-Modelle mit vLLM bereitstellen
In diesem Abschnitt wird beschrieben, wie Sie vorgefertigte Llama 3.2-Modelle in die Model Registry hochladen und auf einem Vertex AI-Endpunkt bereitstellen. Die Bereitstellung kann je nach Größe des Modells bis zu einer Stunde dauern. Llama 3.2-Modelle sind in multimodalen Versionen verfügbar, die sowohl Text- als auch Bildeingaben unterstützen. vLLM unterstützt:
- Nur-Text-Format
- Einzelbild- und Textformat
Diese Formate machen Llama 3.2 für Anwendungen geeignet, die sowohl visuelle als auch Textverarbeitung erfordern.
Schritt 1: Bereitzustellendes Modell auswählen
Geben Sie die Llama 3.2-Modellvariante an, die Sie bereitstellen möchten. Im folgenden Beispiel wird Llama-3.2-11B-Vision als ausgewähltes Modell verwendet. Sie können jedoch je nach Bedarf auch andere verfügbare Optionen auswählen.
base_model_name = "Llama-3.2-11B-Vision" # @param ["Llama-3.2-1B", "Llama-3.2-1B-Instruct", "Llama-3.2-3B", "Llama-3.2-3B-Instruct", "Llama-3.2-11B-Vision", "Llama-3.2-11B-Vision-Instruct", "Llama-3.2-90B-Vision", "Llama-3.2-90B-Vision-Instruct"]
hf_model_id = "meta-Llama/" + base_model_name
Schritt 2: Hardware und Ressourcen konfigurieren
Wählen Sie die passende Hardware für die Modellgröße aus. vLLM kann je nach Rechenanforderungen des Modells verschiedene GPUs verwenden:
- 1B- und 3B-Modelle: Verwenden Sie NVIDIA L4-GPUs.
- 11B-Modelle: Verwenden Sie NVIDIA A100-GPUs.
- 90B-Modelle: Verwenden Sie NVIDIA H100-GPUs.
In diesem Beispiel wird die Bereitstellung basierend auf der Modellauswahl konfiguriert:
if "3.2-1B" in base_model_name or "3.2-3B" in base_model_name:
accelerator_type = "NVIDIA_L4"
machine_type = "g2-standard-8"
accelerator_count = 1
elif "3.2-11B" in base_model_name:
accelerator_type = "NVIDIA_TESLA_A100"
machine_type = "a2-highgpu-1g"
accelerator_count = 1
elif "3.2-90B" in base_model_name:
accelerator_type = "NVIDIA_H100_80GB"
machine_type = "a3-highgpu-8g"
accelerator_count = 8
else:
raise ValueError(f"Recommended GPU setting not found for: {base_model_name}.")
Prüfen Sie, ob Sie das erforderliche GPU-Kontingent haben:
common_util.check_quota(
project_id=PROJECT_ID,
region=REGION,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
is_for_training=False,
)
Schritt 3: Modell mit vLLM bereitstellen
Die folgende Funktion übernimmt die Bereitstellung des Llama 3.2-Modells in Vertex AI. Sie konfiguriert die Umgebung des Modells, die Speicherauslastung und die vLLM-Einstellungen für eine effiziente Bereitstellung.
def deploy_model_vllm(
model_name: str,
model_id: str,
service_account: str,
base_model_id: str = None,
machine_type: str = "g2-standard-8",
accelerator_type: str = "NVIDIA_L4",
accelerator_count: int = 1,
gpu_memory_utilization: float = 0.9,
max_model_len: int = 4096,
dtype: str = "auto",
enable_trust_remote_code: bool = False,
enforce_eager: bool = False,
enable_lora: bool = False,
max_loras: int = 1,
max_cpu_loras: int = 8,
use_dedicated_endpoint: bool = False,
max_num_seqs: int = 12,
model_type: str = None,
) -> Tuple[aiplatform.Model, aiplatform.Endpoint]:
"""Deploys trained models with vLLM into Vertex AI."""
endpoint = aiplatform.Endpoint.create(
display_name=f"{model_name}-endpoint",
dedicated_endpoint_enabled=use_dedicated_endpoint,
)
if not base_model_id:
base_model_id = model_id
vllm_args = [
"python",
"-m",
"vllm.entrypoints.api_server",
"--host=0.0.0.0",
"--port=8080",
f"--model={model_id}",
f"--tensor-parallel-size={accelerator_count}",
"--swap-space=16",
f"--gpu-memory-utilization={gpu_memory_utilization}",
f"--max-model-len={max_model_len}",
f"--dtype={dtype}",
f"--max-loras={max_loras}",
f"--max-cpu-loras={max_cpu_loras}",
f"--max-num-seqs={max_num_seqs}",
"--disable-log-stats",
]
if enable_trust_remote_code:
vllm_args.append("--trust-remote-code")
if enforce_eager:
vllm_args.append("--enforce-eager")
if enable_lora:
vllm_args.append("--enable-lora")
if model_type:
vllm_args.append(f"--model-type={model_type}")
env_vars = {
"MODEL_ID": base_model_id,
"DEPLOY_SOURCE": "notebook",
}
# HF_TOKEN is not a compulsory field and may not be defined.
try:
if HF_TOKEN:
env_vars["HF_TOKEN"] = HF_TOKEN
except NameError:
pass
model = aiplatform.Model.upload(
display_name=model_name,
serving_container_image_uri=VLLM_DOCKER_URI,
serving_container_args=vllm_args,
serving_container_ports=[8080],
serving_container_predict_route="/generate",
serving_container_health_route="/ping",
serving_container_environment_variables=env_vars,
serving_container_shared_memory_size_mb=(16 * 1024),
serving_container_deployment_timeout=7200,
)
print(f"Deploying {model_name} on {machine_type} with {accelerator_count} {accelerator_type} GPU(s).")
model.deploy(
endpoint=endpoint,
machine_type=machine_type,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
deploy_request_timeout=1800,
service_account=service_account,
)
print("endpoint_name:", endpoint.name)
return model, endpoint
Schritt 4: Deployment ausführen
Führen Sie die Bereitstellungsfunktion mit dem konfigurierten Modell und den konfigurierten Einstellungen aus. Die Funktion gibt sowohl die Modell- als auch die Endpunktinstanzen zurück, die Sie für die Inferenz verwenden können.
model_name = common_util.get_job_name_with_datetime(prefix=f"{base_model_name}-serve-vllm")
models["vllm_gpu"], endpoints["vllm_gpu"] = deploy_model_vllm(
model_name=model_name
model_id=hf_model_id,
base_model_id=hf_model_id,
service_account=SERVICE_ACCOUNT,
machine_type=machine_type,
accelerator_type=accelerator_type,
accelerator_count=accelerator_count,
gpu_memory_utilization=gpu_memory_utilization,
max_model_len=max_model_len,
enforce_eager=True,
use_dedicated_endpoint=use_dedicated_endpoint,
max_num_seqs=max_num_seqs,
)
 Abbildung 5: Llama 3.2-Bereitstellungsendpunkt im Vertex-Dashboard
Abbildung 5: Llama 3.2-Bereitstellungsendpunkt im Vertex-Dashboard
Je nach Modellgröße kann die Bereitstellung eines neuen Modells bis zu einer Stunde dauern. Sie können den Fortschritt bei der Onlinevorhersage verfolgen.
Inferenz mit vLLM in Vertex AI mit der Standardvorhersageroute
In diesem Abschnitt erfahren Sie, wie Sie die Inferenz für das Llama 3.2 Vision-Modell in Vertex AI mit dem Standardvorhersagepfad einrichten. Sie verwenden die vLLM-Bibliothek für die effiziente Bereitstellung und interagieren mit dem Modell, indem Sie einen visuellen Prompt in Kombination mit Text senden.
Prüfen Sie zuerst, ob Ihr Modellendpunkt bereitgestellt und für Vorhersagen bereit ist.
Schritt 1: Prompt und Parameter definieren
In diesem Beispiel werden eine Bild-URL und ein Text-Prompt angegeben, die das Modell verarbeitet, um eine Antwort zu generieren.
 Abbildung 6: Beispiel für Bildeingabe für Prompts für Llama 3.2
Abbildung 6: Beispiel für Bildeingabe für Prompts für Llama 3.2
image_url = "https://images.pexels.com/photos/1254140/pexels-photo-1254140.jpeg"
raw_prompt = "This is a picture of"
# Reference prompt formatting guidelines here: https://www.Llama.com/docs/model-cards-and-prompt-formats/Llama3_2/#-base-model-prompt
prompt = f"<|begin_of_text|><|image|>{raw_prompt}"
Schritt 2: Prognoseparameter konfigurieren
Passen Sie die folgenden Parameter an, um die Antwort des Modells zu steuern:
max_tokens = 64
temperature = 0.5
top_p = 0.95
Schritt 3: Vorhersageanfrage vorbereiten
Richten Sie die Vorhersageanfrage mit der Bild-URL, dem Prompt und anderen Parametern ein.
instances = [
{
"prompt": prompt,
"multi_modal_data": {"image": image_url},
"max_tokens": max_tokens,
"temperature": temperature,
"top_p": top_p,
},
]
Schritt 4: Vorhersage treffen
Senden Sie die Anfrage an Ihren Vertex AI-Endpunkt und verarbeiten Sie die Antwort:
response = endpoints["vllm_gpu"].predict(instances=instances)
for raw_prediction in response.predictions:
prediction = raw_prediction.split("Output:")
print(prediction[1])
Wenn Sie ein Zeitlimitproblem (z. B. ServiceUnavailable: 503 Took too
long to respond when processing) haben, versuchen Sie, den Wert für max_tokens auf eine niedrigere Zahl wie 20 zu reduzieren, um die Reaktionszeit zu verkürzen.
Inferenz mit vLLM in Vertex AI mit OpenAI Chat Completion
In diesem Abschnitt wird beschrieben, wie Sie mit der OpenAI Chat Completions API in Vertex AI Inferenz für Llama 3.2 Vision-Modelle ausführen. Mit diesem Ansatz können Sie multimodale Funktionen nutzen, indem Sie sowohl Bilder als auch Textprompts an das Modell senden, um interaktivere Antworten zu erhalten.
Schritt 1: Llama 3.2 Vision Instruct-Modell bereitstellen
Führen Sie die Bereitstellungsfunktion mit dem konfigurierten Modell und den konfigurierten Einstellungen aus. Die Funktion gibt sowohl die Modell- als auch die Endpunktinstanzen zurück, die Sie für die Inferenz verwenden können.
base_model_name = "Llama-3.2-11B-Vision-Instruct"
hf_model_id = f"meta-llama/{base_model_name}"
model_name = common_util.get_job_name_with_datetime(prefix=f"{base_model_name}-serve-vllm")
model, endpoint = deploy_model_vllm(
model_name=model_name
model_id=hf_model_id,
base_model_id=hf_model_id,
service_account=SERVICE_ACCOUNT,
machine_type="a2-highgpu-1g",
accelerator_type="NVIDIA_TESLA_A100",
accelerator_count=1,
gpu_memory_utilization=0.9,
max_model_len=4096,
enforce_eager=True,
max_num_seqs=12,
)
Schritt 2: Endpunktressource konfigurieren
Richten Sie zuerst den Namen der Endpunktressource für Ihre Vertex AI-Bereitstellung ein.
ENDPOINT_RESOURCE_NAME = "projects/{}/locations/{}/endpoints/{}".format(
PROJECT_ID, REGION, endpoint.name
)
Schritt 3: OpenAI SDK und Authentifizierungsbibliotheken installieren
Wenn Sie Anfragen mit dem SDK von OpenAI senden möchten, müssen Sie die erforderlichen Bibliotheken installieren:
!pip install -qU openai google-auth requests
Schritt 4: Eingabeparameter für die Chat-Vervollständigung definieren
Richten Sie die Bild-URL und den Text-Prompt ein, die an das Modell gesendet werden. Passen Sie max_tokens und temperature an, um die Länge und Zufälligkeit der Antwort zu steuern.
user_image = "https://images.freeimages.com/images/large-previews/ab3/puppy-2-1404644.jpg"
user_message = "Describe this image?"
max_tokens = 50
temperature = 1.0
Schritt 5: Authentifizierung und Basis-URL einrichten
Rufen Sie Ihre Anmeldedaten ab und legen Sie die Basis-URL für API-Anfragen fest.
import google.auth
import openai
creds, project = google.auth.default()
auth_req = google.auth.transport.requests.Request()
creds.refresh(auth_req)
BASE_URL = (
f"https://{REGION}-aiplatform.googleapis.com/v1beta1/{ENDPOINT_RESOURCE_NAME}"
)
try:
if use_dedicated_endpoint:
BASE_URL = f"https://{DEDICATED_ENDPOINT_DNS}/v1beta1/{ENDPOINT_RESOURCE_NAME}"
except NameError:
pass
Schritt 6: Chat Completion-Anfrage senden
Senden Sie das Bild und den Textprompt mit der Chat Completions API von OpenAI an Ihren Vertex AI-Endpunkt:
client = openai.OpenAI(base_url=BASE_URL, api_key=creds.token)
model_response = client.chat.completions.create(
model="",
messages=[
{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": user_image}},
{"type": "text", "text": user_message},
],
}
],
temperature=temperature,
max_tokens=max_tokens,
)
print(model_response)
Schritt 7 (optional): Verbindung zu einem vorhandenen Endpunkt wiederherstellen
Verwenden Sie die Endpunkt-ID, um die Verbindung zu einem zuvor erstellten Endpunkt wiederherzustellen. Dieser Schritt ist nützlich, wenn Sie einen Endpunkt wiederverwenden möchten, anstatt einen neuen zu erstellen.
endpoint_name = ""
aip_endpoint_name = (
f"projects/{PROJECT_ID}/locations/{REGION}/endpoints/{endpoint_name}"
)
endpoint = aiplatform.Endpoint(aip_endpoint_name)
Diese Einrichtung bietet die Flexibilität, bei Bedarf zwischen neu erstellten und vorhandenen Endpunkten zu wechseln, was das Testen und die Bereitstellung vereinfacht.
Bereinigen
Um laufende Gebühren zu vermeiden und Ressourcen freizugeben, müssen Sie die bereitgestellten Modelle, Endpunkte und optional den für diesen Test verwendeten Speicher-Bucket löschen.
Schritt 1: Endpunkte und Modelle löschen
Mit dem folgenden Code wird die Bereitstellung jedes Modells aufgehoben und die zugehörigen Endpunkte werden gelöscht:
# Undeploy model and delete endpoint
for endpoint in endpoints.values():
endpoint.delete(force=True)
# Delete models
for model in models.values():
model.delete()
Schritt 2 (optional): Cloud Storage-Bucket löschen
Wenn Sie einen Cloud Storage-Bucket speziell für dieses Experiment erstellt haben, können Sie ihn löschen, indem Sie „delete_bucket“ auf „True“ setzen. Dieser Schritt ist optional, wird aber empfohlen, wenn der Bucket nicht mehr benötigt wird.
delete_bucket = False
if delete_bucket:
! gsutil -m rm -r $BUCKET_NAME
Wenn Sie diese Schritte ausführen, werden alle in dieser Anleitung verwendeten Ressourcen bereinigt, wodurch unnötige Kosten für das Experiment reduziert werden.
Häufige Probleme beheben
In diesem Abschnitt finden Sie Informationen zum Erkennen und Beheben häufiger Probleme, die bei der Bereitstellung und Inferenz von vLLM-Modellen in Vertex AI auftreten.
Log prüfen
Prüfen Sie die Logs, um die Ursache von Bereitstellungsfehlern oder unerwartetem Verhalten zu ermitteln:
- Zur Vertex AI Prediction Console wechseln:Rufen Sie in der Google Cloud Console die Vertex AI Prediction Console auf.
- Endpunkt auswählen:Klicken Sie auf den Endpunkt, bei dem Probleme auftreten. Der Status sollte angeben, ob die Bereitstellung fehlgeschlagen ist.
- Logs ansehen:Klicken Sie auf den Endpunkt und rufen Sie dann den Tab Logs auf oder klicken Sie auf Logs ansehen. Sie werden zu Cloud Logging weitergeleitet, wo die Logs für diesen Endpunkt und die Modellbereitstellung gefiltert angezeigt werden. Sie können auch direkt über den Cloud Logging-Dienst auf Logs zugreifen.
- Logs analysieren:Prüfen Sie die Logeinträge auf Fehlermeldungen, Warnungen und andere relevante Informationen. Zeitstempel ansehen, um Logeinträge bestimmten Aktionen zuzuordnen. Suchen Sie nach Problemen im Zusammenhang mit Ressourcenbeschränkungen (Arbeitsspeicher und CPU), Authentifizierungsproblemen oder Konfigurationsfehlern.
Häufiges Problem 1: CUDA-Fehler „Out of Memory“ (OOM) bei der Bereitstellung
CUDA-OOM-Fehler (Out-of-Memory) treten auf, wenn die Arbeitsspeichernutzung des Modells die verfügbare GPU-Kapazität überschreitet.
Für das Modell, das nur Text ausgibt, haben wir die folgenden Engine-Argumente verwendet:
base_model_name = "Meta-Llama-3.1-8B"
hf_model_id = f"meta-llama/{base_model_name}"
accelerator_type = "NVIDIA_L4"
accelerator_count = 1
machine_type = "g2-standard-12"
accelerator_count: int = 1
gpu_memory_utilization = 0.9
max_model_len = 4096
dtype = "auto"
max_num_seqs = 256
Für das multimodale Modell haben wir die folgenden Engine-Argumente verwendet:
base_model_name = "Llama-3.2-11B-Vision-Instruct"
hf_model_id = f"meta-llama/{base_model_name}"
accelerator_type = "NVIDIA_L4"
accelerator_count = 1
machine_type = "g2-standard-12"
accelerator_count: int = 1
gpu_memory_utilization = 0.9
max_model_len = 4096
dtype = "auto"
max_num_seqs = 12
Wenn Sie das multimodale Modell mit max_num_seqs = 256 bereitstellen, wie wir es beim reinen Textmodell getan haben, kann dies zu folgendem Fehler führen:
[rank0]: torch.OutOfMemoryError: CUDA out of memory. Tried to allocate 3.91 GiB. GPU 0 has a total capacity of 39.38 GiB of which 3.76 GiB is free. Including non-PyTorch memory, this process has 0 bytes memory in use. Of the allocated memory 34.94 GiB is allocated by PyTorch, and 175.15 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory Management (https://pytorch.org/docs/stable/notes/cuda.html#environment-variables)
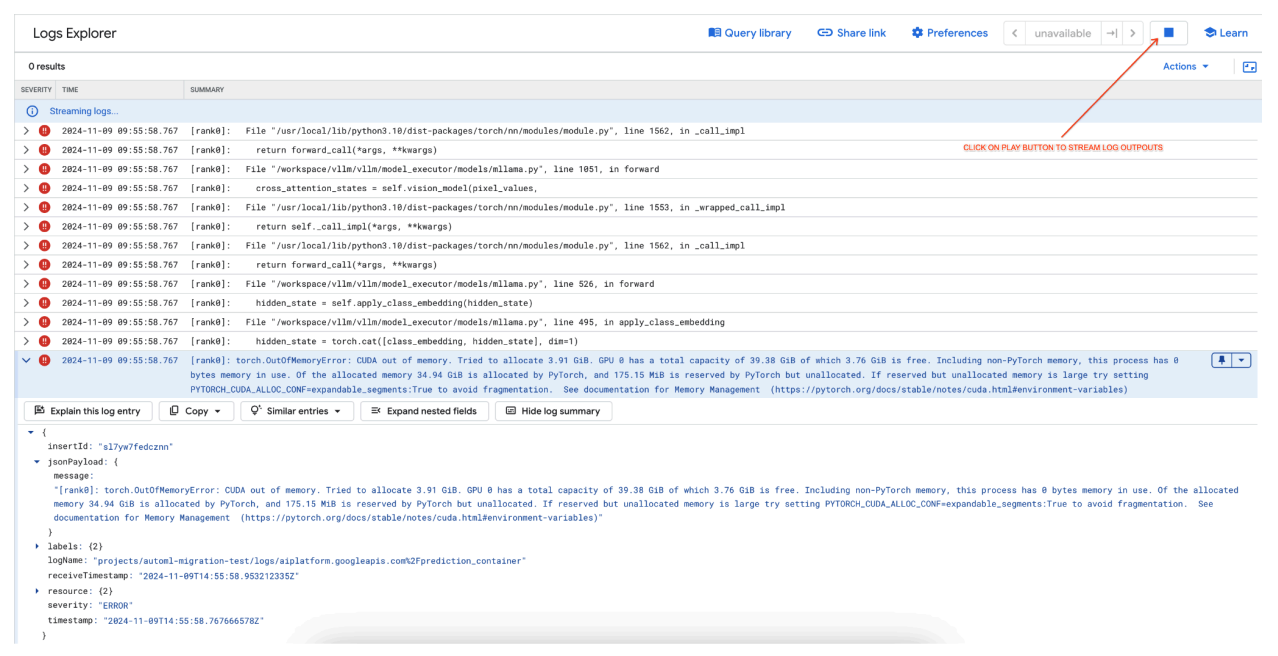 Abbildung 7: GPU-Fehlerprotokoll für „Out of Memory“ (OOM)
Abbildung 7: GPU-Fehlerprotokoll für „Out of Memory“ (OOM)
max_num_seqs und GPU-Arbeitsspeicher:
- Der Parameter
max_num_seqsdefiniert die maximale Anzahl gleichzeitiger Anfragen, die das Modell verarbeiten kann. - Jede vom Modell verarbeitete Sequenz belegt GPU-Arbeitsspeicher. Die gesamte Arbeitsspeichernutzung ist proportional zu
max_num_seqs× Arbeitsspeicher pro Sequenz. - Nur-Text-Modelle (z. B. Meta-Llama-3.1-8B) benötigen in der Regel weniger Speicher pro Sequenz als multimodale Modelle (z. B. Llama-3.2-11B-Vision-Instruct), die sowohl Text als auch Bilder verarbeiten.
Sehen Sie sich das Fehlerprotokoll an (Abbildung 8):
- Das Protokoll zeigt ein
torch.OutOfMemoryErrorbeim Versuch, Arbeitsspeicher auf der GPU zuzuweisen. - Der Fehler tritt auf, weil die Arbeitsspeichernutzung des Modells die verfügbare GPU-Kapazität überschreitet. Die NVIDIA L4-GPU hat 24 GB. Wenn Sie den Parameter
max_num_seqsfür das multimodale Modell zu hoch festlegen, kommt es zu einem Überlauf. - Das Log empfiehlt,
PYTORCH_CUDA_ALLOC_CONF=expandable_segments:Truefestzulegen, um die Speicherverwaltung zu verbessern. Das Hauptproblem ist jedoch die hohe Speicherauslastung.
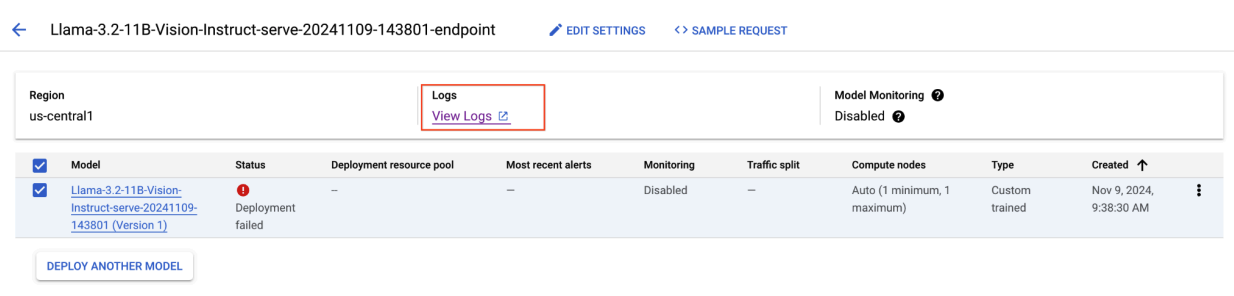 Abbildung 8: Fehler bei der Bereitstellung von Llama 3.2
Abbildung 8: Fehler bei der Bereitstellung von Llama 3.2
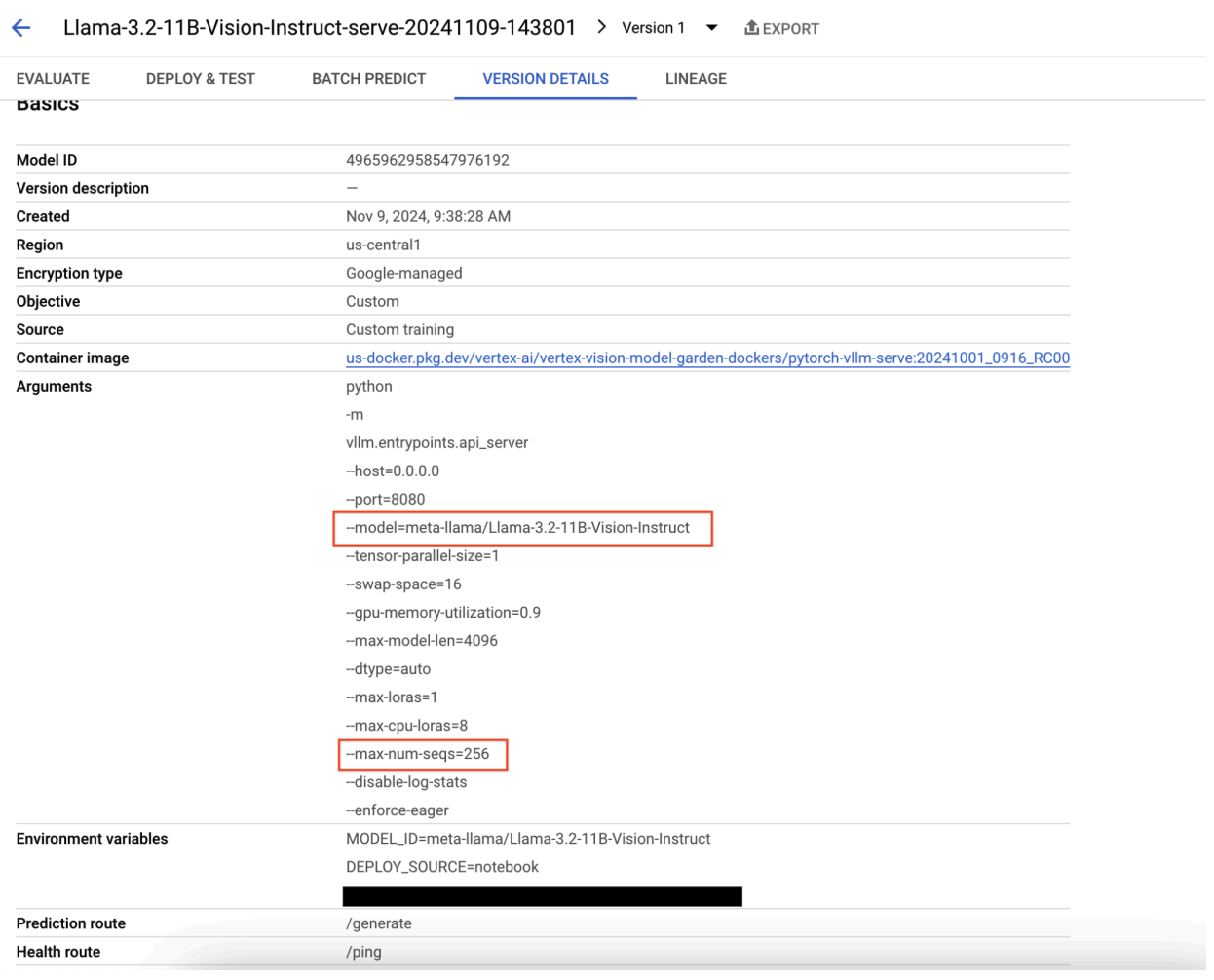 Abbildung 9: Feld „Model Version Details“ (Details zur Modellversion)
Abbildung 9: Feld „Model Version Details“ (Details zur Modellversion)
Um dieses Problem zu beheben, rufen Sie die Vertex AI Prediction Console auf und klicken Sie auf den Endpunkt. Der Status sollte angeben, dass die Bereitstellung fehlgeschlagen ist. Klicken Sie hier, um die Logs aufzurufen. Prüfen Sie, ob „max-num-seqs“ = 256 ist. Dieser Wert ist für Llama-3.2-11B-Vision-Instruct zu hoch. Ein angemessenerer Wert wäre 12.
Häufiges Problem 2: Hugging Face-Token erforderlich
Hugging Face-Tokenfehler treten auf, wenn für das Modell ein eingeschränkter Zugriff gilt und für den Zugriff auf das Modell gültige Anmeldedaten erforderlich sind.
Der folgende Screenshot zeigt einen Logeintrag im Log-Explorer von Google Cloud mit einer Fehlermeldung zum Zugriff auf das auf Hugging Face gehostete Modell Meta LLaMA-3.2-11B-Vision. Der Fehler weist darauf hin, dass der Zugriff auf das Modell eingeschränkt ist und eine Authentifizierung erforderlich ist, um fortzufahren. In der Meldung heißt es: „Cannot access gated repository for URL“ (Auf das Repository mit Zugriffsbeschränkung für die URL kann nicht zugegriffen werden). Das weist darauf hin, dass das Modell Zugriffsbeschränkungen hat und für den Zugriff entsprechende Authentifizierungsanmeldedaten erforderlich sind. Dieser Logeintrag kann bei der Behebung von Authentifizierungsproblemen bei der Arbeit mit eingeschränkten Ressourcen in externen Repositories hilfreich sein.
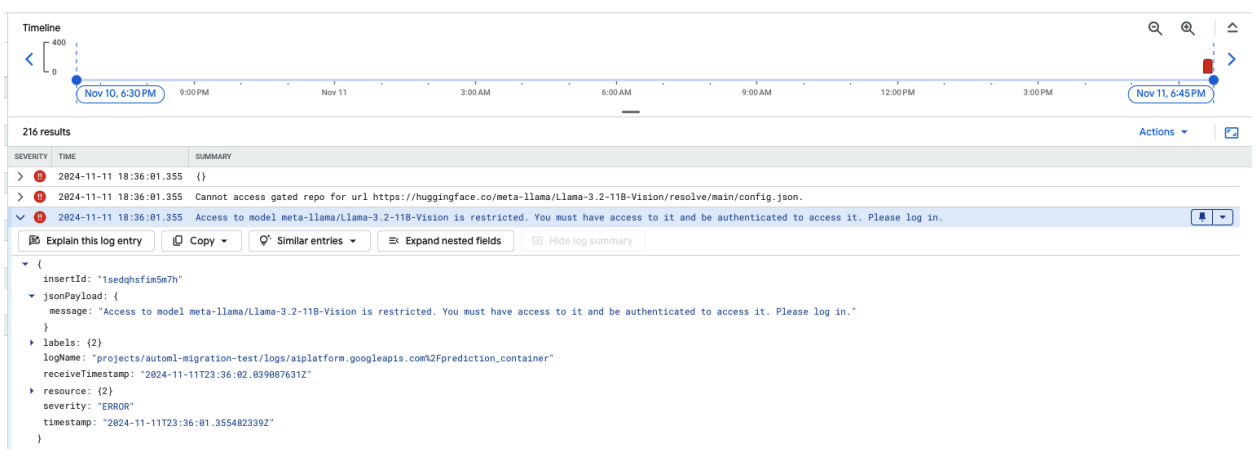 Abbildung 10: Hugging Face-Token-Fehler
Abbildung 10: Hugging Face-Token-Fehler
Prüfen Sie die Berechtigungen Ihres Hugging Face-Zugriffstokens, um dieses Problem zu beheben. Kopieren Sie das aktuelle Token und stellen Sie einen neuen Endpunkt bereit.
Häufiges Problem 3: Chatvorlage erforderlich
Fehler bei Chatvorlagen treten auf, wenn die Standard-Chatvorlage nicht mehr zulässig ist und eine benutzerdefinierte Chatvorlage angegeben werden muss, wenn der Tokenizer keine definiert.
Dieser Screenshot zeigt einen Logeintrag im Log-Explorer von Google Cloud, in dem aufgrund einer fehlenden Chatvorlage in der Transformers-Bibliothek Version 4.44 ein ValueError auftritt. Die Fehlermeldung weist darauf hin, dass die Standard-Chatvorlage nicht mehr zulässig ist und eine benutzerdefinierte Chatvorlage angegeben werden muss, wenn im Tokenizer keine definiert ist. Dieser Fehler weist auf eine kürzlich erfolgte Änderung in der Bibliothek hin, die eine explizite Definition einer Chatvorlage erfordert. Dies ist nützlich, um Probleme beim Bereitstellen von Chat-basierten Anwendungen zu beheben.
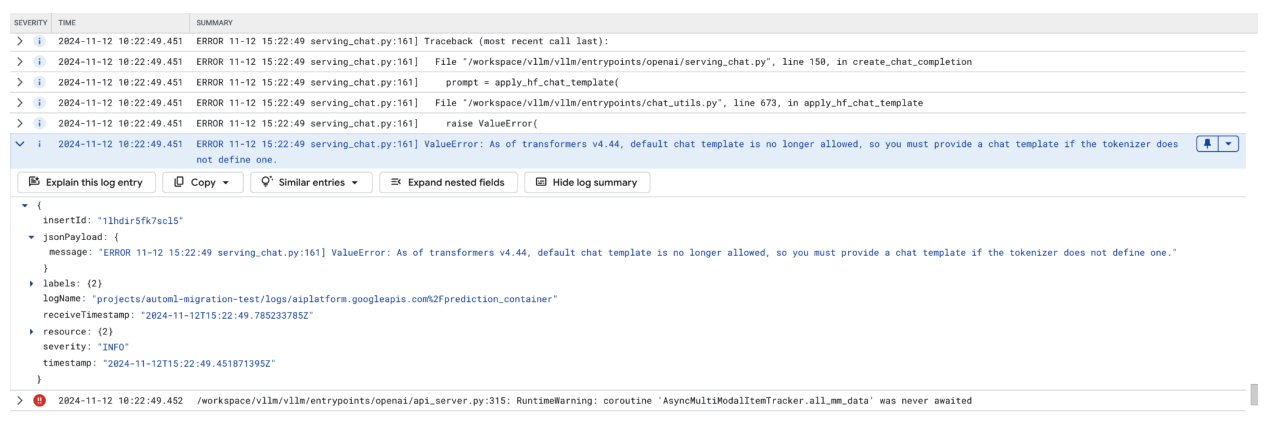 Abbildung 11: Chatvorlage erforderlich
Abbildung 11: Chatvorlage erforderlich
Um dies zu umgehen, müssen Sie bei der Bereitstellung mit dem Eingabeargument --chat-template eine Chatvorlage angeben. Beispielvorlagen finden Sie im vLLM-Beispielrepository.
Häufiges Problem 4: Maximale Sequenzlänge des Modells
Fehler bei der maximalen Sequenzlänge des Modells treten auf, wenn die maximale Sequenzlänge des Modells (4.096) größer ist als die maximale Anzahl von Tokens, die im KV-Cache gespeichert werden können (2.256).
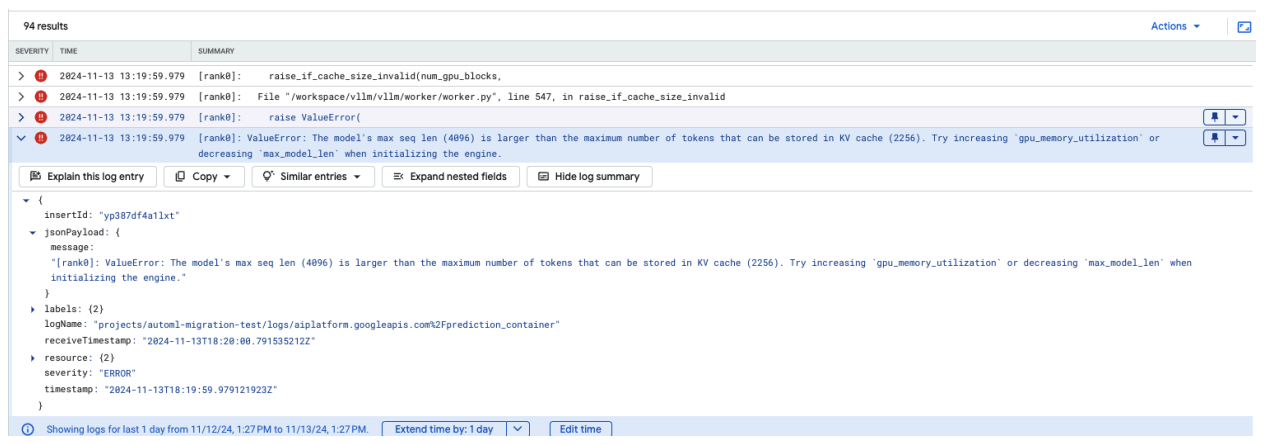 Abbildung 12: Max. Seq. Length zu groß
Abbildung 12: Max. Seq. Length zu groß
ValueError: Die maximale Sequenzlänge des Modells (4096) ist größer als die maximale Anzahl von Tokens, die im KV-Cache gespeichert werden können (2256). Versuchen Sie, gpu_memory_utilization zu erhöhen oder max_model_len zu verringern, wenn Sie die Engine initialisieren.
Um dieses Problem zu beheben, legen Sie „max_model_len“ auf 2.048 fest, was weniger als 2.256 ist. Eine weitere Lösung für dieses Problem besteht darin, mehr oder größere GPUs zu verwenden. Wenn Sie sich für die Verwendung von mehr GPUs entscheiden, muss „tensor-parallel-size“ entsprechend festgelegt werden.
Versionshinweise zu vLLM-Containern in Model Garden
Haupt-Releases
Standard-vLLM
Veröffentlichungsdatum |
Architektur |
vLLM-Version |
Container-URI |
|---|---|---|---|
| 17. Juli 2025 | ARM |
v0.9.2 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250717_0916_arm_RC01 |
| 10. Juli 2025 | x86 |
v0.9.2 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250710_0916_RC01 |
| 20. Juni 2025 | x86 |
Ab Version 0.9.1, Commit |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250620_0916_RC01 |
| 11. Juni 2025 | x86 |
v0.9.1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250611_0916_RC01 |
| 2. Juni 2025 | x86 |
v0.9.0 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250601_0916_RC01 |
| 6. Mai 2025 | x86 |
v0.8.5.post1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250506_0916_RC01 |
| 29. April 2025 | x86 |
v0.8.4 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250429_0916_RC01, 20250430_0916_RC00_maas |
| 17. April 2025 | x86 |
v0.8.4 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250417_0916_RC01 |
| 10. April 2025 | x86 |
Ab Version 0.8.3, Commit |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250410_0917_RC01 |
| 7. April 2025 | x86 |
v0.8.3 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250407_0917_RC01, 20250407_0917_RC0120250429_0916_RC00_maas |
| 7. April 2025 | x86 |
v0.8.1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250404_0916_RC01 |
| 5. April 2025 | x86 |
Ab Version 0.8.2, Commit |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250405_1205_RC01 |
| 31. März 2025 | x86 |
v0.8.1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250401_0916_RC01 |
| 26. März 2025 | x86 |
v0.8.1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250327_0916_RC01 |
| 23. März 2025 | x86 |
v0.8.1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250324_0916_RC01 |
| 21. März 2025 | x86 |
v0.8.1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250321_0916_RC01 |
| 11. März 2025 | x86 |
Nach v0.7.3, Commit |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250312_0916_RC01 |
| 3. März 2025 | x86 |
v0.7.2 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250304_0916_RC01 |
| 14. Januar 2025 | x86 |
v0.6.4.post1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250114_0916_RC00_maas |
| 2. Dezember 2024 | x86 |
v0.6.4.post1 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20241202_0916_RC00_maas |
| 12. November 2024 | x86 |
v0.6.2 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20241112_0916_RC00_maas |
| 16. Oktober 2024 | x86 |
v0.6.2 |
us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20241016_0916_RC00_maas |
Optimiertes vLLM
Veröffentlichungsdatum |
Architektur |
Container-URI |
|---|---|---|
| 21. Januar 2025 | x86 |
us-docker.pkg.dev/vertex-ai-restricted/vertex-vision-model-garden-dockers/pytorch-vllm-optimized-serve:20250121_0835_RC00 |
| 29. Oktober 2024 | x86 |
us-docker.pkg.dev/vertex-ai-restricted/vertex-vision-model-garden-dockers/pytorch-vllm-optimized-serve:20241029_0835_RC00 |
Zusätzliche Releases
Die vollständige Liste der VMG-Standard-vLLM-Container-Releases finden Sie auf der Artifact Registry-Seite.
Releases für vLLM-TPU im experimentellen Status sind mit <yyyymmdd_hhmm_tpu_experimental_RC00> gekennzeichnet.