Configurable safety filters
Safety attribute confidence and severity scoring
Content processed through the Vertex AI PaLM API is assessed against a list of safety attributes, which include "harmful categories" and topics that can be considered sensitive.
Each safety attribute has an associated confidence score between 0.0 and 1.0, rounded to one decimal place, reflecting the likelihood of the input or response belonging to a given category.
Four of these safety attributes (harassment, hate speech, dangerous content, and sexually explicit), are assigned a safety rating (severity level) and a severity score ranging from 0.0 to 1.0, rounded to one decimal place. These ratings and scores reflect the predicted severity of the content belonging to a given category.
Sample response
{
"predictions": [
{
"safetyAttributes": {
"categories": [
"Derogatory",
"Toxic",
"Violent",
"Sexual",
"Insult",
"Profanity",
"Death, Harm & Tragedy",
"Firearms & Weapons",
"Public Safety",
"Health",
"Religion & Belief",
"Illicit Drugs",
"War & Conflict",
"Politics",
"Finance",
"Legal"
],
"scores": [
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1,
0.1
],
"safetyRatings": [
{"category": "Hate Speech", "severity": "NEGLIGIBLE", "severityScore": 0.0,"probabilityScore": 0.1},
{"category": "Dangerous Content", "severity": "LOW", "severityScore": 0.3, "probabilityScore": 0.1},
{"category": "Harassment", "severity": "MEDIUM", "severityScore": 0.6, "probabilityScore": 0.1},
{"category": "Sexually Explicit", "severity": "HIGH", "severityScore": 0.9, "probabilityScore": 0.1}
],
"blocked": false
},
"content": "<>"
}
]
}
Note: Categories with a score that rounds to 0.0 are omitted in the response. This sample response is for illustrative purposes only.
Sample response when blocked
{
"predictions": [
{
"safetyAttributes": {
"blocked": true,
"errors": [
150,
152,
250
]
},
"content": ""
}
]
}
Safety attribute descriptions
| Safety Attribute | Description |
|---|---|
| Derogatory | Negative or harmful comments targeting identity and/or protected attributes. |
| Toxic | Content that is rude, disrespectful, or profane. |
| Sexual | Contains references to sexual acts or other lewd content. |
| Violent | Describes scenarios depicting violence against an individual or group, or general descriptions of gore. |
| Insult | Insulting, inflammatory, or negative comment towards a person or a group of people. |
| Profanity | Obscene or vulgar language such as cursing. |
| Death, Harm & Tragedy | Human deaths, tragedies, accidents, disasters, and self-harm. |
| Firearms & Weapons | Content that mentions knives, guns, personal weapons, and accessories such as ammunition, holsters, etc. |
| Public Safety | Services and organizations that provide relief and ensure public safety. |
| Health | Human health, including: Health conditions, diseases, and disorders; medical therapies, medication, vaccination, and medical practices; resources for healing, including support groups. |
| Religion & Belief | Belief systems that deal with the possibility of supernatural laws and beings; religion, faith, belief, spiritual practice, churches, and places of worship. Includes astrology and the occult. |
| Illicit Drugs | Recreational and illicit drugs; drug paraphernalia and cultivation, headshops, and more. Includes medicinal use of drugs typically used recreationally (for example, marijuana). |
| War & Conflict | War, military conflicts, and major physical conflicts involving large numbers of people. Includes discussion of military services, even if not directly related to a war or conflict. |
| Finance | Consumer and business financial services, such as banking, loans, credit, investing, insurance, and more. |
| Politics | Political news and media; discussions of social, governmental, and public policy. |
| Legal | Law-related content, to include: law firms, legal information, primary legal materials, paralegal services, legal publications and technology, expert witnesses, litigation consultants, and other legal service providers. |
Safety attributes with safety ratings
| Safety Attribute | Definition | Levels |
|---|---|---|
| Hate Speech | Negative or harmful comments targeting identity and/or protected attributes. | High, Medium, Low, Negligible |
| Harassment | Malicious, intimidating, bullying, or abusive comments targeting another individual. | High, Medium, Low, Negligible |
| Sexually Explicit | Contains references to sexual acts or other lewd content. | High, Medium, Low, Negligible |
| Dangerous Content | Promotes or enables access to harmful goods, services, and activities. | High, Medium, Low, Negligible |
Safety thresholds
Safety thresholds are in place for the following safety attributes:
- Hate Speech
- Harassment
- Sexually Explicit
- Dangerous Content
Google blocks model responses that exceed the designated severity scores for these safety attributes. To request the ability to modify a safety threshold, contact your Google Cloud account team.
Testing your confidence and severity thresholds
You can test Google's safety filters and define confidence thresholds that are right for your business. By using these thresholds, you can take comprehensive measures to detect content that violates Google's usage policies or terms of service and take appropriate action.
The confidence scores are predictions only, and you shouldn't depend on the scores for reliability or accuracy. Google is not responsible for interpreting or using these scores for business decisions.
Important: Probability and Severity
With the exception of the four safety attributes with safety ratings, the PaLM API safety filters confidence scores are based on the probability of content being unsafe and not the severity. This is important to consider because some content can have low probability of being unsafe even though the severity of harm could still be high. For example, comparing the sentences:
- The robot punched me.
- The robot slashed me up.
Sentence 1 might cause a higher probability of being unsafe but you might consider sentence 2 to be a higher severity in terms of violence.
Given this, it is important customers carefully test and consider what the appropriate level of blocking is needed to support their key use cases while minimizing harm to end users.
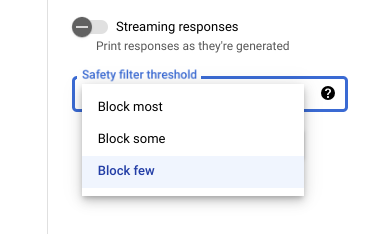
Safety settings in Vertex AI Studio
With the adjustable safety filter threshold, you can adjust how likely you are
to see responses that could be harmful. Model responses are blocked based on the
probability that it contains harassment, hate speech, dangerous content, or
sexually explicit content. The safety filter setting is located on the right
side of the prompt field in Vertex AI Studio. You can choose from
three options: block most, block some, and
block few.
Citation filter
Our generative code features are intended to produce original content and not replicate existing content at length. We've designed our systems to limit the chances of this occurring, and continuously improve how these systems function. If these features do directly quote at length from a web page, they cite that page.
Sometimes the same content can be found on multiple web pages and we attempt to point you to a popular source. In the case of citations to code repositories, the citation might also reference an applicable open source license. Complying with any license requirements is your responsibility.
To learn about the metadata of the citation filter, see the Citation API reference.
Safety errors
Safety error codes are three-digit codes that represent the reason that a
prompt or response was blocked. The first digit is a prefix that
indicates whether the code applies to the prompt or the response, and the
remaining digits identify the reason that the prompt or response was blocked.
For example, an error code of 251 indicates that the response was blocked
due to an issue with hate speech content in the response from the model.
Multiple error codes can be returned in a single response.
If you encounter errors that block the content in your response from the model
(prefix = 2, for example 250),
adjust the temperature setting in your request. This helps generate a
different set of responses with less of a chance of being blocked.
Error code prefix
The error code prefix is the first digit of the error code.
| 1 | The error code applies to the prompt sent to the model. |
| 2 | The error code applies to the response from the model. |
Error code reason
The error code reason is the second and third digits of the error code.
Error codes reasons that begin with 3 or 4 indicate prompts or responses
blocked because the confidence threshold for a safety attribute violation was
met.
Error codes reasons that begin with 5 indicate prompts or responses where
unsafe content was found.
| 10 | The response was blocked because of a quality
issue or a parameter setting affecting citation metadata. This applies only to
responses from the model. That is, Citation checker identifies quality issues or issues stemming from a
parameter setting. Try increasing the For more information, see Citation filter. |
| 20 | The supplied or returned language is unsupported. For a list of supported languages, see Language support. |
| 30 | The prompt or response was blocked because it was found to be potentially harmful. A term is included from the terminology blocklist. Rephrase your prompt. |
| 31 | The content might include Sensitive Personally Identifiable Information (SPII). Rephrase your prompt. |
| 40 | The prompt or response was blocked because it was found to be potentially harmful. The content violates SafeSearch settings. Rephrase your prompt. |
| 50 | The prompt or response was blocked because it might contain sexually explicit content. Rephrase your prompt. |
| 51 | The prompt or response was blocked because it might contain hate speech content. Rephrase your prompt. |
| 52 | The prompt or response was blocked because it might contain harassment content. Rephrase your prompt. |
| 53 | The prompt or response was blocked because it might contain dangerous content. Rephrase your prompt. |
| 54 | The prompt or response was blocked because it might contain toxic content. Rephrase your prompt. |
| 00 | Reason unknown. Rephrase your prompt. |
What's next
- Learn more about responsible AI.
- Learn about data governance.