クエリ実行プランで説明しているとおり、SQL コンパイラは SQL ステートメントをクエリ実行プランに変換します。クエリ実行プランはクエリの結果を取得するために使用されます。このページでは、Spanner が効率的な実行プランを見つけるのに役立つ SQL ステートメントを作成するためのおすすめの方法について説明します。
このページに示す SQL ステートメントの例では次のサンプル スキーマを使用します。
GoogleSQL
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
BirthDate DATE
) PRIMARY KEY (SingerId);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
ReleaseDate DATE
) PRIMARY KEY (SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
SQL の詳細なリファレンスについては、ステートメントの構文、関数と演算子、語彙の構造と構文をご覧ください。
PostgreSQL
CREATE TABLE Singers (
SingerId BIGINT PRIMARY KEY,
FirstName VARCHAR(1024),
LastName VARCHAR(1024),
SingerInfo BYTEA,
BirthDate TIMESTAMPTZ
);
CREATE TABLE Albums (
SingerId BIGINT NOT NULL,
AlbumId BIGINT NOT NULL,
AlbumTitle VARCHAR(1024),
ReleaseDate DATE,
PRIMARY KEY(SingerId, AlbumId),
FOREIGN KEY (SingerId) REFERENCES Singers(SingerId)
) INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
詳細については、Spanner の PostgreSQL 言語をご覧ください。
クエリ パラメータを使用する
Spanner は、パフォーマンスを向上させるクエリ パラメータをサポートしています。また、ユーザー入力からクエリが作成される際の SQL インジェクションを防止できます。クエリ パラメータは任意の式の代わりに使用できますが、識別子、列名、テーブル名、またはクエリの他の部分の代わりに使用することはできません。
パラメータは、リテラル値が期待されている場所であればどこにでも現れることができます。1 つの SQL ステートメントで同じパラメータ名を複数回使用できる。
まとめると、クエリ パラメータは次の方法でのクエリ実行をサポートします。
- 事前に最適化されたプラン: パラメータを使用するクエリは、パラメータ化によって Spanner での実行プランのキャッシュ保存が容易になるため、呼び出しごとに高速に実行できます。
- 簡単なクエリ比較: 文字列の値をクエリ パラメータに指定する場合、その文字列をエスケープする必要はありません。クエリ パラメータを使用すると、構文エラーのリスクが少なくなります。
- セキュリティ: クエリ パラメータでさまざまな SQL インジェクション攻撃から保護することによって、クエリの安全性が高まります。クエリをユーザーの入力から作成する場合に、この保護は特に重要になります。
Spanner がクエリを実行する仕組みを理解する
Spanner では、取得するデータを指定する宣言型 SQL ステートメントを使用してデータベースでクエリを実行できます。Spanner での結果の取得方法を理解するには、クエリの実行プランを調べます。クエリ実行プランではクエリの各ステップに関連付けられた計算コストが表示されます。これにより、クエリのパフォーマンスに関する問題をデバッグし、クエリを最適化できます。詳細については、クエリ実行プランをご覧ください。
クエリ実行プランは、 Google Cloud コンソールまたはクライアント ライブラリで取得できます。
Google Cloud コンソールを使用して特定のクエリのクエリ実行プランを取得する手順は次のとおりです。
[Spanner インスタンス] ページを開きます。
クエリを実行する Spanner インスタンスとデータベースの名前を選択します。
左側のナビゲーション パネルで [Spanner Studio] をクリックします。
テキスト フィールドにクエリを入力し、[クエリを実行] をクリックします。
[説明] をクリックします。
Google Cloud コンソールにクエリの視覚的な実行プランが表示されます。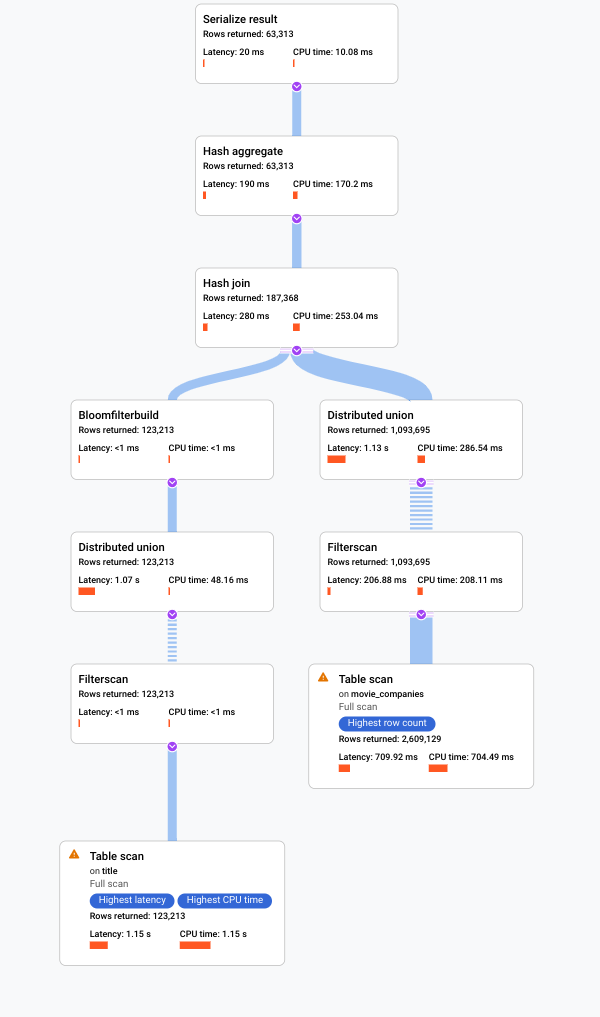
視覚的なプランを理解し、クエリのデバッグに使用する方法については、クエリプランの可視化ツールを使用したクエリのチューニングをご覧ください。
また、過去のクエリプランのサンプルを表示し、特定のクエリの時間の経過に伴うクエリのパフォーマンスを比較することもできます。詳細については、サンプリングされたクエリプランをご覧ください。
セカンダリ インデックスを使用する
他のリレーショナル データベースと同様に、Spanner でもセカンダリ インデックスが提供されます。これによって、SQL ステートメントまたは Spanner の読み取りインターフェースを使用してデータを取得できます。インデックスからデータを取得する最も一般的な方法は、Spanner Studio を使用することです。SQL クエリでセカンダリ インデックスを使用すると、Spanner が結果を取得する方法を指定できます。セカンダリ インデックスを指定することで、クエリを高速化できる場合があります。
たとえば、特定の姓のすべての歌手の ID をフェッチするとします。このような SQL クエリを作成する 1 つの方法は次のとおりです。
SELECT s.SingerId
FROM Singers AS s
WHERE s.LastName = 'Smith';
このクエリは期待どおりの結果を返しますが、結果を返すまでに時間がかかる場合があります。タイミングは Singers テーブル内の行数と述語 WHERE s.LastName = 'Smith' の数に応じて異なります。読み取り先の LastName 列を含むセカンダリ インデックスがない場合、クエリプランは Singers テーブル全体を読み取り、述語に一致する行を検索します。テーブル全体の読み取りはテーブル全体のスキャンと呼ばれます。テーブルにその姓を持つSingersの割合のごく一部しか含まれていない場合、テーブル全体のスキャンで結果を取得するのは高コストになります。
姓の列についてセカンダリ インデックスを定義すると、クエリのパフォーマンスを向上させることができます。
CREATE INDEX SingersByLastName ON Singers (LastName);
セカンダリ インデックス SingersByLastName にはインデックス登録されたテーブル列 LastName と主キー列 SingerId が含まれるため、Spanner で Singers テーブル全体にスキャンを実行する代わりに、非常に小さいインデックス テーブルからすべてのデータをフェッチできます。
このシナリオでは、クエリを実行するとき(データベースの作成から 3 日間がすぎている場合。新しいデータベースに関する注意事項を参照)Spanner は自動的にセカンダリ インデックス SingersByLastName を使用します。しかし、FROM 句でインデックス ディレクティブを指定して、そのインデックスを使用するように Spanner に明示的に指示する方法をおすすめします。
GoogleSQL
SELECT s.SingerId
FROM Singers@{FORCE_INDEX=SingersByLastName} AS s
WHERE s.LastName = 'Smith';
PostgreSQL
SELECT s.SingerId
FROM Singers /*@ FORCE_INDEX=SingersByLastName */ AS s
WHERE s.LastName = 'Smith';
歌手の名前と ID を取得する場合について考えてみましょう。インデックスに FirstName 列が含まれていないため、前の例と同様に、インデックス ディレクティブを指定する必要があります。
GoogleSQL
SELECT s.SingerId, s.FirstName
FROM Singers@{FORCE_INDEX=SingersByLastName} AS s
WHERE s.LastName = 'Smith';
PostgreSQL
SELECT s.SingerId, s.FirstName
FROM Singers /*@ FORCE_INDEX=SingersByLastName */ AS s
WHERE s.LastName = 'Smith';
Spanner でクエリプランの実行時にテーブル全体のスキャンを実行する必要がないため、この場合でもインデックスの使用によってパフォーマンス上の利点を得られます。代わりに、SingersByLastName インデックスから述語を満たす行のサブセットを選択し、ベーステーブル Singers からルックアップを実行して、行のサブセットのみを対象として名前をフェッチします。
Spanner でベーステーブルから行を取得する必要がまったくない場合、FirstName 列のコピーをインデックス自体に格納できます。
GoogleSQL
CREATE INDEX SingersByLastName ON Singers (LastName) STORING (FirstName);
PostgreSQL
CREATE INDEX SingersByLastName ON Singers (LastName) INCLUDE (FirstName);
このように STORING 句(GoogleSQL 言語)または INCLUDE 句(PostgreSQL 言語)を使用すると、追加のストレージ費用がかかりますが、次のような利点があります。
- インデックスを使用し、
STORINGまたはINCLUDE句に保存された列を選択する SQL クエリでは、ベーステーブルへの余分な結合が不要になります。 - インデックスを使用する読み取り呼び出しで、
STORINGまたはINCLUDE句に保存された列を読み取ることができます。
上述の例は、クエリの WHERE 句によって選択された行を、セカンダリ インデックスを使用してすばやく特定できる場合、セカンダリ インデックスでクエリをどれだけ高速化できるかを示しています。
セカンダリ インデックスによってパフォーマンスを向上させることができるもう 1 つのシナリオは、順序付けされた結果を返す特定のクエリの場合です。たとえば、すべてのアルバム タイトルとそれらのリリース日をフェッチし、リリース日の昇順、アルバム タイトルの降順でそれらを返すとします。SQL クエリは次のように作成できます。
SELECT a.AlbumTitle, a.ReleaseDate
FROM Albums AS a
ORDER BY a.ReleaseDate, a.AlbumTitle DESC;
セカンダリ インデックスがない場合、このクエリには高コストになりがちな実行プランの並べ替えステップが必要となります。このセカンダリ インデックスを定義して、クエリ実行を高速化できます。
CREATE INDEX AlbumsByReleaseDateTitleDesc on Albums (ReleaseDate, AlbumTitle DESC);
セカンダリ インデックスを使用するようにクエリを書き換えます。
GoogleSQL
SELECT a.AlbumTitle, a.ReleaseDate
FROM Albums@{FORCE_INDEX=AlbumsByReleaseDateTitleDesc} AS a
ORDER BY a.ReleaseDate, a.AlbumTitle DESC;
PostgreSQL
SELECT a.AlbumTitle, a.ReleaseDate
FROM Albums /*@ FORCE_INDEX=AlbumsByReleaseDateTitleDesc */ AS s
ORDER BY a.ReleaseDate, a.AlbumTitle DESC;
このクエリとインデックス定義は次の両方の基準を満たすものです。
- 並べ替えステップを削除するには、
ORDER BY句の列リストがインデックス キーリストの接頭辞であることを確認します。 - 不足している列を取得するためにベーステーブルから結合しないようにするため、クエリで使用されるテーブル内のすべての列をインデックスでカバーするようにします。
セカンダリ インデックスによって、よく使用するクエリを高速化できますが、セカンダリ インデックスを追加すると、各セカンダリ インデックスでは一般的に各 commit 内に追加のノードを含める必要があるため、commit オペレーションのレイテンシが追加される可能性があります。ほとんどのワークロードで、セカンダリ インデックスを少なくすることをおすすめします。ただし、読み取りまたは書き込みの待ち時間を重視するかどうか、ワークロードで最も重要なオペレーションはどれかを検討する必要があります。ワークロードのベンチマークを実行して、期待どおりのパフォーマンスが得られることを確認します。
セカンダリ インデックスの詳細なリファレンスについては、セカンダリ インデックスをご覧ください。
スキャンを最適化する
特定の Spanner クエリでは、一般的な行指向型の処理方法ではなく、データのスキャン時にバッチ指向型の処理方法を使用した方がメリットが得られます。スキャンを一括処理することで、大量のデータを一度に処理するためのより効率的な方法になり、クエリで CPU 使用率とレイテンシの低減を実現できます。
Spanner のスキャン オペレーションは、常に行指向メソッドで実行が開始されます。この間、Spanner はいくつかのランタイム指標を収集します。その後、Spanner はこれらの指標の結果に基づいて一連のヒューリスティックを適用し、最適なスキャン方法を決定します。適切なタイミングで、Spanner はバッチ指向型の処理方法に切り替えて、スキャンのスループットとパフォーマンスを向上させることができます。
一般的なユースケース
次の特性を持つクエリは通常、バッチ指向型の処理を使用することでメリットが得られます。
- 更新頻度の低いデータに対する大規模なスキャン。
- 固定幅の列に対する述語を使用したスキャン。
- シーク数が多いスキャン。(シークはインデックスを使用してレコードを取得します。)
パフォーマンスの向上がないユースケース
すべてのクエリがバッチ指向型の処理からメリットを得られるわけではありません。次のクエリタイプは、行指向型のスキャン処理の方がパフォーマンスが向上します。
- ポイント検索クエリ: 1 行のみをフェッチするクエリ。
- 小規模なスキャンクエリ: シーク数が多くない限り、数行のみをスキャンするテーブル スキャン。
LIMITを使用するクエリ。- チャーンレートが高いデータを読み取るクエリ: データ読み取りの 10% 以上が頻繁に更新されるクエリ。
- 大きな値を含む行でのクエリ: 値の大きい行とは、1 つの列に 32,000 バイトを超える値(圧縮前)を含む行のことです。
クエリで使用されるスキャン方法を確認する
クエリでバッチ指向型の処理、行指向型の処理が使用されるか、これらの 2 つのスキャン方法が自動的に切り替えられるかを確認するには、次の操作を行います。
Google Cloud コンソールの [Spanner インスタンス] ページに移動します。
調査するクエリを含むインスタンスの名前をクリックします。
[データベース] テーブルで、調査するクエリを含むデータベースをクリックします。
ナビゲーション メニューで [Spanner Studio] をクリックします。
[新しい SQL エディタタブ] または [新しいタブ] をクリックし、新しいタブを開きます。
クエリエディタが表示されたら、クエリを入力します。
[実行] をクリックします。
Spanner がクエリを実行し、結果を表示します。
クエリエディタの下にある [説明] タブをクリックします。
Spanner にクエリ実行プランの可視化ツールが表示されます。グラフの各カードはイテレータを表します。
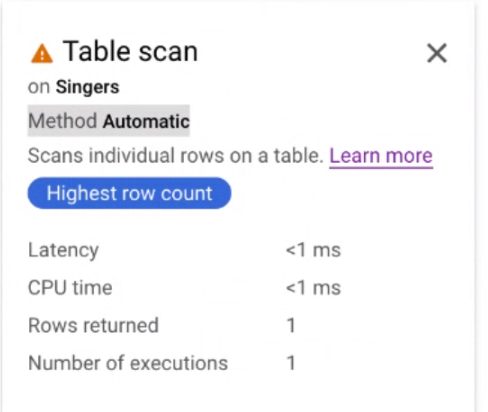
イテレータ カード [テーブル スキャン] をクリックして、情報パネルを開きます。
情報パネルには、選択したスキャンに関するコンテキスト情報が表示されます。このカードにスキャン方法が表示されます。[自動] は、Spanner がスキャン方法を決定することを示します。その他の使用可能な値には、バッチ指向型の処理用の Batch や、行指向型の処理用の Row があります。
クエリで使用されるスキャン方法を適用する
クエリのパフォーマンスを最適化するために、Spanner はクエリに最適なスキャン方法を選択します。このデフォルトのスキャン方法を使用することをおすすめします。ただし、特定の種類のスキャン方法を適用する必要がある場合もあります。
バッチ指向型スキャンを適用する
バッチ指向型スキャンは、テーブルレベルとステートメント レベルで適用できます。
バッチ指向型スキャン方法をテーブルレベルで適用するには、クエリでテーブルヒントを使用します。
GoogleSQL
SELECT ...
FROM (t1@{SCAN_METHOD=BATCH} JOIN t2 ON ...)
WHERE ...
PostgreSQL
SELECT ...
FROM (t1/*@ scan_method=batch */ JOIN t2 on ...)
WHERE ...
バッチ指向型スキャン方法をステートメント レベルで適用するには、クエリでステートメント ヒントを使用します。
GoogleSQL
@{SCAN_METHOD=BATCH}
SELECT ...
FROM ...
WHERE ...
PostgreSQL
/*@ scan_method=batch */
SELECT ...
FROM ...
WHERE ...
自動スキャンを無効にして行指向型スキャンを適用する
Spanner によって設定された自動スキャン方法を無効にすることはおすすめしませんが、レイテンシの診断などのトラブルシューティングを目的として、自動スキャン方法を無効にして行指向型のスキャン方法を使用することもできます。
自動スキャン方法を無効にして、テーブルレベルでの行処理を適用するには、クエリでテーブルヒントを使用します。
GoogleSQL
SELECT ...
FROM (t1@{SCAN_METHOD=ROW} JOIN t2 ON ...)
WHERE ...
PostgreSQL
SELECT ...
FROM (t1/*@ scan_method=row */ JOIN t2 on ...)
WHERE ...
自動スキャン方法を無効にして、ステートメント レベルでの行処理を適用するには、クエリでステートメント ヒントを使用します。
GoogleSQL
@{SCAN_METHOD=ROW}
SELECT ...
FROM ...
WHERE ...
PostgreSQL
/*@ scan_method=row */
SELECT ...
FROM ...
WHERE ...
クエリ実行を最適化する
スキャンを最適化するだけでなく、ステートメント レベルで実行方法を適用してクエリ実行を最適化することもできます。これは一部の演算子に対してのみ機能し、スキャン演算子によってのみ使用されるスキャン方法とは独立しています。
デフォルトでは、ほとんどの演算子は行指向の方法で実行され、データを 1 行ずつ処理します。ベクトル化演算子はバッチ指向の方法で実行され、実行スループットとパフォーマンスが向上します。これらの演算子は、データを一度に 1 ブロックずつ処理します。演算子が多くの行を処理する必要がある場合は、通常、バッチ指向の実行方法の方が効率的です。
実行方法とスキャン方法
クエリの実行方法は、クエリのスキャン方法とは独立しています。クエリヒントでは、これらの方法を設定できるのは 1 つか両方、またはどちらも設定できません。
クエリ実行方法は、クエリ演算子が中間結果を処理する方法と演算子同士が相互作用する方法を指します。一方、スキャン方法は、スキャン演算子が Spanner のストレージ レイヤとやり取りする方法を指します。
クエリで使用される実行方法を適用する
クエリのパフォーマンスを最適化するために、Spanner はさまざまなヒューリスティクスに基づいてクエリの最適な実行方法を選択します。このデフォルトの実行方法を使用することをおすすめします。ただし、特定の種類の実行方法を適用する必要がある場合もあります。
実行方法はステートメント レベルで適用できます。EXECUTION_METHOD はディレクティブではなくクエリヒントです。最終的には、クエリ オプティマイザーが個々の演算子に使用する方法を決定します。
バッチ指向の実行方法をステートメント レベルで適用するには、クエリでステートメント ヒントを使用します。
GoogleSQL
@{EXECUTION_METHOD=BATCH}
SELECT ...
FROM ...
WHERE ...
PostgreSQL
/*@ execution_method=batch */
SELECT ...
FROM ...
WHERE ...
Spanner によって設定された自動実行方法を無効にすることはおすすめしませんが、レイテンシの診断などのトラブルシューティングを目的として、自動実行方法を無効にして行指向型のスキャン方法を使用することもできます。
自動実行方法を無効にして、ステートメント レベルで行指向の実行方法を適用するには、クエリでステートメント ヒントを使用します。
GoogleSQL
@{EXECUTION_METHOD=ROW}
SELECT ...
FROM ...
WHERE ...
PostgreSQL
/*@ execution_method=row */
SELECT ...
FROM ...
WHERE ...
有効になっている実行方法を確認する
すべての Spanner 演算子が、バッチ指向と行指向の両方の実行方法をサポートしているわけではありません。クエリ実行プランの可視化ツールでは、演算子ごとにイテレータ カードに実行方法が表示されます。実行方法がバッチ指向の場合、[バッチ] と表示されます。行方向の場合は [行] と表示されます。
クエリ内の演算子が異なる実行方法を使用して実行される場合、実行方法のアダプタ DataBlockToRowAdapter と RowToDataBlockAdapter が演算子の間に表示され、実行方法の変更が示されます。
範囲キーの検索を最適化する
SQL クエリの一般的な用途は、既知のキーのリストに基づいて、Spanner から複数行を読み取ることです。
次のベスト プラクティスは、キーの範囲でデータをフェッチするときに効率的なクエリを作成するのに役立ちます。
キーのリストが短く、連続していない場合、クエリ パラメータと
UNNESTを使用してクエリを作成する。たとえば、キーのリストが
{1, 5, 1000}の場合、次のようなクエリを作成します。GoogleSQL
SELECT * FROM Table AS t WHERE t.Key IN UNNEST (@KeyList)
PostgreSQL
SELECT * FROM Table AS t WHERE t.Key IN UNNEST ($1)
注:
配列 UNNEST 演算子は、入力配列を要素の行にフラット化します。
前述のベスト プラクティスで説明したとおり、クエリ パラメータ(GoogleSQL の場合は
@KeyList、PostgreSQL の場合は$1)を使用すると、クエリを高速化できます。
キーのリストが連続して範囲内である場合、
WHERE句でキーの範囲の下限と上限を指定します。たとえば、キーのリストが
{1,2,3,4,5}の場合、次のようにクエリを作成します。GoogleSQL
SELECT * FROM Table AS t WHERE t.Key BETWEEN @min AND @max
PostgreSQL
SELECT * FROM Table AS t WHERE t.Key BETWEEN $1 AND $2
このクエリはキー範囲内のキーが連続している場合にのみより効率的です。言い換えると、キーのリストが
{1, 5, 1000}の場合、作成されるクエリで 1~1000 のすべての値がスキャンされるため、上記のクエリのように上限と下限を指定しないでください。
結合を最適化する
結合オペレーションは、クエリでスキャンする必要がある行数が大幅に増加し、結果的にクエリが遅くなることがあるため、コストが高くなる可能性があります。他のリレーショナル データベースで使い慣れている結合クエリを最適化するためのテクニックに加えて、Spanner SQL を使用する場合のさらに効率的な JOIN のおすすめの方法がいくつかあります。
可能な限り、インターリーブされたテーブルのデータを主キーによって結合する。例:
SELECT s.FirstName, a.ReleaseDate FROM Singers AS s JOIN Albums AS a ON s.SingerId = a.SingerId;
スキーマとデータモデルで説明しているとおり、インターリーブされたテーブル
Albums内の行は、Singersの親行と同じスプリットに物理的に保存されることが保証されます。したがって、ネットワークを介して大量のデータを送信することなく、結合をローカルで実行できます。結合の順序を強制する場合、結合ディレクティブを使用します。例:
GoogleSQL
SELECT * FROM Singers AS s JOIN@{FORCE_JOIN_ORDER=TRUE} Albums AS a ON s.SingerId = a.Singerid WHERE s.LastName LIKE '%x%' AND a.AlbumTitle LIKE '%love%';
PostgreSQL
SELECT * FROM Singers AS s JOIN/*@ FORCE_JOIN_ORDER=TRUE */ Albums AS a ON s.SingerId = a.Singerid WHERE s.LastName LIKE '%x%' AND a.AlbumTitle LIKE '%love%';
結合ディレクティブ
FORCE_JOIN_ORDERは Spanner に、クエリで指定された結合順序(つまり、Albums JOIN SingersではなくSingers JOIN Albums)を使用するように指示します。ただし、クエリプランで Spanner によって結合順序が変更され、大量の中間結果や行検索の機会消失などの望ましくない結果が生じたことに気付いた場合、この結合ディレクティブを使用します。結合ディレクティブを使用して、結合の実装を選択します。SQL を使用して複数のテーブルにクエリを実行する場合、Spanner はクエリを効率化する可能性のある結合メソッドを自動的に使用します。ただし、さまざまな結合アルゴリズムを使用してテストすることをおすすめします。適した結合アルゴリズムを選択することで、レイテンシを短縮できるか、メモリ使用量を削減できるか、あるいはその両方を実現できます。このクエリは、結合ディレクティブを
JOIN_METHODヒントとともに使用してHASH JOINを選択する構文を示しています。GoogleSQL
SELECT * FROM Singers s JOIN@{JOIN_METHOD=HASH_JOIN} Albums AS a ON a.SingerId = a.SingerId
PostgreSQL
SELECT * FROM Singers s JOIN/*@ JOIN_METHOD=HASH_JOIN */ Albums AS a ON a.SingerId = a.SingerId
HASH JOINまたはAPPLY JOINを使用する場合、またはJOINの片側で高度に選択的なWHERE句がある場合、結合のFROM句の最初のテーブルとして、最小数の行を生成するテーブルを配置します。この構造は、HASH JOINにあるので役立ち、Spanner は常に左側のテーブルがビルドとして、右側のテーブルがプローブとして選択します。同様に、APPLY JOINの場合、Spanner は左側のテーブルを外側として、右側のテーブルを内側として選択します。これらの結合タイプの詳細については、ハッシュ結合と適用結合をご覧ください。ワークロードに不可欠なクエリの場合は、より安定したパフォーマンスのために、SQL ステートメントで最もパフォーマンスの高い結合方法と結合順序を指定します。
タイムスタンプ述語のプッシュダウンを使用してクエリを最適化する
タイムスタンプ述部のプッシュダウンは、エージベースの階層型ストレージ ポリシーでタイムスタンプとデータを使用するクエリの効率を高めるために Spanner で使用されるクエリ最適化手法です。この最適化を有効にすると、タイムスタンプ列のフィルタリング オペレーションは、クエリ実行プランのできるだけ早い段階で実行されます。これにより、処理されるデータの量を大幅に削減し、クエリのパフォーマンスを全体的に向上させることができます。
タイムスタンプ述部のプッシュダウンでは、データベース エンジンがクエリを分析し、タイムスタンプ フィルタを見つけます。次に、このフィルタをストレージ レイヤに「プッシュダウン」します。これにより、タイムスタンプ条件に基づく関連データのみが SSD から読み取られます。これにより、処理および転送されるデータの量が最小限に抑えられ、クエリの実行が高速化されます。
SSD に保存されているデータにのみアクセスするようにクエリを最適化するには、次の条件を満たす必要があります。
- クエリでタイムスタンプ述語のプッシュダウンが有効になっている必要があります。詳細については、GoogleSQL ステートメント ヒントと PostgreSQL ステートメント ヒントをご覧ください。
- クエリでは、データの振り分けポリシーで指定された経過時間(
CREATE LOCALITY GROUPまたはALTER LOCALITY GROUPDDL ステートメントのssd_to_hdd_spill_timespanオプションで設定)以下のエージベースの制限を使用する必要があります。詳細については、GoogleSQLLOCALITY GROUPステートメントと PostgreSQLLOCALITY GROUPステートメントをご覧ください。 クエリでフィルタされる列は、commit タイムスタンプを含むタイムスタンプ列である必要があります。commit タイムスタンプ列を作成する方法については、GoogleSQL の commit タイムスタンプと PostgreSQL の commit タイムスタンプをご覧ください。これらの列はタイムスタンプ列とともに更新され、エージベースの階層型ストレージ ポリシーを持つ同じローカリティ グループ内に存在する必要があります。
特定の行で、クエリ対象の列の一部が SSD にあり、一部が HDD にある場合(列が異なるタイミングで更新され、HDD に異なるタイミングで古くなるため)、ヒントを使用するとクエリのパフォーマンスが低下する可能性があります。これは、クエリがさまざまなストレージ レイヤからデータを入力する必要があるためです。ヒントを使用すると、Spanner は各セルの commit タイムスタンプに基づいて個々のセルレベル(行と列の粒度レベル)でデータを古くするため、クエリの速度が低下します。この問題を回避するには、この最適化手法を使用してクエリされるすべての列を同じトランザクションで定期的に更新し、すべての列が同じ commit タイムスタンプを共有して最適化のメリットを享受できるようにします。
ステートメント レベルでタイムスタンプ述語のプッシュダウンを有効にするには、クエリでステートメント ヒントを使用します。例:
GoogleSQL
@{allow_timestamp_predicate_pushdown=TRUE}
SELECT s.SingerInfo
FROM Singers s
WHERE s.ModificationTime > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 12 HOUR);
PostgreSQL
/*@allow_timestamp_predicate_pushdown=TRUE*/
SELECT s.SingerInfo
FROM Singers s
WHERE s.ModificationTime > CURRENT_TIMESTAMP - INTERVAL '12 hours';
読み書きトランザクションで大量の読み取りを回避する
読み書きトランザクションでは、0 回または 1 回以上の読み取りまたは SQL クエリが可能で、commit の呼び出しの前に一連のミューテーションを含めることができます。データの整合性を維持するため、Spanner はテーブルとインデックスの行を読み書きするときにロックを取得します。ロックの詳細については、読み取りと書き込みのライフサイクルをご覧ください。
Cloud Spanner のロックのしくみによって、大量の行を読み取る必要がある読み取りまたは SQL クエリの実行(たとえば、SELECT * FROM Singers)は、トランザクションが commit されるか中止されるまで、読み取られた行に他のトランザクションが書き込めないことを意味します。
さらに、トランザクションで大量の行を処理しているため、小規模な範囲の行を読み取るトランザクション(たとえば、SELECT LastName FROM Singers WHERE SingerId = 7)よりも時間がかかり、それによって問題が悪化し、システムのスループットが低下します。
そのため、書き込みスループットの低下を許容しない限り、トランザクション内で大量の読み取り(たとえば、テーブル全体のスキャンまたは大量の結合操作)を避けます。
場合によっては、次のパターンでより良い結果が得られることがあります。
- 読み取り専用トランザクションで大量の読み取りを実行します読み取り専用トランザクションはロックを使用しないため、集計スループットが向上します。
- [省略可能]: 読み取ったばかりのデータに対して必要な処理を行います。
- 読み書きトランザクションを開始します。
- ステップ 1 での読み取り専用トランザクションの実行以降に、重要な行の値が変更されていないことを確認します。
- 行が変更されている場合、トランザクションをロールバックし、ステップ 1 を再実行します。
- 何も問題がないように見える場合は、ミューテーションを commit します。
読み取り / 書き込みトランザクションで大量の読み取りを確実に回避する 1 つの方法は、クエリが生成する実行プランを確認することです。
ORDER BY を使用して SQL 結果の順序を指定する
SELECT クエリの結果を特定の順序で表示する場合、ORDER BY 句を明示的に含めます。たとえば、主キーの順序ですべての歌手を表示する場合、次のクエリを使用します。
SELECT * FROM Singers
ORDER BY SingerId;
Spanner で結果の順序が保証されるのは、クエリに ORDER BY 句がある場合のみです。言い換えると、ORDER
BY を使用しないでこのクエリを考えます。
SELECT * FROM Singers;
Spanner では、このクエリの結果が主キー順になるとは限りません。さらに、結果の順序はいつでも変わる可能性があり、異なる呼び出しの間での整合性は保証されません。クエリに ORDER BY 句があり、Spanner が必要なオーダーを提供するインデックスを使用する場合、Spanner はデータを明示的に並べ替えません。したがって、この句を含めることによるパフォーマンスへの影響は心配ありません。明示的な並べ替えオペレーションが実行に含まれているかどうかは、クエリプランで確認できます。
LIKE の代わりに STARTS_WITH を使用する
Spanner はパラメータ化された LIKE パターンを実行時まで評価しないので、すべての行を読み取って LIKE 式で評価し、一致しない行を除外しなければなりません。
LIKE パターンの形式が foo%(たとえば、固定文字列で始まり、単一のワイルドカード パーセントで終わる)で、列にインデックスが付けられている場合、LIKE の代わりに STARTS_WITH を使用します。このオプションを使用すると、Spanner はクエリ実行プランをより効果的に最適化できます。
非推奨:
GoogleSQL
SELECT a.AlbumTitle FROM Albums a WHERE a.AlbumTitle LIKE @like_clause;
PostgreSQL
SELECT a.AlbumTitle FROM Albums a WHERE a.AlbumTitle LIKE $1;
推奨:
GoogleSQL
SELECT a.AlbumTitle FROM Albums a WHERE STARTS_WITH(a.AlbumTitle, @prefix);
PostgreSQL
SELECT a.AlbumTitle FROM Albums a WHERE STARTS_WITH(a.AlbumTitle, $2);
commit タイムスタンプを使用する
アプリケーションが特定の時刻以降に書き込まれたデータをクエリする必要がある場合は、関連するテーブルに commit タイムスタンプ列を追加します。commit タイムスタンプを使用すると、特定の時間よりも後に書き込まれた行に対して、WHERE 句が結果を制限するクエリの I/O を減らすことができる Spanner 最適化が可能になります。
この詳細については、GoogleSQL 言語データベースまたは PostgreSQL 言語データベースを使用した最適化をご覧ください。