本教學課程將說明如何從 Amazon DynamoDB 遷移至 Spanner。主要適用於想從 NoSQL 系統移至 Spanner 的應用程式擁有者。Spanner 是支援交易且具高擴充性的完全關聯式容錯 SQL 資料庫系統。如果您的 Amazon DynamoDB 資料表使用一致的類型和版面配置,對應至 Spanner 就會很簡單。如果您的 Amazon DynamoDB 資料表包含任意資料類型和值,移至 Datastore 或 Firestore 等其他 NoSQL 服務可能比較容易。
本教學課程假設您已熟悉資料庫結構定義、資料類型、NoSQL 的基本概念,以及關聯式資料庫系統。此外,本教學課程會執行預先定義的工作來示範遷移作業。完成教學課程後,您可以根據您的環境修改課程中提供的程式碼和步驟。
以下架構圖概略呈現本教學課程中用來遷移資料的元件:

目標
- 將 Amazon DynamoDB 中的資料遷移至 Spanner。
- 建立 Spanner 資料庫和遷移資料表。
- 將 NoSQL 結構定義對應至關聯式結構定義。
- 建立及匯出使用 Amazon DynamoDB 的範例資料集。
- 在 Amazon S3 和 Cloud Storage 之間轉移資料。
- 使用 Dataflow 將資料載入 Spanner。
費用
本教學課程使用下列 Google Cloud的計費元件:
Spanner 的費用是依據執行個體的運算資源量,以及每月帳單週期期間儲存的資料量計算。在本教學課程中,您將使用這些資源的最低設定,並在最後清除這些資源。在實際使用情況中,請預估您的總處理量和儲存空間需求,然後參閱 Spanner 執行個體說明文件決定您需要的運算資源量。
除了 Google Cloud 資源以外,本教學課程還會使用下列 Amazon Web Services (AWS) 資源:
- AWS Lambda
- Amazon S3
- Amazon DynamoDB
這些服務只有在遷移期間需要用到。完成本教學課程後,請按照相關操作說明清除所有資源,以避免產生不必要的費用。請使用 AWS Pricing Calculator 估算相關費用。
如要根據預測用量估算費用,請使用 Pricing Calculator。
事前準備
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Spanner, Pub/Sub, Compute Engine, and Dataflow APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Spanner, Pub/Sub, Compute Engine, and Dataflow APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
- 設定預設 Compute Engine 區域,例如:
us-central1-b。gcloud config set compute/zone us-central1-b - 複製包含範例程式碼的 GitHub 存放區。 git clone https://github.com/GoogleCloudPlatform/dynamodb-spanner-migration.git
- 前往複製的目錄。 cd dynamodb-spanner-migration
- 建立 Python 虛擬環境。 pip3 install virtualenv virtualenv env
- 啟動虛擬環境。 source env/bin/activate
- 安裝必要的 Python 模組。 pip3 install -r requirements.txt
- 在 AWS 主控台中,前往「IAM」專區按一下 [Roles],然後選取 [Create role]。
- 在「Trusted entity type」(信任的實體類型) 下方,確認已選取「AWS service」(AWS 服務)。
- 在「用途」下方選取「Lambda」,然後點選「下一步」。
- 在「權限政策」篩選器方塊中輸入
AWSLambdaDynamoDBExecutionRole,然後按Return搜尋。 - 勾選「AWSLambdaDynamoDBExecutionRole」核取方塊,然後按一下「Next」。
- 在「Role name」(角色名稱) 方塊中輸入
dynamodb-spanner-lambda-role,然後按一下「Create role」(建立角色)。 - 在 AWS 主控台的「IAM」專區中按一下「Users」,然後選取「Add users」。
- 在「User name」(使用者名稱) 方塊中輸入
dynamodb-spanner-migration。 在「Access type」下方,選取「Access key - Programmatic access」左側的核取方塊。
點選 [Next: Permissions] (下一步:權限)。
按一下「Attach existing policies directly」,然後使用「Search」方塊篩選,勾選下列三項政策旁的核取方塊:
AmazonDynamoDBFullAccessAmazonS3FullAccessAWSLambda_FullAccess
依序點選「下一步:標記」和「下一步:檢閱」,然後點選「建立使用者」。
按一下 [Show] 查看憑證。系統會顯示新建立使用者的存取金鑰 ID 和存取密鑰。您需要在下一節使用憑證,因此請暫時將這個視窗保持開啟。這些憑證可用來變更您的帳戶和影響您的環境,因此請妥善儲存。完成本教學課程後,您可以刪除 IAM 使用者。
在 Cloud Shell 中設定 AWS 指令列介面 (CLI)。
aws configure
畫面會出現以下輸出結果:
AWS Access Key ID [None]: PASTE_YOUR_ACCESS_KEY_ID AWS Secret Access Key [None]: PASTE_YOUR_SECRET_ACCESS_KEY Default region name [None]: us-west-2 Default output format [None]:
- 輸入您建立的 AWS IAM 帳戶
ACCESS KEY ID和SECRET ACCESS KEY。 - 在「Default region name」(預設地區名稱) 欄位中輸入
us-west-2,並保留其他欄位的預設值。
- 輸入您建立的 AWS IAM 帳戶
關閉 AWS IAM 主控台視窗。
在 Cloud Shell 中,建立使用範例資料表屬性的 Amazon DynamoDB 資料表。
aws dynamodb create-table --table-name Migration \ --attribute-definitions AttributeName=Username,AttributeType=S \ --key-schema AttributeName=Username,KeyType=HASH \ --provisioned-throughput ReadCapacityUnits=75,WriteCapacityUnits=75確認資料表的狀態為
ACTIVE。aws dynamodb describe-table --table-name Migration \ --query 'Table.TableStatus'在資料表中填入範例資料。
python3 make-fake-data.py --table Migration --items 25000
在設定了預設 Compute Engine 區域的地區中建立 Spanner 執行個體,例如
us-central1。gcloud beta spanner instances create spanner-migration \ --config=regional-us-central1 --processing-units=100 \ --description="Migration Demo"在 Spanner 執行個體中建立資料庫和範例資料表。
gcloud spanner databases create migrationdb \ --instance=spanner-migration \ --ddl "CREATE TABLE Migration ( \ Username STRING(1024) NOT NULL, \ PointsEarned INT64, \ ReminderDate DATE, \ Subscribed BOOL, \ Zipcode INT64, \ ) PRIMARY KEY (Username)"在 Cloud Shell 中,針對來源資料表啟用 Amazon DynamoDB 串流。
aws dynamodb update-table --table-name Migration \ --stream-specification StreamEnabled=true,StreamViewType=NEW_AND_OLD_IMAGES設定 Pub/Sub 主題來接收變更。
gcloud pubsub topics create spanner-migration
畫面會出現以下輸出結果:
Created topic [projects/your-project/topics/spanner-migration].
建立 IAM 服務帳戶,以將資料表更新推送至 Pub/Sub 主題。
gcloud iam service-accounts create spanner-migration \ --display-name="Spanner Migration"畫面會出現以下輸出結果:
Created service account [spanner-migration].
建立 IAM 政策繫結,讓服務帳戶有權發布至 Pub/Sub。將
GOOGLE_CLOUD_PROJECT替換為您的 Google Cloud 專案名稱。gcloud projects add-iam-policy-binding GOOGLE_CLOUD_PROJECT \ --role roles/pubsub.publisher \ --member serviceAccount:spanner-migration@GOOGLE_CLOUD_PROJECT.iam.gserviceaccount.com畫面會出現以下輸出結果:
bindings: (...truncated...) - members: - serviceAccount:spanner-migration@solution-z.iam.gserviceaccount.com role: roles/pubsub.publisher
建立服務帳戶的憑證。
gcloud iam service-accounts keys create credentials.json \ --iam-account spanner-migration@GOOGLE_CLOUD_PROJECT.iam.gserviceaccount.com畫面會出現以下輸出結果:
created key [5e559d9f6bd8293da31b472d85a233a3fd9b381c] of type [json] as [credentials.json] for [spanner-migration@your-project.iam.gserviceaccount.com]
準備及包裝 AWS Lambda 函式,以將 Amazon DynamoDB 資料表變更推送至 Pub/Sub 主題。
pip3 install --ignore-installed --target=lambda-deps google-cloud-pubsub cd lambda-deps; zip -r9 ../pubsub-lambda.zip *; cd - zip -g pubsub-lambda.zip ddbpubsub.py
建立變數,以針對您先前建立的 Lambda 執行角色擷取其 Amazon Resource Name (ARN)。
LAMBDA_ROLE=$(aws iam list-roles \ --query 'Roles[?RoleName==`dynamodb-spanner-lambda-role`].[Arn]' \ --output text)使用
pubsub-lambda.zip套件建立 AWS Lambda 函式。aws lambda create-function --function-name dynamodb-spanner-lambda \ --runtime python3.9 --role ${LAMBDA_ROLE} \ --handler ddbpubsub.lambda_handler --zip fileb://pubsub-lambda.zip \ --environment Variables="{SVCACCT=$(base64 -w 0 credentials.json),PROJECT=GOOGLE_CLOUD_PROJECT,TOPIC=spanner-migration}"畫面會出現以下輸出結果:
{ "FunctionName": "dynamodb-spanner-lambda", "LastModified": "2022-03-17T23:45:26.445+0000", "RevisionId": "e58e8408-cd3a-4155-a184-4efc0da80bfb", "MemorySize": 128, ... truncated output... "PackageType": "Zip", "Architectures": [ "x86_64" ] }建立變數,以針對您的資料表擷取 Amazon DynamoDB 串流的 ARN。
STREAMARN=$(aws dynamodb describe-table \ --table-name Migration \ --query "Table.LatestStreamArn" \ --output text)將 Lambda 函式附加至 Amazon DynamoDB 資料表。
aws lambda create-event-source-mapping --event-source ${STREAMARN} \ --function-name dynamodb-spanner-lambda --enabled \ --starting-position TRIM_HORIZON如要最佳化測試期間的回應速度,請在上述指令的結尾加上
--batch-size 1,這樣每當您建立、更新或刪除項目時就會觸發函式。您會看到類似下方的輸出內容:
{ "UUID": "44e4c2bf-493a-4ba2-9859-cde0ae5c5e92", "StateTransitionReason": "User action", "LastModified": 1530662205.549, "BatchSize": 100, "EventSourceArn": "arn:aws:dynamodb:us-west-2:accountid:table/Migration/stream/2018-07-03T15:09:57.725", "FunctionArn": "arn:aws:lambda:us-west-2:accountid:function:dynamodb-spanner-lambda", "State": "Creating", "LastProcessingResult": "No records processed" ... truncated output...在 Cloud Shell 中,針對您要在下方幾節中使用的值區名稱建立變數。
BUCKET=${DEVSHELL_PROJECT_ID}-dynamodb-spanner-export建立 Amazon S3 值區來接收 DynamoDB 匯出內容。
aws s3 mb s3://${BUCKET}在 AWS 管理主控台中,前往 DynamoDB,然後點選「Tables」。
按一下「
Migration」資料表。在「匯出和串流」分頁下方,按一下「匯出至 S3」。
如果系統提示,請啟用
point-in-time-recovery(PITR)。按一下「Browse S3」(瀏覽 S3),然後選擇您先前建立的 S3 bucket。
按一下 [匯出]。
按一下「重新整理」圖示,更新匯出工作的狀態。匯出作業需要幾分鐘的時間。
流程完成後,請查看輸出值區。
aws s3 ls --recursive s3://${BUCKET}這個步驟大約需要 5 分鐘。完成後,您會看到如下所示的輸出內容:
2022-02-17 04:41:46 0 AWSDynamoDB/01645072900758-ee1232a3/_started 2022-02-17 04:46:04 500441 AWSDynamoDB/01645072900758-ee1232a3/data/xygt7i2gje4w7jtdw5652s43pa.json.gz 2022-02-17 04:46:17 199 AWSDynamoDB/01645072900758-ee1232a3/manifest-files.json 2022-02-17 04:46:17 24 AWSDynamoDB/01645072900758-ee1232a3/manifest-files.md5 2022-02-17 04:46:17 639 AWSDynamoDB/01645072900758-ee1232a3/manifest-summary.json 2022-02-17 04:46:18 24 AWSDynamoDB/01645072900758-ee1232a3/manifest-summary.md5
在 Cloud Shell 中建立 Cloud Storage 值區,以接收從 Amazon S3 匯出的檔案。
gcloud storage buckets create gs://${BUCKET}將 Amazon S3 中的檔案同步至 Cloud Storage。
rsync指令對於大部分的複製作業都有效。如果匯出檔案很大 (幾 GB 以上),請使用 Cloud Storage 移轉服務在背景管理轉移作業。gcloud storage rsync s3://${BUCKET} gs://${BUCKET} --recursive --delete-unmatched-destination-objects如要將匯出檔案中的資料寫入 Spanner 資料表,請透過範例 Apache Beam 程式碼執行 Dataflow 工作。
cd dataflow mvn compile mvn exec:java \ -Dexec.mainClass=com.example.spanner_migration.SpannerBulkWrite \ -Pdataflow-runner \ -Dexec.args="--project=GOOGLE_CLOUD_PROJECT \ --instanceId=spanner-migration \ --databaseId=migrationdb \ --table=Migration \ --importBucket=$BUCKET \ --runner=DataflowRunner \ --region=us-central1"如要查看匯入工作的進度,請在 Google Cloud 控制台中前往 Dataflow。
當工作正在執行時,您可以查看執行圖來檢查記錄。請按一下「Status」(狀態) 為「Running」(執行中) 的工作。
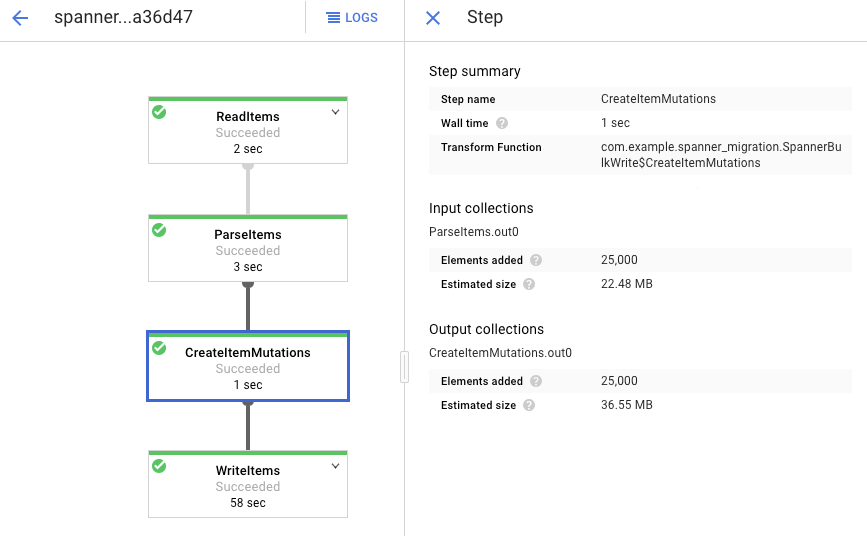
按一下各個階段可查看已處理完畢的元素數量。如果所有階段都顯示「Succeeded」(成功),表示已匯入完成。在各個階段中顯示為處理完畢的元素數量,與在 Amazon DynamoDB 資料表中建立的元素數量相同。
確認目標 Spanner 資料表中的記錄數量與 Amazon DynamoDB 資料表中的項目數量一致。
aws dynamodb describe-table --table-name Migration --query Table.ItemCount gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration --sql="select count(*) from Migration"
畫面會出現以下輸出結果:
$ aws dynamodb describe-table --table-name Migration --query Table.ItemCount 25000 $ gcloud spanner databases execute-sql migrationdb --instance=spanner-migration --sql="select count(*) from Migration" 25000
在每個資料表中取樣隨機項目,確保資料皆一致。
gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration \ --sql="select * from Migration limit 1"畫面會出現以下輸出結果:
Username: aadams4495 PointsEarned: 5247 ReminderDate: 2022-03-14 Subscribed: True Zipcode: 58057
針對前一步驟中 Spanner 查詢傳回的
Username,查詢具有相同值的 Amazon DynamoDB 資料表,例如:aallen2538。這個值是資料庫中範例資料專用的。aws dynamodb get-item --table-name Migration \ --key '{"Username": {"S": "aadams4495"}}'其他欄位的值應與 Spanner 輸出內容一致。畫面會出現以下輸出結果:
{ "Item": { "Username": { "S": "aadams4495" }, "ReminderDate": { "S": "2018-06-18" }, "PointsEarned": { "N": "1606" }, "Zipcode": { "N": "17303" }, "Subscribed": { "BOOL": false } } }針對 Pub/Sub 主題建立訂閱項目,供 AWS Lambda 傳送事件。
gcloud pubsub subscriptions create spanner-migration \ --topic spanner-migration畫面會出現以下輸出結果:
Created subscription [projects/your-project/subscriptions/spanner-migration].
如要將 Pub/Sub 收到的變更串流寫入 Spanner 資料表,請透過 Cloud Shell 執行 Dataflow 工作。
mvn exec:java \ -Dexec.mainClass=com.example.spanner_migration.SpannerStreamingWrite \ -Pdataflow-runner \ -Dexec.args="--project=GOOGLE_CLOUD_PROJECT \ --instanceId=spanner-migration \ --databaseId=migrationdb \ --table=Migration \ --experiments=allow_non_updatable_job \ --subscription=projects/GOOGLE_CLOUD_PROJECT/subscriptions/spanner-migration \ --runner=DataflowRunner \ --region=us-central1"與批次載入步驟類似,如要查看工作的進度,請在 Google Cloud 控制台中前往 Dataflow。
按一下「Status」(狀態) 為「Running」(執行中) 的工作。
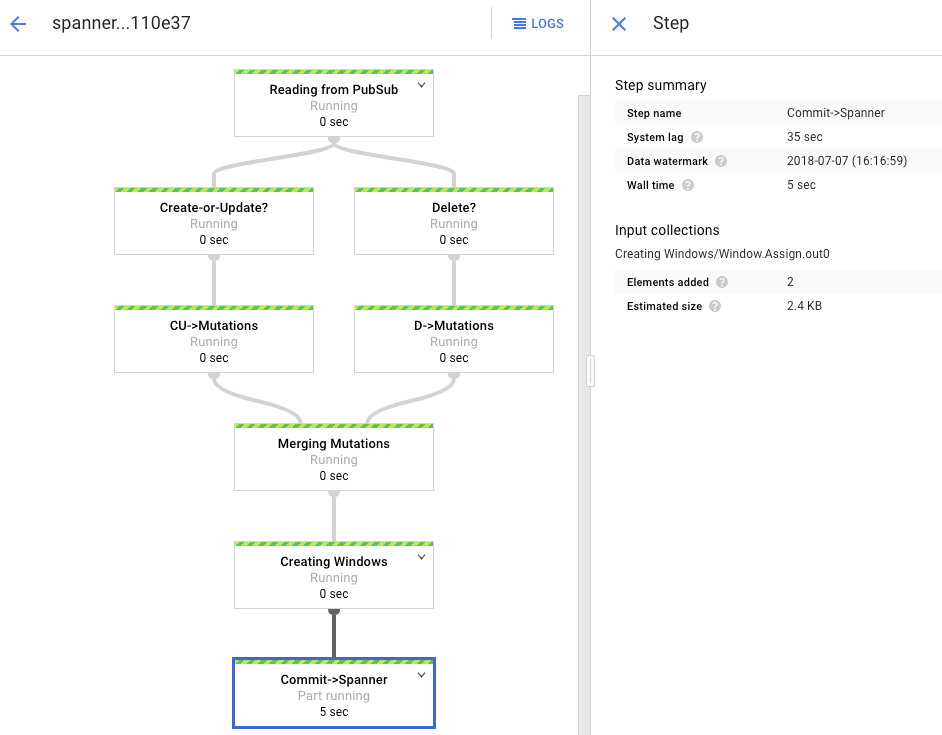
處理圖會顯示和之前類似的輸出內容,但每個已處理完畢的項目會計入狀態視窗中顯示的數量。系統延遲時間是 Spanner 資料表反映變更前的概略預期延遲時間。
查詢 Spanner 中不存在的資料列。
gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration \ --sql="SELECT * FROM Migration WHERE Username='my-test-username'"這項作業不會傳回任何結果。
透過您在 Spanner 查詢中使用的鍵,在 Amazon DynamoDB 中建立記錄。如果指令執行成功,則不會有任何輸出結果。
aws dynamodb put-item \ --table-name Migration \ --item '{"Username" : {"S" : "my-test-username"}, "Subscribed" : {"BOOL" : false}}'再次執行相同的查詢,確認該資料列現已在 Spanner 中。
gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration \ --sql="SELECT * FROM Migration WHERE Username='my-test-username'"輸出結果會顯示插入的資料列:
Username: my-test-username PointsEarned: None ReminderDate: None Subscribed: False Zipcode:
變更原始項目的部分屬性,並更新 Amazon DynamoDB 資料表。
aws dynamodb update-item \ --table-name Migration \ --key '{"Username": {"S":"my-test-username"}}' \ --update-expression "SET PointsEarned = :pts, Subscribed = :sub" \ --expression-attribute-values '{":pts": {"N":"4500"}, ":sub": {"BOOL":true}}'\ --return-values ALL_NEW您會看到類似下方的輸出內容:
{ "Attributes": { "Username": { "S": "my-test-username" }, "PointsEarned": { "N": "4500" }, "Subscribed": { "BOOL": true } } }確認變更已推送到 Spanner 資料表。
gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration \ --sql="SELECT * FROM Migration WHERE Username='my-test-username'"畫面會出現以下輸出結果:
Username PointsEarned ReminderDate Subscribed Zipcode my-test-username 4500 None True
刪除 Amazon DynamoDB 來源資料表中的測試項目。
aws dynamodb delete-item \ --table-name Migration \ --key '{"Username": {"S":"my-test-username"}}'確認對應資料列已從 Spanner 資料表中刪除。如果變更已推送完畢,以下指令不會傳回任何資料列:
gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration \ --sql="SELECT * FROM Migration WHERE Username='my-test-username'"前往 Spanner。
按一下「Spanner Studio」。
在「Query」(查詢) 欄位中輸入以下查詢,然後按一下 [Run query] (執行查詢)。
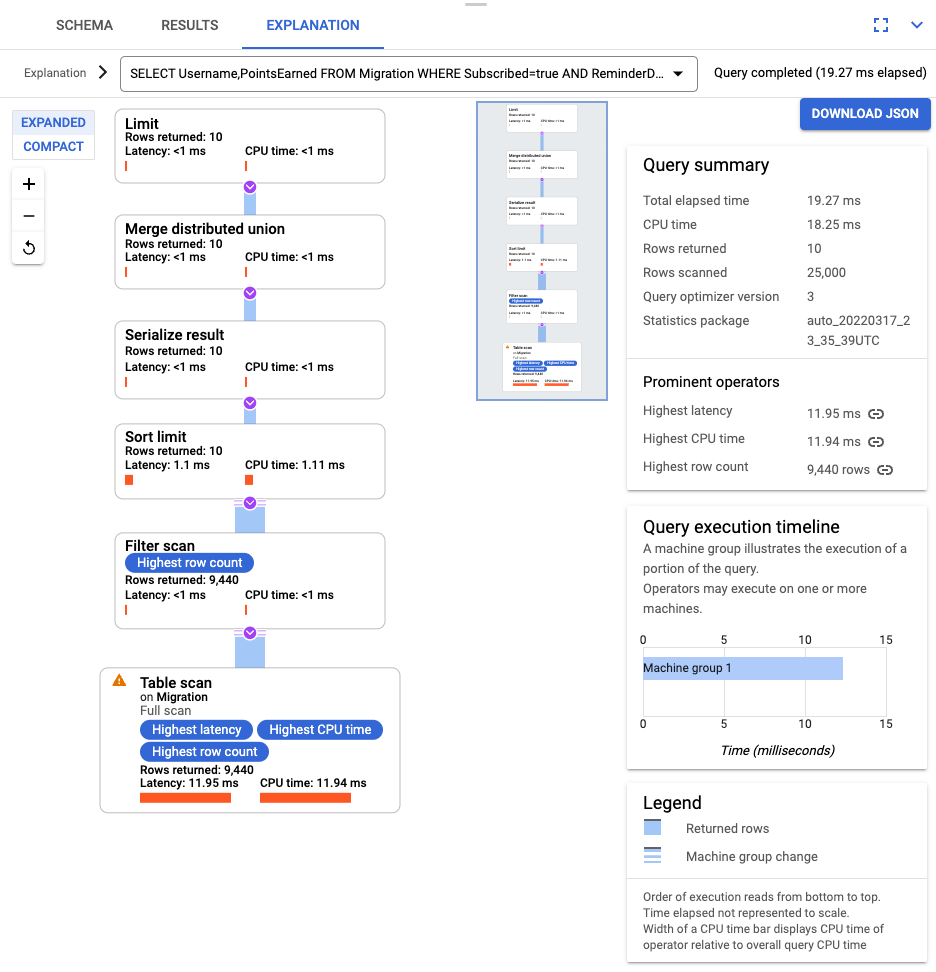
SELECT Username,PointsEarned FROM Migration WHERE Subscribed=true AND ReminderDate > DATE_SUB(DATE(current_timestamp()), INTERVAL 14 DAY) ORDER BY ReminderDate DESC LIMIT 10
查詢執行完畢後,按一下 [Explanation] (說明) 並記下「Rows scanned」(掃描的資料列) 數量和「Rows returned」(傳回的資料列) 數量。在沒有索引的情況下,Spanner 會掃描整個資料表,以傳回符合查詢的一小部分資料。
如果這是常用查詢,請針對 Subscribed 和 ReminderDate 資料欄建立複合式索引。在 Spanner 控制台中,選取左側導覽窗格的「索引」,然後按一下「建立索引」。
在文字方塊中輸入索引定義。
CREATE INDEX SubscribedDateDesc ON Migration ( Subscribed, ReminderDate DESC )
如要開始在背景建構資料庫,請按一下 [Create] (建立)。
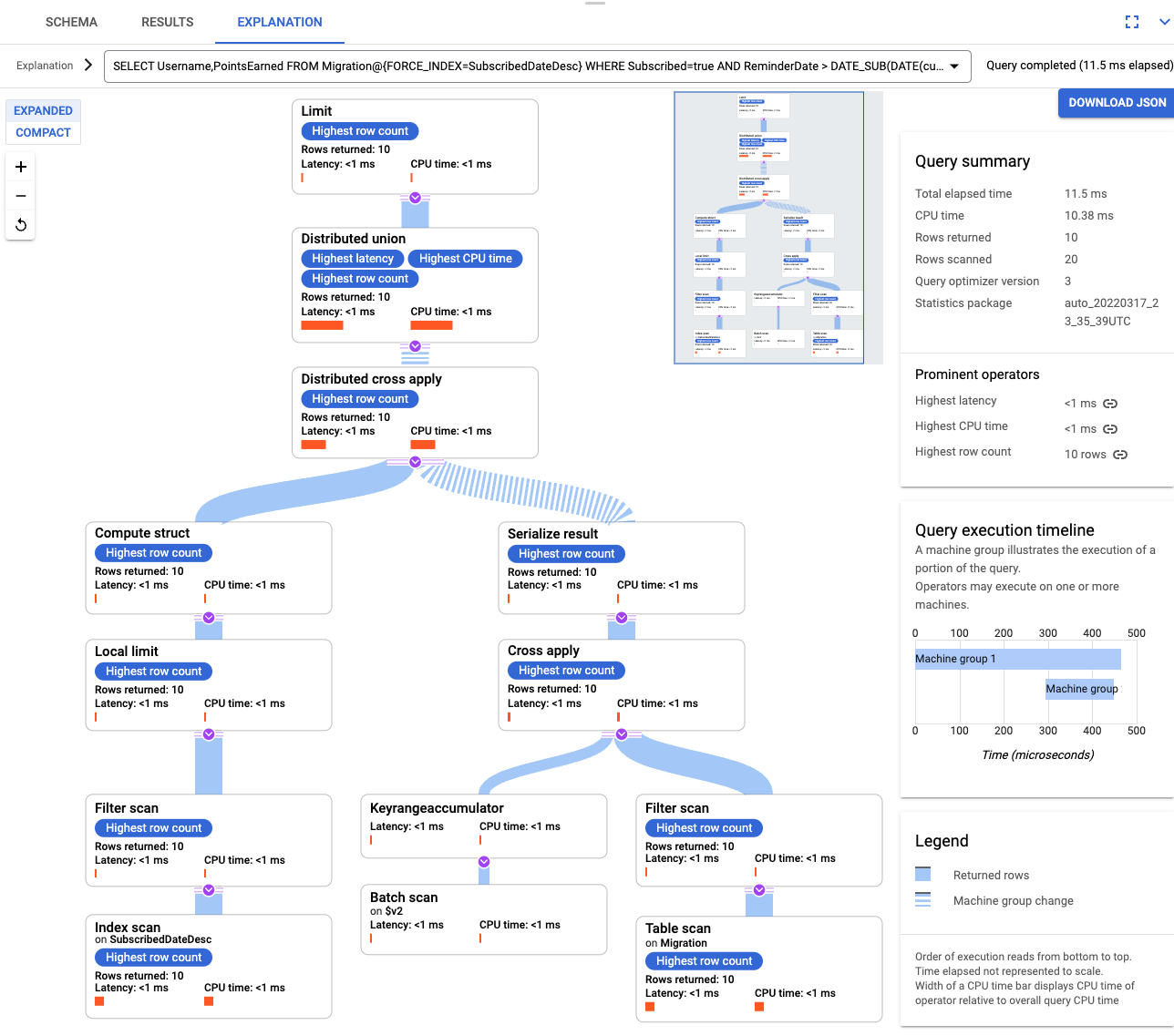
索引建立完畢後,請再次執行查詢並新增索引。
SELECT Username,PointsEarned FROM Migration@{FORCE_INDEX=SubscribedDateDesc} WHERE Subscribed=true AND ReminderDate > DATE_SUB(DATE(current_timestamp()), INTERVAL 14 DAY) ORDER BY ReminderDate DESC LIMIT 10再次查看查詢說明。您會發現「Rows scanned」(掃描的資料列) 數量減少了,每個步驟中的「Rows returned」(傳回的資料列) 數量則與查詢傳回的數量相符。
如要剖析傳入的 JSON 並建構變異版本,請使用 GSON。根據您的資料調整 JSON 定義。
調整相對的 JSON 對應。
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
- 刪除名為「Migration」的 DyanmoDB 資料表。
- 刪除您在遷移過程中建立的 Amazon S3 值區和 Lambda 函式。
- 最後,刪除您在本教學課程中建立的 AWS IAM 使用者。
- 瞭解如何最佳化 Spanner 結構定義。
- 瞭解如何將 Dataflow 用於更複雜的情況。
完成本文所述工作後,您可以刪除已建立的資源,避免繼續計費。詳情請參閱清除所用資源一節。
準備環境
在本教學課程中,您將使用 Cloud Shell 執行指令。Cloud Shell 可讓您在 Google Cloud中存取指令列,並包括 Google Cloud CLI 以及 Google Cloud 開發所需的其他工具。Cloud Shell 可能需要幾分鐘的時間初始化。
設定 AWS 存取權
在本教學課程中,您將建立及刪除 Amazon DynamoDB 資料表、Amazon S3 值區和其他資源。如要存取這些資源,您必須先建立必要的 AWS 身分與存取權管理 (IAM) 權限。您可以使用測試或沙箱 AWS 帳戶,避免影響相同帳戶中的實際工作環境資源。
為 AWS Lambda 建立 AWS IAM 角色
在本節中,您將建立 AWS IAM 角色,在本教學課程後面的步驟中供 AWS Lambda 使用。
建立 AWS IAM 使用者
按照下列步驟建立可透過程式存取 AWS 資源的 AWS IAM 使用者;這些資源在整個教學課程中都會用到。
設定 AWS 指令列介面
瞭解資料模型
本節將概略說明 Amazon DynamoDB 和 Spanner 資料類型、鍵與索引的相似與不同之處。
資料類型
Spanner 使用 GoogleSQL 資料類型。下表說明 Amazon DynamoDB 資料類型和 Spanner 資料類型之間的對應關係。
| Amazon DynamoDB | Spanner |
|---|---|
| 數字 | 視精確度或預定用途而定,可對應至 INT64、FLOAT64、TIMESTAMP 或 DATE。 |
| 字串 | 字串 |
| 布林值 | BOOL |
| 空值 | 沒有明確的類型。資料欄可包含空值。 |
| 二進位檔 | 位元組 |
| 集合 | 陣列 |
| 對應和清單 | 如果結構一致並可使用資料表 DDL 語法描述,則為 Struct。 |
主鍵
Amazon DynamoDB 主鍵會產生唯一性,並可為雜湊鍵或是範圍鍵和雜湊鍵的組合。本教學課程會先示範遷移主鍵為雜湊鍵的 Amazon DynamoDB 資料表。這個雜湊鍵將成為您 Spanner 資料表的主鍵。在下方的交錯式資料表一節中,您將模擬 Amazon DynamoDB 資料表使用的主鍵是由雜湊鍵和範圍鍵組成的情形。
次要索引
Amazon DynamoDB 和 Spanner 都支援針對非主鍵屬性建立索引。請記下您 Amazon DynamoDB 資料表中的任何次要索引,以便在 Spanner 資料表中建立,詳情請參閱本教學課程下方的一節。
範例資料表
為方便進行本教學課程,請將下列範例資料表從 Amazon DynamoDB 遷移至 Spanner:
| Amazon DynamoDB | Spanner | |
|---|---|---|
| 資料表名稱 |
Migration
|
Migration
|
| 主鍵 |
"Username" : String
|
"Username" : STRING(1024)
|
| 鍵類型 | 雜湊 | 不適用 |
| 其他欄位 |
Zipcode: Number
Subscribed: Boolean
ReminderDate: String
PointsEarned: Number
|
Zipcode: INT64
Subscribed: BOOL
ReminderDate: DATE
PointsEarned: INT64
|
準備 Amazon DynamoDB 資料表
在本節中,您將建立 Amazon DynamoDB 來源資料表並填入資料。
可建立 Spanner 資料庫
您建立的 Spanner 執行個體運算資源盡可能小,只有 100 個處理單元。這個運算容量足以應付本教學課程的範圍。如要在實際工作環境部署,請參閱 Spanner 執行個體說明文件,根據您的資料庫效能需求決定適當的運算容量。
在這個範例中,您將在建立資料庫的同時建立資料庫結構定義。您也可以在建立資料庫後更新結構定義,這種做法很常見。
準備遷移作業
以下各節將說明如何匯出 Amazon DynamoDB 來源資料表,以及如何設定 Pub/Sub 複製功能以擷取資料庫在匯出期間發生的任何變更。
將變更串流傳入 Pub/Sub
您必須使用 AWS Lambda 函式,將資料庫變更串流傳入 Pub/Sub。
將 Amazon DynamoDB 資料表匯出至 Amazon S3
執行遷移作業
Pub/Sub 傳送程序現已準備就緒,您可以推送在匯出後發生的任何資料表變更。
將匯出的資料表複製到 Cloud Storage
批次匯入資料
複製新的變更
批次匯入工作完成後,請設定串流工作,將來源資料表中持續發生的更新寫入 Spanner。您必須透過 Pub/Sub 訂閱事件,並將其寫入 Spanner。
您建立的 Lambda 函式已經過設定,可擷取來源 Amazon DynamoDB 資料表的變更,並將其發布至 Pub/Sub。
您在批次載入階段執行的 Dataflow 工作是一組有限的輸入,又稱為「受限」資料集。這個 Dataflow 工作會使用 Pub/Sub 做為串流來源,並視為「不受限」。如要進一步瞭解這兩種來源,請參閱 Apache Beam 程式設計指南的 PCollections 一節。這個步驟中的 Dataflow 工作應保持運作,而不會在完成時終止。串流 Dataflow 工作會繼續處於「Running」(執行中) 狀態,而非「Succeeded」(成功) 狀態。
確認複製設定
請對來源資料表進行一些變更,確認變更內容會複製到 Spanner 資料表。
使用交錯式資料表
Spanner 支援交錯式資料表的概念。在這種設計模型中,頂層項目有多個與該頂層項目相關的巢狀項目,例如客戶和其訂單,或是玩家及其遊戲分數。如果您的 Amazon DynamoDB 來源資料表使用由雜湊鍵和範圍鍵組成的主鍵,您可以使用交錯式資料表結構定義做為模型,如下圖所示。這個結構可讓您有效率地查詢交錯式資料表,同時彙整父項資料表中的欄位。

套用次要索引
如要將次要索引套用至 Spanner 資料表,最佳做法是在載入資料後再套用。複製功能現已開始運作,因此您可以設定次要索引加快查詢速度。如同 Spanner 資料表,Spanner 次要索引是完全一致的,而「不」具有許多 NoSQL 資料庫中常見的最終一致性。這個特性有助於簡化應用程式設計。
執行不使用任何索引的查詢。您要在有特定資料欄值的情況下,尋找前 N 個出現情形。這可提高資料庫效率,因此在 Amazon DynamoDB 中是常見的查詢。
交錯式索引
您可以在 Spanner 中設定交錯式索引。前一節討論的次要索引是資料庫階層的根,且使用索引的方式與傳統資料庫相同。交錯式索引則與其交錯式資料列相關。請參閱索引選項進一步瞭解如何套用交錯式索引。
針對資料模型進行調整
如要根據您自己的情況調整本教學課程的遷移設定,請修改您的 Apache Beam 來源檔案。在實際進行遷移的期間,請不要變更來源結構定義,否則可能會遺失資料。
在上述步驟中,您修改了 Apache Beam 原始碼以進行大量匯入。 請以類似的方式針對管道的串流部分修改原始碼,最後再調整 Spanner 目標資料庫的資料表建立指令碼、結構定義和索引。
清除所用資源
如要避免系統向您的 Google Cloud 帳戶收取本教學課程所用資源的費用,請刪除含有相關資源的專案,或者保留專案但刪除個別資源。
刪除專案
刪除 AWS 資源
如果您會在本教學課程以外的地方使用您的 AWS 帳戶,刪除下列資源時請務必小心: