Spanner Data Boost is a fully managed, serverless service that provides independent compute resources for supported Spanner workloads. Data Boost lets you execute analytics queries and data exports with near-zero impact to existing workloads on the provisioned Spanner instance. The service consists of Spanner clusters that Google manages at the region level. For eligible queries that request Data Boost, Spanner routes the workload to these servers transparently. Eligible queries are those for which the first operator in the query execution plan is a distributed union. These queries don't have to change to take advantage of Data Boost.
Data Boost is most impactful in the following scenarios where you want to avoid negative impacts to the existing transactional system due to resource contention:
- Ad hoc or infrequent queries that involve processing large amounts of data. A typical example is a federated query from BigQuery to Spanner.
- Reporting or data export jobs. An example is a Dataflow job to export Spanner data to Cloud Storage.
The following diagram illustrates how Data Boost coordinates with the Spanner instance to provide independent compute resources.
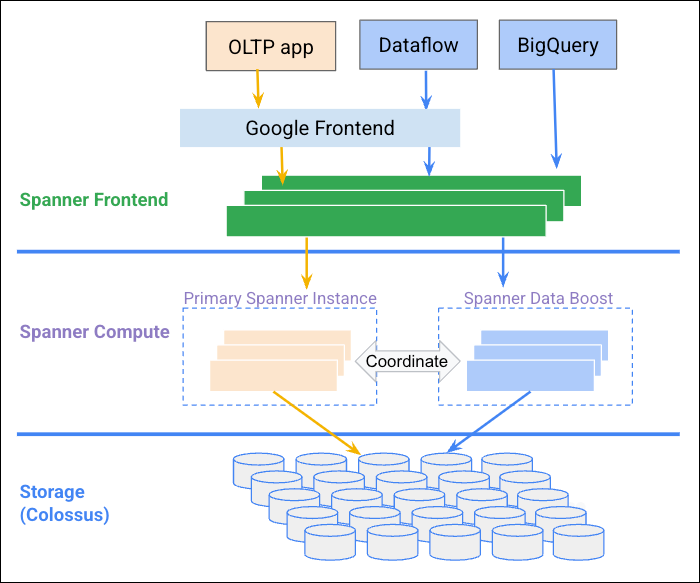
Benefits
Data Boost offers the following benefits:
- Provides workload isolation. You can run supported queries against the latest data with near-zero impact on existing transactional workloads regardless of query complexity or amount of data processed.
- Provides equal or better latency.
- Prevents over-provisioning of Spanner instances just to support occasional analytics queries.
- Offers a high degree of scalability with greater query parallelism that scales elastically with burst loads.
- Provides comprehensive metrics, which let administrators identify the most expensive queries and determine the cost component to optimize. Administrators can then verify the impact of their optimizations by monitoring the query's serverless processing unit consumption in its next execution.
- Requires no additional operational overhead. There is no extra service to manage, no capacity planning or provisioning, no need to wait for scaling, and no maintenance.
Permissions
Any principal that runs a query or export that requests Data Boost
must have the spanner.databases.useDataBoost Identity and Access Management (IAM)
permission. We recommend that you use the
Cloud Spanner Database Reader With DataBoost (roles/spanner.databaseReaderWithDataBoost)
IAM role.
Billing and quotas
You pay only for actual processing units used by queries that run on Data Boost. Administrators can set limits on usage to avoid cost overruns.
What's next
- Run federated queries with Data Boost
- Export data with Data Boost
- Use Data Boost in your applications
- Monitor Data Boost usage
- Monitor and manage Data Boost quota usage