Neste tutorial, explicamos como reduzir os custos implantando um escalonador automático programado no Google Kubernetes Engine (GKE). Esse tipo de escalonador automático aumenta ou diminui os clusters de acordo com uma programação baseada na hora do dia ou no dia da semana. Um escalonador automático programado é útil se seu tráfego tem uma fluxo de trabalho e fluxo previsíveis, por exemplo, se você for um varejista regional ou se o software for para funcionários com horas de trabalho limitadas a uma parte específica do dia. para criar um anexo da VLAN de monitoramento.
O tutorial é destinado a desenvolvedores e operadores que querem escalonar clusters de maneira confiável antes que os picos cheguem e reduzi-los novamente para economizar dinheiro à noite, nos fins de semana ou qualquer outro período quando menos usuários estiverem on-line. Para acompanhar este artigo, é necessário ter familiaridade com o Docker, o Kubernetes, o Kubernetes CronJobs, o GKE e o Linux.
Introdução
Muitos aplicativos usam padrões de tráfego desigual. Por exemplo, os workers de uma organização podem interagir com um aplicativo somente durante o dia. Como resultado, os servidores do data center desse aplicativo estão ociosos à noite.
Além de outros benefícios, Google Cloud pode ajudar você a economizar dinheiro ao alocar dinamicamente a infraestrutura de acordo com a carga do tráfego. Em alguns casos, uma configuração de escalonamento automático simples pode gerenciar o desafio de alocação de tráfego desigual. Se for o seu caso, não deixe de segui-lo. No entanto, em outros casos, alterações nítidas nos padrões de tráfego exigem configurações de escalonamento automático mais refinadas para evitar instabilidade do sistema durante o escalonamento vertical e evitar o provisionamento excessivo do cluster.
Este tutorial se concentra em cenários em que mudanças consideráveis nos padrões de tráfego são bem compreendidas e você quer dar dicas ao escalonador automático que sua infraestrutura está prestes a sofrer picos. Neste documento, mostramos como aumentar os clusters do GKE durante a manhã ou o anoitecer, mas é possível usar uma abordagem semelhante para aumentar e diminuir a capacidade de todos os eventos conhecidos, como eventos de escala de pico, campanhas ou tráfego de fim de semana.
Como reduzir um cluster se você tiver descontos por uso contínuo
Neste tutorial, explicamos como reduzir custos com a redução dos clusters do GKE para o mínimo durante o horário de pico. No entanto, se você comprou um desconto por uso contínuo, é importante entender como esses descontos funcionam em conjunto com o escalonamento automático.
Contratos de uso contínuo oferecem grandes descontos quando você se compromete a pagar por uma quantidade definida de recursos (vCPUs, memória e outros). No entanto, para determinar a quantidade de recursos a serem confirmados, você precisa saber com antecedência quantos recursos suas cargas de trabalho usarão ao longo do tempo. Para ajudar a reduzir seus custos, o diagrama a seguir ilustra quais recursos você precisa ou não incluir no planejamento.

Como o diagrama mostra, a alocação de recursos em um contrato de uso contínuo é estável. Os recursos cobertos por este contrato precisam estar em uso na maior parte do tempo para cumprir o compromisso firmado. Portanto, não inclua recursos usados durante picos no cálculo dos recursos confirmados. Para recursos suficientes, recomendamos que você use as opções do escalonador automático do GKE. Essas opções incluem o escalonador automático programado mencionado neste artigo ou outras opções gerenciadas que são discutidas em Práticas recomendadas para executar aplicativos Kubernetes otimizados para custo no GKE.
Se você já tiver um contrato de uso contínuo para uma determinada quantidade de recursos, não reduzirá seus custos diminuindo a escala do cluster abaixo desse mínimo. Nesses cenários, recomendamos que você tente programar alguns jobs para preencher as lacunas durante os períodos de baixa demanda de computação.
Arquitetura
No diagrama a seguir, mostramos a arquitetura da infraestrutura e o escalonador automático programado que você implantará neste tutorial. O escalonador automático programado consiste em um conjunto de componentes que trabalham juntos para gerenciar o escalonamento com base em uma programação.

Nesta arquitetura, um conjunto de CronJobs do Kubernetes exporta informações conhecidas sobre padrões de tráfego para uma métrica personalizada do Cloud Monitoring. Esses dados são lidos por um Escalonador automático horizontal de pods (HPA) do Kubernetes como entrada quando o HPA precisa escalonar a carga de trabalho. Além de outras métricas de carga, como a utilização de CPU de destino, o HPA decide como escalonar as réplicas para uma determinada implantação.
Preparar o ambiente
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
No Cloud Shell, configure o ID do projeto Google Cloud , o endereço de e-mail, a zona e a região de computação:
PROJECT_ID=YOUR_PROJECT_ID ALERT_EMAIL=YOUR_EMAIL_ADDRESS gcloud config set project $PROJECT_ID gcloud config set compute/region us-central1 gcloud config set compute/zone us-central1-fSubstitua:
YOUR_PROJECT_ID: o nome do projeto Google Cloud que você está usando.YOUR_EMAIL_ADDRESS: um endereço de e-mail para ser notificado quando o escalonador automático programado não estiver funcionando corretamente.
Se quiser, escolha uma região e zona diferentes neste tutorial.
Clone o repositório do GitHub
kubernetes-engine-samples:git clone https://github.com/GoogleCloudPlatform/kubernetes-engine-samples/ cd kubernetes-engine-samples/cost-optimization/gke-scheduled-autoscalerO código neste exemplo está estruturado nas seguintes pastas:
- Root: contém o código usado pelos CronJobs para exportar métricas personalizadas para o Cloud Monitoring.
k8s/: contém um exemplo de implantação que tem um HPA do Kubernetes.k8s/scheduled-autoscaler/: contém os CronJobs que exportam uma métrica personalizada e uma versão atualizada do HPA para ler a partir de uma métrica personalizada.k8s/load-generator/: contém uma implantação do Kubernetes que tem um aplicativo para simular o uso por hora. Uma implantação é um objeto da API Kubernetes que permite executar várias réplicas de pods distribuídos entre os nós de um cluster.monitoring/: contém os componentes do Cloud Monitoring que você configura neste tutorial.
No Cloud Shell, crie um cluster do GKE para executar o escalonador automático programado:
gcloud container clusters create scheduled-autoscaler \ --enable-ip-alias \ --release-channel=stable \ --machine-type=e2-standard-2 \ --enable-autoscaling --min-nodes=1 --max-nodes=10 \ --num-nodes=1 \ --autoscaling-profile=optimize-utilizationA resposta será semelhante a:
NAME LOCATION MASTER_VERSION MASTER_IP MACHINE_TYPE NODE_VERSION NUM_NODES STATUS scheduled-autoscaler us-central1-f 1.22.15-gke.100 34.69.187.253 e2-standard-2 1.22.15-gke.100 1 RUNNINGEsta não é uma configuração de produção, mas é uma configuração adequada para este tutorial. Nesta configuração, você configura o escalonador automático de cluster com pelo menos um nó e, no máximo, dez nós. Você também pode ativar o perfil
optimize-utilizationpara acelerar o processo de escalonamento vertical.Implante o aplicativo de exemplo sem o escalonador automático programado:
kubectl apply -f ./k8sAbra o arquivo
k8s/hpa-example.yaml.A lista a seguir mostra o conteúdo do arquivo.
Observe que o número mínimo de réplicas (
minReplicas) está definido como 10. Essa configuração também define o cluster que será escalonado com base na utilização da CPU (as configuraçõesname: cpuetype: Utilization).Aguarde até que o aplicativo fique disponível:
kubectl wait --for=condition=available --timeout=600s deployment/php-apache EXTERNAL_IP='' while [ -z $EXTERNAL_IP ] do EXTERNAL_IP=$(kubectl get svc php-apache -o jsonpath={.status.loadBalancer.ingress[0].ip}) [ -z $EXTERNAL_IP ] && sleep 10 done curl -w '\n' http://$EXTERNAL_IPQuando o aplicativo estiver disponível, a saída será a seguinte:
OK!Verifique as configurações:
kubectl get hpa php-apacheA resposta será semelhante a:
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE php-apache Deployment/php-apache 9%/60% 10 20 10 6d19hA coluna
REPLICASexibe10, que corresponde ao valor do campominReplicasno arquivohpa-example.yaml.Verificar se o número de nós aumentou para 4:
kubectl get nodesA resposta será semelhante a:
NAME STATUS ROLES AGE VERSION gke-scheduled-autoscaler-default-pool-64c02c0b-9kbt Ready <none> 21S v1.17.9-gke.1504 gke-scheduled-autoscaler-default-pool-64c02c0b-ghfr Ready <none> 21s v1.17.9-gke.1504 gke-scheduled-autoscaler-default-pool-64c02c0b-gvl9 Ready <none> 21s v1.17.9-gke.1504 gke-scheduled-autoscaler-default-pool-64c02c0b-t9sr Ready <none> 21s v1.17.9-gke.1504Ao criar o cluster, você define uma configuração mínima usando a sinalização
min-nodes=1. No entanto, o aplicativo implantado no início deste procedimento está solicitando mais infraestrutura porqueminReplicasno arquivohpa-example.yamlestá definido como 10.Definir
minReplicascomo um valor como 10 é uma estratégia comum usada por empresas como varejistas, que esperam um aumento repentino no tráfego nas primeiras horas do dia útil. No entanto, definir valores altos para o HPAminReplicaspode aumentar os custos porque o cluster não pode ser reduzido, nem mesmo à noite, quando o tráfego do aplicativo está baixo.No Cloud Shell, instale o adaptador de métricas personalizadas do Cloud Monitoring no cluster do GKE:
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/k8s-stackdriver/master/custom-metrics-stackdriver-adapter/deploy/production/adapter_new_resource_model.yaml kubectl wait --for=condition=available --timeout=600s deployment/custom-metrics-stackdriver-adapter -n custom-metricsEste adaptador ativa o escalonamento automático de pods com base em métricas personalizadas do Cloud Monitoring.
Crie um repositório no Artifact Registry e conceda permissões de leitura:
gcloud artifacts repositories create gke-scheduled-autoscaler \ --repository-format=docker --location=us-central1 gcloud auth configure-docker us-central1-docker.pkg.dev gcloud artifacts repositories add-iam-policy-binding gke-scheduled-autoscaler \ --location=us-central1 --member=allUsers --role=roles/artifactregistry.readerCrie e envie o código do exportador personalizado da métrica:
docker build -t us-central1-docker.pkg.dev/$PROJECT_ID/gke-scheduled-autoscaler/custom-metric-exporter . docker push us-central1-docker.pkg.dev/$PROJECT_ID/gke-scheduled-autoscaler/custom-metric-exporterImplante os CronJobs que exportam métricas personalizadas e implantam a versão atualizada do HPA que lê dessas métricas:
sed -i.bak s/PROJECT_ID/$PROJECT_ID/g ./k8s/scheduled-autoscaler/scheduled-autoscale-example.yaml kubectl apply -f ./k8s/scheduled-autoscalerAbra e examine o arquivo
k8s/scheduled-autoscaler/scheduled-autoscale-example.yaml.A lista a seguir mostra o conteúdo do arquivo.
Essa configuração especifica que os CronJobs precisam exportar a contagem de réplicas de pod sugeridas para uma métrica personalizada chamada
custom.googleapis.com/scheduled_autoscaler_examplecom base na hora do dia. Para facilitar a seção de monitoramento deste tutorial, a configuração do campo da programação define aumentos e reduções de horas por hora. Para produção, é possível personalizar essa programação para atender às necessidades do seu negócio.Abra e examine o arquivo
k8s/scheduled-autoscaler/hpa-example.yaml.A lista a seguir mostra o conteúdo do arquivo.
Essa configuração especifica que o objeto HPA deve substituir o HPA que foi implantado anteriormente. Observe que a configuração reduz o valor de
minReplicaspara 1. Isso significa que a carga de trabalho pode ser reduzida ao mínimo. A configuração também adiciona uma métrica externa (type: External). Essa adição significa que o escalonamento automático agora é acionado por dois fatores.Nesse cenário de várias métricas, o HPA calcula uma contagem de réplica proposta para cada métrica e, em seguida, escolhe a métrica que retorna o valor mais alto. É importante entender isso. O escalonador automático programado pode propor que, em um determinado momento, a contagem de pods precisa ser 1. Mas se a utilização real da CPU for maior que o esperado para um pod, o HPA criará mais réplicas.
Verifique novamente o número de nós e réplicas do HPA executando cada um desses comandos novamente:
kubectl get nodes kubectl get hpa php-apacheA saída vista depende do que o escalonador automático programado fez recentemente. Especificamente, os valores de
minReplicasenodesserão diferentes em pontos diferentes no ciclo de escalonamento.Por exemplo, em aproximadamente minutos 51 a 60 de cada hora (que representa um período de pico de tráfego), o valor de HPA para
minReplicasserá 10 e o valor denodesserá 4 para criar um anexo da VLAN de monitoramento.Por outro lado, para os minutos 1 a 50 (que representam um período de tráfego inferior), o valor de HPA
minReplicasserá 1 e o valornodesserá 1 ou 2, dependendo de quantos pods foram alocados e removidos. Para os valores mais baixos (minutos de 1 a 50), o cluster pode levar até 10 minutos para concluir a redução.No Cloud Shell, crie um canal de notificação:
gcloud beta monitoring channels create \ --display-name="Scheduled Autoscaler team (Primary)" \ --description="Primary contact method for the Scheduled Autoscaler team lead" \ --type=email \ --channel-labels=email_address=${ALERT_EMAIL}O resultado será assim:
Created notification channel NOTIFICATION_CHANNEL_ID.Esse comando cria um canal de notificação do tipo
emailpara simplificar as etapas do tutorial. Em ambientes de produção, recomendamos usar uma estratégia menos assíncrona definindo o canal de notificação comosmsoupagerduty.Defina uma variável que tenha o valor que foi exibido no marcador
NOTIFICATION_CHANNEL_ID:NOTIFICATION_CHANNEL_ID=NOTIFICATION_CHANNEL_IDImplante a política de alertas:
gcloud alpha monitoring policies create \ --policy-from-file=./monitoring/alert-policy.yaml \ --notification-channels=$NOTIFICATION_CHANNEL_IDO arquivo
alert-policy.yamlcontém a especificação para enviar um alerta se a métrica estiver ausente após cinco minutos.Acesse a página Alerta do Cloud Monitoring para ver a política de alertas.
Clique em Política do escalonador automático programado e verifique os detalhes da política de alertas.
Implante o gerador de carga no Cloud Shell:
kubectl apply -f ./k8s/load-generatorA listagem a seguir mostra o script
load-generator:command: ["/bin/sh", "-c"] args: - while true; do RESP=$(wget -q -O- http://php-apache.default.svc.cluster.local); echo "$(date +%H)=$RESP"; sleep $(date +%H | awk '{ print "s("$0"/3*a(1))*0.5+0.5" }' | bc -l); done;Esse script é executado no cluster até você excluir a implantação
load-generator. Ela faz solicitações ao seu serviçophp-apachea cada poucos milissegundos. O comandosleepsimula alterações de distribuição de carga durante o dia. Usando um script que gera tráfego dessa maneira, você entende o que acontece quando combina a utilização da CPU e métricas personalizadas na configuração do HPA.No Cloud Shell, crie um novo painel:
gcloud monitoring dashboards create \ --config-from-file=./monitoring/dashboard.yamlAcesse a página Painéis do Cloud Monitoring.
Clique em Painel do escalonador automático programado.
O painel exibe três gráficos. Você precisa aguardar pelo menos duas horas (idealmente, 24 horas ou mais) para ver a dinâmica de aumentos e reduções de escala e ver como a diferentes distribuições de carga durante o dia afeta o escalonamento automático para criar um anexo da VLAN de monitoramento.
Para ter uma ideia do que é exibido nos gráficos, você pode estudar os seguintes gráficos, que apresentam uma visualização de dia inteiro:
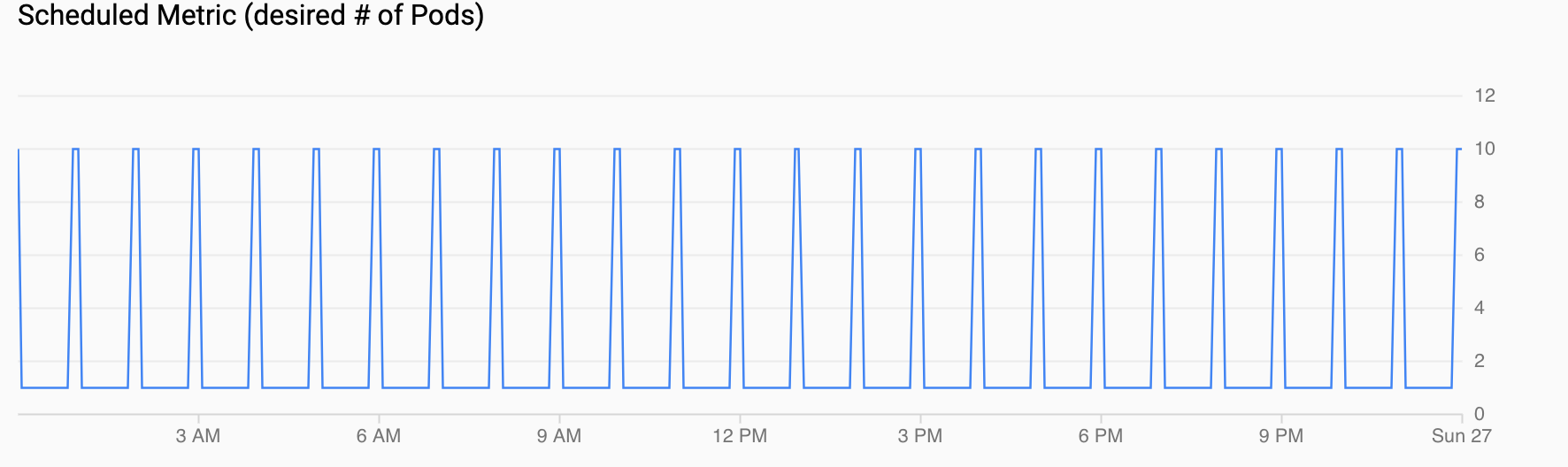
A Métrica programada (número de pods pretendidos) mostra uma série temporal da métrica personalizada que está sendo exportada para o Cloud Monitoring por meio de CronJobs configurados em Como configurar um escalonamento automático programado.
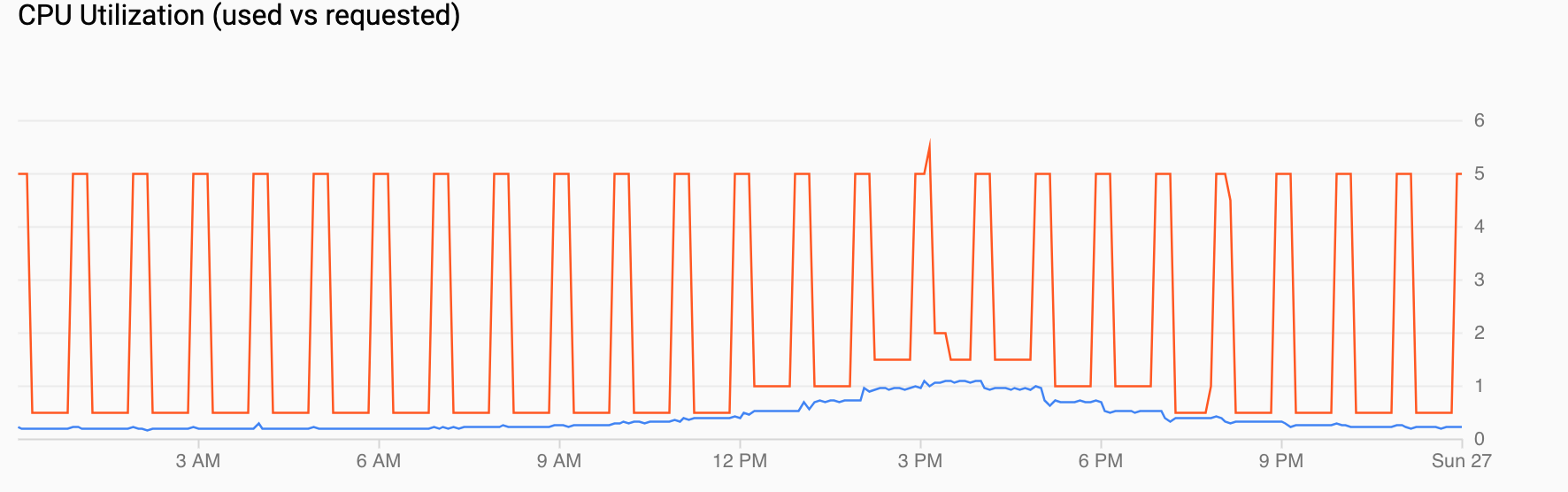
A Uso da CPU (solicitada versus usada) mostra uma série temporal da CPU solicitada (vermelha) e a utilização real da CPU (azul). Quando a carga é baixa, o HPA respeita a decisão de uso feita pelo escalonador automático programado. No entanto, quando o tráfego aumenta, o HPA aumenta o número de pods conforme necessário, já que você pode ver os pontos de dados entre 12h e 18h.
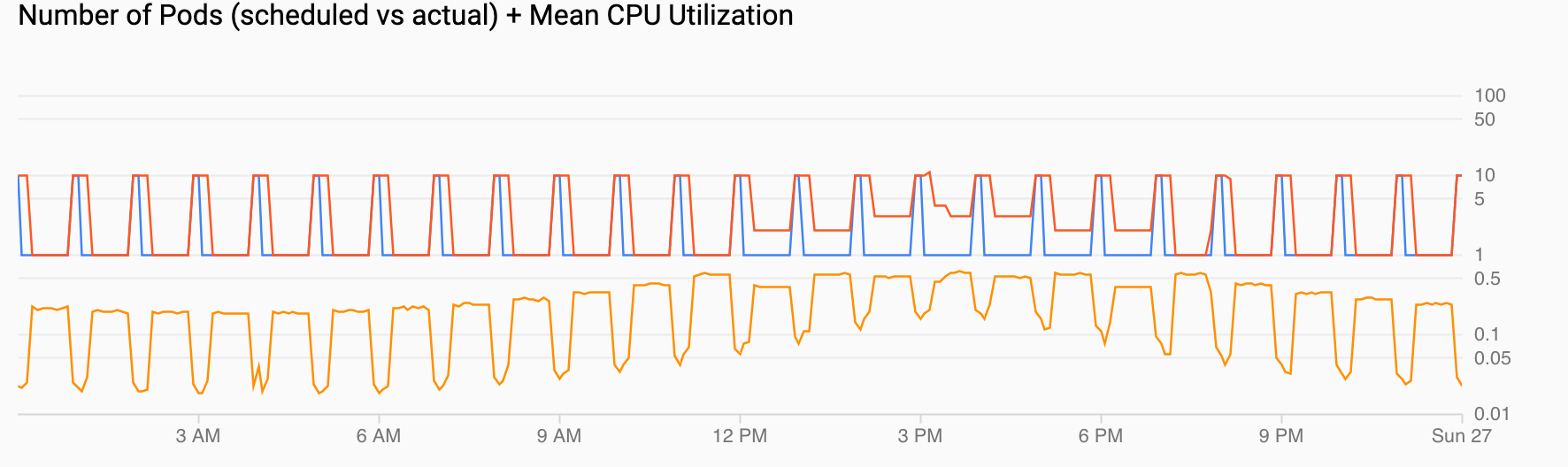
Número de pods (programados x reais) + Uso médio da CPU mostra uma visualização semelhante às anteriores. A contagem de pods (vermelho) aumenta para 10 a cada hora conforme programado (azul). O número de pods aumenta e diminui naturalmente ao longo do tempo em resposta ao carregamento (12h e 18h). O uso médio da CPU (laranja) permanece abaixo da meta que você definiu (60%).
Criar o cluster do GKE
Implantar o aplicativo de exemplo
Configurar um escalonador automático programado
Como configurar alertas para quando o escalonador automático programado não funcionar corretamente
Em um ambiente de produção, você normalmente quer saber quando os CronJobs não estão preenchendo a métrica personalizada. Para essa finalidade, você pode criar um alerta que é acionado quando qualquer fluxo custom.googleapis.com/scheduled_autoscaler_example fica restrito por um período de cinco minutos.
Gerar carga para o aplicativo de exemplo
Como visualizar o escalonamento em resposta ao tráfego ou às métricas programadas
Nesta seção, são apresentadas as visualizações que mostram os efeitos do escalonamento vertical e horizontal.