Anda dapat mengaktifkan komponen tambahan seperti Flink saat membuat cluster Dataproc menggunakan fitur Komponen opsional. Halaman ini menunjukkan cara membuat cluster Dataproc dengan komponen opsional Apache Flink diaktifkan (cluster Flink), lalu menjalankan tugas Flink di cluster.
Anda dapat menggunakan cluster Flink untuk:
Jalankan tugas Flink menggunakan resource Dataproc
Jobsdari Google Cloud konsol, Google Cloud CLI, atau Dataproc API.Jalankan tugas Flink menggunakan
flinkCLI yang berjalan di node master cluster Flink.Menjalankan Flink di cluster yang di-Kerberize
Buat cluster Dataproc Flink
Anda dapat menggunakan Google Cloud konsol, Google Cloud CLI, atau Dataproc API untuk membuat cluster Dataproc yang mengaktifkan komponen Flink di cluster.
Rekomendasi: Gunakan cluster VM 1 master standar dengan komponen Flink. Cluster mode Ketersediaan Tinggi Dataproc (dengan 3 VM master) tidak mendukung mode ketersediaan tinggi Flink.
Konsol
Untuk membuat cluster Dataproc Flink menggunakan konsol Google Cloud , lakukan langkah-langkah berikut:
Buka halaman Dataproc Membuat cluster Dataproc di Compute Engine.
- Panel Set up cluster dipilih.
- Di bagian Versi, konfirmasi atau ubah
Jenis dan Versi Gambar. Versi image cluster menentukan
versi komponen Flink yang diinstal di cluster.
- Versi image harus 1.5 atau yang lebih tinggi untuk mengaktifkan komponen Flink di cluster (Lihat Versi Dataproc yang didukung untuk melihat daftar versi komponen yang disertakan dalam setiap rilis image Dataproc).
- Versi image harus [TBD] atau yang lebih baru untuk menjalankan tugas Flink melalui Dataproc Jobs API (lihat Menjalankan tugas Flink Dataproc).
- Di bagian Komponen:
- Di bagian Component Gateway, pilih Aktifkan component gateway. Anda harus mengaktifkan Component Gateway untuk mengaktifkan link Component Gateway ke UI Flink History Server. Mengaktifkan Gateway Komponen juga memungkinkan akses ke antarmuka web Flink Job Manager yang berjalan di cluster Flink.
- Di bagian Komponen opsional, pilih Flink dan komponen opsional lainnya yang akan diaktifkan di cluster Anda.
- Di bagian Versi, konfirmasi atau ubah
Jenis dan Versi Gambar. Versi image cluster menentukan
versi komponen Flink yang diinstal di cluster.
Klik panel Sesuaikan cluster (opsional).
Di bagian Cluster properties, klik Add Properties untuk setiap properti cluster opsional yang akan ditambahkan ke cluster Anda. Anda dapat menambahkan properti berawalan
flinkuntuk mengonfigurasi properti Flink di/etc/flink/conf/flink-conf.yamlyang akan berfungsi sebagai default untuk aplikasi Flink yang Anda jalankan di cluster.Contoh:
- Tetapkan
flink:historyserver.archive.fs.diruntuk menentukan lokasi Cloud Storage tempat menulis file histori tugas Flink (lokasi ini akan digunakan oleh Flink History Server yang berjalan di cluster Flink). - Tetapkan slot tugas Flink dengan
flink:taskmanager.numberOfTaskSlots=n.
- Tetapkan
Di bagian Metadata cluster kustom, klik Tambahkan Metadata untuk menambahkan metadata opsional. Misalnya, tambahkan
flink-start-yarn-sessiontrueuntuk menjalankan daemon Flink YARN (/usr/bin/flink-yarn-daemon) di latar belakang pada node master cluster untuk memulai sesi Flink YARN (lihat Mode sesi Flink).
Jika Anda menggunakan versi image Dataproc 2.0 atau yang lebih lama, klik panel Kelola keamanan (opsional), lalu di bagian Akses project, pilih
Enables the cloud-platform scope for this cluster. Cakupancloud-platformdiaktifkan secara default saat Anda membuat cluster yang menggunakan Dataproc versi image 2.1 atau yang lebih baru.
- Panel Set up cluster dipilih.
Klik Create untuk membuat cluster.
gcloud
Untuk membuat cluster Dataproc Flink menggunakan gcloud CLI, jalankan perintah gcloud dataproc clusters create secara lokal di jendela terminal atau di Cloud Shell:
gcloud dataproc clusters create CLUSTER_NAME \ --region=REGION \ --image-version=DATAPROC_IMAGE_VERSION \ --optional-components=FLINK \ --enable-component-gateway \ --properties=PROPERTIES ... other flags
Catatan:
- CLUSTER_NAME: Tentukan nama cluster.
- REGION: Tentukan region Compute Engine tempat cluster akan berada.
DATAPROC_IMAGE_VERSION: Secara opsional, tentukan versi image yang akan digunakan di cluster. Versi image cluster menentukan versi komponen Flink yang diinstal di cluster.
Versi image harus 1.5 atau yang lebih tinggi untuk mengaktifkan komponen Flink di cluster (Lihat Versi Dataproc yang didukung untuk melihat daftar versi komponen yang disertakan dalam setiap rilis image Dataproc).
Versi image harus [TBD] atau yang lebih baru untuk menjalankan tugas Flink melalui Dataproc Jobs API (lihat Menjalankan tugas Flink Dataproc).
--optional-components: Anda harus menentukan komponenFLINKuntuk menjalankan tugas Flink dan Layanan Web Flink HistoryServer di cluster.--enable-component-gateway: Anda harus mengaktifkan Component Gateway untuk mengaktifkan link Component Gateway ke UI Flink History Server. Mengaktifkan Gateway Komponen juga memungkinkan akses ke antarmuka web Pengelola Tugas Flink yang berjalan di cluster Flink.PROPERTIES. Secara opsional, tentukan satu atau beberapa properti cluster.
Saat membuat cluster Dataproc dengan versi image
2.0.67+ dan2.1.15+, Anda dapat menggunakan tanda--propertiesuntuk mengonfigurasi properti Flink di/etc/flink/conf/flink-conf.yamlyang akan bertindak sebagai default untuk aplikasi Flink yang Anda jalankan di cluster.Anda dapat menetapkan
flink:historyserver.archive.fs.diruntuk menentukan lokasi Cloud Storage tempat menulis file histori tugas Flink (lokasi ini akan digunakan oleh Flink History Server yang berjalan di cluster Flink).Contoh beberapa properti:
--properties=flink:historyserver.archive.fs.dir=gs://my-bucket/my-flink-cluster/completed-jobs,flink:taskmanager.numberOfTaskSlots=2Flag lainnya:
- Anda dapat menambahkan tanda
--metadata flink-start-yarn-session=trueopsional untuk menjalankan daemon Flink YARN (/usr/bin/flink-yarn-daemon) di latar belakang pada node master cluster untuk memulai sesi Flink YARN (lihat Mode sesi Flink).
- Anda dapat menambahkan tanda
Saat menggunakan versi image 2.0 atau yang lebih lama, Anda dapat menambahkan tanda
--scopes=https://www.googleapis.com/auth/cloud-platformuntuk mengaktifkan akses ke Google Cloud API oleh cluster Anda (lihat Praktik terbaik cakupan). Cakupancloud-platformdiaktifkan secara default saat Anda membuat cluster yang menggunakan Dataproc versi image 2.1 atau yang lebih baru.
API
Untuk membuat cluster Dataproc Flink menggunakan Dataproc API, kirim permintaan clusters.create sebagai berikut:
Catatan:
Tetapkan SoftwareConfig.Component ke
FLINK.Anda dapat secara opsional menyetel
SoftwareConfig.imageVersionuntuk menentukan versi image yang akan digunakan di cluster. Versi image cluster menentukan versi komponen Flink yang diinstal di cluster.Versi image harus 1.5 atau yang lebih tinggi untuk mengaktifkan komponen Flink di cluster (Lihat Versi Dataproc yang didukung untuk melihat daftar versi komponen yang disertakan dalam setiap rilis image Dataproc).
Versi image harus [TBD] atau yang lebih baru untuk menjalankan tugas Flink melalui Dataproc Jobs API (lihat Menjalankan tugas Flink Dataproc).
Tetapkan EndpointConfig.enableHttpPortAccess ke
trueuntuk mengaktifkan link Component Gateway ke UI Flink History Server. Mengaktifkan Gateway Komponen juga memungkinkan akses ke antarmuka web Pengelola Tugas Flink yang berjalan di cluster Flink.Anda dapat secara opsional menetapkan
SoftwareConfig.propertiesuntuk menentukan satu atau beberapa properti cluster.- Anda dapat menentukan properti Flink yang akan bertindak sebagai
default untuk aplikasi Flink yang Anda jalankan di cluster. Misalnya,
Anda dapat menetapkan
flink:historyserver.archive.fs.diruntuk menentukan lokasi Cloud Storage tempat menulis file histori tugas Flink (lokasi ini akan digunakan oleh Flink History Server yang berjalan di cluster Flink).
- Anda dapat menentukan properti Flink yang akan bertindak sebagai
default untuk aplikasi Flink yang Anda jalankan di cluster. Misalnya,
Anda dapat menetapkan
Anda dapat secara opsional menetapkan:
GceClusterConfig.metadata. Misalnya, untuk menentukanflink-start-yarn-sessiontrueuntuk menjalankan daemon Flink YARN (/usr/bin/flink-yarn-daemon) di latar belakang pada node master cluster untuk memulai sesi Flink YARN (lihat Mode sesi Flink).- GceClusterConfig.serviceAccountScopes
ke
https://www.googleapis.com/auth/cloud-platform(cakupancloud-platform) saat menggunakan versi image 2.0 atau yang lebih lama untuk mengaktifkan akses ke Google Cloud API oleh cluster Anda (lihat Praktik terbaik cakupan). Cakupancloud-platformdiaktifkan secara default saat Anda membuat cluster yang menggunakan Dataproc versi image 2.1 atau yang lebih baru.
Setelah Anda membuat cluster Flink
- Gunakan link
Flink History Serverdi Component Gateway untuk melihat Flink History Server yang berjalan di cluster Flink. - Gunakan
YARN ResourceManager linkdi Gateway Komponen untuk melihat antarmuka web Flink Job Manager yang berjalan di cluster Flink . - Buat Dataproc Persistent History Server untuk melihat file histori tugas Flink yang ditulis oleh cluster Flink yang ada dan yang dihapus.
Menjalankan tugas Flink menggunakan resource Jobs Dataproc
Anda dapat menjalankan tugas Flink menggunakan resource Dataproc Jobs dari
Google Cloud konsol, Google Cloud CLI, atau Dataproc API.
Konsol
Untuk mengirimkan contoh tugas wordcount Flink dari konsol:
Buka halaman Dataproc Submit a job di Google Cloud console di browser Anda.
Isi kolom di halaman Kirim tugas:
- Pilih nama Cluster Anda dari daftar cluster.
- Tetapkan Jenis pekerjaan ke
Flink. - Tetapkan Main class or jar ke
org.apache.flink.examples.java.wordcount.WordCount. - Setel File jar ke
file:///usr/lib/flink/examples/batch/WordCount.jar.file:///menunjukkan file yang ada di cluster. Dataproc menginstalWordCount.jarsaat membuat cluster Flink.- Kolom ini juga menerima jalur Cloud Storage
(
gs://BUCKET/JARFILE) atau jalur Hadoop Distributed File System (HDFS) (hdfs://PATH_TO_JAR).
Klik Kirim.
- Output driver tugas ditampilkan di halaman Detail tugas.
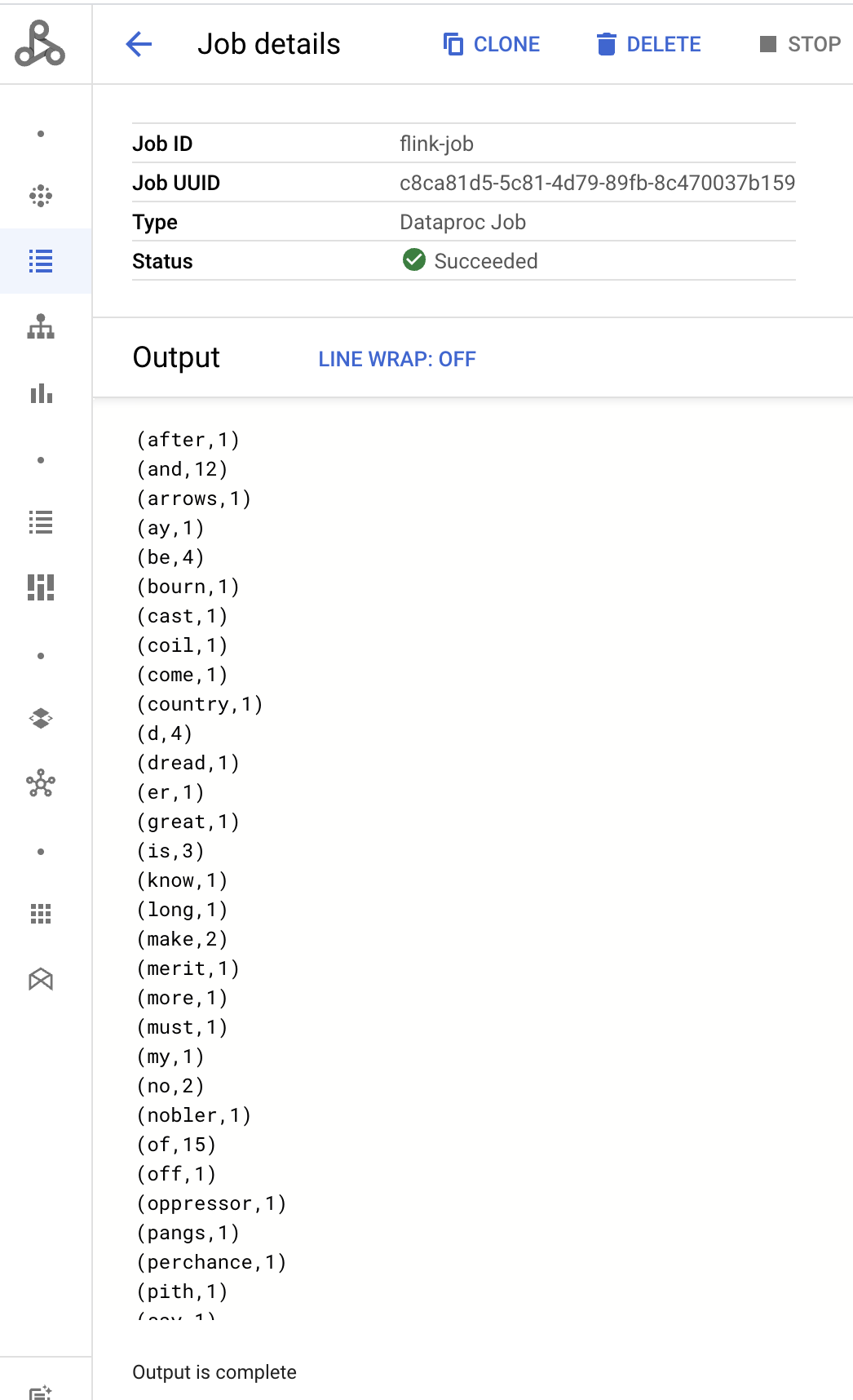
- Tugas Flink dicantumkan di halaman Dataproc Jobs di konsol Google Cloud .
- Klik Hentikan atau Hapus dari halaman Tugas atau Detail tugas untuk menghentikan atau menghapus tugas.
gcloud
Untuk mengirimkan tugas Flink ke cluster Flink Dataproc, jalankan perintah gcloud CLI gcloud dataproc jobs submit secara lokal di jendela terminal atau di Cloud Shell.
gcloud dataproc jobs submit flink \ --cluster=CLUSTER_NAME \ --region=REGION \ --class=MAIN_CLASS \ --jar=JAR_FILE \ -- JOB_ARGS
Catatan:
- CLUSTER_NAME: Tentukan nama cluster Dataproc Flink untuk mengirimkan tugas.
- REGION: Tentukan region Compute Engine tempat cluster berada.
- MAIN_CLASS: Tentukan class
mainaplikasi Flink Anda, seperti:org.apache.flink.examples.java.wordcount.WordCount
- JAR_FILE: Tentukan file jar aplikasi Flink. Anda dapat menentukan:
- File jar yang diinstal di cluster, menggunakan awalan
file:///` :file:///usr/lib/flink/examples/streaming/TopSpeedWindowing.jarfile:///usr/lib/flink/examples/batch/WordCount.jar
- File jar di Cloud Storage:
gs://BUCKET/JARFILE - File jar di HDFS:
hdfs://PATH_TO_JAR
- File jar yang diinstal di cluster, menggunakan awalan
JOB_ARGS: Secara opsional, tambahkan argumen tugas setelah tanda hubung ganda (
--).Setelah mengirimkan tugas, output driver tugas akan ditampilkan di terminal lokal atau Cloud Shell.
Program execution finished Job with JobID 829d48df4ebef2817f4000dfba126e0f has finished. Job Runtime: 13610 ms ... (after,1) (and,12) (arrows,1) (ay,1) (be,4) (bourn,1) (cast,1) (coil,1) (come,1)
REST
Bagian ini menunjukkan cara mengirimkan tugas Flink ke cluster Flink Dataproc menggunakan Dataproc jobs.submit API.
Sebelum menggunakan salah satu data permintaan, lakukan penggantian berikut:
- PROJECT_ID: Google Cloud project ID
- REGION: cluster region
- CLUSTER_NAME: Tentukan nama cluster Dataproc Flink yang akan digunakan untuk mengirimkan tugas
Metode HTTP dan URL:
POST https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/jobs:submit
Meminta isi JSON:
{
"job": {
"placement": {
"clusterName": "CLUSTER_NAME"
},
"flinkJob": {
"mainClass": "org.apache.flink.examples.java.wordcount.WordCount",
"jarFileUris": [
"file:///usr/lib/flink/examples/batch/WordCount.jar"
]
}
}
}
Untuk mengirim permintaan Anda, perluas salah satu opsi berikut:
Anda akan melihat respons JSON seperti berikut:
{
"reference": {
"projectId": "PROJECT_ID",
"jobId": "JOB_ID"
},
"placement": {
"clusterName": "CLUSTER_NAME",
"clusterUuid": "CLUSTER_UUID"
},
"flinkJob": {
"mainClass": "org.apache.flink.examples.java.wordcount.WordCount",
"args": [
"1000"
],
"jarFileUris": [
"file:///usr/lib/flink/examples/batch/WordCount.jar"
]
},
"status": {
"state": "PENDING",
"stateStartTime": "2020-10-07T20:16:21.759Z"
},
"jobUuid": "JOB_UUID"
}
- Tugas Flink dicantumkan di halaman Dataproc Jobs di konsol Google Cloud .
- Anda dapat mengklik Hentikan atau Hapus dari halaman Tugas atau Detail tugas di konsol Google Cloud untuk menghentikan atau menghapus tugas.
Menjalankan tugas Flink menggunakan flink CLI
Daripada
menjalankan tugas Flink menggunakan resource Jobs Dataproc,
Anda dapat menjalankan tugas Flink di node master cluster Flink menggunakan CLI flink.
Bagian berikut menjelaskan berbagai cara untuk menjalankan tugas CLI flink di
cluster Dataproc Flink.
SSH ke node master: Gunakan utilitas SSH untuk membuka jendela terminal di VM master cluster.
Setel classpath: Lakukan inisialisasi classpath Hadoop dari jendela terminal SSH di VM master cluster Flink:
export HADOOP_CLASSPATH=$(hadoop classpath)Menjalankan tugas Flink: Anda dapat menjalankan tugas Flink dalam berbagai mode deployment di YARN: mode aplikasi, per-tugas, dan sesi.
Mode aplikasi: Mode Aplikasi Flink didukung oleh versi image Dataproc 2.0 dan yang lebih baru. Mode ini menjalankan metode
main()tugas di Pengelola Tugas YARN. Cluster dimatikan setelah tugas selesai.Contoh pengiriman tugas:
flink run-application \ -t yarn-application \ -Djobmanager.memory.process.size=1024m \ -Dtaskmanager.memory.process.size=2048m \ -Djobmanager.heap.mb=820 \ -Dtaskmanager.heap.mb=1640 \ -Dtaskmanager.numberOfTaskSlots=2 \ -Dparallelism.default=4 \ /usr/lib/flink/examples/batch/WordCount.jarMencantumkan tugas yang sedang berjalan:
./bin/flink list -t yarn-application -Dyarn.application.id=application_XXXX_YYMembatalkan tugas yang sedang berjalan:
./bin/flink cancel -t yarn-application -Dyarn.application.id=application_XXXX_YY <jobId>Mode per tugas: Mode Flink ini menjalankan metode
main()tugas di sisi klien.Contoh pengiriman tugas:
flink run \ -m yarn-cluster \ -p 4 \ -ys 2 \ -yjm 1024m \ -ytm 2048m \ /usr/lib/flink/examples/batch/WordCount.jarMode sesi: Memulai sesi Flink YARN yang berjalan lama, lalu mengirimkan satu atau beberapa tugas ke sesi.
Mulai sesi: Anda dapat memulai sesi Flink dengan salah satu cara berikut:
Buat cluster Flink, dengan menambahkan flag
--metadata flink-start-yarn-session=trueke perintahgcloud dataproc clusters create(Lihat Membuat cluster Dataproc Flink). Dengan mengaktifkan tanda ini, setelah cluster dibuat, Dataproc akan menjalankan/usr/bin/flink-yarn-daemonuntuk memulai sesi Flink di cluster.ID aplikasi YARN sesi disimpan di
/tmp/.yarn-properties-${USER}. Anda dapat mencantumkan ID dengan perintahyarn application -list.Jalankan skrip Flink
yarn-session.shyang telah diinstal sebelumnya di VM master cluster, dengan setelan kustom:Contoh dengan setelan kustom:
/usr/lib/flink/bin/yarn-session.sh \ -s 1 \ -jm 1024m \ -tm 2048m \ -nm flink-dataproc \ --detachedJalankan skrip wrapper
/usr/bin/flink-yarn-daemonFlink dengan setelan default:. /usr/bin/flink-yarn-daemon
Mengirimkan tugas ke sesi: Jalankan perintah berikut untuk mengirimkan tugas Flink ke sesi.
flink run -m <var>FLINK_MASTER_URL</var>/usr/lib/flink/examples/batch/WordCount.jar- FLINK_MASTER_URL: URL, termasuk host dan port, dari VM master Flink tempat tugas dijalankan.
Hapus
http:// prefixdari URL. URL ini tercantum dalam output perintah saat Anda memulai sesi Flink. Anda dapat menjalankan perintah berikut untuk mencantumkan URL ini di kolomTracking-URL:
yarn application -list -appId=<yarn-app-id> | sed 's#http://##' ```- FLINK_MASTER_URL: URL, termasuk host dan port, dari VM master Flink tempat tugas dijalankan.
Hapus
Mencantumkan tugas dalam sesi: Untuk mencantumkan tugas Flink dalam sesi, lakukan salah satu hal berikut:
Jalankan
flink listtanpa argumen. Perintah ini mencari ID aplikasi YARN sesi di/tmp/.yarn-properties-${USER}.Dapatkan ID aplikasi YARN sesi dari
/tmp/.yarn-properties-${USER}atau outputyarn application -list, lalu jalankan<code>flink list -yid YARN_APPLICATION_ID.Jalankan
flink list -m FLINK_MASTER_URL.
Menghentikan sesi: Untuk menghentikan sesi, dapatkan ID aplikasi YARN sesi dari
/tmp/.yarn-properties-${USER}atau outputyarn application -list, lalu jalankan salah satu perintah berikut:echo "stop" | /usr/lib/flink/bin/yarn-session.sh -id YARN_APPLICATION_IDyarn application -kill YARN_APPLICATION_ID
Menjalankan tugas Apache Beam di Flink
Anda dapat menjalankan tugas Apache Beam di
Dataproc menggunakan
FlinkRunner.
Anda dapat menjalankan tugas Beam di Flink dengan cara berikut:
- Tugas Java Beam
- Tugas Portable Beam
Tugas Java Beam
Kemasi tugas Beam Anda ke dalam file JAR. Sediakan file JAR yang dibundel dengan dependensi yang diperlukan untuk menjalankan tugas.
Contoh berikut menjalankan tugas Java Beam dari node master cluster Dataproc.
Buat cluster Dataproc dengan komponen Flink yang diaktifkan.
gcloud dataproc clusters create CLUSTER_NAME \ --optional-components=FLINK \ --image-version=DATAPROC_IMAGE_VERSION \ --region=REGION \ --enable-component-gateway \ --scopes=https://www.googleapis.com/auth/cloud-platform--optional-components: Flink.--image-version: versi image cluster, yang menentukan versi Flink yang diinstal pada cluster (misalnya, lihat versi komponen Apache Flink yang tercantum untuk empat versi rilis image 2.0.x terbaru dan sebelumnya).--region: region Dataproc yang didukung.--enable-component-gateway: mengaktifkan akses ke UI Pengelola Tugas Flink.--scopes: mengaktifkan akses ke Google Cloud API oleh cluster Anda (lihat Praktik terbaik cakupan). Cakupancloud-platformdiaktifkan secara default (Anda tidak perlu menyertakan setelan tanda ini) saat Anda membuat cluster yang menggunakan versi image Dataproc 2.1 atau yang lebih baru.
Gunakan utilitas SSH untuk membuka jendela terminal di node master cluster Flink.
Mulai sesi Flink YARN di node master cluster Dataproc.
. /usr/bin/flink-yarn-daemonCatat versi Flink di cluster Dataproc Anda.
flink --versionDi komputer lokal, buat contoh penghitungan kata Beam kanonis di Java.
Pilih versi Beam yang kompatibel dengan versi Flink di cluster Dataproc Anda. Lihat tabel Kompatibilitas Versi Flink yang mencantumkan kompatibilitas versi Beam-Flink.
Buka file POM yang dihasilkan. Periksa versi runner Beam Flink yang ditentukan oleh tag
<flink.artifact.name>. Jika versi runner Beam Flink dalam nama artefak Flink tidak cocok dengan versi Flink di cluster Anda, perbarui nomor versi agar cocok.mvn archetype:generate \ -DarchetypeGroupId=org.apache.beam \ -DarchetypeArtifactId=beam-sdks-java-maven-archetypes-examples \ -DarchetypeVersion=BEAM_VERSION \ -DgroupId=org.example \ -DartifactId=word-count-beam \ -Dversion="0.1" \ -Dpackage=org.apache.beam.examples \ -DinteractiveMode=falseKemas contoh jumlah kata.
mvn package -Pflink-runnerUpload file uber JAR yang dipaketkan,
word-count-beam-bundled-0.1.jar(~135 MB) ke node master cluster Dataproc Anda. Anda dapat menggunakangcloud storage cpuntuk transfer file yang lebih cepat ke cluster Dataproc dari Cloud Storage.Di terminal lokal, buat bucket Cloud Storage, lalu upload JAR uber.
gcloud storage buckets create BUCKET_NAMEgcloud storage cp target/word-count-beam-bundled-0.1.jar gs://BUCKET_NAME/Di node master Dataproc, download uber JAR.
gcloud storage cp gs://BUCKET_NAME/word-count-beam-bundled-0.1.jar .
Jalankan tugas Java Beam di node master cluster Dataproc.
flink run -c org.apache.beam.examples.WordCount word-count-beam-bundled-0.1.jar \ --runner=FlinkRunner \ --output=gs://BUCKET_NAME/java-wordcount-outPeriksa apakah hasil telah ditulis ke bucket Cloud Storage Anda.
gcloud storage cat gs://BUCKET_NAME/java-wordcount-out-SHARD_IDHentikan sesi Flink YARN.
yarn application -listyarn application -kill YARN_APPLICATION_ID
Tugas Beam Portabel
Untuk menjalankan tugas Beam yang ditulis dalam Python, Go, dan bahasa lain yang didukung, Anda dapat menggunakan FlinkRunner dan PortableRunner seperti yang dijelaskan di halaman Flink Runner Beam (lihat juga Peta Jalan Framework Portabilitas).
Contoh berikut menjalankan tugas Beam portabel di Python dari node master cluster Dataproc.
Buat cluster Dataproc dengan komponen Flink dan Docker yang diaktifkan.
gcloud dataproc clusters create CLUSTER_NAME \ --optional-components=FLINK,DOCKER \ --image-version=DATAPROC_IMAGE_VERSION \ --region=REGION \ --enable-component-gateway \ --scopes=https://www.googleapis.com/auth/cloud-platformCatatan:
--optional-components: Flink dan Docker.--image-version: Versi image cluster, yang menentukan versi Flink yang diinstal di cluster (misalnya, lihat versi komponen Apache Flink yang tercantum untuk empat versi rilis image 2.0.x terbaru dan sebelumnya).--region: Region Dataproc yang tersedia.--enable-component-gateway: Aktifkan akses ke UI Flink Job Manager.--scopes: Aktifkan akses ke API Google Cloud oleh cluster Anda (lihat Praktik terbaik cakupan). Cakupancloud-platformdiaktifkan secara default (Anda tidak perlu menyertakan setelan tanda ini) saat Anda membuat cluster yang menggunakan versi image Dataproc 2.1 atau yang lebih baru.
Gunakan gcloud CLI secara lokal atau di Cloud Shell untuk membuat bucket Cloud Storage. Anda akan menentukan BUCKET_NAME saat menjalankan program wordcount contoh.
gcloud storage buckets create BUCKET_NAMEDi jendela terminal pada VM cluster, mulai sesi Flink YARN. Catat URL master Flink, alamat master Flink tempat tugas dijalankan. Anda akan menentukan FLINK_MASTER_URL saat Anda menjalankan program wordcount contoh.
. /usr/bin/flink-yarn-daemonTampilkan dan catat versi Flink yang menjalankan cluster Dataproc. Anda akan menentukan FLINK_VERSION saat Anda menjalankan program wordcount contoh.
flink --versionInstal library Python yang diperlukan untuk tugas di node master cluster.
Instal versi Beam yang kompatibel dengan versi Flink di cluster.
python -m pip install apache-beam[gcp]==BEAM_VERSIONJalankan contoh penghitungan kata di node master cluster.
python -m apache_beam.examples.wordcount \ --runner=FlinkRunner \ --flink_version=FLINK_VERSION \ --flink_master=FLINK_MASTER_URL --flink_submit_uber_jar \ --output=gs://BUCKET_NAME/python-wordcount-outCatatan:
--runner:FlinkRunner.--flink_version: FLINK_VERSION, yang dicatat sebelumnya.--flink_master: FLINK_MASTER_URL, yang dicatat sebelumnya.--flink_submit_uber_jar: Gunakan JAR uber untuk mengeksekusi tugas Beam.--output: BUCKET_NAME, yang dibuat sebelumnya.
Pastikan hasil telah ditulis ke bucket Anda.
gcloud storage cat gs://BUCKET_NAME/python-wordcount-out-SHARD_IDHentikan sesi Flink YARN.
- Dapatkan ID aplikasi.
yarn application -list1. Insert the <var>YARN_APPLICATION_ID</var>, then stop the session.yarn application -kill
Menjalankan Flink di cluster yang di-Kerberize
Komponen Dataproc Flink mendukung cluster yang di-Kerberize. Tiket Kerberos yang valid diperlukan untuk mengirimkan dan mempertahankan tugas Flink atau untuk memulai cluster Flink. Secara default, tiket Kerberos tetap valid selama tujuh hari.
Mengakses UI Flink Job Manager
Antarmuka web Flink Job Manager tersedia saat tugas Flink atau cluster sesi Flink sedang berjalan. Untuk menggunakan antarmuka web:
- Buat cluster Dataproc Flink.
- Setelah pembuatan cluster, klik Component Gateway YARN ResourceManager link di tab Web Interface pada halaman Cluster details di konsol Google Cloud .
- Di UI YARN Resource Manager, identifikasi entri aplikasi cluster Flink. Bergantung pada status penyelesaian tugas, link ApplicationMaster
atau History akan dicantumkan.
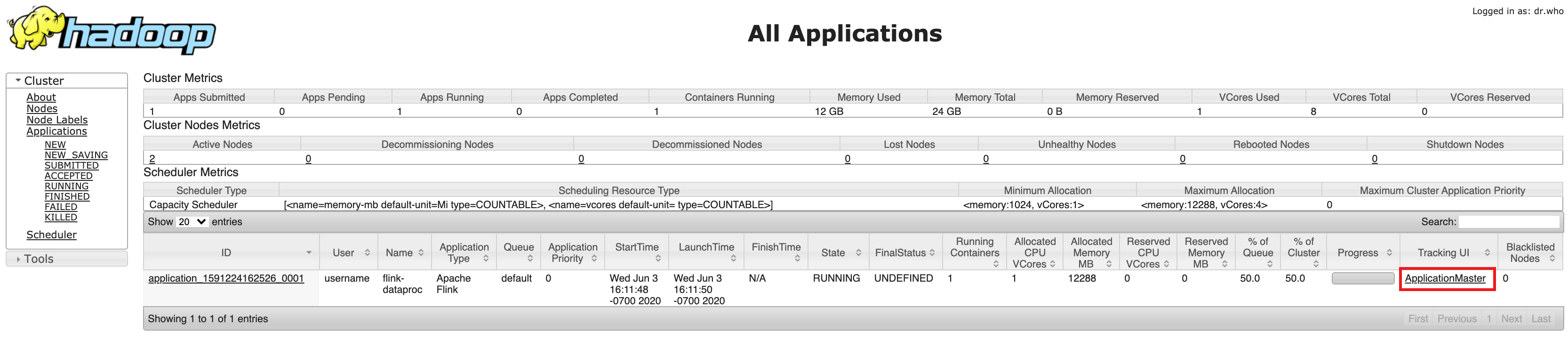
- Untuk tugas streaming yang berjalan lama, klik link ApplicationManager untuk membuka dasbor Flink; untuk tugas yang telah selesai, klik link History untuk melihat detail tugas.
