The BigQuery Connector for Apache Spark allows Data Scientists to blend the power of BigQuery's seamlessly scalable SQL engine with Apache Spark’s Machine Learning capabilities. In this tutorial, we show how to use Dataproc, BigQuery and Apache Spark ML to perform machine learning on a dataset.
Objectives
Use linear regression to build a model of birth weight as a function of five factors:- gestation weeks
- mother's age
- father's age
- mother's weight gain during pregnancy
- Apgar score
Use the following tools:
- BigQuery, to prepare the linear regression input table, which is written to your Google Cloud project
- Python, to query and manage data in BigQuery
- Apache Spark, to access the resulting linear regression table
- Spark ML, to build and evaluate the model
- Dataproc PySpark job, to invoke Spark ML functions
Costs
In this document, you use the following billable components of Google Cloud:
- Compute Engine
- Dataproc
- BigQuery
To generate a cost estimate based on your projected usage,
use the pricing calculator.
Before you begin
A Dataproc cluster has the Spark components, including Spark ML, installed. To set up a Dataproc cluster and run the code in this example, you will need to do (or have done) the following:
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Enable the Dataproc, BigQuery, Compute Engine APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
If you're using an external identity provider (IdP), you must first sign in to the gcloud CLI with your federated identity.
-
To initialize the gcloud CLI, run the following command:
gcloud init -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Enable the Dataproc, BigQuery, Compute Engine APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
If you're using an external identity provider (IdP), you must first sign in to the gcloud CLI with your federated identity.
-
To initialize the gcloud CLI, run the following command:
gcloud init - Create a Dataproc cluster in your project. Your cluster should be running a Dataproc version with Spark 2.0 or higher, (includes machine learning libraries).
Create a subset of BigQuery natality data
In this section, you create a dataset in your project, then create a table in the dataset to which you copy a subset of birth rate data from the publicly available natality BigQuery dataset. Later in this tutorial you will use the subset data in this table to predict birth weight as a function of maternal age, paternal age, and gestation weeks.
You can create the data subset using the Google Cloud console or running a Python script on your local machine.
Console
Create a dataset in your project.
- Go to the BigQuery Web UI.
- In the left navigation panel, click your project name, then click CREATE DATASET.
- In the Create dataset dialog:
- For Dataset ID, enter "natality_regression".
- For Data location, you can choose a
location
for the dataset. The default value location is
US multi-region. After a dataset is created, the location cannot be changed. - For Default table expiration, choose one of the following options:
- Never (default): You must delete the table manually.
- Number of days: The table will be deleted after the specified number days from its creation time.
- For Encryption, choose one of the following options:
- Google-owned and Google-managed encryption key (default).
- Customer-managed key: See Protecting data with Cloud KMS keys.
- Click Create dataset.
Run a query against the public natality dataset, then save the query results in a new table in your dataset.
- Copy and paste the following query into the Query Editor, then
click Run.
CREATE OR REPLACE TABLE natality_regression.regression_input as SELECT weight_pounds, mother_age, father_age, gestation_weeks, weight_gain_pounds, apgar_5min FROM `bigquery-public-data.samples.natality` WHERE weight_pounds IS NOT NULL AND mother_age IS NOT NULL AND father_age IS NOT NULL AND gestation_weeks IS NOT NULL AND weight_gain_pounds IS NOT NULL AND apgar_5min IS NOT NULL
- After the query completes (in approximately one minute), the results
are saved as "regression_input" BigQuery table
in the
natality_regressiondataset in your project.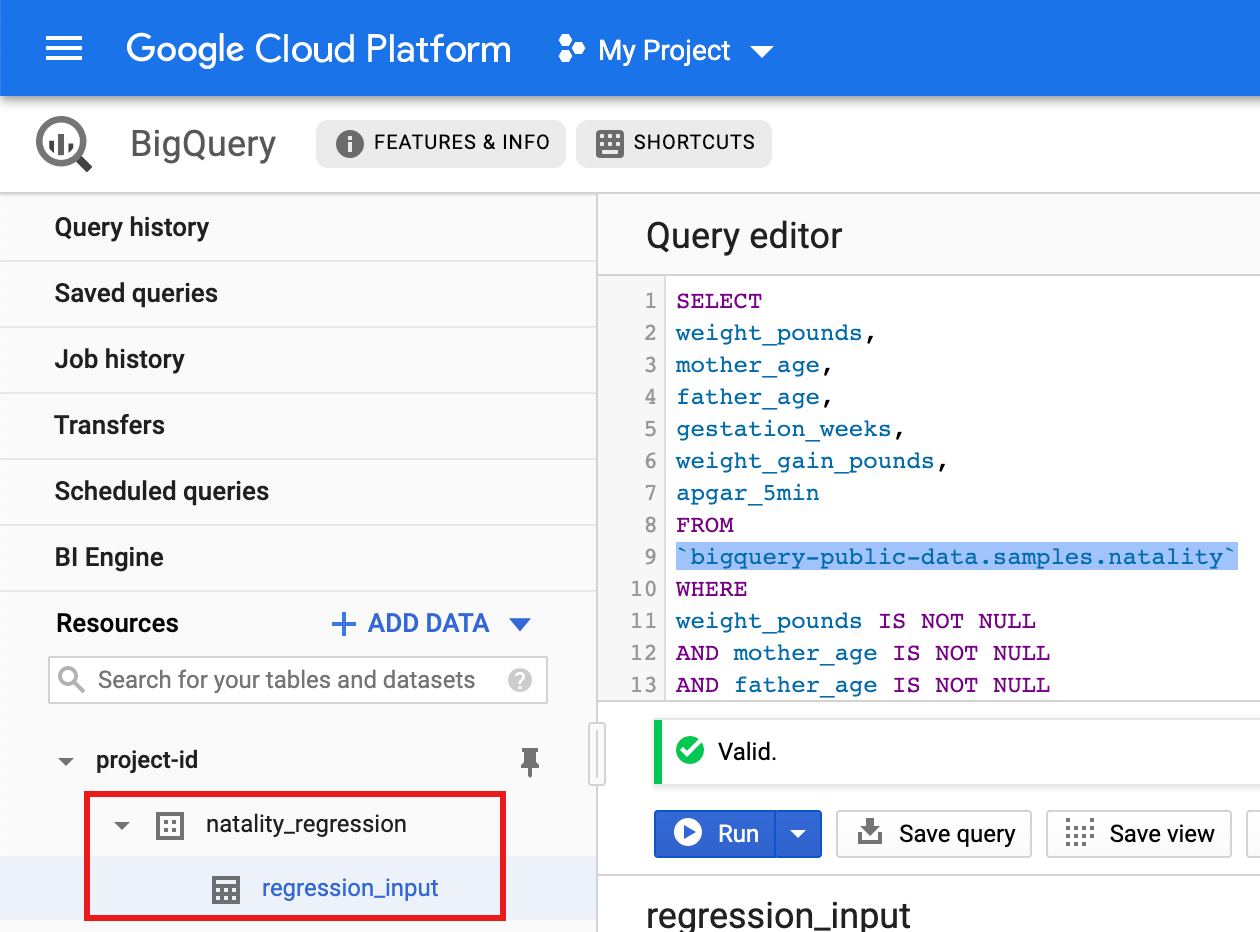
- Copy and paste the following query into the Query Editor, then
click Run.
Python
Before trying this sample, follow the Python setup instructions in the Dataproc quickstart using client libraries. For more information, see the Dataproc Python API reference documentation.
To authenticate to Dataproc, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
See Setting Up a Python Development Environment for instructions on installing Python and the Google Cloud Client Library for Python (needed to run the code). Installing and using a Python
virtualenvis recommended.Copy and paste the
natality_tutorial.pycode, below, into apythonshell on your local machine. Press the<return>key in the shell to run the code to create a "natality_regression" BigQuery dataset in your default Google Cloud project with a "regression_input" table that is populated with a subset of the publicnatalitydata.Confirm the creation of the
natality_regressiondataset and theregression_inputtable.
Run a linear regression
In this section, you'll run a PySpark linear regression by submitting
the job to the Dataproc service using the Google Cloud console
or by running the gcloud command from a local terminal.
Console
Copy and paste the following code into a new
natality_sparkml.pyfile on your local machine."""Run a linear regression using Apache Spark ML. In the following PySpark (Spark Python API) code, we take the following actions: * Load a previously created linear regression (BigQuery) input table into our Cloud Dataproc Spark cluster as an RDD (Resilient Distributed Dataset) * Transform the RDD into a Spark Dataframe * Vectorize the features on which the model will be trained * Compute a linear regression using Spark ML """ from pyspark.context import SparkContext from pyspark.ml.linalg import Vectors from pyspark.ml.regression import LinearRegression from pyspark.sql.session import SparkSession # The imports, above, allow us to access SparkML features specific to linear # regression as well as the Vectors types. # Define a function that collects the features of interest # (mother_age, father_age, and gestation_weeks) into a vector. # Package the vector in a tuple containing the label (`weight_pounds`) for that # row. def vector_from_inputs(r): return (r["weight_pounds"], Vectors.dense(float(r["mother_age"]), float(r["father_age"]), float(r["gestation_weeks"]), float(r["weight_gain_pounds"]), float(r["apgar_5min"]))) sc = SparkContext() spark = SparkSession(sc) # Read the data from BigQuery as a Spark Dataframe. natality_data = spark.read.format("bigquery").option( "table", "natality_regression.regression_input").load() # Create a view so that Spark SQL queries can be run against the data. natality_data.createOrReplaceTempView("natality") # As a precaution, run a query in Spark SQL to ensure no NULL values exist. sql_query = """ SELECT * from natality where weight_pounds is not null and mother_age is not null and father_age is not null and gestation_weeks is not null """ clean_data = spark.sql(sql_query) # Create an input DataFrame for Spark ML using the above function. training_data = clean_data.rdd.map(vector_from_inputs).toDF(["label", "features"]) training_data.cache() # Construct a new LinearRegression object and fit the training data. lr = LinearRegression(maxIter=5, regParam=0.2, solver="normal") model = lr.fit(training_data) # Print the model summary. print("Coefficients:" + str(model.coefficients)) print("Intercept:" + str(model.intercept)) print("R^2:" + str(model.summary.r2)) model.summary.residuals.show()
Copy the local
natality_sparkml.pyfile to a Cloud Storage bucket in your project.gcloud storage cp natality_sparkml.py gs://bucket-name
Run the regression from the Dataproc Submit a job page.
In the Main python file field, insert the
gs://URI of the Cloud Storage bucket where your copy of thenatality_sparkml.pyfile is located.Select
PySparkas the Job type.Insert
gs://spark-lib/bigquery/spark-bigquery-latest_2.12.jarin the Jar files field. This makes the spark-bigquery-connector available to the PySpark application at runtime to allow it to read BigQuery data into a Spark DataFrame.Fill in the Job ID, Region, and Cluster fields.
Click Submit to run the job on your cluster.
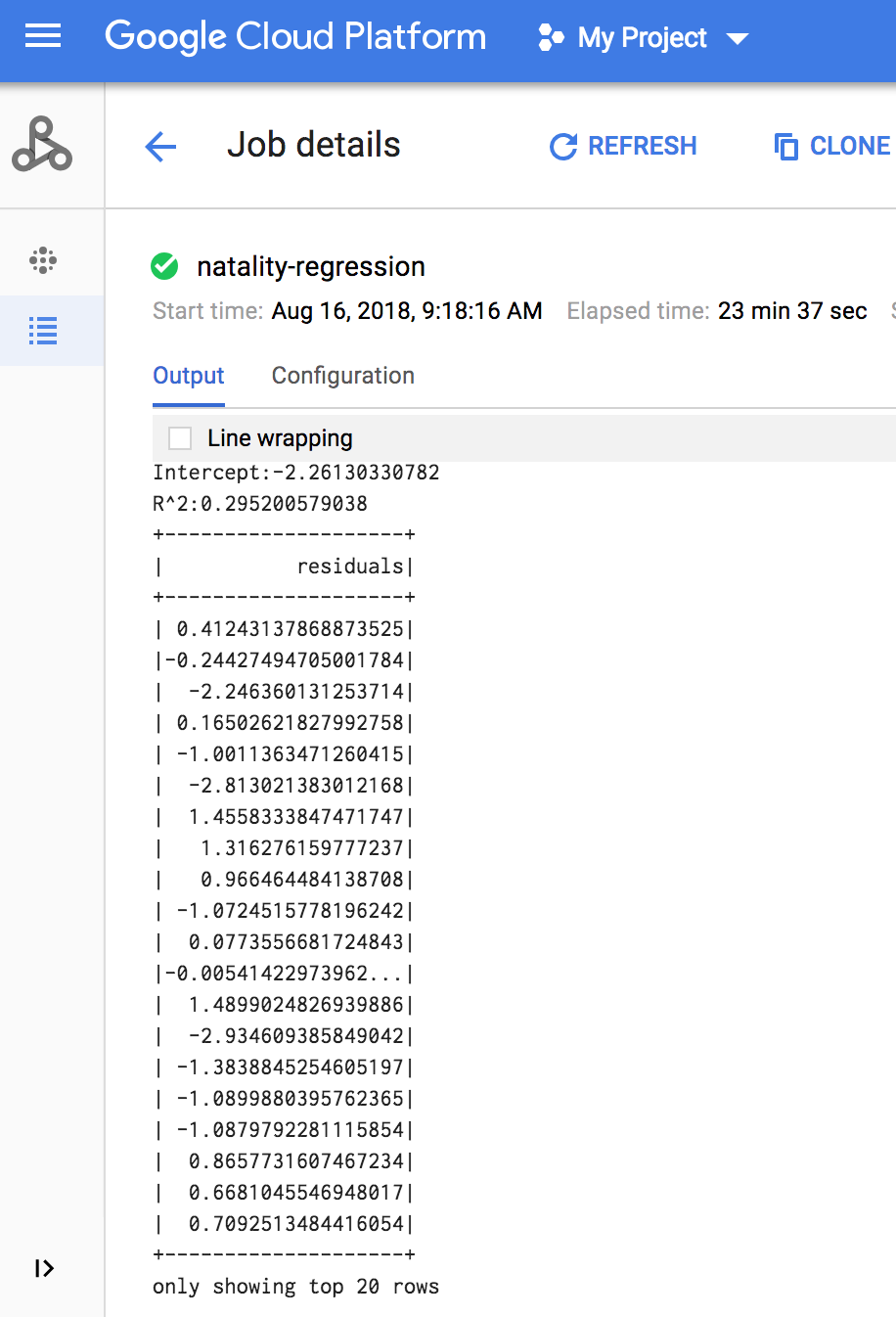
When the job completes, the linear regression output model summary appears in
the Dataproc Job details window.
gcloud
Copy and paste the following code into a new
natality_sparkml.pyfile on your local machine."""Run a linear regression using Apache Spark ML. In the following PySpark (Spark Python API) code, we take the following actions: * Load a previously created linear regression (BigQuery) input table into our Cloud Dataproc Spark cluster as an RDD (Resilient Distributed Dataset) * Transform the RDD into a Spark Dataframe * Vectorize the features on which the model will be trained * Compute a linear regression using Spark ML """ from pyspark.context import SparkContext from pyspark.ml.linalg import Vectors from pyspark.ml.regression import LinearRegression from pyspark.sql.session import SparkSession # The imports, above, allow us to access SparkML features specific to linear # regression as well as the Vectors types. # Define a function that collects the features of interest # (mother_age, father_age, and gestation_weeks) into a vector. # Package the vector in a tuple containing the label (`weight_pounds`) for that # row. def vector_from_inputs(r): return (r["weight_pounds"], Vectors.dense(float(r["mother_age"]), float(r["father_age"]), float(r["gestation_weeks"]), float(r["weight_gain_pounds"]), float(r["apgar_5min"]))) sc = SparkContext() spark = SparkSession(sc) # Read the data from BigQuery as a Spark Dataframe. natality_data = spark.read.format("bigquery").option( "table", "natality_regression.regression_input").load() # Create a view so that Spark SQL queries can be run against the data. natality_data.createOrReplaceTempView("natality") # As a precaution, run a query in Spark SQL to ensure no NULL values exist. sql_query = """ SELECT * from natality where weight_pounds is not null and mother_age is not null and father_age is not null and gestation_weeks is not null """ clean_data = spark.sql(sql_query) # Create an input DataFrame for Spark ML using the above function. training_data = clean_data.rdd.map(vector_from_inputs).toDF(["label", "features"]) training_data.cache() # Construct a new LinearRegression object and fit the training data. lr = LinearRegression(maxIter=5, regParam=0.2, solver="normal") model = lr.fit(training_data) # Print the model summary. print("Coefficients:" + str(model.coefficients)) print("Intercept:" + str(model.intercept)) print("R^2:" + str(model.summary.r2)) model.summary.residuals.show()
Copy the local
natality_sparkml.pyfile to a Cloud Storage bucket in your project.gcloud storage cp natality_sparkml.py gs://bucket-name
Submit the Pyspark job to the Dataproc service by running the
gcloudcommand, shown below, from a terminal window on your local machine.- The --jars flag value makes the spark-bigquery-connector available
to the PySpark jobv at runtime to allow it to read
BigQuery data into a Spark DataFrame.
gcloud dataproc jobs submit pyspark \ gs://your-bucket/natality_sparkml.py \ --cluster=cluster-name \ --region=region \ --jars=gs://spark-lib/bigquery/spark-bigquery-with-dependencies_SCALA_VERSION-CONNECTOR_VERSION.jar
- The --jars flag value makes the spark-bigquery-connector available
to the PySpark jobv at runtime to allow it to read
BigQuery data into a Spark DataFrame.
The linear regression output (model summary) appears in the terminal window when the job completes.
<<< # Print the model summary. ... print "Coefficients:" + str(model.coefficients) Coefficients:[0.0166657454602,-0.00296751984046,0.235714392936,0.00213002070133,-0.00048577251587] <<< print "Intercept:" + str(model.intercept) Intercept:-2.26130330748 <<< print "R^2:" + str(model.summary.r2) R^2:0.295200579035 <<< model.summary.residuals.show() +--------------------+ | residuals| +--------------------+ | -0.7234737533344147| | -0.985466980630501| | -0.6669710598385468| | 1.4162434829714794| |-0.09373154375186754| |-0.15461747949235072| | 0.32659061654192545| | 1.5053877697929803| | -0.640142797263989| | 1.229530260294963| |-0.03776160295256...| | -0.5160734239126814| | -1.5165972740062887| | 1.3269085258245008| | 1.7604670124710626| | 1.2348130901905972| | 2.318660276655887| | 1.0936947030883175| | 1.0169768511417363| | -1.7744915698181583| +--------------------+ only showing top 20 rows.
Clean up
After you finish the tutorial, you can clean up the resources that you created so that they stop using quota and incurring charges. The following sections describe how to delete or turn off these resources.
Delete the project
The easiest way to eliminate billing is to delete the project that you created for the tutorial.
To delete the project:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Delete the Dataproc cluster
See Delete a cluster.