Auf dieser Seite finden Sie Tipps und Strategien zur Fehlerbehebung, die für Sie nützlich sein könnten, wenn Sie Probleme beim Erstellen oder Ausführen einer Dataflow-Pipeline haben. Diese Informationen können Ihnen dabei helfen, einen Pipelinefehler zu erkennen und den Grund einer fehlgeschlagenen Ausführung der Pipeline zu bestimmen. Darüber hinaus erhalten Sie einige Vorschläge zur Behebung des Problems.
Das folgende Diagramm zeigt den Workflow zur Dataflow-Fehlerbehebung, der auf dieser Seite beschrieben wird.

Dataflow bietet Echtzeitfeedback zu Ihrem Job. Außerdem gibt es grundlegende Schritte zum Überprüfen der Fehlermeldungen und Logs sowie auf bestimmte Bedingungen, z. B. ob sich ein Job verzögert.
Hilfe bei gängigen Fehlern, die beim Ausführen eines Dataflow-Jobs auftreten können, finden Sie unter Fehlerbehebung bei Dataflow-Fehlern. Informationen zum Überwachen und Beheben von Pipelineleistung finden Sie unter Pipelineleistung überwachen.
Best Practices für Pipelines
Im Folgenden finden Sie die Best Practices für Java-, Python- und Go-Pipelines.
Java
Für Batchjobs empfehlen wir, eine Gültigkeitsdauer (TTL) für den temporären Speicherort festzulegen.
Bevor Sie eine TTL einrichten und als allgemeine Best Practice festlegen, müssen Sie als Staging-Speicherort und temporären Speicherort unterschiedliche Speicherorte festlegen.
Löschen Sie die Objekte am Staging-Speicherort nicht, da sie wiederverwendet werden.
Wenn ein Job abgeschlossen oder angehalten wurde und die temporären Objekte nicht bereinigt werden, entfernen Sie diese Dateien manuell aus dem Cloud Storage-Bucket, der als temporärer Speicherort verwendet wird.
Python
Sowohl der temporäre als auch der Staging-Speicherort haben das Präfix <job_name>.<time>.
Sorgen Sie dafür, dass Sie sowohl den Staging-Speicherort als auch den temporären Speicherort auf verschiedene Speicherorte festlegen.
Löschen Sie bei Bedarf die Objekte am Staging-Speicherort, nachdem ein Job abgeschlossen oder beendet wurde. Außerdem befinden sich die bereitgestellten Objekte nicht in Python-Pipelines.
Wenn ein Job endet und die temporären Objekte nicht bereinigt werden, entfernen Sie diese Dateien manuell aus dem Cloud Storage-Bucket, der als temporärer Speicherort verwendet wird.
Für Batchjobs empfehlen wir, eine Gültigkeitsdauer (TTL) sowohl für den temporären als auch für den Staging-Speicherort festzulegen.
Go
Sowohl der temporäre als auch der Staging-Speicherort haben das Präfix
<job_name>.<time>.Sorgen Sie dafür, dass Sie sowohl den Staging-Speicherort als auch den temporären Speicherort auf verschiedene Speicherorte festlegen.
Löschen Sie bei Bedarf die Objekte am Staging-Speicherort, nachdem ein Job abgeschlossen oder beendet wurde. Außerdem befinden sich die bereitgestellten Objekte nicht in Go-Pipelines.
Wenn ein Job endet und die temporären Objekte nicht bereinigt werden, entfernen Sie diese Dateien manuell aus dem Cloud Storage-Bucket, der als temporärer Speicherort verwendet wird.
Für Batchjobs empfehlen wir, eine Gültigkeitsdauer (TTL) sowohl für den temporären als auch für den Staging-Speicherort festzulegen.
Status einer Pipeline prüfen
Sie können mithilfe der Dataflow-Monitoring-Oberfläche jegliche Fehler in der Ausführung Ihrer Pipeline erkennen.
- Öffnen Sie die Google Cloud Console.
- Wählen Sie Ihr Google Cloud-Projekt aus der Projektliste aus.
- Klicken Sie im Navigationsmenü unter Big Data auf Dataflow. Daraufhin wird im rechten Bereich eine Liste der laufenden Jobs angezeigt.
- Wählen Sie den Pipelinejob, den Sie anzeigen lassen möchten. Den Status des Jobs sehen Sie auf einen Blick im Feld Status: "Aktiv", "Erfolgreich" oder "Fehler".
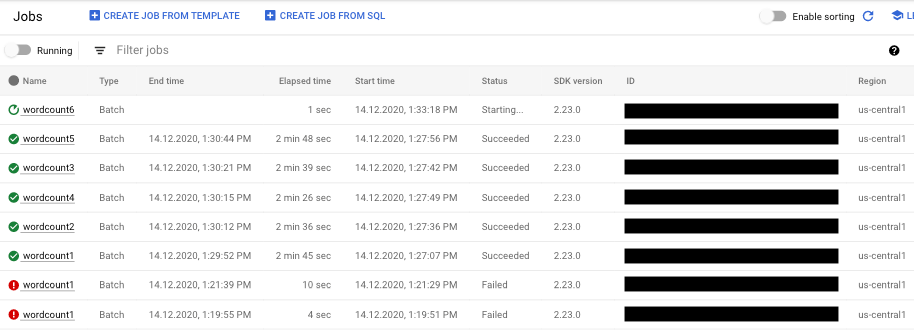
Informationen zu Pipelinefehlern finden
Falls ein Pipelinejob fehlgeschlagen ist, können Sie den Job auswählen, um weitere Details zu Fehlern und Ausführungsergebnissen aufzurufen. Wenn Sie einen Job auswählen, können Sie die wichtigsten Diagramme für Ihre Pipeline, das Ausführungsdiagramm, den Bereich Jobinfo und den Bereich Logs mit den Registerkarten Joblogs, Worker-Logs, Diagnose und Empfehlungen anzeigen lassen.
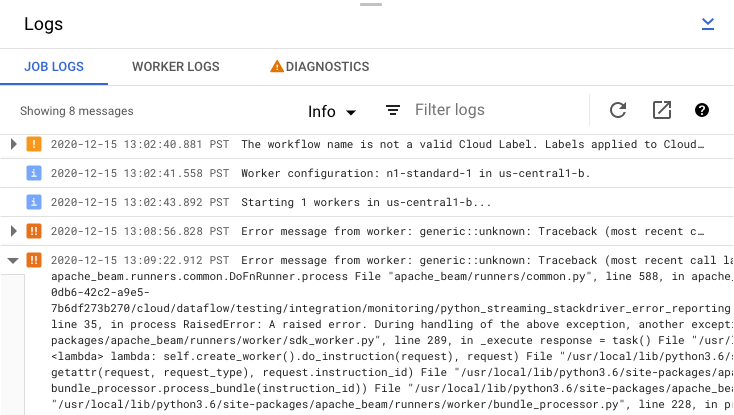
Fehlermeldungen zu Jobs überprüfen
Um die von Ihrem Pipeline-Code und dem Dataflow-Dienst erzeugten Job-Logs anzusehen, klicken Sie im Bereich Logs auf segmentAnzeigen.
Sie können die Nachrichten filtern, die in Joblogs angezeigt werden. Klicken Sie dazu auf Infoarrow_drop_down und filter_listFilter. Wenn nur Fehlermeldungen angezeigt werden sollen, klicken Sie auf Infoarrow_drop_down und wählen Sie Fehler aus.
Wenn Sie eine Fehlermeldung erweitern möchten, klicken Sie auf den erweiterbaren Bereich arrow_right.
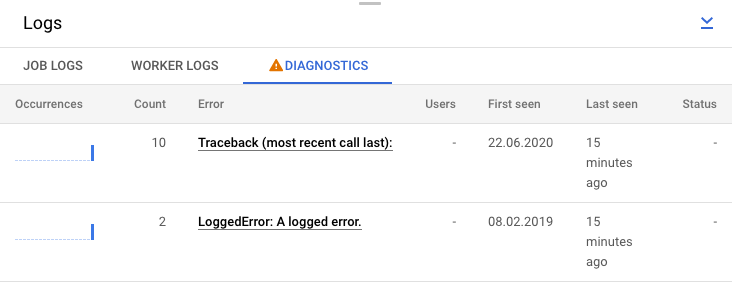
Alternativ können Sie auch auf den Tab Diagnose klicken. Dieser Tab zeigt, wo Fehler auf der ausgewählten Zeitachse aufgetreten sind, die Anzahl aller protokollierten Fehler und mögliche Empfehlungen für Ihre Pipeline.
Schrittlogs für den Job aufrufen
Wenn Sie einen Schritt in Ihrer Pipelinegrafik auswählen, wechselt das Logsteuerfeld von der Anzeige der Joblogs, die von dem Dataflow-Dienst generiert werden, zu der Anzeige der Logs der Compute Engine-Instanzen, die Ihren Pipelineschritt ausführen.
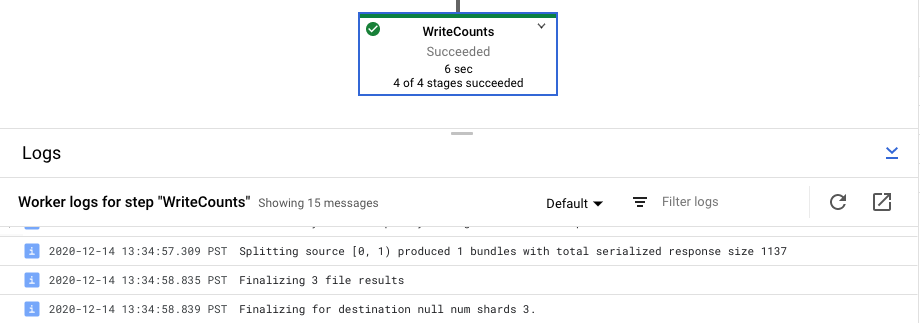
Cloud Logging fasst alle gesammelten Logs aus den Compute Engine-Instanzen Ihres Projekts an einem Ort zusammen. Weitere Informationen zur Verwendung der verschiedenen Logging-Möglichkeiten von Dataflow finden Sie unter Logging von Pipelinenachrichten.
Umgang mit automatisierter Pipelineablehnung
In einigen Fällen erkennt der Dataflow-Dienst, dass Ihre Pipeline bekannte SDK-Probleme auslösen könnte. Damit Pipelines, die wahrscheinlich Probleme verursachen, nicht gesendet werden, lehnt Dataflow diese Pipelines automatisch ab und zeigt folgende Meldung an:
The workflow was automatically rejected by the service because it might trigger an identified bug in the SDK (details below). If you think this identification is in error, and would like to override this automated rejection, please re-submit this workflow with the following override flag: [OVERRIDE FLAG]. Bug details: [BUG DETAILS]. Contact Google Cloud Support for further help. Please use this identifier in your communication: [BUG ID].
Wenn Sie nach Lesen der Hinweise in den verlinkten Fehlerdetails die Pipeline trotzdem ausführen möchten, können Sie die automatische Ablehnung überschreiben. Fügen Sie das Flag --experiments=<override-flag> hinzu und senden Sie die Pipeline noch einmal.
Ursache eines Pipelinefehlers ermitteln
In der Regel kann eine fehlgeschlagene Apache Beam-Pipelineausführung eine der folgenden Ursachen haben:
- Fehler bei der Erstellung der Grafik oder Pipeline: Diese Fehler treten auf, wenn Dataflow beim Erstellen der Grafik mit den Schritten, aus denen Ihre Pipeline besteht (wie von Ihrer Apache Beam-Pipeline beschrieben), ein Problem hat.
- Fehler bei der Jobvalidierung: Der Dataflow-Dienst prüft jeden Pipelinejob, den Sie starten. Fehler im Validierungsprozess können verhindern, dass der Job erfolgreich erstellt oder ausgeführt wird. Validierungsfehler können Probleme mit dem Cloud Storage-Bucket des Google Cloud-Projekts oder mit den Berechtigungen des Projekts umfassen.
- Ausnahmen im Worker-Code: Diese Fehler treten auf, wenn der vom Nutzer bereitgestellte Code, der von Dataflow auf parallele Worker wie die
DoFn-Instanzen einerParDo-Transformation verteilt wird, fehlerhaft ist. - Fehler aufgrund vorübergehender Ausfälle in anderen Google Cloud-Diensten. Ihre Pipeline kann aufgrund eines vorübergehenden Ausfalls oder eines anderen Problems in den Google Cloud-Diensten, auf die Dataflow angewiesen ist, z. B. Compute Engine oder Cloud Storage, fehlschlagen.
Fehler bei der Erstellung der Grafik oder Pipeline erkennen
Ein Fehler bei der Erstellung einer Grafik kann auftreten, wenn Dataflow die Ausführungsgrafik für Ihre Pipeline aus dem Code in Ihrem Dataflow-Programm erstellt. Dataflow prüft die Grafik während der Erstellung auf ungültige Vorgänge.
Falls Dataflow einen Fehler bei der Erstellung von Grafiken erkennt, wird im Dataflow-Dienst kein Job erstellt. Daher wird in diesem Fall in der Dataflow-Monitoring-Oberfläche kein Feedback angezeigt. Stattdessen wird im Console- oder Terminalfenster, in dem die Apache Beam-Pipeline ausgeführt wurde, eine Fehlermeldung ähnlich der folgenden angezeigt:
Java
Wenn die Pipeline beispielsweise versucht, eine Gruppierung wie GroupByKey auf eine unbegrenzte PCollection mit globalem Fenstermodus und ohne Trigger anzuwenden, erhalten Sie eine Fehlermeldung ähnlich der folgenden:
... ... Exception in thread "main" java.lang.IllegalStateException: ... GroupByKey cannot be applied to non-bounded PCollection in the GlobalWindow without a trigger. ... Use a Window.into or Window.triggering transform prior to GroupByKey ...
Python
Wenn Ihre Pipeline zum Beispiel Type Hints verwendet und ein Parametertyp in einer der Transformationen nicht wie erwartet ist, erhalten Sie eine Fehlermeldung ähnlich der folgenden:
... in <module> run()
... in run | beam.Map('count', lambda (word, ones): (word, sum(ones))))
... in __or__ return self.pipeline.apply(ptransform, self)
... in apply transform.type_check_inputs(pvalueish)
... in type_check_inputs self.type_check_inputs_or_outputs(pvalueish, 'input')
... in type_check_inputs_or_outputs pvalue_.element_type))
google.cloud.dataflow.typehints.decorators.TypeCheckError: Input type hint violation at group: expected Tuple[TypeVariable[K], TypeVariable[V]], got <type 'str'>
Go
Wenn Ihre Pipeline beispielsweise einen „DoFn“ verwendet, der keine Eingaben annimmt, tritt eine Fehlermeldung ähnlich der folgenden auf:
... panic: Method ProcessElement in DoFn main.extractFn is missing all inputs. A main input is required. ... Full error: ... inserting ParDo in scope root/CountWords ... graph.AsDoFn: for Fn named main.extractFn ... ProcessElement method has no main inputs ... goroutine 1 [running]: ... github.com/apache/beam/sdks/v2/go/pkg/beam.MustN(...) ... (more stacktrace)
Sollte ein solcher Fehler auftreten, überprüfen Sie den Pipelinecode darauf, ob die Pipelinevorgänge zulässig sind.
Fehler bei der Dataflow-Jobvalidierung erkennen
Sobald der Dataflow-Dienst die Grafik Ihrer Pipeline erhalten hat, versucht der Dienst, Ihren Job zu validieren. Dies umfasst Folgendes:
- Es wird geprüft, ob der Dienst auf die mit dem Job verknüpften Cloud Storage-Buckets für das Staging von Dateien und die temporäre Ausgabe zugreifen kann.
- Es wird geprüft, ob die erforderlichen Berechtigungen in Ihrem Google Cloud-Projekt vorliegen.
- Es wird geprüft, ob der Dienst auf Eingabe- und Ausgabequellen wie Dateien zugreifen kann.
Wenn der Validierungsprozess Ihres Jobs fehlschlägt, wird eine Fehlermeldung in der Dataflow-Monitoring-Oberfläche sowie in Ihrem Console- oder dem Terminalfenster angezeigt, wenn Sie die Blocking-Ausführung verwenden. Die Fehlermeldung sieht etwa so aus:
Java
INFO: To access the Dataflow monitoring console, please navigate to
https://console.developers.google.com/project/google.com%3Aclouddfe/dataflow/job/2016-03-08_18_59_25-16868399470801620798
Submitted job: 2016-03-08_18_59_25-16868399470801620798
...
... Starting 3 workers...
... Executing operation BigQuery-Read+AnonymousParDo+BigQuery-Write
... Executing BigQuery import job "dataflow_job_16868399470801619475".
... Stopping worker pool...
... Workflow failed. Causes: ...BigQuery-Read+AnonymousParDo+BigQuery-Write failed.
Causes: ... BigQuery getting table "non_existent_table" from dataset "cws_demo" in project "my_project" failed.
Message: Not found: Table x:cws_demo.non_existent_table HTTP Code: 404
... Worker pool stopped.
... com.google.cloud.dataflow.sdk.runners.BlockingDataflowPipelineRunner run
INFO: Job finished with status FAILED
Exception in thread "main" com.google.cloud.dataflow.sdk.runners.DataflowJobExecutionException:
Job 2016-03-08_18_59_25-16868399470801620798 failed with status FAILED
at com.google.cloud.dataflow.sdk.runners.DataflowRunner.run(DataflowRunner.java:155)
at com.google.cloud.dataflow.sdk.runners.DataflowRunner.run(DataflowRunner.java:56)
at com.google.cloud.dataflow.sdk.Pipeline.run(Pipeline.java:180)
at com.google.cloud.dataflow.integration.BigQueryCopyTableExample.main(BigQueryCopyTableExample.java:74)
Python
INFO:root:Created job with id: [2016-03-08_14_12_01-2117248033993412477] ... Checking required Cloud APIs are enabled. ... Job 2016-03-08_14_12_01-2117248033993412477 is in state JOB_STATE_RUNNING. ... Combiner lifting skipped for step group: GroupByKey not followed by a combiner. ... Expanding GroupByKey operations into optimizable parts. ... Lifting ValueCombiningMappingFns into MergeBucketsMappingFns ... Annotating graph with Autotuner information. ... Fusing adjacent ParDo, Read, Write, and Flatten operations ... Fusing consumer split into read ... ... Starting 1 workers... ... ... Executing operation read+split+pair_with_one+group/Reify+group/Write ... Executing failure step failure14 ... Workflow failed. Causes: ... read+split+pair_with_one+group/Reify+group/Write failed. Causes: ... Unable to view metadata for files: gs://dataflow-samples/shakespeare/missing.txt. ... Cleaning up. ... Tearing down pending resources... INFO:root:Job 2016-03-08_14_12_01-2117248033993412477 is in state JOB_STATE_FAILED.
Go
Die in diesem Abschnitt beschriebene Jobvalidierung wird derzeit für Go nicht unterstützt. Fehler aufgrund dieser Probleme werden als Worker-Ausnahmen angezeigt.
Ausnahme im Worker-Code erkennen
Beim Ausführen eines Jobs können im Worker-Code Fehler oder Ausnahmen auftreten. Diese bedeuten im Allgemeinen, dass die DoFn-Objekte im Pipelinecode unbearbeitete Ausnahmen erzeugt haben, die dazu führen, dass Aufgaben im Dataflow-Job fehlschlagen.
Ausnahmen im Nutzercode, zum Beispiel in Ihren DoFn-Instanzen, werden in der Dataflow-Monitoring-Oberfläche angezeigt.
Wenn Sie eine Pipeline mit Blocking ausführen, werden Fehlermeldungen in der Konsole bzw. im Terminalfenster ausgegeben. Diese sehen ungefähr so aus:
Java
INFO: To access the Dataflow monitoring console, please navigate to https://console.developers.google.com/project/example_project/dataflow/job/2017-05-23_14_02_46-1117850763061203461
Submitted job: 2017-05-23_14_02_46-1117850763061203461
...
... To cancel the job using the 'gcloud' tool, run: gcloud beta dataflow jobs --project=example_project cancel 2017-05-23_14_02_46-1117850763061203461
... Autoscaling is enabled for job 2017-05-23_14_02_46-1117850763061203461.
... The number of workers will be between 1 and 15.
... Autoscaling was automatically enabled for job 2017-05-23_14_02_46-1117850763061203461.
...
... Executing operation BigQueryIO.Write/BatchLoads/Create/Read(CreateSource)+BigQueryIO.Write/BatchLoads/GetTempFilePrefix+BigQueryIO.Write/BatchLoads/TempFilePrefixView/BatchViewOverrides.GroupByWindowHashAsKeyAndWindowAsSortKey/ParDo(UseWindowHashAsKeyAndWindowAsSortKey)+BigQueryIO.Write/BatchLoads/TempFilePrefixView/Combine.GloballyAsSingletonView/Combine.globally(Singleton)/WithKeys/AddKeys/Map/ParMultiDo(Anonymous)+BigQueryIO.Write/BatchLoads/TempFilePrefixView/Combine.GloballyAsSingletonView/Combine.globally(Singleton)/Combine.perKey(Singleton)/GroupByKey/Reify+BigQueryIO.Write/BatchLoads/TempFilePrefixView/Combine.GloballyAsSingletonView/Combine.globally(Singleton)/Combine.perKey(Singleton)/GroupByKey/Write+BigQueryIO.Write/BatchLoads/TempFilePrefixView/BatchViewOverrides.GroupByWindowHashAsKeyAndWindowAsSortKey/BatchViewOverrides.GroupByKeyAndSortValuesOnly/Write
... Workers have started successfully.
...
... org.apache.beam.runners.dataflow.util.MonitoringUtil$LoggingHandler process SEVERE: 2017-05-23T21:06:33.711Z: (c14bab21d699a182): java.lang.RuntimeException: org.apache.beam.sdk.util.UserCodeException: java.lang.ArithmeticException: / by zero
at com.google.cloud.dataflow.worker.runners.worker.GroupAlsoByWindowsParDoFn$1.output(GroupAlsoByWindowsParDoFn.java:146)
at com.google.cloud.dataflow.worker.runners.worker.GroupAlsoByWindowFnRunner$1.outputWindowedValue(GroupAlsoByWindowFnRunner.java:104)
at com.google.cloud.dataflow.worker.util.BatchGroupAlsoByWindowAndCombineFn.closeWindow(BatchGroupAlsoByWindowAndCombineFn.java:191)
...
... Cleaning up.
... Stopping worker pool...
... Worker pool stopped.
Python
INFO:root:Job 2016-03-08_14_21_32-8974754969325215880 is in state JOB_STATE_RUNNING. ... INFO:root:... Expanding GroupByKey operations into optimizable parts. INFO:root:... Lifting ValueCombiningMappingFns into MergeBucketsMappingFns INFO:root:... Annotating graph with Autotuner information. INFO:root:... Fusing adjacent ParDo, Read, Write, and Flatten operations ... INFO:root:...: Starting 1 workers... INFO:root:...: Executing operation group/Create INFO:root:...: Value "group/Session" materialized. INFO:root:...: Executing operation read+split+pair_with_one+group/Reify+group/Write INFO:root:Job 2016-03-08_14_21_32-8974754969325215880 is in state JOB_STATE_RUNNING. INFO:root:...: ...: Workers have started successfully. INFO:root:Job 2016-03-08_14_21_32-8974754969325215880 is in state JOB_STATE_RUNNING. INFO:root:...: Traceback (most recent call last): File ".../dataflow_worker/batchworker.py", line 384, in do_work self.current_executor.execute(work_item.map_task) ... File ".../apache_beam/examples/wordcount.runfiles/py/apache_beam/examples/wordcount.py", line 73, in <lambda> ValueError: invalid literal for int() with base 10: 'www'
Go
... 2022-05-26T18:32:52.752315397Zprocess bundle failed for instruction ... process_bundle-4031463614776698457-2 using plan s02-6 : while executing ... Process for Plan[s02-6] failed: Oh no! This is an error message!
Fügen Sie Ihrem Code ggf. einen Ausnahme-Handler hinzu, um Fehler zu vermeiden. Wenn Sie beispielsweise Elemente auslassen möchten, die einige benutzerdefinierte Eingabevalidierungen in ParDo fehlschlagen lassen, verarbeiten Sie die Ausnahme innerhalb Ihres DoFn-Objekts und lassen Sie das Element weg.
Sie können fehlschlagende Elemente auch auf mehrere Arten verfolgen:
- Sie können die zu einem Fehlschlag führenden Elemente loggen und die Ausgabe mithilfe von Cloud Logging prüfen.
- Sie können die Dataflow-Worker- und Worker-Startlogs auf Warnungen oder Fehler prüfen, indem Sie der Anleitung unter Logs ansehen folgen.
- Sie können festlegen, dass
ParDodie fehlschlagenden Elemente zur späteren Prüfung in eine zusätzliche Ausgabe schreibt.
Wenn Sie die Attribute einer ausgeführten Pipeline verfolgen möchten, verwenden Sie die Klasse Metrics wie im folgenden Beispiel gezeigt:
Java
final Counter counter = Metrics.counter("stats", "even-items"); PCollection<Integer> input = pipeline.apply(...); ... input.apply(ParDo.of(new DoFn<Integer, Integer>() { @ProcessElement public void processElement(ProcessContext c) { if (c.element() % 2 == 0) { counter.inc(); } });
Python
class FilterTextFn(beam.DoFn): """A DoFn that filters for a specific key based on a regex.""" def __init__(self, pattern): self.pattern = pattern # A custom metric can track values in your pipeline as it runs. Create # custom metrics to count unmatched words, and know the distribution of # word lengths in the input PCollection. self.word_len_dist = Metrics.distribution(self.__class__, 'word_len_dist') self.unmatched_words = Metrics.counter(self.__class__, 'unmatched_words') def process(self, element): word = element self.word_len_dist.update(len(word)) if re.match(self.pattern, word): yield element else: self.unmatched_words.inc() filtered_words = ( words | 'FilterText' >> beam.ParDo(FilterTextFn('s.*')))
Go
func addMetricDoFnToPipeline(s beam.Scope, input beam.PCollection) beam.PCollection { return beam.ParDo(s, &MyMetricsDoFn{}, input) } func executePipelineAndGetMetrics(ctx context.Context, p *beam.Pipeline) (metrics.QueryResults, error) { pr, err := beam.Run(ctx, runner, p) if err != nil { return metrics.QueryResults{}, err } // Request the metric called "counter1" in namespace called "namespace" ms := pr.Metrics().Query(func(r beam.MetricResult) bool { return r.Namespace() == "namespace" && r.Name() == "counter1" }) // Print the metric value - there should be only one line because there is // only one metric called "counter1" in the namespace called "namespace" for _, c := range ms.Counters() { fmt.Println(c.Namespace(), "-", c.Name(), ":", c.Committed) } return ms, nil } type MyMetricsDoFn struct { counter beam.Counter } func init() { beam.RegisterType(reflect.TypeOf((*MyMetricsDoFn)(nil))) } func (fn *MyMetricsDoFn) Setup() { // While metrics can be defined in package scope or dynamically // it's most efficient to include them in the DoFn. fn.counter = beam.NewCounter("namespace", "counter1") } func (fn *MyMetricsDoFn) ProcessElement(ctx context.Context, v beam.V, emit func(beam.V)) { // count the elements fn.counter.Inc(ctx, 1) emit(v) }
Fehlerbehebung von langsam laufenden Pipelines oder fehlender Ausgabe
Siehe Fehlerbehebung bei langsamen und hängenden Jobs.
Gängige Fehler und mögliche Maßnahmen
Wenn Sie den Fehler kennen, der den Pipelinefehler verursacht hat, finden Sie auf der Seite Fehlerbehebung bei Dataflow-Fehlern eine Anleitung zur Fehlerbehebung.