Die Dataflow-Monitoring-Oberfläche bietet eine grafische Darstellung jedes Jobs: die Jobgrafik. Die Jobgrafik enthält auch eine Jobübersicht, ein Joblog und Informationen zu jedem Schritt in der Pipeline.
So rufen Sie das Jobdiagramm für einen Job auf:
Rufen Sie in der Google Cloud Console die Seite Dataflow > Jobs auf.
Wählen Sie einen Job aus.
Klicken Sie auf den Tab Job-Diagramm.
Standardmäßig wird auf der Seite für die Jobgrafik die Diagrammansicht angezeigt. Job-Grafik als Tabelle ansehen. Dazu Wählen Sie unter Ansicht mit Jobschritten die Option Tabellenansicht aus. Tabellenansicht enthält die gleichen Informationen in einem anderen Format. Die Tabellenansicht ist in den folgenden Szenarien hilfreich:
- Ihr Job hat viele Phasen, was die Navigation im Job-Diagramm erschwert.
- Sie möchten die Job-Schritte nach einer bestimmten Eigenschaft sortieren. Sie können beispielsweise die Tabelle nach Echtzeit sortieren, um langsame Schritte zu identifizieren.
Diagrammansicht
Darin wird jede Transformation in der Pipeline als Feld dargestellt. Das folgende Bild zeigt ein Jobdiagramm mit drei Transformationen: Read PubSub Events, 5m Window und Write File(s).
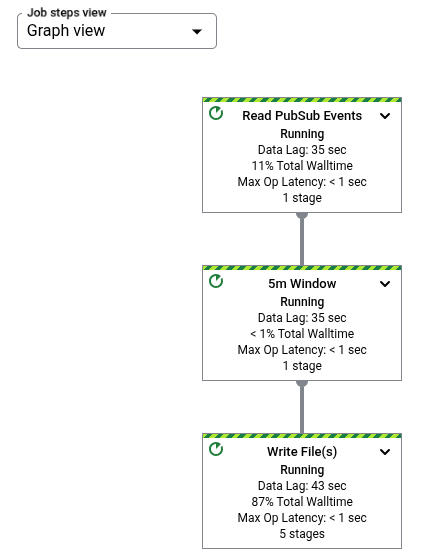
Jedes Feld enthält die folgenden Informationen:
Transform name (Transformationsname)
Status; einer der folgenden Werte:
- Wird ausgeführt: Der Schritt wird ausgeführt.
- Queued (In der Warteschlange): Der Schritt in einem FlexRS-Job wurde in die Warteschlange gestellt.
- Succeeded (Erfolgreich): Der Schritt wurde erfolgreich abgeschlossen.
- Angehalten: Der Schritt wurde angehalten, weil der Job angehalten wurde.
- Unknown (Unbekannt): In diesem Schritt konnte der Status nicht gemeldet werden.
- Failed (Fehlgeschlagen): Der Schritt konnte nicht abgeschlossen werden.
Die Anzahl der Jobphasen, in denen dieser Schritt ausgeführt wird
Wenn ein Schritt eine zusammengesetzte Transformation darstellt, können Sie den Schritt maximieren, um die Untertransformationen aufzurufen. Klicken Sie zum Maximieren des Schritts auf den Pfeil Knoten maximieren.
Transformationsnamen
Dataflow hat verschiedene Möglichkeiten, den Transformationsnamen zu ermitteln, der in der Jobgrafik der Überwachung angezeigt wird. Transformationsnamen werden an öffentlich sichtbaren Stellen verwendet, einschließlich der Dataflow-Monitoring-Oberfläche, Log-Dateien und Debugging-Tools. Verwenden Sie keine Namen für Transformationen, die personenidentifizierbare Informationen wie Nutzernamen oder Organisationsnamen enthalten.
Java
- Dataflow kann den Namen verwenden, den Sie beim Anwenden der Transformation zuweisen. Das erste Argument, das Sie an die Methode
applygeben, ist Ihr Transformationsname. - Dataflow kann den Transformationsnamen ableiten – entweder vom Klassennamen, wenn Sie eine benutzerdefinierte Transformation erstellen, oder vom Namen des Funktionsobjekts
DoFn, wenn Sie eine Kerntransformation wieParDoverwenden.
Python
- Dataflow kann den Namen verwenden, den Sie beim Anwenden der Transformation zuweisen. Durch das Angeben des Arguments
labelder Transformation können Sie den Transformationsnamen angeben. - Dataflow kann den Transformationsnamen ableiten – entweder vom Klassennamen, wenn Sie eine benutzerdefinierte Transformation erstellen, oder vom Namen des Funktionsobjekts
DoFn, wenn Sie eine Kerntransformation wieParDoverwenden.
Go
- Dataflow kann den Namen verwenden, den Sie beim Anwenden der Transformation zuweisen. Durch Angabe von
Scopekönnen Sie den Transformationsnamen festlegen. - Dataflow kann den Transformationsnamen ableiten, entweder aus dem struct-Namen, wenn Sie einen strukturellen
DoFnverwenden, oder aus dem Funktionsnamen, wenn Sie einen funktionalenDoFnverwenden.
Schrittinformationen ansehen
Wenn Sie im Jobdiagramm auf einen Schritt klicken, werden im Bereich Schrittinformationen weitere Details zum Schritt angezeigt. Weitere Informationen finden Sie unter Informationen zu Jobschritten.
Engpässe
Wenn Dataflow einen Engpass erkennt, wird im Job-Diagramm ein -Warnsymbol für die betroffenen Schritte angezeigt. Wenn Sie die Ursache für den Engpass sehen möchten, klicken Sie auf den Schritt, um den Bereich Schrittinfo zu öffnen. Weitere Informationen finden Sie unter Engpässe beheben.
Beispiel für Jobgrafiken
In diesem Abschnitt finden Sie Beispielcode für Pipelines und die entsprechenden Jobdiagramme.
Einfache Jobgrafik
Pipelinecode:
Java// Read the lines of the input text. p.apply("ReadLines", TextIO.read().from(options.getInputFile())) // Count the words. .apply(new CountWords()) // Write the formatted word counts to output. .apply("WriteCounts", TextIO.write().to(options.getOutput())); Python( pipeline # Read the lines of the input text. | 'ReadLines' >> beam.io.ReadFromText(args.input_file) # Count the words. | CountWords() # Write the formatted word counts to output. | 'WriteCounts' >> beam.io.WriteToText(args.output_path)) Go// Create the pipeline. p := beam.NewPipeline() s := p.Root() // Read the lines of the input text. lines := textio.Read(s, *input) // Count the words. counted := beam.ParDo(s, CountWords, lines) // Write the formatted word counts to output. textio.Write(s, *output, formatted) |
Jobgrafik:

|
Jobgrafik mit zusammengesetzten Transformationen
Zusammengesetzte Transformationen sind Transformationen, die mehrere verschachtelte Untertransformationen enthalten. Im Jobdiagramm lassen sich zusammengesetzte Transformationen maximieren. Klicken Sie auf den Pfeil, um die Transformation zu maximieren und die Untertransformationen anzeigen zu lassen.
Pipelinecode:
Java// The CountWords Composite Transform // inside the WordCount pipeline. public static class CountWords extends PTransform<PCollection<String>, PCollection<String>> { @Override public PCollection<String> apply(PCollection<String> lines) { // Convert lines of text into individual words. PCollection<String> words = lines.apply( ParDo.of(new ExtractWordsFn())); // Count the number of times each word occurs. PCollection<KV<String, Long>> wordCounts = words.apply(Count.<String>perElement()); return wordCounts; } } Python# The CountWords Composite Transform inside the WordCount pipeline. @beam.ptransform_fn def CountWords(pcoll): return ( pcoll # Convert lines of text into individual words. | 'ExtractWords' >> beam.ParDo(ExtractWordsFn()) # Count the number of times each word occurs. | beam.combiners.Count.PerElement() # Format each word and count into a printable string. | 'FormatCounts' >> beam.ParDo(FormatCountsFn())) Go// The CountWords Composite Transform inside the WordCount pipeline. func CountWords(s beam.Scope, lines beam.PCollection) beam.PCollection { s = s.Scope("CountWords") // Convert lines of text into individual words. col := beam.ParDo(s, &extractFn{SmallWordLength: *smallWordLength}, lines) // Count the number of times each word occurs. return stats.Count(s, col) } |
Jobgrafik:
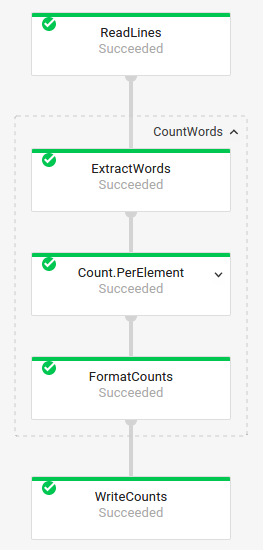
|
In Ihrem Pipeline-Code verwenden Sie möglicherweise den folgenden Code, um Ihre zusammengesetzte Transformation aufzurufen:
result = transform.apply(input);
In zusammengesetzten Transformationen, die auf diese Weise aufgerufen werden, wird die erwartete Verschachtelung weggelassen. Aus diesem Grund können sie in der Dataflow-Monitoring-Oberfläche erweitert angezeigt werden. Ihre Pipeline kann während der Pipelineausführung außerdem Warnmeldungen oder Fehler zu stabilen eindeutigen Namen generieren.
Achten Sie darauf, Ihre Transformation im empfohlenen Format aufzurufen, um diese Probleme zu vermeiden:
result = input.apply(transform);
Nächste Schritte
- Detaillierte Informationen zu Jobschritten ansehen
- Jobphasen auf dem Tab Ausführungsdetails ansehen
- Fehlerbehebung bei Pipelines