Dataflow erfasst Messwerte für Ihre Jobs, die Ihnen helfen können, Fehler zu beheben, Leistungsprobleme zu beheben oder Ihre Pipeline zu optimieren. Auf der Dataflow-Monitoring-Oberfläche werden Visualisierungen für diese Messwerte angezeigt. Sie können Cloud Monitoring auch verwenden, um Benachrichtigungen zu erstellen oder Metrics Explorer-Abfragen zu erstellen.
Auf Jobmesswerte zugreifen
So rufen Sie die Jobmesswerte für einen Job auf:
Rufen Sie in der Google Cloud Console die Seite Dataflow > Jobs auf.
Wählen Sie einen Job aus.
Klicken Sie auf den Tab Jobmesswerte.
Wählen Sie einen Messwert aus, der angezeigt werden soll.
Klicken Sie auf Daten auswerten, um auf zusätzliche Informationen in den Jobmesswertdiagrammen zuzugreifen.
Die Messwerte sind in folgenden Dashboards organisiert:
- Messwerte für Autoscaling
- Übersichtsmesswerte
- Streaming-Messwerte
- Ressourcenmesswerte
- Input- und Output-Messwerte
Unterstützung und Einschränkungen
Beachten Sie bei der Verwendung der Dataflow-Messwerte die folgenden Details.
Manchmal sind Jobdaten zeitweise nicht verfügbar. Wenn Daten fehlen, werden in den Job-Monitoring-Diagrammen Lücken angezeigt.
Einige dieser Diagramme gelten nur für Streamingpipelines.
Zum Schreiben von Messwertdaten muss ein nutzerverwaltetes Dienstkonto die IAM API-Berechtigung
monitoring.timeSeries.createhaben. Diese Berechtigung ist in der Rolle „Dataflow-Worker“ enthalten.Der Dataflow-Dienst meldet die reservierte CPU-Zeit nach dem Abschluss von Jobs. Bei unbegrenzten (Streaming) Jobs wird die reservierte CPU-Zeit erst gemeldet, nachdem sie abgebrochen wurden oder fehlgeschlagen sind. Daher enthalten die Jobmesswerte keine reservierte CPU-Zeit für Streamingjobs.
Messwerte für Autoscaling
Horizontales Autoscaling ermöglicht es Dataflow, die richtige Anzahl von Worker-Instanzen für den Job auszuwählen und dabei Worker nach Bedarf hinzuzufügen oder zu entfernen.
Im Bereich Autoscaling auf dem Tab Jobmesswerte sehen Sie die Anzahl der Worker und die Zielanzahl der Worker im Zeitverlauf. Wenn Ihr Job Streaming Engine verwendet, wird auch die Mindest- und Höchstzahl von Workern angezeigt.
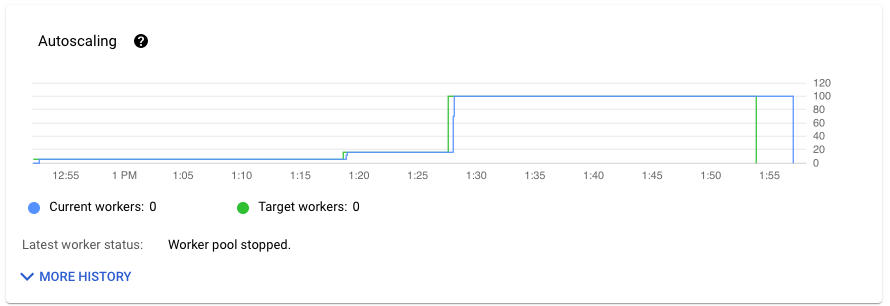
Klicken Sie auf Weiteren Verlauf, um den Verlauf der Autoscaling-Änderungen aufzurufen. Eine Tabelle mit Informationen zum Worker-Verlauf Ihres Jobs wird angezeigt.
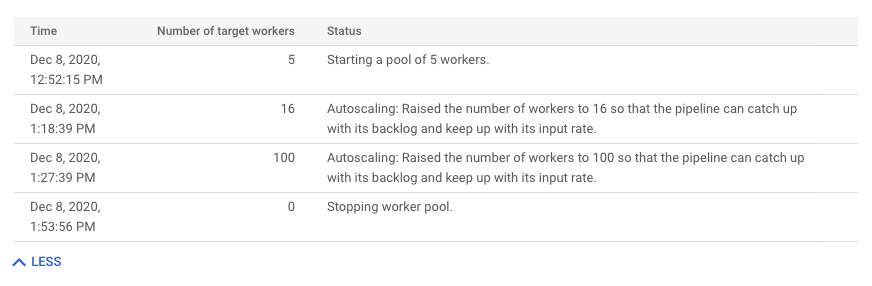
Wenn Sie zusätzliche Informationen zum Autoscaling für Streamingjobs sehen möchten, klicken Sie auf den Tab Autoscaling. Weitere Informationen finden Sie unter Dataflow-Autoscaling überwachen.
Übersichtsmesswerte
Die folgenden Messwerte werden unter Übersichtsmesswerte angezeigt.
Datenaktualität
Dieser Messwert gilt nur für Streamingjobs.
Die Datenaktualität ist die Differenz zwischen dem Zeitpunkt, zu dem ein Datenelement verarbeitet wird (Verarbeitungszeit), und dem Zeitstempel des Datenelements (Ereigniszeit). Höhere Werte bedeuten eine längere Verzögerung zwischen der Ereigniszeit und der Verarbeitungszeit.
Das Diagramm zur Datenaktualität zeigt den maximalen Wert für die Datenaktualität zu einem beliebigen Zeitpunkt. Dataflow verarbeitet mehrere Elemente parallel. Das Diagramm spiegelt daher das Element mit der größten Verzögerung im Verhältnis zur Ereigniszeit wider.
Wenn irgendwelche Eingabedaten noch nicht verarbeitet wurden, kann das Ausgabewasserzeichen verzögert sein, was sich auf die Datenaktualität auswirkt. Ein erheblicher Unterschied zwischen der Wasserzeichenzeit und der Ereigniszeit kann auf einen langsamen oder hängenden Vorgang hinweisen. Weitere Informationen finden Sie in der Apache Beam-Dokumentation unter Wasserzeichen und verspätete Daten.
Das Dashboard enthält die folgenden zwei Diagramme:
- Datenaktualität nach Phasen
- Datenaktualität
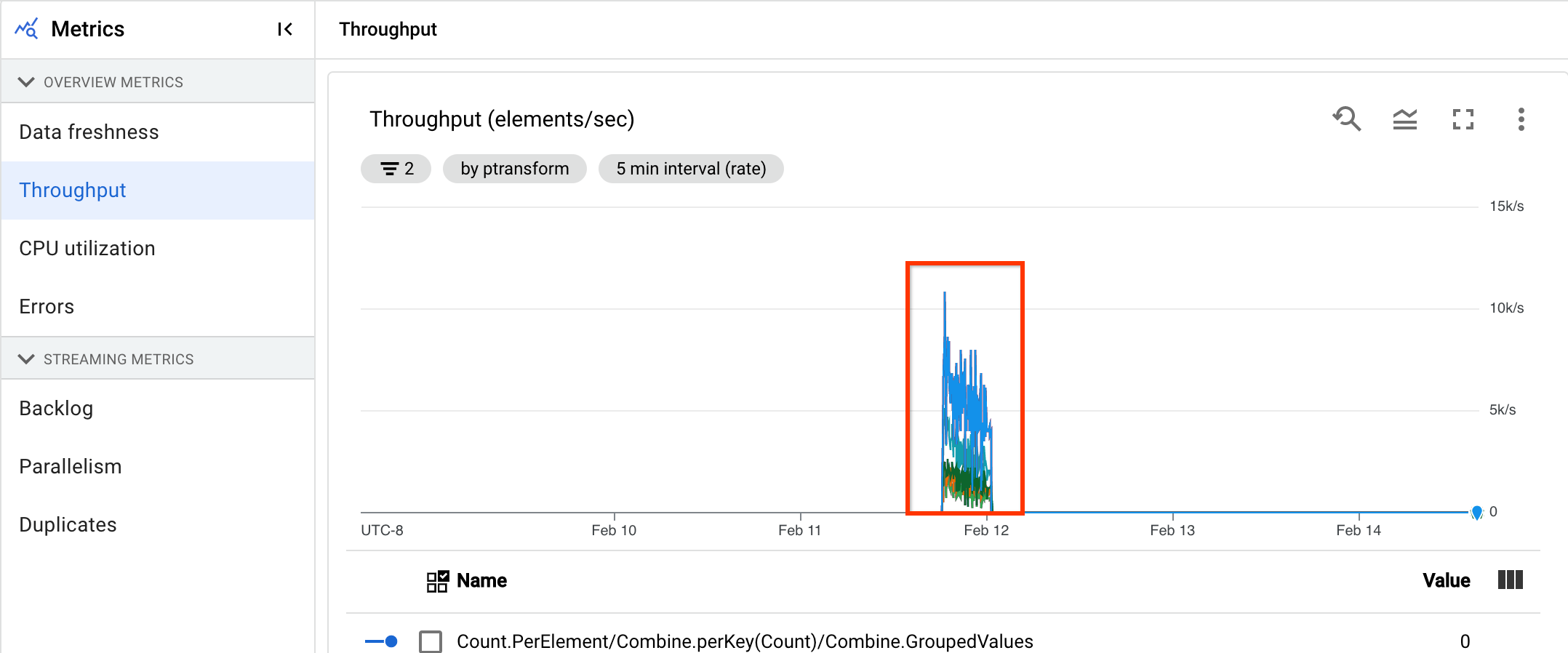
In der folgenden Abbildung zeigt der markierte Bereich einen großen Unterschied zwischen der Ereigniszeit und der Ausgabezeit im Wasserzeichen, was auf einen langsamen Vorgang hinweist.
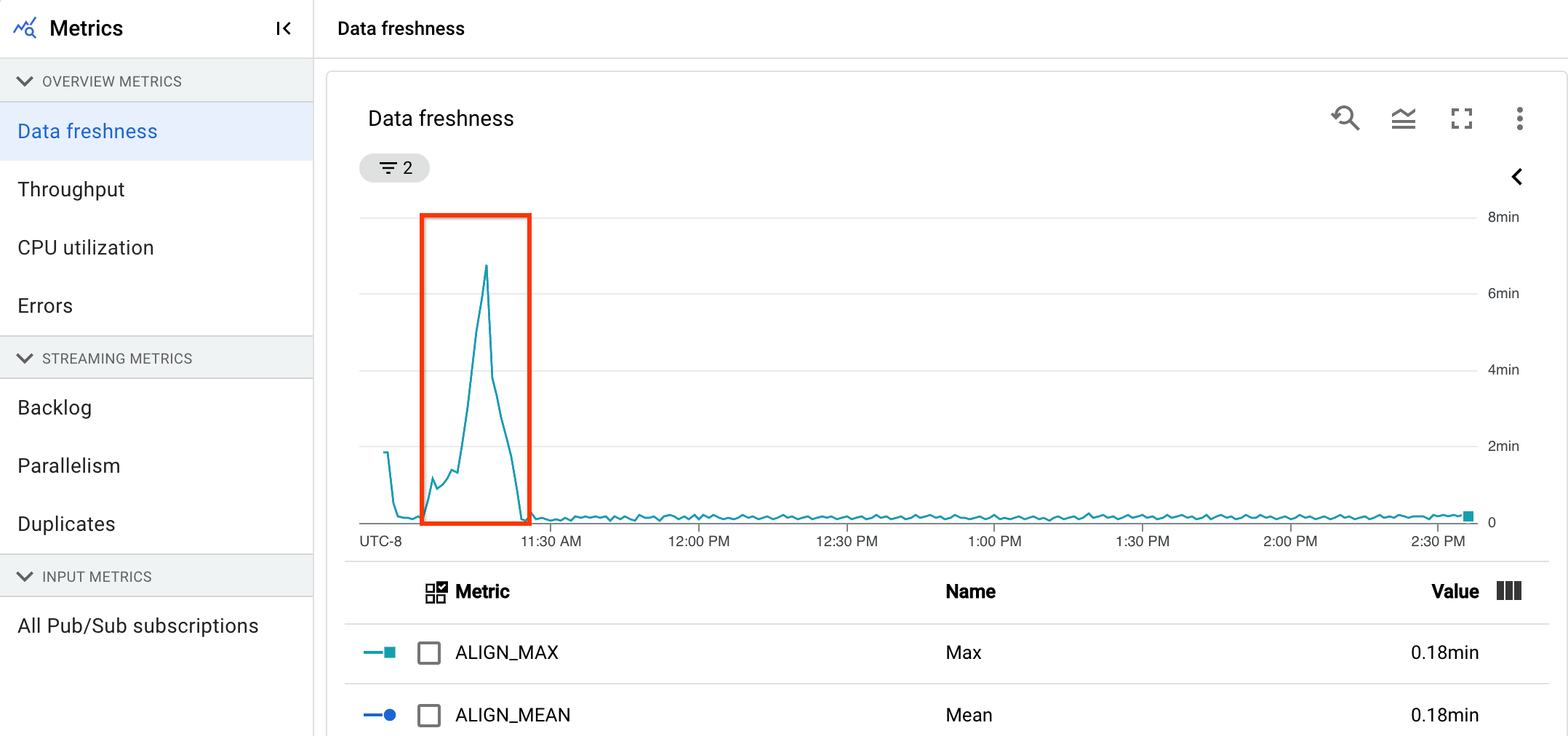
Hohe Werte für diesen Messwert können folgende Ursachen haben:
- Leistungsengpässe: Wenn Ihre Pipeline Phasen mit einer hohen Systemlatenz oder Logs aufweist, die auf hängende Transformationen hinweisen, kann die Pipeline Leistungsprobleme aufweisen, die die Datenaktualität erhöhen können. Weitere Informationen finden Sie unter Fehlerbehebung bei langsamen oder hängenden Streamingjobs.
- Engpässe in der Datenquelle: Wenn Ihre Datenquellen wachsende Rückstände haben, können die Ereigniszeitstempel Ihrer Elemente vom Wasserzeichen abweichen, wenn sie auf die Verarbeitung warten. Große Rückstände werden häufig durch Leistungsengpässe oder Probleme mit Datenquellen verursacht, die am besten durch Monitoring der von Ihrer Pipeline verwendeten Quellen erkannt werden.
- Ungeordnete Quellen wie Pub/Sub können feste Wasserzeichen erzeugen, auch wenn sie mit einer hohen Rate ausgegeben werden. Das liegt daran, dass Elemente nicht in der Reihenfolge der Zeitstempel ausgegeben werden und das Wasserzeichen auf dem kleinsten unverarbeiteten Zeitstempel basiert.
- Häufige Wiederholungsversuche: Wenn Fehler angezeigt werden, die darauf hinweisen, dass Elemente nicht verarbeitet werden können und noch einmal versucht werden, können ältere Zeitstempel aus wiederholten Elementen die Datenaktualität erhöhen. Die Liste der häufigen Dataflow-Fehler kann Ihnen bei der Fehlerbehebung helfen.
Für kürzlich aktualisierte Streamingjobs sind möglicherweise keine Informationen zum Jobstatus und zum Wasserzeichen verfügbar. Der Aktualisierungsvorgang nimmt mehrere Änderungen vor, deren Weitergabe an die Monitoring-Oberfläche von Dataflow einige Minuten dauern kann. Aktualisieren Sie die Monitoring-Oberfläche fünf Minuten nach der Aktualisierung Ihres Jobs.
Systemlatenz
Dieser Messwert gilt nur für Streamingjobs.
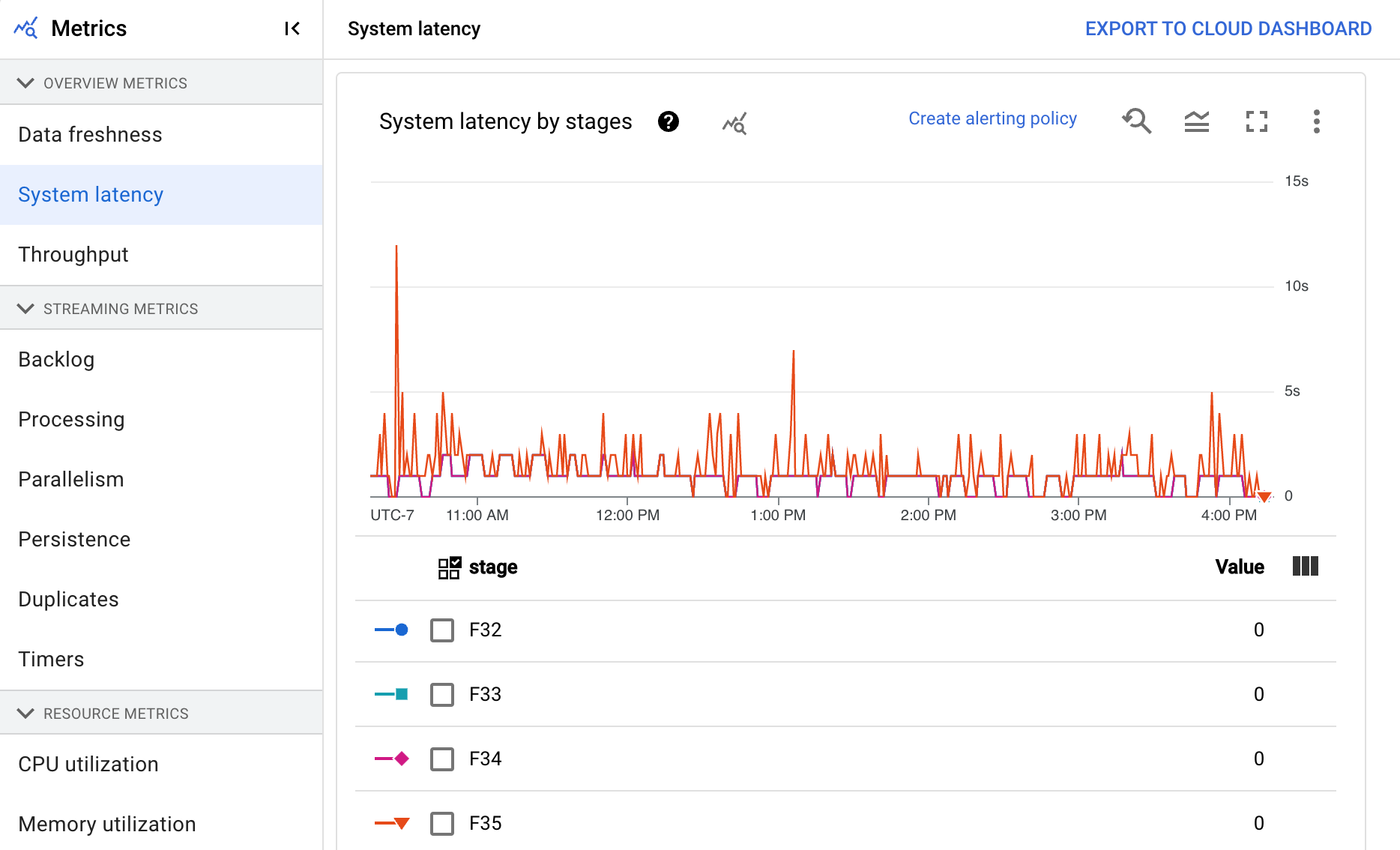
Die Systemlatenz ist die aktuelle maximale Dauer in Sekunden, die ein Datenelement verarbeitet wurde oder auf die Verarbeitung wartet. Der Messwert gibt an, wie lange Elemente in einer Quelle warten. Wenn ein Ausgabeziel beispielsweise für einen bestimmten Zeitraum keine Schreibanfragen mehr akzeptiert, können sich Daten an der Quelle ansammeln, was zu einer höheren Systemlatenz führt. Wenn die Schreibvorgänge fortgesetzt werden und die Pipeline aufholen kann, kehrt die Systemlatenz zum Ausgangsniveau zurück.
Weitere Hinweise:
- Bei mehreren Quellen und Senken ist die Systemlatenz die maximale Zeitspanne, die ein Element innerhalb einer Quelle wartet, bevor es in alle Senken geschrieben wird.
- Manchmal gibt eine Quelle keinen Wert für den Zeitraum an, für den ein Element innerhalb der Quelle wartet. Außerdem kann das Element keine Metadaten haben, um die Ereigniszeit zu definieren. In diesem Szenario wird die Systemlatenz ab dem Zeitpunkt berechnet, an dem die Pipeline das Element empfängt.
Das Dashboard enthält die folgenden zwei Diagramme:
- Systemlatenz nach Phasen
- Systemlatenz
Durchsatz
Der Durchsatz ist das Datenvolumen, das zu einem bestimmten Zeitpunkt verarbeitet wird. Das Dashboard enthält die folgenden Diagramme:
- Durchsatz pro Schritt in Elementen pro Sekunde
- Durchsatz pro Schritt in Byte pro Sekunde
Logzähler für Worker-Fehler
In Logzähler für Worker-Fehler sehen Sie die Fehlerquote der einzelnen Worker zum jeweiligen Zeitpunkt.

Streaming-Messwerte
Die folgenden Messwerte werden unter Streaming-Messwerte angezeigt.
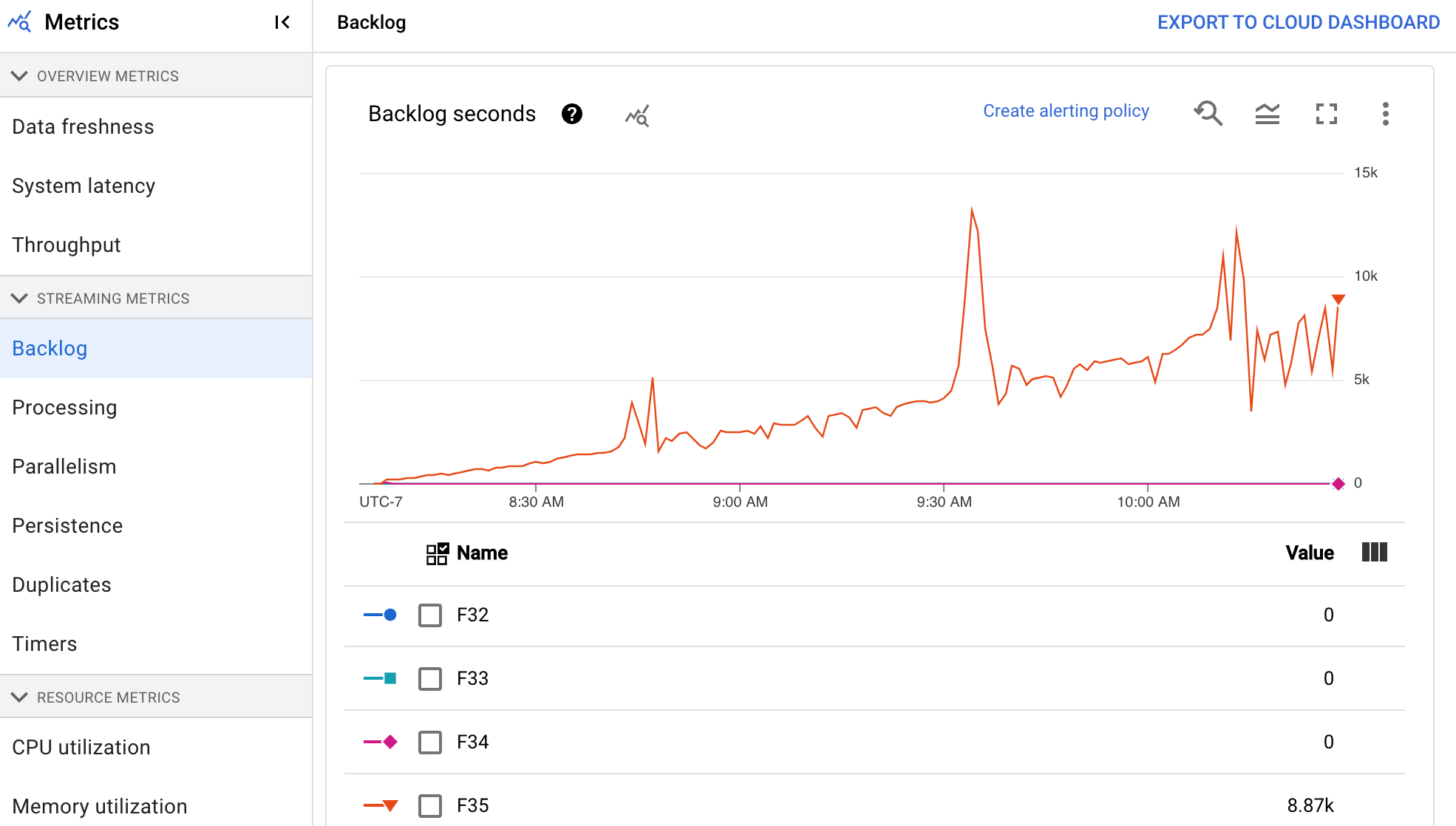
Rückstand
Dieser Messwert gilt nur für Streamingjobs.
Das Dashboard Rückstand enthält Informationen zu Elementen, die noch verarbeitet werden müssen. Das Dashboard enthält die folgenden zwei Diagramme:
- Rückstandssekunden (nur Streaming Engine)
- Rückstand in Byte (mit und ohne Streaming Engine)
Das Diagramm Rückstandsekunden zeigt eine Schätzung der Zeit in Sekunden, die benötigt wird, um den aktuellen Rückstand zu verarbeiten, wenn keine neuen Daten eintreffen und sich der Durchsatz nicht ändert. Die geschätzte Rückstandszeit wird sowohl aus dem Durchsatz als auch aus den Rückstandbyte aus der Eingabequelle berechnet, die noch verarbeitet werden müssen. Dieser Messwert wird vom Feature Streaming-Autoscaling verwendet, um zu bestimmen, wann hoch- oder herunterskaliert werden soll.
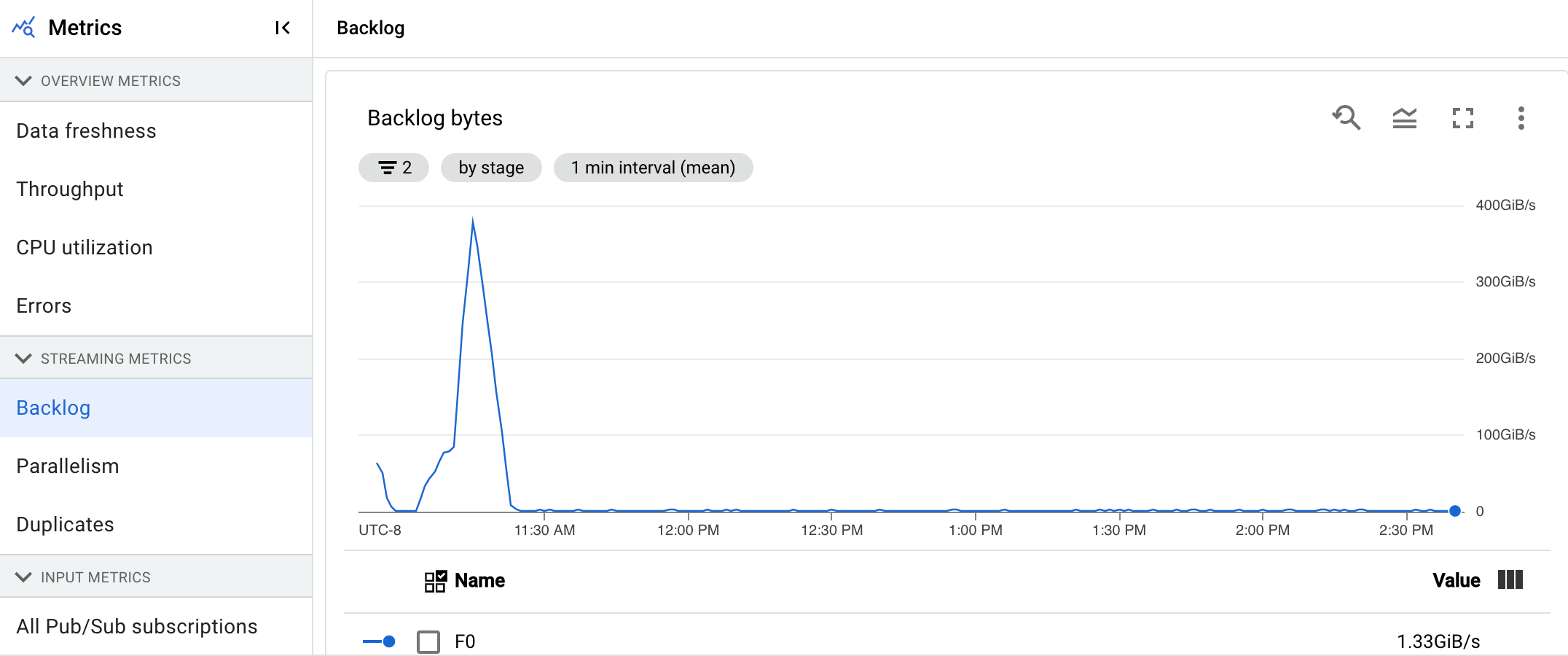
Das Diagramm Rückstandbyte zeigt die Menge der bekannten nicht verarbeiteten Eingaben für eine Phase in Byte an. Bei diesem Messwert werden die verbleibenden Byte, die von jeder Phase verbraucht werden, mit den vorgelagerten Phasen verglichen. Damit dieser Messwert genau die Berichte meldet, muss jede von der Pipeline aufgenommene Quelle korrekt konfiguriert sein. Integrierte Quellen wie Pub/Sub und BigQuery werden bereits standardmäßig unterstützt. Benutzerdefinierte Quellen erfordern jedoch eine zusätzliche Implementierung. Weitere Informationen finden Sie unter Autoscaling für benutzerdefinierte unbegrenzte Quellen.
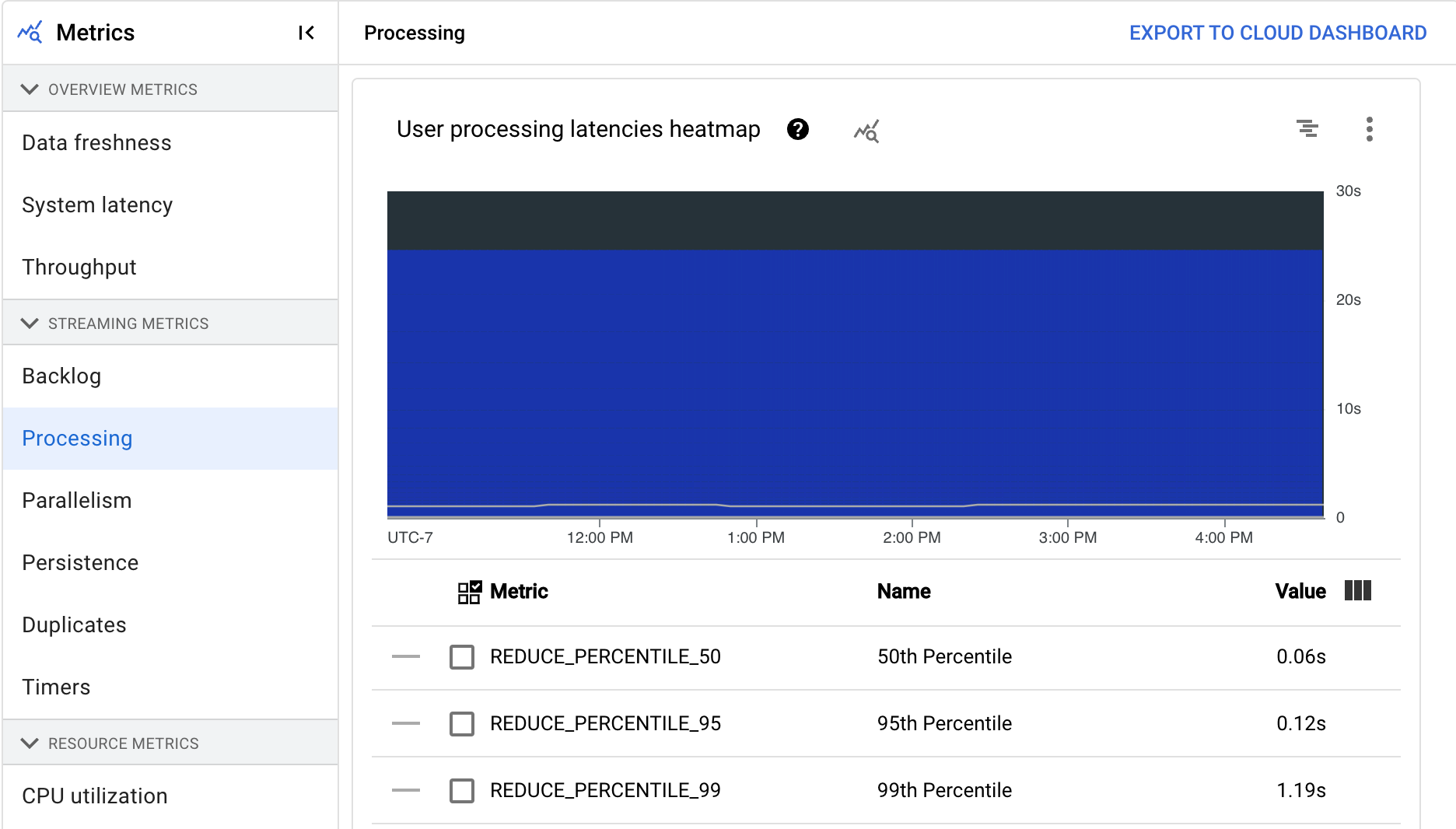
Verarbeitung
Dieser Messwert gilt nur für Streamingjobs.
Wenn Sie eine Apache Beam-Pipeline im Dataflow-Dienst ausführen, werden Pipelineaufgaben auf Worker-VMs ausgeführt. Das Dashboard Verarbeitung enthält Informationen dazu, wie lange Aufgaben auf den Worker-VMs verarbeitet wurden. Das Dashboard enthält die folgenden zwei Diagramme:
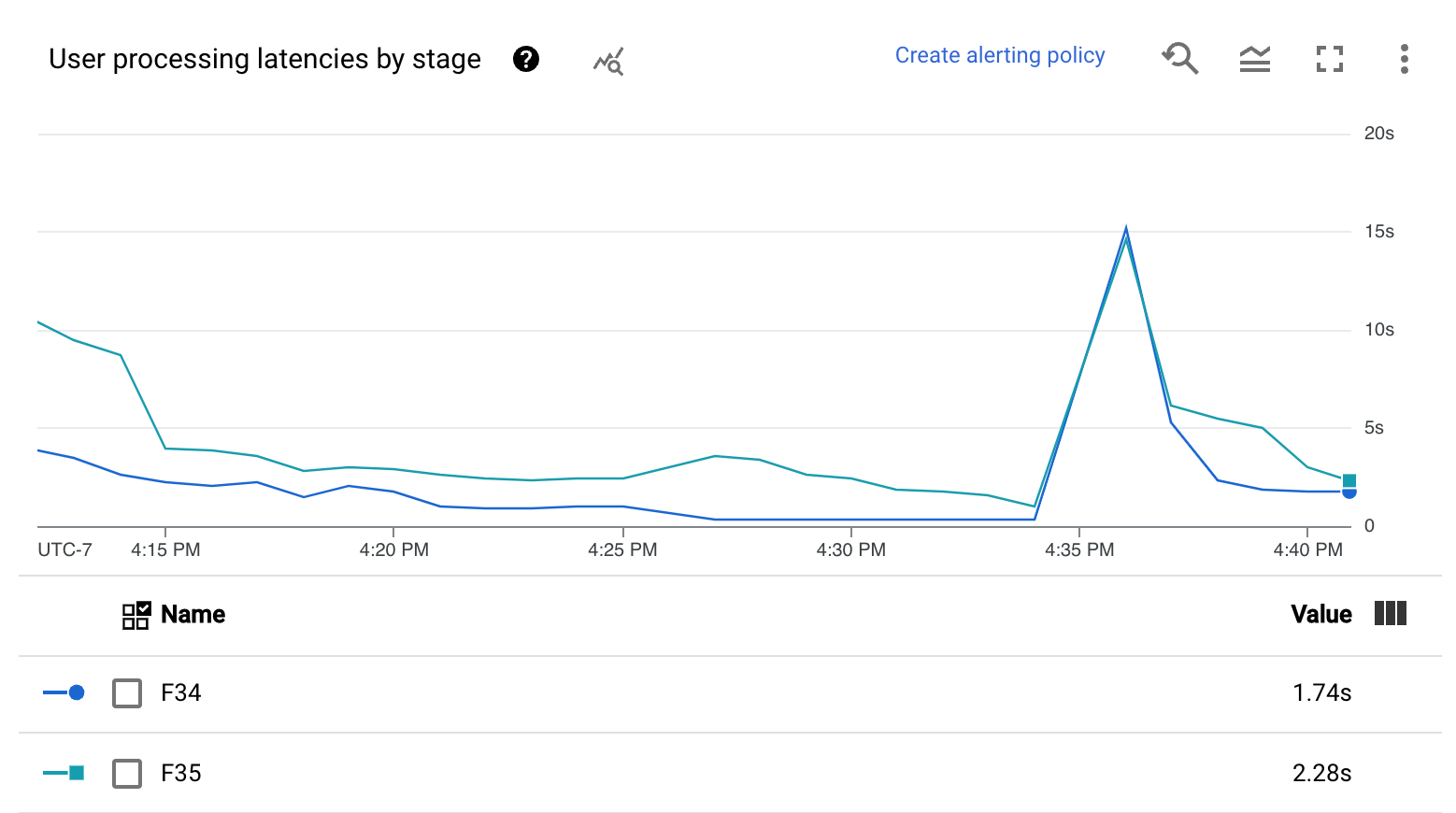
- Heatmap der Nutzerverarbeitungslatenzen
- Nutzerverarbeitungslatenzen nach Phase
Die Heatmap zur Nutzerverarbeitungslatenz zeigt die maximalen Latenzen für Vorgänge über die Verteilungen des 50., 95. und 99. Perzentils. Mit der Heatmap können Sie feststellen, ob Longtail-Vorgänge eine hohe Gesamtsystemlatenz oder die Gesamtdatenaktualität negativ beeinträchtigen.
Um ein Upstream-Problem zu beheben, bevor es zu einem Problem wird, legen Sie eine Benachrichtigungsrichtlinie für hohe Latenzen im 50. Perzentil fest.
Im Diagramm Nutzerverarbeitungslatenzen nach Phase wird das 99. Perzentil für alle Aufgaben angezeigt, die Worker nach Phase verarbeiten. Verursacht Nutzercode einen Engpass, wird in diesem Diagramm angezeigt, welche Phase den Engpass enthält. Mit den folgenden Schritten können Sie Fehler in der Pipeline beheben:
Verwenden Sie das Diagramm, um eine Phase mit ungewöhnlich hoher Latenz zu finden.
Wählen Sie auf der Seite mit den Jobdetails auf dem Tab Ausführungsdetails für Grafikansicht die Option Phasenworkflow aus. Suchen Sie im Diagramm Phasenworkflow nach der Phase mit ungewöhnlich hoher Latenz.
Klicken Sie im Diagramm auf den Knoten für diese Phase, um die zugehörigen Nutzervorgänge zu ermitteln.
Für weitere Details rufen Sie Cloud Profiler auf und verwenden Sie Cloud Profiler, um Fehler im Stacktrace zum richtigen Zeitraum zu beheben. Suchen Sie nach den Nutzervorgängen, die Sie im vorherigen Schritt ermittelt haben.
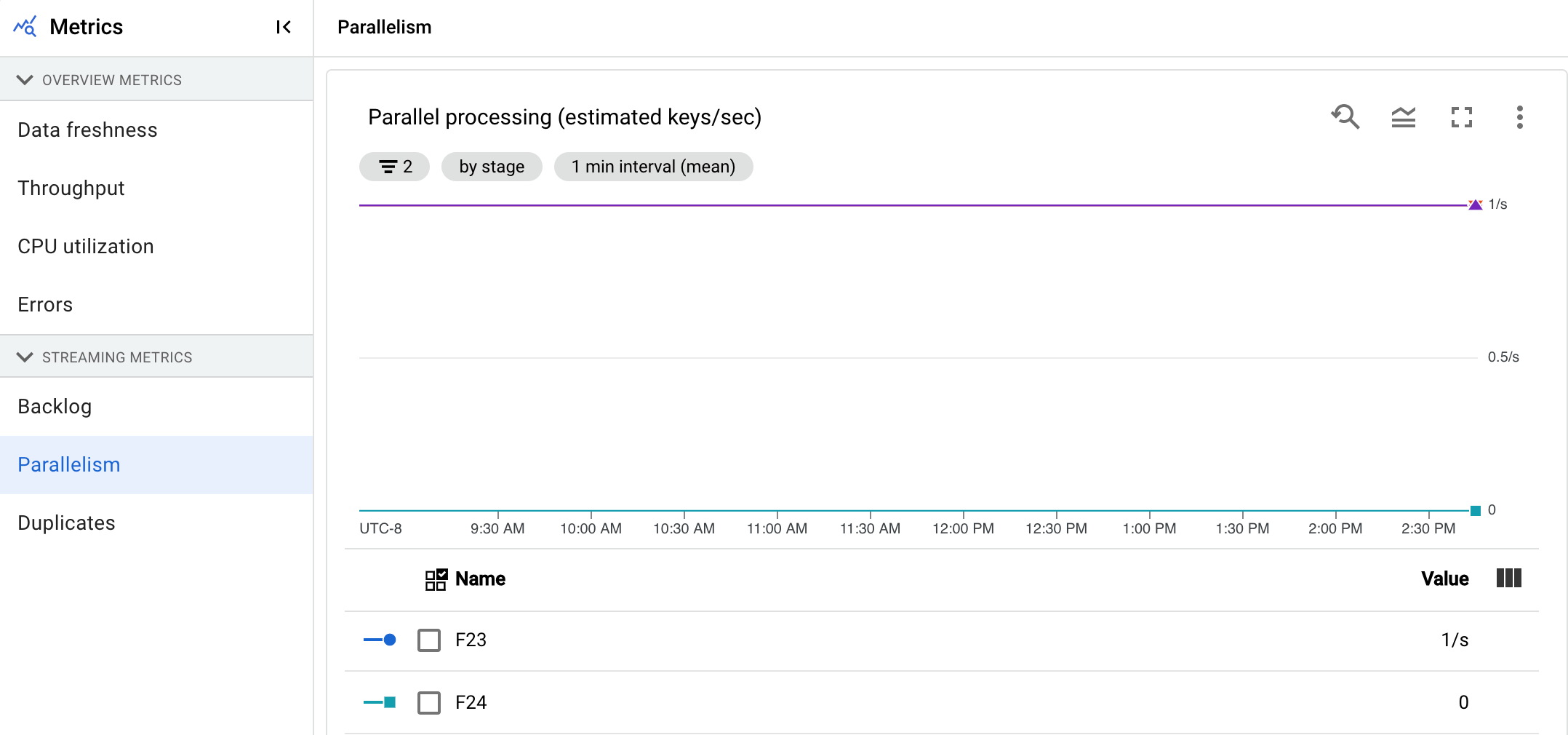
Parallelität
Dieser Messwert gilt nur für Streaming Engine-Jobs.
Das Diagramm Parallelverarbeitung zeigt die ungefähre Anzahl der Schlüssel an, die für die Datenverarbeitung in jeder Phase verwendet werden. Dataflow skaliert auf der Grundlage der Parallelität einer Pipeline.
Wenn Dataflow eine Pipeline ausführt, wird die Verarbeitung auf mehrere Compute Engine-VMs (VMs) verteilt, die auch als Worker bezeichnet werden. Der Dataflow-Dienst parallelisiert und verteilt die Verarbeitungslogik in Ihrer Pipeline automatisch an die Worker. Die Verarbeitung für einen bestimmten Schlüssel ist serialisiert, sodass die Gesamtzahl der Schlüssel für eine Phase die maximal verfügbare Parallelität in dieser Phase darstellt.
Parallelitätsmesswerte können nützlich sein, um heiße Schlüssel oder Engpässe für langsame oder hängende Pipelines zu ermitteln.
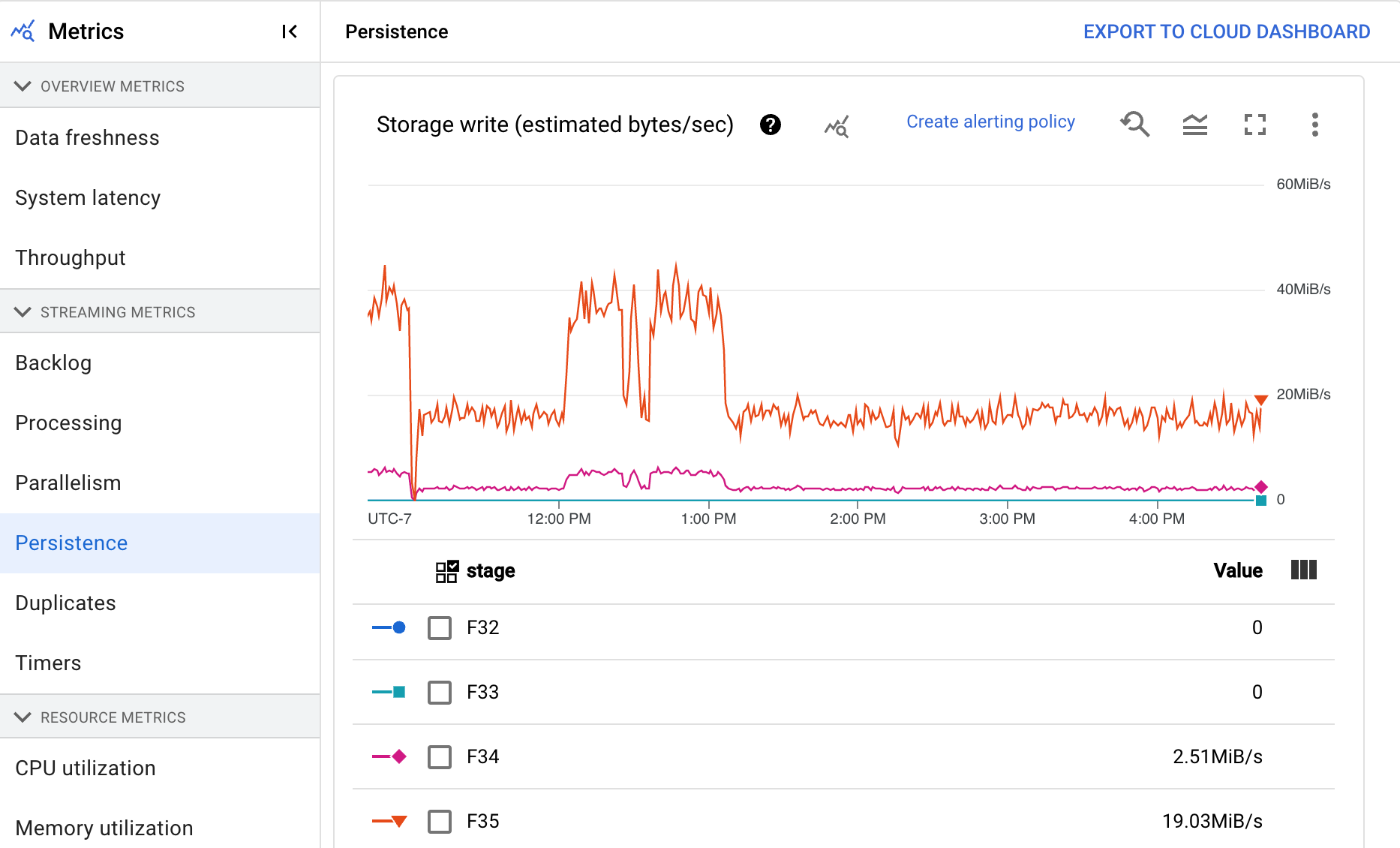
Persistenz
Dieser Messwert gilt nur für Streamingjobs.
Das Dashboard Persistenz bietet Informationen zur Rate, mit der nichtflüchtiger Speicher von einer bestimmten Pipelinephase in Byte pro Sekunde geschrieben und gelesen wird. Zu den gelesenen und geschriebenen Byte gehören Nutzerstatusvorgänge und Status für persistente Shuffles, Entfernen von Duplikaten, Nebeneingaben und Wasserzeichen-Tracking. Pipeline-Codierung und Caching wirken sich auf die gelesenen und geschriebenen Byte aus. Die Anzahl der Speicher-Bytes kann sich aufgrund der internen Speichernutzung und des Caching von der Anzahl der verarbeiteten Bytes unterscheiden.
Das Dashboard enthält die folgenden zwei Diagramme:
- Schreiben in Speicher
- Speicherlesevorgänge
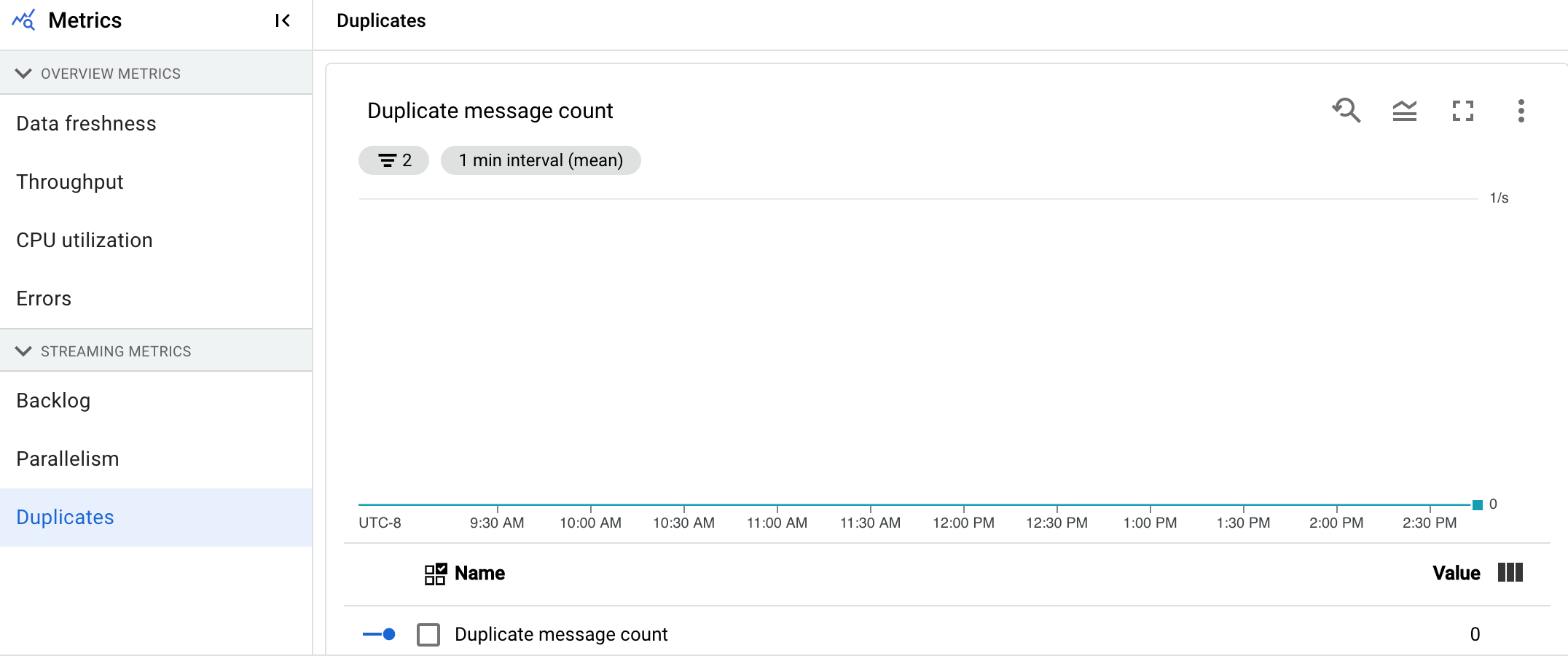
Duplikate
Dieser Messwert gilt nur für Streamingjobs.
Das Diagramm Duplikate zeigt die Anzahl der Nachrichten, die von einer bestimmten Phase verarbeitet wurden und als Duplikate herausgefiltert wurden.
Dataflow unterstützt viele Quellen und Senken, die eine at least once-Zustellung garantieren. Der Nachteil der at least once-Zustellung ist, dass sie zu Duplikaten führen kann.
Dataflow garantiert die exactly once-Zustellung, d. h. Duplikate werden automatisch herausgefiltert.
Nachgelagerte Phasen werden aus der erneuten Verarbeitung derselben Elemente gespeichert, wodurch sichergestellt wird, dass der Status und die Ausgaben nicht betroffen sind.
Die Pipeline kann für Ressourcen und Leistung optimiert werden, indem die Anzahl der Duplikate in jeder Phase reduziert wird.
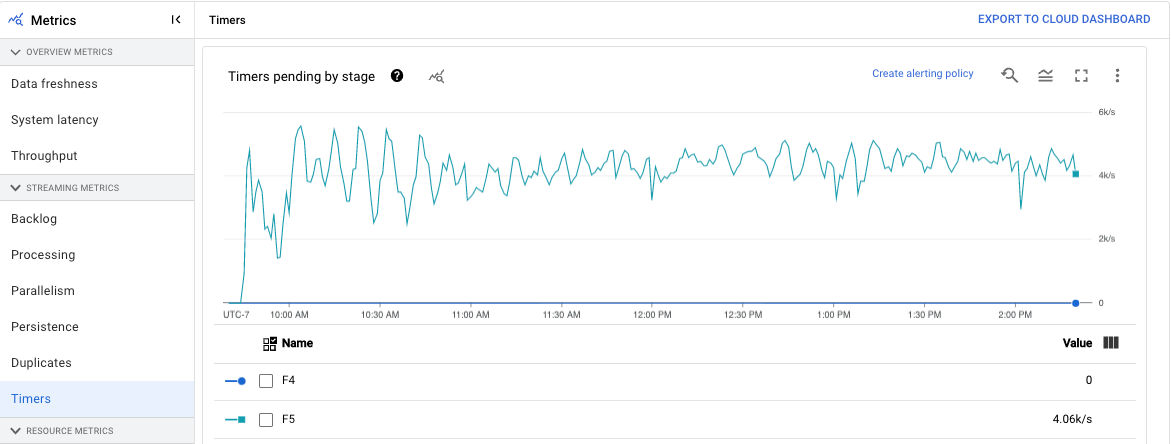
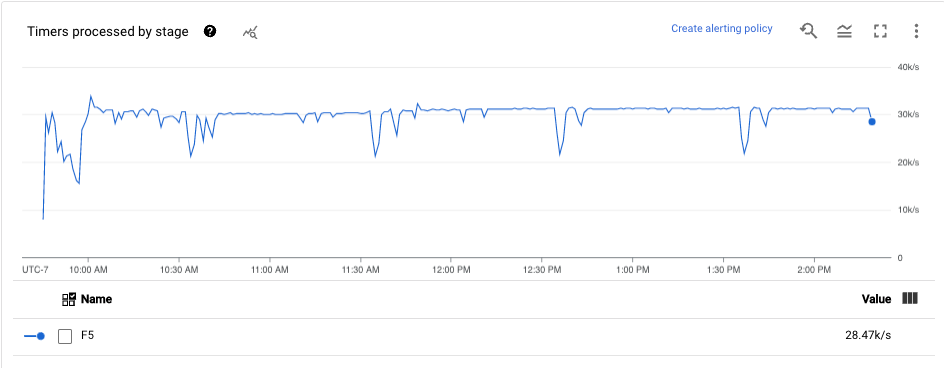
Timer
Dieser Messwert gilt nur für Streamingjobs.
Das Dashboard Timer enthält Informationen zur Anzahl der ausstehenden Timer und zur Anzahl der Timer, die bereits in einer bestimmten Pipelinephase verarbeitet wurden. Da Fenster auf Timer angewiesen sind, können Sie mit diesem Messwert den Fortschritt von Fenstern verfolgen.
Das Dashboard enthält die folgenden zwei Diagramme:
- Ausstehende Timer nach Phase
- Timer für die Verarbeitung nach Phase
Diese Diagramme zeigen die Rate, zu der Fenster zu einem bestimmten Zeitpunkt ausstehen oder verarbeitet werden. Das Diagramm Timer nach Phase gibt an, wie viele Fenster aufgrund von Engpässen verzögert werden. Das Diagramm Timer für die Verarbeitung nach Phase gibt an, wie viele Fenster derzeit Elemente erfassen.
In diesen Diagrammen werden alle Job-Timer angezeigt. Wenn Timer an anderer Stelle im Code verwendet werden, werden diese Timer ebenfalls in diesen Diagrammen angezeigt.
Ressourcenmesswerte
Die folgenden Messwerte werden unter Ressourcenmesswerte angezeigt.
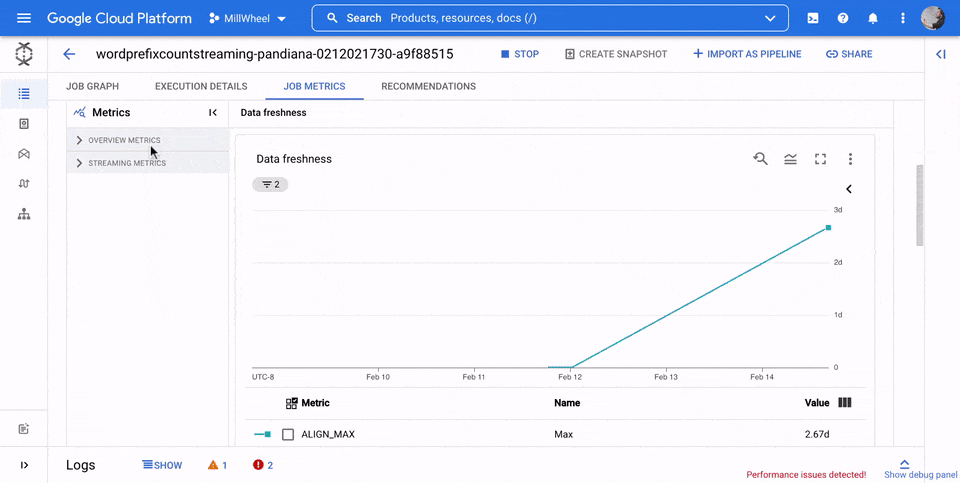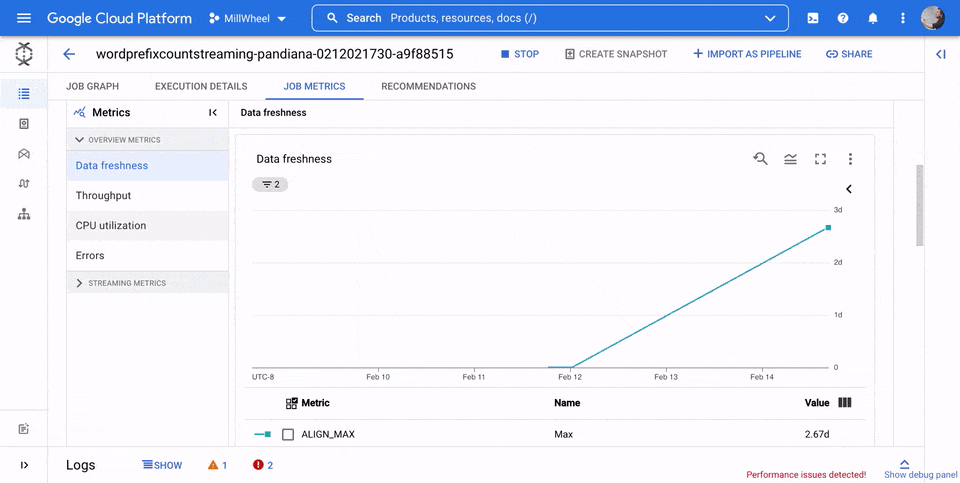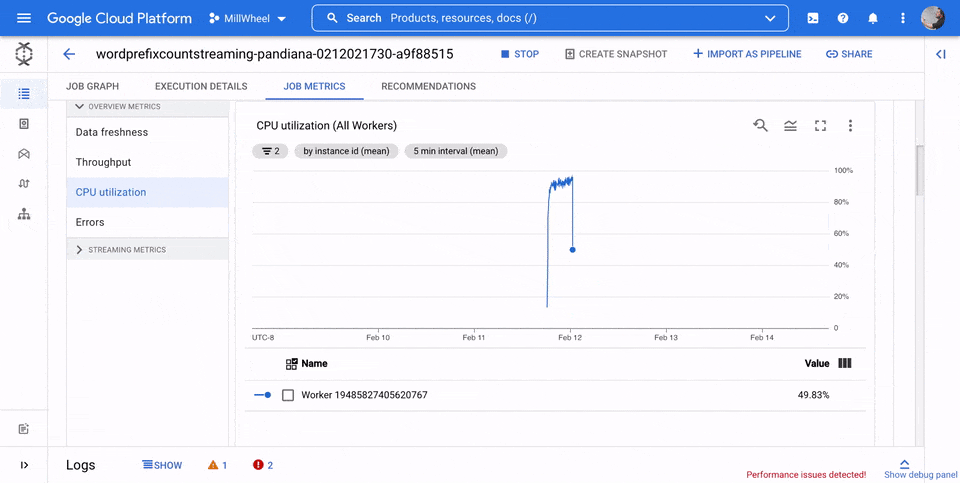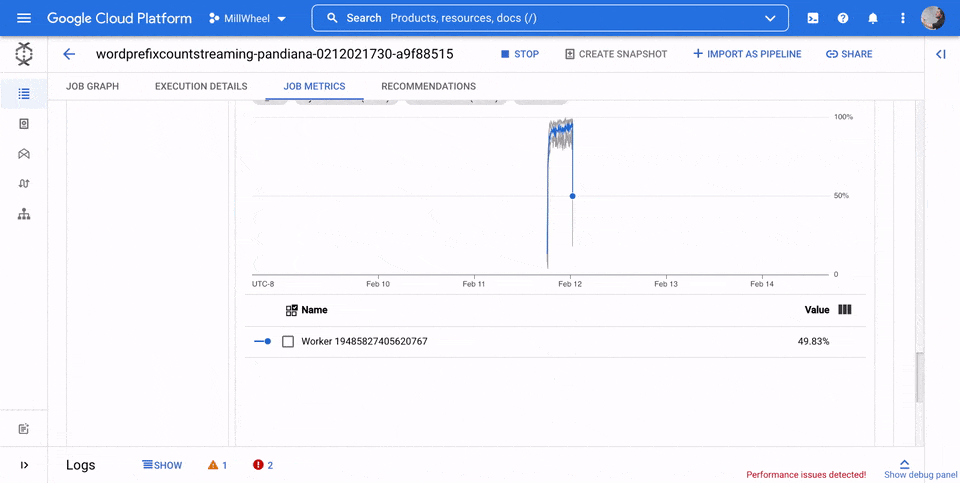
CPU-Auslastung
Die CPU-Auslastung ist die genutzte CPU-Kapazität, geteilt durch die CPU-Kapazität, die für die Verarbeitung verfügbar ist. Dieser Messwert pro Worker wird als Prozentsatz angezeigt. Das Dashboard enthält die folgenden vier Diagramme:
- CPU-Auslastung (Alle Worker)
- CPU-Auslastung (Stats)
- CPU-Auslastung (Obere 4)
- CPU-Auslastung (Untere 4)
Arbeitsspeicherauslastung
Die Speicherauslastung ist die geschätzte Speichermenge, die von den Workern in Byte pro Sekunde verwendet wird. Das Dashboard enthält die folgenden zwei Diagramme:
- Maximale Worker-Speicherauslastung (geschätzte Byte pro Sekunde)
- Speicherauslastung (geschätzte Byte pro Sekunde)
Das Diagramm Maximale Worker-Auslastung enthält Informationen zu den Workern, die zu jedem Zeitpunkt den meisten Arbeitsspeicher im Dataflow-Job verwenden. Wenn sich der Worker an verschiedenen Punkten während eines Jobs ändert, der die maximale Speichermenge verwendet, zeigt dieselbe Linie im Diagramm Daten für mehrere Worker an. Jeder Datenpunkt in der Linie zeigt Daten für den Worker mit der maximalen Speichermenge zu diesem Zeitpunkt an. Das Diagramm vergleicht den geschätzten Worker, der vom Worker verwendet wird, mit dem Arbeitsspeicherlimit in Byte.
Sie können dieses Diagramm verwenden, um Probleme mit unzureichendem Speicherplatz zu beheben. Abstürze ohne Worker-Speicher werden in diesem Diagramm nicht angezeigt.
Das Diagramm Speicherauslastung zeigt eine Schätzung des Arbeitsspeichers, der von allen Workern im Dataflow-Job verwendet wird, im Vergleich zum Arbeitsspeicherlimit in Byte.
Eingabe- und Ausgabemesswerte
Wenn Ihr Dataflow-Streamingjob Datensätze mit Pub/Sub liest oder schreibt, werden auf dem Tab Jobmesswerte Messwerte für Pub/Sub-Lese- oder ‑Schreibvorgänge angezeigt.
Alle Eingabemesswerte desselben Typs werden kombiniert und auch alle Ausgabemesswerte werden kombiniert. Beispielsweise werden alle Pub/Sub-Messwerte in einem Abschnitt gruppiert. Jeder Messwerttyp ist in einem separaten Abschnitt organisiert. Wählen Sie den Abschnitt auf der linken Seite aus, der die gewünschten Messwerte darstellt, um die angezeigten Messwerte zu ändern. In den folgenden Abbildungen sind alle verfügbaren Abschnitte aufgeführt.
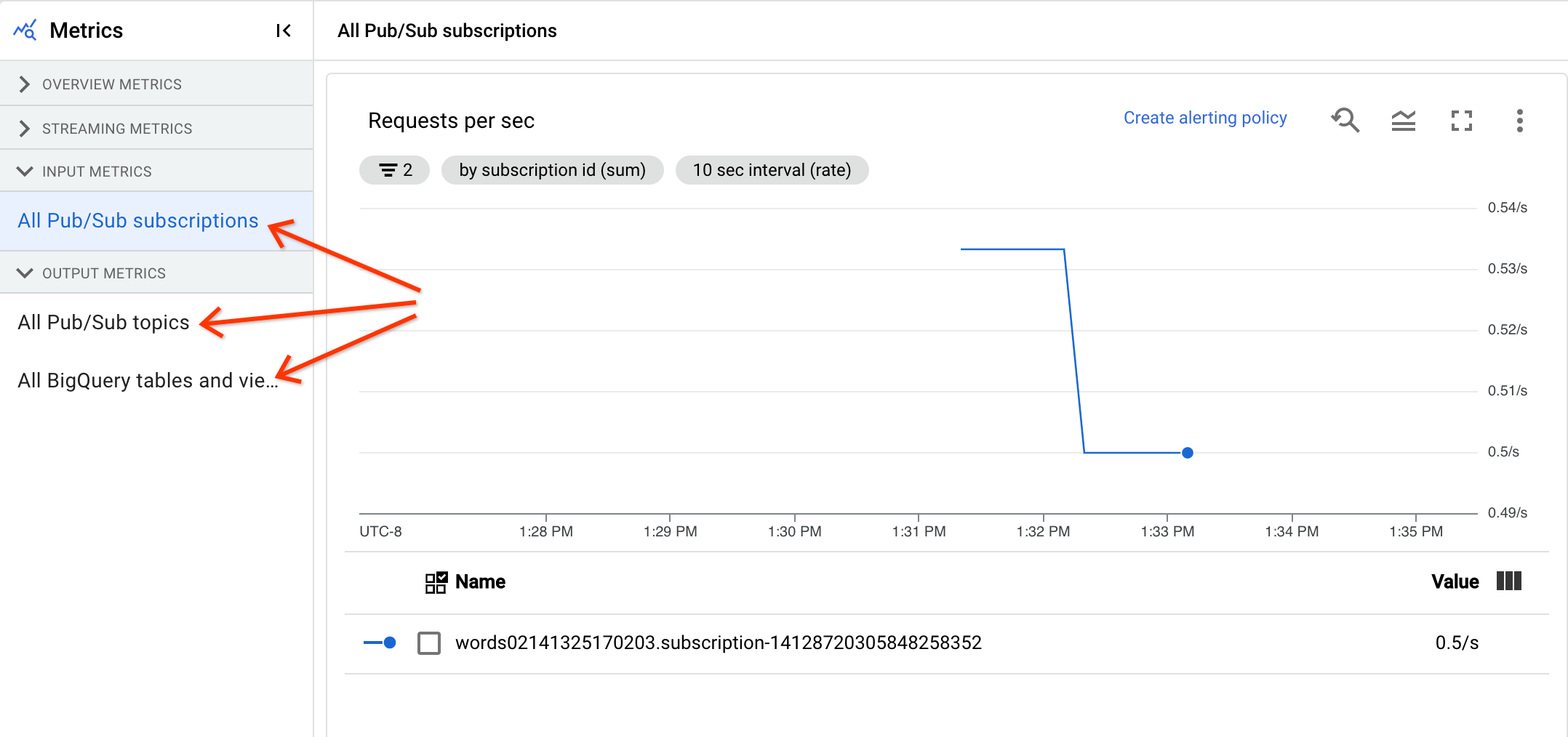
Die folgenden beiden Diagramme werden sowohl im Bereich Eingabemesswerte als auch im Bereich Ausgabemesswerte angezeigt.
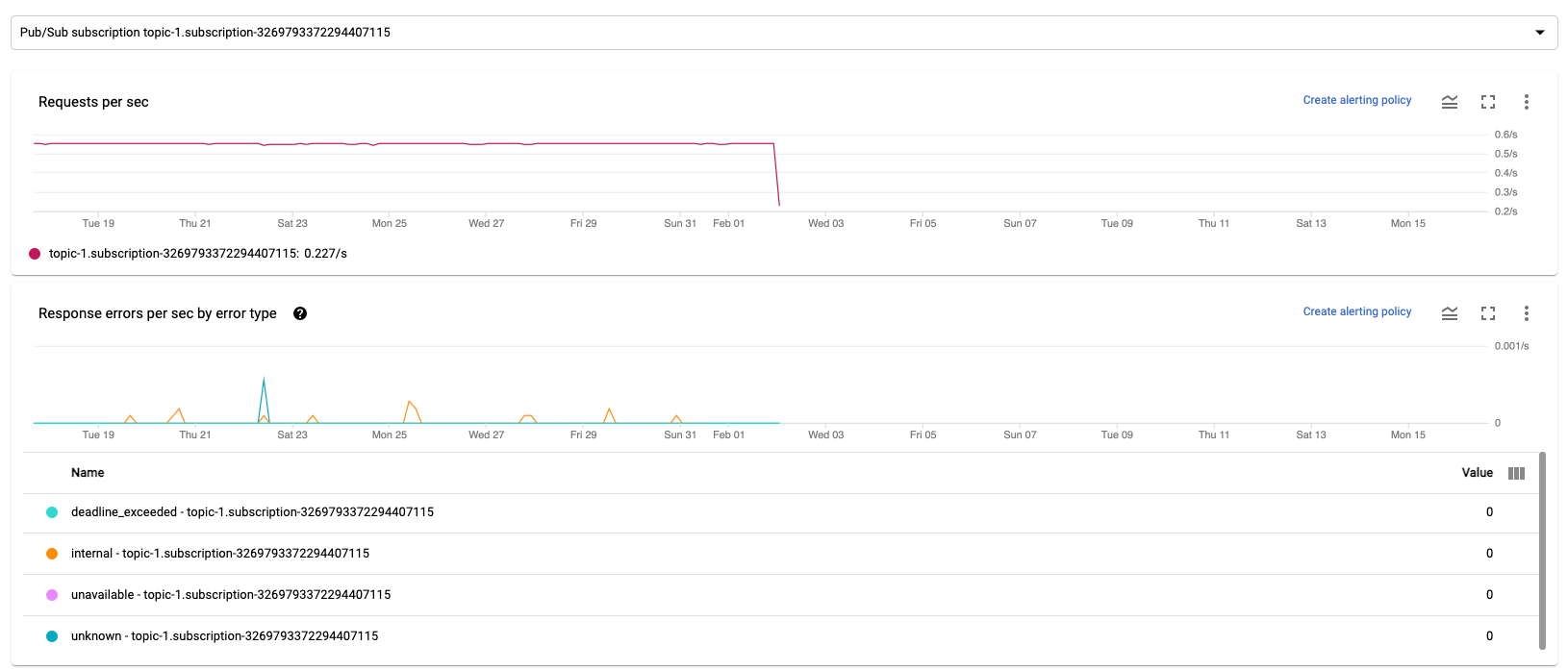
Anfragen pro Sekunde
„Anfragen pro Sekunde“ ist die Rate von API-Anfragen der Quelle oder Senke zum Lesen oder Schreiben von Daten im Zeitverlauf. Wenn diese Rate auf null sinkt oder erheblich für einen längeren Zeitraum relativ zum erwarteten Verhalten sinkt, kann die Pipeline bestimmte Vorgänge möglicherweise nicht ausführen. Außerdem liegen unter Umständen keine Daten zum Lesen vor. Überprüfen Sie in einem solchen Fall die Jobschritte mit einem hohen Systemwasserzeichen. Überprüfen Sie auch die Worker-Logs auf Fehler oder Hinweise auf eine langsame Verarbeitung.

Antwortfehler pro Sekunde nach Fehlertyp
„Antwortfehler pro Sekunde nach Fehlertyp“ ist die Rate fehlgeschlagener API-Anfragen von der Quelle oder Senke zum Lesen oder Schreiben von Daten im Zeitverlauf. Wenn solche Fehler häufig auftreten, verlangsamen diese API-Anfragen möglicherweise die Verarbeitung. Diese fehlgeschlagenen API-Anfragen müssen untersucht werden. Informationen zur Behebung dieser Probleme finden Sie in den allgemeinen Eingabe- und Ausgabefehlercodes. Lesen Sie auch die Dokumentation der jeweiligen Fehlercodes, die von der Quelle oder Senke verwendet wird, z. B. die Pub/Sub-Fehlercodes.
Weitere Informationen zu Szenarien, in denen Sie diese Messwerte für das Debugging verwenden können, finden Sie unter Tools zum Debugging in „Fehlerbehebung bei langsamen oder hängenden Jobs“.
Cloud Monitoring verwenden
Dataflow ist vollständig in Cloud Monitoring eingebunden. Verwenden Sie Cloud Monitoring für die folgenden Aufgaben:
- Erstellen Sie Benachrichtigungen, wenn der Job einen benutzerdefinierten Grenzwert überschreitet.
- Verwenden Sie den Metrics Explorer, um Abfragen zu erstellen und die Zeitspanne der Messwerte anzupassen.
- Messwerte ansehen, die nicht auf der Dataflow-Monitoring-Oberfläche angezeigt werden.
Eine Anleitung zum Erstellen von Benachrichtigungen und zur Verwendung von Metrics Explorer finden Sie unter Cloud Monitoring für Dataflow-Pipelines verwenden.
Die vollständige Liste der Dataflow-Messwerte finden Sie in der Dokumentation zu Google Cloud-Messwerten.
Cloud Monitoring-Benachrichtigungen erstellen
Mit Cloud Monitoring können Sie Benachrichtigungen erstellen, wenn Ihr Dataflow-Job einen benutzerdefinierten Grenzwert überschreitet. Klicken Sie zum Erstellen einer Cloud Monitoring-Benachrichtigung aus einem Messwertdiagramm auf Benachrichtigungsrichtlinie erstellen.
Wenn Sie die Monitoring-Diagramme nicht sehen oder keine Benachrichtigungen erstellen können, benötigen Sie möglicherweise zusätzliche Monitoring-Berechtigungen.
Im Metrics Explorer ansehen
Sie können die Dataflow-Messwertdiagramme im Metrics Explorer aufrufen, wo Sie Abfragen erstellen und die Zeitspanne der Messwerte anpassen können.
Öffnen Sie zum Anzeigen der Dataflow-Diagramme in Metrics Explorer in der Ansicht Jobmesswerte die Option Weitere Diagrammoptionen und klicken Sie auf Im Metrics Explorer aufrufen.
Wenn Sie die Zeitspanne der Messwerte anpassen, können Sie eine vordefinierte Dauer oder ein benutzerdefiniertes Zeitintervall für die Auswertung des Jobs auswählen.
Standardmäßig werden für Streaming- und In-Flight-Batch-Jobs die Messwerte des letzten sechs Stunden für diesen Job angezeigt. Bei angehaltenen oder fertigen Streamingjobs gibt die Standardanzeige die gesamte Laufzeit der Jobdauer wieder.
Dataflow-E/A-Messwerte
Sie können die folgenden Dataflow-E/A-Messwerte im Metrics Explorer aufrufen:
job/pubsub/write_count: Pub/Sub-Veröffentlichungsanfragen von PubsubIO.Write in Dataflow-Jobs.job/pubsub/read_count: Pub/Sub-Pull-Anfragen von Pubsub.IO.Read in Dataflow-Jobs.job/bigquery/write_count: BigQuery-Veröffentlichungsanfragen von BigQueryIO.Write in Dataflow-Jobs.job/bigquery/write_count-Messwerte sind in Python-Pipelines mithilfe der WriteToBigQuery-Transformation verfügbar, wennmethod='STREAMING_INSERTS'für Apache Beam Version 2.28.0 oder höher aktiviert ist. Dieser Messwert ist sowohl für Batch- als auch für Streamingpipelines verfügbar.- Wenn Ihre Pipeline eine BigQuery-Quelle oder -Senke verwendet, verwenden Sie die BigQuery Storage API-Messwerte, um Kontingentprobleme zu beheben.
DoFn-Messwerte
Für Streamingjobs, die Streaming Engine verwenden und nicht Runner v2, können Sie die folgenden Messwerte für einzelne nutzerdefinierte DoFns aufrufen:
job/dofn_latency_average: Die durchschnittliche Nachrichtenverarbeitungszeit für eine einzelneDoFnim 3-Minuten-Zeitraum davor in Millisekunden.job/dofn_latency_max: Die maximale Nachrichtenverarbeitungszeit für eine einzelneDoFnim 3-Minuten-Zeitraum davor in Millisekunden.job/dofn_latency_min: Die minimale Nachrichtenverarbeitungszeit für eine einzelneDoFnim 3-Minuten-Zeitraum in Millisekunden.job/dofn_latency_num_messages: Die Anzahl der Nachrichten, die in den letzten 3 Minuten von einem einzelnenDoFnverarbeitet wurden.job/dofn_latency_total: Die gesamte Nachrichtenverarbeitungszeit für alle Nachrichten in einem einzelnenDoFnim 3-Minuten-Zeitfenster, in Millisekunden.job/oldest_active_message_age: Die Dauer der Verarbeitung der ältesten aktiven Nachricht in einemDoFnin Millisekunden.
Für diese Messwerte ist das Apache Beam SDK in Version 2.53.0 oder höher erforderlich. Verwenden Sie den Metrics Explorer, um diese Messwerte aufzurufen.
Anhand dieser Messwerte können Sie herausfinden, welche DoFns am meisten zur Verarbeitungslatenz in Ihren Jobs beitragen. Wenn ein Job beispielsweise nicht mehr reagiert, können Sie mit dem Messwert job/oldest_active_message_age die DoFn mit der ältesten aktiven Nachricht ermitteln. Das folgende Bild zeigt ein DoFn mit einem großen Anstieg dieses Messwerts:

Wenn Sie den Namen des DoFn sehen möchten, halten Sie den Mauszeiger über die Diagrammlinie.
Nächste Schritte
- Fehlerbehebung bei langsamen oder hängenden Streamingjobs
- Fehlerbehebung bei langsamen oder hängenden Batchjobs
- Horizontales Autoscaling für Streamingpipelines optimieren
- Kosten optimieren