このページでは、Cloud Run のボリューム マウントを使用して、Cloud Storage バケットをストレージ ボリュームとしてマウントする方法について説明します。
Cloud Run でバケットをボリュームとしてマウントすると、バケットの内容がコンテナ ファイル システムのファイルとして提示されます。バケットをボリュームとしてマウントした後、Google API クライアント ライブラリではなく、プログラミング言語のファイル システム オペレーションとライブラリを使用して、バケットにローカル ファイル システムのディレクトリのようにアクセスします。
ボリュームを読み取り専用としてマウントできます。また、ボリュームのマウント オプションを指定することもできます。
メモリ要件
Cloud Storage ボリューム マウントでは、次のアクティビティに Cloud Run のコンテナメモリが使用されます。すべての Cloud Storage FUSE キャッシュに対して、Cloud Run はデフォルトで統計キャッシュの設定を使用し、有効期間(TTL)を 60 秒に設定します。統計キャッシュのデフォルトの最大サイズは 32 MB、タイプキャッシュのデフォルトの最大サイズは 4 MiB です。
Cloud Storage から読み取る場合、Cloud Storage FUSE は API 呼び出しを行い、ファイル全体をローカル ディレクトリにダウンロードせずにオブジェクトを直接読み取ります。Cloud Storage FUSE は TCP 接続を確立し、Cloud Storage オブジェクト全体を読み取ります。または、アプリケーションまたはオペレーティング システムでオフセットを介して指定したファイルの一部のみを読み取ります。Cloud Storage FUSE は、読み取り時に、統計キャッシュとタイプ キャッシュ以外のメモリも消費します。たとえば、読み取るファイルごとに 1 MiB の配列を消費し、
goroutinesを実行するたびに 1 MiB の配列を消費します。Cloud Storage に書き込む場合、Cloud Storage FUSE はデフォルトで書き込みパスである
streaming-writesをサポートします。Cloud Storage FUSE は、ファイルを完全にステージングせずに、データを Cloud Storage に直接アップロードします。ストリーミング用に開いた各ファイルは、アップロード プロセス中に約 64 MiB のメモリを消費します。これにより、レイテンシとディスク容量の使用量が削減されます。そのため、大規模なシーケンシャル書き込みで特に有効です。
制限事項
Cloud Run は、このボリューム マウントに Cloud Storage FUSE を使用するため、Cloud Storage バケットをボリュームとしてマウントする場合は、次の点に注意してください。
- Cloud Storage FUSE では、同じファイルへの複数書き込みの同時実行制御(ファイルのロック)は行いません。複数の書き込みによってファイルの置き換えが試みられた場合は、最後の書き込みが有効となり、それより前の書き込みはすべて失われます。
- Cloud Storage FUSE は POSIX を完全に遵守したファイル システムではありません。詳細については、Cloud Storage FUSE のドキュメントをご覧ください。
使用できないパス
Cloud Run では、/dev、/proc、/sys、またはそのサブディレクトリにボリュームをマウントすることはできません。
始める前に
ボリュームとしてマウントするには、Cloud Storage バケットが必要です。
Cloud Storage への読み取り / 書き込みのパフォーマンスを最適化するには、Cloud Storage FUSE ネットワーク帯域幅のパフォーマンスの最適化をご覧ください。
必要なロール
Cloud Storage ボリューム マウントの構成に必要な権限を取得するには、次の IAM ロールを付与するよう管理者に依頼してください。
-
Cloud Run ジョブに対する Cloud Run デベロッパー(
roles/run.developer) -
サービス ID に対するサービス アカウント ユーザー(
roles/iam.serviceAccountUser)
ファイルと Cloud Storage バケットにアクセスするためにサービス ID に必要な権限を取得するには、サービス ID に Storage オブジェクト閲覧者(roles/storage.objectViewer)ロールを付与するよう管理者に依頼してください。サービス ID がバケット内で書き込みオペレーションも実行する必要がある場合は、代わりに Storage オブジェクト ユーザー(roles/storage.objectUser)ロールを付与します。
Cloud Storage のロールと権限の詳細については、Cloud Storage の IAM をご覧ください。
Cloud Run に関連付けられている IAM ロールと権限のリストについては、Cloud Run IAM ロールと Cloud Run IAM 権限をご覧ください。Cloud Run ジョブがGoogle Cloud API(Cloud クライアント ライブラリなど)と連携している場合は、サービス ID の構成ガイドをご覧ください。ロールの付与の詳細については、デプロイ権限とアクセスの管理をご覧ください。
Cloud Storage ボリュームをマウントする
複数のバケットを異なるマウントパスにマウントできます。複数のコンテナで同じマウントパスまたは異なるマウントパスを使用して、ボリュームを複数のコンテナにマウントすることもできます。
複数のコンテナを使用している場合は、まずボリュームを指定してから、各コンテナのボリューム マウントを指定します。
コンソール
Google Cloud コンソールで、Cloud Run の [ジョブ] ページに移動します。
メニューから [ジョブ] を選択し、[コンテナをデプロイ] をクリックして、ジョブの初期設定ページに入力します。既存のジョブを構成する場合は、ジョブを選択して [ジョブ構成を表示して編集] をクリックします。
[コンテナ、ボリューム、接続、セキュリティ] をクリックして、ジョブのプロパティ ページを開きます。
[ボリューム] タブをクリックします。
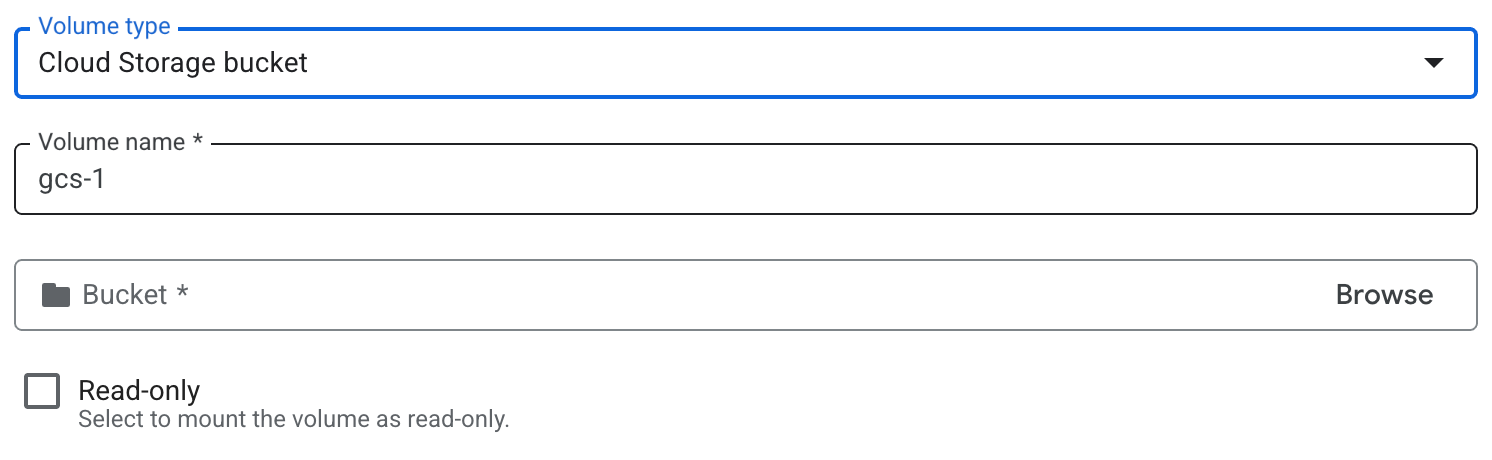
- [ボリューム] で、次の操作を行います。
- [ボリュームを追加] をクリックします。
- [ボリュームのタイプ] プルダウンで、ボリューム タイプとして Cloud Storage バケットを選択します。
- [ボリューム名] フィールドに、ボリュームに使用する名前を入力します。
- ボリュームに使用するバケットまたは特定のディレクトリを参照して選択します。必要に応じて、新しいバケットを作成します。
- 必要に応じて、[読み取り専用] チェックボックスをオンにして、バケットを読み取り専用にします。
- [完了] をクリックします。
- [コンテナ] タブをクリックし、ボリュームをマウントするコンテナを開いて、コンテナを編集します。
- [ボリュームのマウント] タブをクリックします。
- [ボリュームをマウント] をクリックします。
- メニューから Cloud Storage ボリュームを選択します。
- ボリュームをマウントするパスを指定します。
- [ボリュームをマウント] をクリックします。
- [ボリューム] で、次の操作を行います。
[作成] または [更新] をクリックします。
gcloud
ボリュームを追加してマウントするには:
gcloud run jobs update JOB \ --add-volume name=VOLUME_NAME,type=cloud-storage,bucket=BUCKET_NAME \ --add-volume-mount volume=VOLUME_NAME,mount-path=MOUNT_PATH
次のように置き換えます。
JOB: ジョブの名前。- MOUNT_PATH: ボリュームをマウントする相対パス(
/mnt/my-volumeなど)。 - VOLUME_NAME: ボリュームに付ける名前。VOLUME_NAME 値は、ボリュームをボリューム マウントにマッピングするために使用されます。
- BUCKET_NAME: Cloud Storage バケットの名前。
ボリュームを読み取り専用ボリュームとしてマウントするには:
--add-volume=name=VOLUME_NAME,type=cloud-storage,bucket=BUCKET_NAME,readonly=true
複数のコンテナを使用している場合は、まずボリュームを指定してから、各コンテナのボリューム マウントを指定します。
gcloud run jobs update JOB \ --add-volume name=VOLUME_NAME,type=cloud-storage,bucket=BUCKET_NAME \ --container CONTAINER_1 \ --add-volume-mount volume=VOLUME_NAME,mount-path=MOUNT_PATH \ --container CONTAINER_2 \ --add-volume-mount volume=VOLUME_NAME,mount-path=MOUNT_PATH2
YAML
新しいジョブを作成する場合は、この手順をスキップします。既存のジョブを更新する場合は、その YAML 構成をダウンロードします。
gcloud run jobs describe JOB_NAME --format export > job.yaml
必要に応じて、MOUNT_PATH、VOLUME_NAME、BUCKET_NAME、IS_READ_ONLY を更新します。
apiVersion: run.googleapis.com/v1 kind: Job metadata: name: JOB_NAME spec: template: metadata: annotations: run.googleapis.com/execution-environment: gen2 spec: template: spec: containers: - image: IMAGE_URL volumeMounts: - mountPath: MOUNT_PATH name: VOLUME_NAME volumes: - name: VOLUME_NAME csi: driver: gcsfuse.run.googleapis.com readOnly: IS_READ_ONLY volumeAttributes: bucketName: BUCKET_NAME
次のように置き換えます。
- IMAGE_URL: コンテナ イメージへの参照(
us-docker.pkg.dev/cloudrun/container/job:latestなど)。 - MOUNT_PATH: ボリュームをマウントする相対パス(
/mnt/my-volumeなど)。 - VOLUME_NAME: ボリュームに付ける名前。VOLUME_NAME 値は、ボリュームをボリューム マウントにマッピングするために使用されます。
- IS_READ_ONLY: ボリュームを読み取り専用にする場合は
True、書き込み可能にする場合はFalse。 - BUCKET_NAME: Cloud Storage バケットの名前。
- IMAGE_URL: コンテナ イメージへの参照(
次のコマンドを使用して、ジョブを作成または更新します。
gcloud run jobs replace job.yaml
Terraform
Terraform 構成を適用または削除する方法については、基本的な Terraform コマンドをご覧ください。
Terraform 構成のgoogle_cloud_run_v2_job リソースに次の内容を追加します。 resource "google_cloud_run_v2_job" "default" {
name = "JOB_NAME"
location = "REGION"
template {
template {
containers {
image = "IMAGE_URL"
volume_mounts {
name = "VOLUME_NAME"
mount_path = "MOUNT_PATH"
}
}
volumes {
name = "VOLUME_NAME"
gcs {
bucket = google_storage_bucket.default.name
read_only = IS_READ_ONLY
}
}
}
}
}
resource "google_storage_bucket" "default" {
name = "BUCKET_NAME"
location = "REGION"
}
次のように置き換えます。
- JOB_NAME: Cloud Run ジョブの名前。
- REGION: Google Cloud のリージョン。
- IMAGE_URL: コンテナ イメージへの参照(
us-docker.pkg.dev/cloudrun/container/job:latestなど)。 - VOLUME_NAME: ボリュームに付ける名前。VOLUME_NAME 値は、ボリュームをボリューム マウントにマッピングするために使用されます。
- MOUNT_PATH: ボリュームをマウントする相対パス(
/mnt/my-volumeなど)。 - IS_READ_ONLY: ボリュームを読み取り専用にする場合は
True、書き込み可能にする場合はFalse。 - BUCKET_NAME: Cloud Storage バケットの名前。
ボリュームの読み取りと書き込み
Cloud Run のボリューム マウント機能を使用する場合、ローカル ファイル システムでファイルの読み取りと書き込みに使用するプログラミング言語のライブラリを使用して、マウントされたボリュームにアクセスします。
これは、ローカル ファイル システムにデータが保存されることを想定し、通常のファイル システム オペレーションを使用してデータにアクセスする既存のコンテナを使用している場合に特に便利です。
次のスニペットは、mountPath が /mnt/my-volume に設定されたボリューム マウントを前提としています。
Node.js
ファイル システム モジュールを使用してボリューム /mnt/my-volume に新しいファイルを作成するか、既存のファイルに追加します。
var fs = require('fs');
fs.appendFileSync('/mnt/my-volume/sample-logfile.txt', 'Hello logs!', { flag: 'a+' });Python
ボリューム /mnt/my-volume に保存されているファイルに書き込みます。
f = open("/mnt/my-volume/sample-logfile.txt", "a")Go
os パッケージを使用して、ボリューム /mnt/my-volume に新しいファイルを作成します。
f, err := os.Create("/mnt/my-volume/sample-logfile.txt")Java
Java.io.File クラスを使用して、ボリューム /mnt/my-volume にログファイルを作成します。
import java.io.File;
File f = new File("/mnt/my-volume/sample-logfile.txt");マウント オプションを使用したボリュームの構成
必要に応じて、マウント オプションを使用して、ボリューム マウントのさまざまなプロパティを構成できます。使用可能なマウント オプションを使用すると、キャッシュ設定の構成、特定のディレクトリのマウント、デバッグ ロギングの有効化などの動作を実行できます。
マウント オプションを指定する
マウント オプションは、 Google Cloud コンソール、Google Cloud CLI、YAML、または Terraform を使用して指定できます。マウント オプションは、Google Cloud CLI ではセミコロン(;)で区切りますが、YAML ではカンマで区切ります。次のタブに例を示します。
コンソール
既存のボリュームのマウント オプションを指定するには:
Google Cloud コンソールで Cloud Run に移動します。
メニューから [ジョブ] を選択します。
ジョブをクリックし、[ジョブ構成を表示して編集] をクリックします。
[ボリューム] タブをクリックします。
- 編集するボリュームをクリックします。
- [マウント オプションを構成] をクリックします。
- 適切なフィールドを更新するか、マウント オプションを手動で追加して、マウント オプションを構成します。
- [保存] をクリックします。
このボリュームをコンテナにまだマウントしていない場合は、[コンテナ] タブをクリックします。
- [ボリュームのマウント] タブをクリックします。
- [ボリュームをマウント] をクリックします。
- メニューからストレージ ボリュームを選択します。
- ボリュームをマウントするパスを指定します。
[完了] をクリックします。
[デプロイ] をクリックします。
gcloud
マウント オプションでボリュームを追加してマウントするには:
gcloud run jobs update JOB \ --add-volume name=VOLUME_NAME,type=cloud-storage,bucket=BUCKET_NAME, mount-options="OPTION_1=VALUE_1;OPTION_N=VALUE_N" \ --add-volume-mount volume=VOLUME_NAME,mount-path=MOUNT_PATH
次のように置き換えます。
- JOB: ジョブの名前。
- MOUNT_PATH: ボリュームをマウントする相対パス(
/cacheなど)。 - VOLUME_NAME: ボリュームに付ける名前。VOLUME_NAME 値は、ボリュームをボリューム マウントにマッピングするために使用されます。
- BUCKET_NAME: Cloud Storage バケットの名前。
- OPTION_1: 最初のマウント オプション。マウント オプションは、必要に応じていくつでも指定できます。各マウント オプションと値のペアをセミコロンで区切ります。
- VALUE_1: 最初のマウント オプションに必要な設定。
- OPTION_N: 次のマウント オプション。
- VALUE_N: 次のマウント オプションの設定。
- BUCKET_NAME: Cloud Storage バケットの名前。
- MOUNT_PATH: ボリュームをマウントする相対パス(
/cacheなど)。
YAML
新しいジョブを作成する場合は、この手順をスキップします。既存のジョブを更新する場合は、その YAML 構成をダウンロードします。
gcloud run jobs describe JOB_NAME --format export > job.yaml
必要に応じて更新します。
apiVersion: run.googleapis.com/v1 kind: Job metadata: name: JOB_NAME spec: metadata: template: metadata: annotations: run.googleapis.com/execution-environment: gen2 spec: template: spec: containers: - image: IMAGE_URL volumeMounts: - mountPath: MOUNT_PATH name: VOLUME_NAME volumes: - name: VOLUME_NAME csi: driver: gcsfuse.run.googleapis.com readOnly: IS_READ_ONLY volumeAttributes: bucketName: BUCKET_NAME mountOptions: OPTION_1=VALUE_1,OPTION_N=VALUE_N
次のように置き換えます。
- IMAGE_URL: ワーカープールを含むコンテナ イメージへの参照(
us-docker.pkg.dev/cloudrun/container/worker-pool:latestなど) - MOUNT_PATH: ボリュームをマウントする相対パス(
/cacheなど)。 - VOLUME_NAME: ボリュームに付ける名前。VOLUME_NAME 値は、ボリュームをボリューム マウントにマッピングするために使用されます。
- IS_READ_ONLY: ボリュームを読み取り専用にする場合は
True、書き込み可能にする場合はFalse。 - BUCKET_NAME: Cloud Storage バケットの名前。
- OPTION_1: 最初のマウント オプション。マウント オプションは、必要に応じていくつでも指定できます。各マウント オプションと値のペアをカンマで区切ります。
- VALUE_1: 最初のマウント オプションに必要な設定。
- OPTION_N: 次のマウント オプション。
- VALUE_N: 次のマウント オプションの設定。
- IMAGE_URL: ワーカープールを含むコンテナ イメージへの参照(
次のコマンドを使用して、ジョブを作成または更新します。
gcloud run jobs replace job.yaml
Terraform
Terraform 構成を適用または削除する方法については、基本的な Terraform コマンドをご覧ください。
Terraform 構成のgoogle_cloud_run_v2_job リソースに次の内容を追加します。resource "google_cloud_run_v2_job" "default" {
provider = google-beta
name = "JOB_NAME"
location = "REGION"
template {
template {
containers {
image = "IMAGE_URL"
volume_mounts {
name = "VOLUME_NAME"
mount_path = "MOUNT_PATH"
}
}
volumes {
name = "VOLUME_NAME"
gcs {
bucket = google_storage_bucket.default.name
read_only = IS_READ_ONLY
mount_options = ["OPTION_1=VALUE_1", "OPTION_N=VALUE_N", "OPTION_O"]
}
}
}
}
}
次のように置き換えます。
- JOB_NAME: Cloud Run サービスの名前。
- REGION: Google Cloud のリージョン。
- IMAGE_URL: ワーカープールを含むコンテナ イメージへの参照(
us-docker.pkg.dev/cloudrun/container/worker-pool:latestなど) - VOLUME_NAME: ボリュームに付ける名前。VOLUME_NAME 値は、ボリュームをボリューム マウントにマッピングするために使用されます。
- MOUNT_PATH: ボリュームをマウントする相対パス(
/mnt/my-volumeなど)。 - IS_READ_ONLY: ボリュームを読み取り専用にする場合は
True、書き込み可能にする場合はFalse。 - BUCKET_NAME: Cloud Storage バケットの名前。
- OPTION_1: 最初のマウント オプション。マウント オプションは、必要に応じていくつでも指定できます。各マウント オプションと値のペアをカンマで区切ります。
- VALUE_1: 最初のマウント オプションに必要な設定。
- OPTION_N: 2 番目のマウント オプション(該当する場合)。
- VALUE_N: 2 番目のマウント オプションの設定。
- OPTION_O: 3 番目のマウント オプション(該当する場合)。一部のマウント オプションには値がありません。
よく使用されるマウント オプション
マウント オプションは通常、次の目的で使用されます。
- キャッシュ設定を構成する
- Cloud Storage バケットから特定のディレクトリのみをマウントする
- ボリュームの所有権を構成する(
uid、gid) - 暗黙的なディレクトリを無効にする
- デバッグ ロギング レベルを指定する
キャッシュ設定を構成する
キャッシュ保存関連のマウント オプションを設定することで、ボリュームのキャッシュ設定を変更できます。次のテーブルに、これらの設定と、デフォルトの Cloud Run 値を示します。
| キャッシュ設定 | 説明 | デフォルト |
|---|---|---|
metadata-cache-ttl-secs |
キャッシュに保存されたメタデータ エントリの有効期間(TTL)を秒単位で指定します例: metadata-cache-ttl-secs=120s。最新のファイルを使用するには、0 の値を指定します。キャッシュに保存されたバージョンを常に使用するには、値 -1 を指定します。詳細については、キャッシュの無効化の構成をご覧ください。 |
60 |
stat-cache-max-size-mb |
統計情報キャッシュで使用できる最大サイズ(MiB)。統計情報キャッシュは常にメモリ内に保持されるため、メモリ消費に影響します。ワークロードに最大 20,000 個のファイルが含まれる場合は、32 の値を指定します。ワークロードで 20,000 を超えるファイルを使用する場合は、6,000 ファイル追加するごとにサイズを 10 ずつ増やします。統計情報キャッシュはファイルあたり平均 1,500 MiB を使用します。統計情報キャッシュが必要なだけメモリを使用できるようにするには、値 -1 を指定します。統計情報キャッシュを無効にするには、値 0 を指定します。 |
32 |
type-cache-max-size-mb |
タイプ キャッシュが使用できるディレクトリあたりの最大サイズ(MiB 単位)。タイプ キャッシュは常にメモリ内に完全に保持されるため、メモリ消費に影響します。 マウントするバケットの 1 つのディレクトリ内にあるファイルの最大数が 20,000 以下の場合は、値 4 を指定します。マウントする 1 つのディレクトリ内のファイルの最大数が 20,000 を超える場合は、5,000 ファイルごとに値を 1 増やします(ファイルあたり平均約 200 バイト)。タイプ キャッシュが必要なだけメモリを使用できるようにするには、値 -1 を指定します。タイプ キャッシュを無効にするには、値 0 を指定します。 |
4 |
次の Google Cloud CLI コマンドは、metadata-cache-ttl-secs を 120 秒に設定し、統計情報とタイプ キャッシュ容量をそれぞれ 52 MiB と 7 MiB に増やします。
gcloud run jobs update JOB \ --add-volume name=VOLUME_NAME,type=cloud-storage,bucket=BUCKET_NAME,mount-options="metadata-cache-ttl-secs=120;stat-cache-max-size-mb=52;type-cache-max-size-mb=7" \ --add-volume-mount volume=VOLUME_NAME,mount-path=MOUNT_PATH
次のように置き換えます。
- JOB: ジョブの名前。
- VOLUME_NAME: ボリュームに付ける名前。VOLUME_NAME 値は、ボリュームをボリューム マウントにマッピングするために使用されます。
- BUCKET_NAME: Cloud Storage バケットの名前。
- MOUNT_PATH: ボリュームをマウントする相対パス(
/cacheなど)。
デバッグ ロギングを有効にする
デフォルトでは、Cloud Storage FUSE は重大度が Info 以上のイベントをログに記録します。ロギング設定は、次のいずれかのログ重大度レベルを使用して変更できます(低い順に表示しています)。
tracedebuginfowarningerror- すべてのロギングをオフにするには、値
offを指定します。
重大度レベルを指定すると、Cloud Storage FUSE は、指定された重大度レベル以上の重大度レベルのイベントのログを生成します。たとえば、warning レベルを指定すると、Cloud Storage FUSE は警告とエラーのログを生成します。
ロギングの重大度を info より高いレベルに設定すると、パフォーマンスに影響し、大量のロギングデータが生成される可能性があるため、必要な場合にのみ設定することをおすすめします。
次のコマンドラインを使用すると、デバッグ ロギングが有効になります。
gcloud run jobs update JOB \ --add-volume name=VOLUME_NAME,type=cloud-storage,bucket=BUCKET_NAME,mount-options="log-severity=debug" \ --add-volume-mount volume=VOLUME_NAME,mount-path=MOUNT_PATH
次のように置き換えます。
- JOB: ジョブの名前。
- VOLUME_NAME は、ボリュームに付ける名前に置き換えます。VOLUME_NAME 値は、ボリュームをボリューム マウントにマッピングするために使用されます。
- BUCKET_NAME は、Cloud Storage バケットの名前に置き換えます。
- MOUNT_PATH は、ボリュームをマウントする相対パス(
/cacheなど)に置き換えます。
暗黙的なディレクトリを無効にする
Cloud Storage を標準のファイル システムのように見せるため、Cloud Run では、Cloud Storage バケットのマウント時に暗黙のディレクトリがデフォルトで有効になります。暗黙的なディレクトリは、implicit-dirs マウント オプションを使用して無効にできます。暗黙的なディレクトリを無効にすると、パフォーマンスと費用を改善できますが、互換性が犠牲になります。
暗黙的なディレクトリ機能を使用すると、ファイル名がディレクトリ構造を模倣している既存の Cloud Storage ファイルを Cloud Run で認識できます(例: /mydir/myfile.txt)。暗黙的なディレクトリを無効にすると、Cloud Run はそのようなファイルを一覧表示または読み取ることができなくなります。
暗黙的なディレクトリをオフにすると、Cloud Storage へのリクエスト数が減り、アプリケーションのパフォーマンスと費用が改善される可能性があります。詳細については、Cloud Storage FUSE のファイルとディレクトリのドキュメントをご覧ください。
次のコマンドラインでは、暗黙的なディレクトリが無効になります。
gcloud run jobs update JOB \ --add-volume name=VOLUME_NAME,type=cloud-storage,bucket=BUCKET_NAME,mount-options="implicit-dirs=false" \ --add-volume-mount volume=VOLUME_NAME,mount-path=MOUNT_PATH
次のように置き換えます。
- JOB: ジョブの名前。
- VOLUME_NAME: ボリュームに付ける名前。VOLUME_NAME 値は、ボリュームをボリューム マウントにマッピングするために使用されます。
- BUCKET_NAME: Cloud Storage バケットの名前。
- MOUNT_PATH: ボリュームをマウントする相対パス(
/cacheなど)。
Cloud Storage バケット内の特定のディレクトリをマウントする
デフォルトでは、Cloud Run は Cloud Storage バケット全体をマウントします。これにより、Cloud Run ジョブはすべてのコンテンツにアクセスできます。特定のディレクトリのみをマウントすることが必要な場合があります。たとえば、バケットに大量のファイルが含まれている場合は、特定のディレクトリをマウントするとパフォーマンスが向上します。
分離目的で、異なるジョブがストレージ バケット内の異なるディレクトリにアクセスする必要がある場合にも、同じように実装できます。
次のコマンドラインでは、マウントするディレクトリを指定します。
gcloud run jobs update JOB \ --add-volume name=VOLUME_NAME,type=cloud-storage,bucket=BUCKET_NAME,mount-options="only-dir=images" \ --add-volume-mount volume=VOLUME_NAME,mount-path=MOUNT_PATH
次のように置き換えます。
- JOB: ジョブの名前。
- VOLUME_NAME: ボリュームに付ける名前。VOLUME_NAME 値は、ボリュームをボリューム マウントにマッピングするために使用されます。
- BUCKET_NAME: Cloud Storage バケットの名前。
- MOUNT_PATH: ボリュームをマウントする相対パス(
/cacheなど)。
ボリュームの UID と GID を設定する
uid マウント オプションと gid マウント オプションを使用して、ボリュームのユーザー ID とグループ ID を変更します。これは、実行中の 1 つ以上のコンテナの ID に一致する特定のユーザーまたはグループにファイルの所有権を設定する場合に便利です。デフォルトでは、ボリュームは root が所有します。
次のコマンドラインは、uid と gid を設定します。
gcloud run jobs update JOB \ --add-volume name=VOLUME_NAME,type=cloud-storage,bucket=BUCKET_NAME,mount-options="uid=UID;gid=GID" \ --add-volume-mount volume=VOLUME_NAME,mount-path=MOUNT_PATH
次のように置き換えます。
- JOB: ジョブの名前。
- VOLUME_NAME: ボリュームに付ける名前。VOLUME_NAME 値は、ボリュームをボリューム マウントにマッピングするために使用されます。
- BUCKET_NAME: Cloud Storage バケットの名前。
- MOUNT_PATH: ボリュームをマウントする相対パス(
/cacheなど)。
その他のマウント オプションを設定する
Cloud Run でサポートされているすべてのマウント オプションの一覧は次のとおりです。
ディレクトリ
implicit-dirsonly-dirrename-dir-limit
デバッグ
debug_fuse_errorsdebug_fusedebug_gcsdebug-invariantsdebug_mutex
キャッシュ
stat-cache-capacitystat-cache-ttltype-cache-ttlenable-nonexistent-type-cache
権限
uidgidfile-modedir-mode
その他
billing-projectclient-protocolexperimental-enable-json-readexperimental-opentelemetry-collector-addresshttp-client-timeoutlimit-bytes-per-seclimit-ops-per-secmax-conns-per-hostmax-idle-conns-per-hostmax-retry-sleep-oretry-multipliersequential-read-size-mbstackdriver-export-interval
サポートされているマウント オプションの詳細については、Cloud Storage FUSE コマンドラインのマウント オプションをご覧ください。
ボリューム マウント設定を表示する
現在のボリューム マウントの設定は、 Google Cloud コンソールまたは Google Cloud CLI を使用して表示できます。
コンソール
Google Cloud コンソールで、Cloud Run の [ジョブ] ページに移動します。
目的のジョブをクリックして、[ジョブの詳細] ページを開きます。
[ボリューム] タブをクリックします。
ボリュームの詳細ページでボリューム マウント設定を見つけます。
gcloud
次のコマンドを使用します。
gcloud run jobs describe JOB_NAME
返された構成で、ボリューム マウント設定を見つけます。
Cloud Storage FUSE ネットワーク帯域幅のパフォーマンスの最適化
読み取りと書き込みのパフォーマンスを向上させるには、ダイレクト VPC を使用して Cloud Run ジョブを VPC ネットワークに接続し、すべてのアウトバウンド トラフィックを VPC ネットワーク経由でルーティングします。これは、次のいずれかの方法で行うことができます。
- プライベート Google アクセスを有効にし、
vpc-egressパラメータをall-trafficに設定します。 - ネットワーキングのベスト プラクティス ページの Google API への内部トラフィックで説明されているオプションのいずれかを使用します。
コンテナの起動時間と Cloud Storage FUSE のマウント
Cloud Storage FUSE を使用すると、Cloud Run はコンテナの起動前にボリューム マウントを開始するため、Cloud Run コンテナのコールド スタート時間がわずかに長くなる可能性があります。コンテナは、Cloud Storage FUSE が正常にマウントされた場合にのみ起動します。
Cloud Storage FUSE は、Cloud Storage への接続を確立した後にのみ、ボリュームを正常にマウントします。ネットワークの遅延は、コンテナの起動時間に影響する可能性があります。同様に、接続の試行が失敗すると、Cloud Storage FUSE はマウントされず、Cloud Run ジョブは起動しません。また、Cloud Run のすべてのマウント処理の合計タイムアウトが 30 秒であるため、Cloud Storage FUSE のマウントに 30 秒以上かかると、Cloud Run ジョブの開始に失敗します。
Cloud Storage FUSE のパフォーマンス特性
それぞれが異なるバケットを指す 2 つのボリュームを定義すると、2 つの Cloud Storage FUSE プロセスが開始されます。マウント処理とプロセスは並行して行われます。
Cloud Storage FUSE は Cloud Storage API を使用して Cloud Storage と通信するため、Cloud Storage FUSE を使用するオペレーションはネットワーク帯域幅の影響を受けます。ネットワーク帯域幅が少ない場合、バケットのコンテンツのリストの取得など、オペレーションが遅くなることがあります。同様に、サイズの大きなファイルの読み取りには時間がかかります。これは、ネットワーク帯域幅によって制限されるためです。
バケットに書き込むと、Cloud Storage FUSE はオブジェクトをメモリに完全にステージングします。つまり、大きなファイルの書き込みは、コンテナ インスタンスで使用可能なメモリ量によって制限されます(コンテナのメモリの最大上限は 32 GiB です)。
書き込みは、close または fsync を実行した場合にのみバケットにフラッシュされます。その後、完全なオブジェクトがバケットにアップロードまたは再アップロードされます。オブジェクトがバケットに完全に再アップロードされる唯一の例外は、ファイルが 2 MiB 以上で、コンテンツが追加されている場合です。
詳しくは、次のリソースをご覧ください。
ボリュームとボリューム マウントを消去して削除する
すべてのボリュームとマウントを消去できます。または、個々のボリュームとボリューム マウントを削除することもできます。
すべてのボリュームとボリューム マウントを消去する
単一コンテナのジョブからすべてのボリュームとボリューム マウントを消去するには、次のコマンドを実行します。
gcloud run jobs update JOB \ --clear-volumes --clear-volume-mounts
複数のコンテナがある場合は、サイドカー CLI 規則に沿ってボリュームとボリューム マウントを消去します。
gcloud run jobs update JOB \ --clear-volumes \ --clear-volume-mounts \ --container=container1 \ --clear-volumes \ -–clear-volume-mounts \ --container=container2 \ --clear-volumes \ -–clear-volume-mounts
個々のボリュームとボリューム マウントを削除する
ボリュームを削除するには、そのボリュームを使用するすべてのボリューム マウントも削除する必要があります。
個々のボリュームまたはボリューム マウントを削除するには、remove-volume フラグと remove-volume-mount フラグを使用します。
gcloud run jobs update JOB \ --remove-volume VOLUME_NAME --container=container1 \ --remove-volume-mount MOUNT_PATH \ --container=container2 \ --remove-volume-mount MOUNT_PATH