Dataflow raccoglie metriche per i tuoi job, che possono aiutarti a eseguire il debug degli errori, risolvere i problemi di prestazioni o ottimizzare la pipeline. L'interfaccia di monitoraggio di Dataflow mostra le visualizzazioni di queste metriche. Puoi anche utilizzare Cloud Monitoring per creare avvisi o query di Metrics Explorer.
Accedere alle metriche del job
Per visualizzare le metriche del job per un job:
Nella console Google Cloud , vai alla pagina Dataflow > Job.
Seleziona un lavoro.
Fai clic sulla scheda Metriche dei job.
Seleziona una metrica da visualizzare.
Per accedere a ulteriori informazioni nei grafici delle metriche del job, fai clic su Esplora dati.
Ogni metrica è organizzata nei seguenti dashboard:
- Metriche di scalabilità automatica
- Metriche di panoramica
- Metriche di streaming
- Metriche delle risorse
- Metriche di input/output
Supporto e limitazioni
Quando utilizzi le metriche Dataflow, tieni presente i seguenti dettagli.
A volte i dati dei job non sono disponibili in modo intermittente. Quando mancano dati, nei grafici di monitoraggio dei job vengono visualizzati dei vuoti.
Alcuni di questi grafici sono specifici per le pipeline di streaming.
Per scrivere dati delle metriche, un service account gestito dall'utente deve disporre dell'autorizzazione API IAM
monitoring.timeSeries.create. Questa autorizzazione è inclusa nel ruolo Dataflow Worker.Il servizio Dataflow segnala il tempo CPU riservato al termine dei job. Per i job senza limiti (streaming), il tempo CPU riservato viene segnalato solo dopo l'annullamento o l'esito negativo dei job. Pertanto, le metriche dei job non includono il tempo CPU riservato per i job di streaming.
Metriche di scalabilità automatica
La scalabilità automatica orizzontale consente a Dataflow di scegliere il numero appropriato di istanze worker per il tuo job, aggiungendo o rimuovendo i worker in base alle esigenze.
La sezione Scalabilità automatica della scheda Metriche job mostra il numero di worker e il numero target di worker nel tempo. Se il job utilizza Streaming Engine, vengono visualizzati anche il numero minimo e massimo di worker.
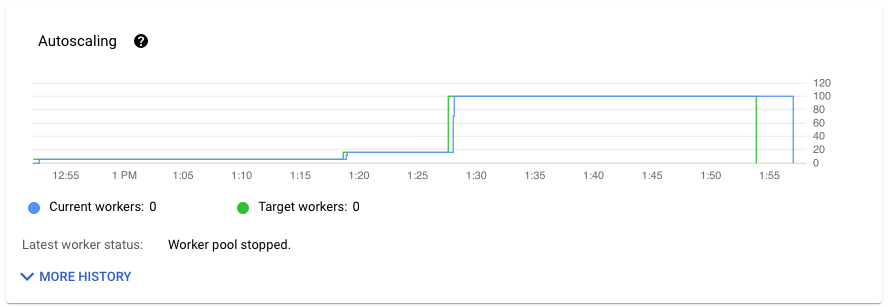
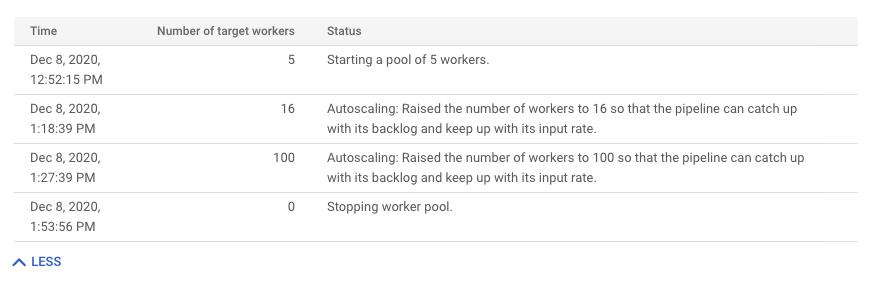
Per visualizzare la cronologia delle modifiche alla scalabilità automatica, fai clic su Altra cronologia. Viene visualizzata una tabella con informazioni sulla cronologia dei worker del job.
Per visualizzare ulteriori informazioni sulla scalabilità automatica per i job di streaming, fai clic sulla scheda Scalabilità automatica. Per saperne di più, vedi Monitorare la scalabilità automatica di Dataflow.
Metriche della panoramica
Le seguenti metriche vengono visualizzate nella sezione Metriche di panoramica.
Aggiornamento dei dati
Questa metrica si applica solo ai job di streaming.
L'aggiornamento dei dati è la differenza tra il momento in cui un elemento di dati viene elaborato (tempo di elaborazione) e il timestamp dell'elemento di dati (ora dell'evento). Valori più elevati indicano un ritardo maggiore tra l'ora dell'evento e l'ora di elaborazione.
Il grafico dell'aggiornamento dei dati mostra il valore massimo di aggiornamento dei dati in un determinato momento. Dataflow elabora più elementi in parallelo, quindi il grafico riflette l'elemento con il ritardo maggiore rispetto all'ora dell'evento.
Se alcuni dati di input non sono ancora stati elaborati, il watermark di output potrebbe essere in ritardo, il che influisce sulla freschezza dei dati. Una differenza significativa tra l'ora della filigrana e l'ora dell'evento potrebbe indicare un'operazione lenta o bloccata. Per saperne di più, consulta Filigrane e dati in ritardo nella documentazione di Apache Beam.
La dashboard include i seguenti due grafici:
- Aggiornamento dei dati per fase
- Aggiornamento dei dati
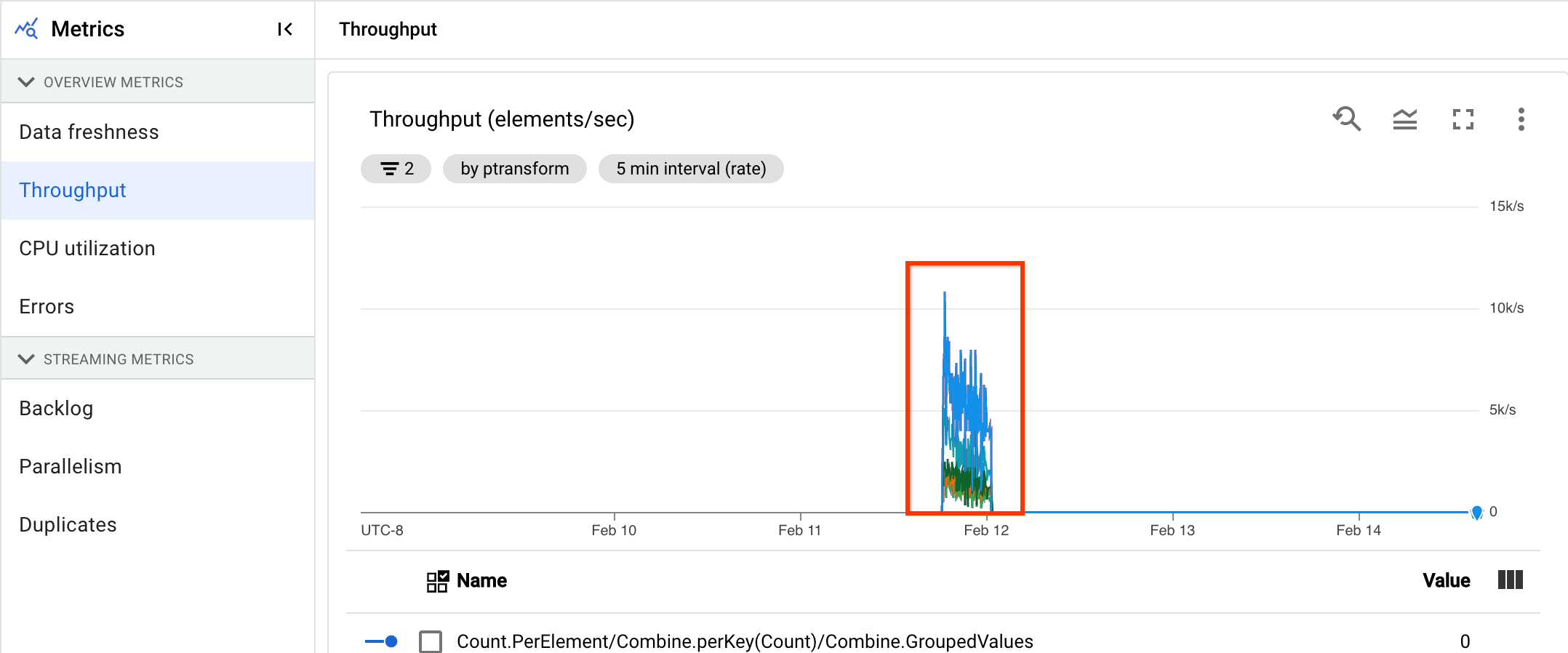
Nell'immagine seguente, l'area evidenziata mostra una grande differenza tra l'ora dell'evento e l'ora della filigrana di output, il che indica un'operazione lenta.
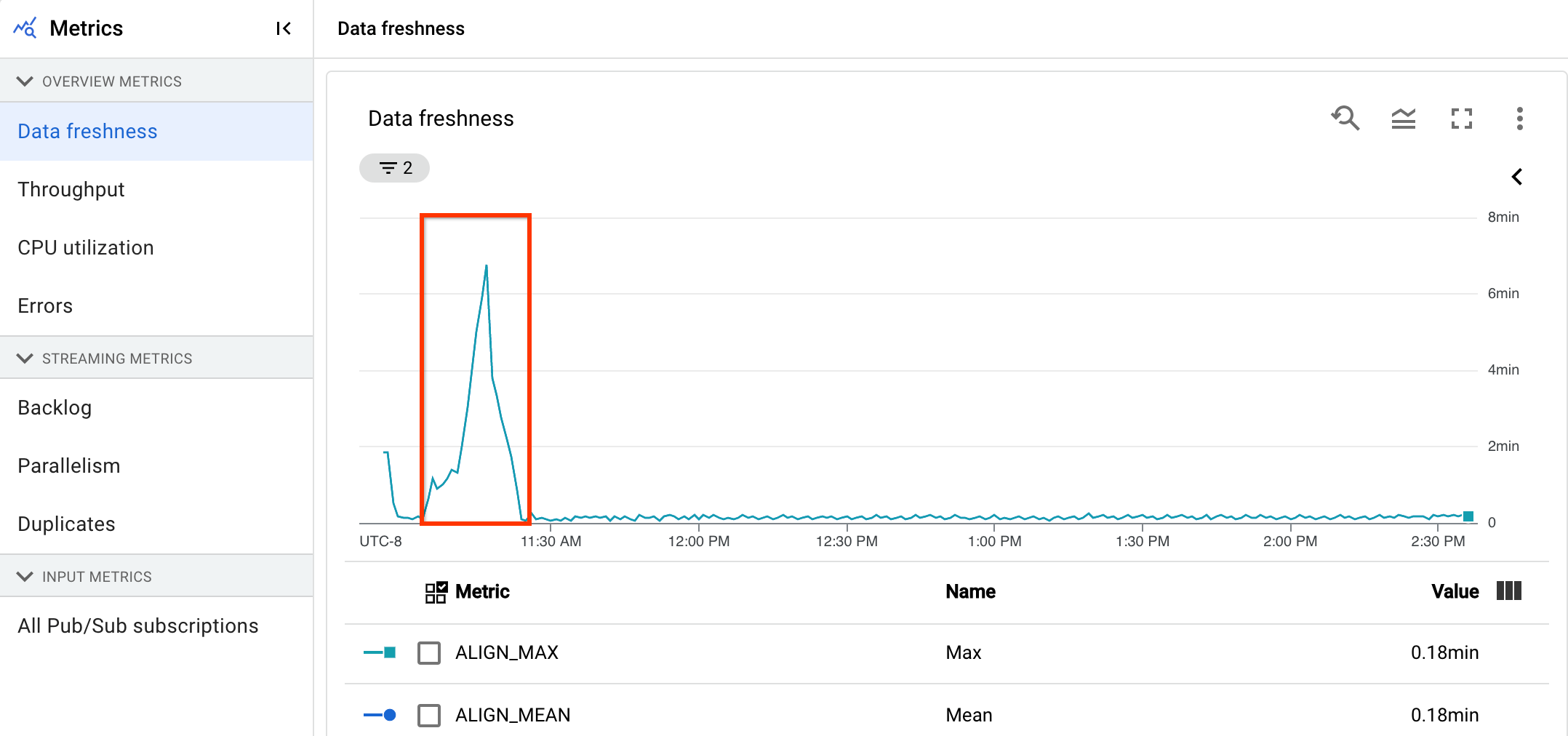
I seguenti problemi potrebbero causare valori elevati per questa metrica:
- Colli di bottiglia delle prestazioni: se la pipeline ha fasi con latenza di sistema elevata o log che indicano trasformazioni bloccate, la pipeline potrebbe presentare problemi di prestazioni che potrebbero aumentare la freschezza dei dati. Per ulteriori indagini, vedi Risolvere i problemi relativi ai job lenti o bloccati.
- Colli di bottiglia dell'origine dati: se le origini dati hanno backlog in crescita, i
timestamp degli eventi dei tuoi elementi potrebbero divergere dal watermark in attesa di essere
elaborati. I backlog di grandi dimensioni sono spesso causati da colli di bottiglia delle prestazioni
o da problemi con le origini dati, che vengono rilevati meglio monitorando le origini utilizzate
dalla pipeline.
- Le origini non ordinate come Pub/Sub possono produrre watermark bloccate anche durante l'output a una velocità elevata. Questa situazione si verifica perché gli elementi non vengono restituiti in ordine di timestamp e la filigrana si basa sul timestamp minimo non elaborato.
- Riprova frequente: se visualizzi errori che indicano che l'elaborazione degli elementi non è riuscita e che è stato eseguito un nuovo tentativo, i timestamp precedenti degli elementi riprovati potrebbero aumentare la freschezza dei dati. L'elenco degli errori comuni di Dataflow può aiutarti a risolvere i problemi.
Per i job di streaming aggiornati di recente, le informazioni sullo stato del job e la filigrana potrebbero non essere disponibili. L'operazione di aggiornamento apporta diverse modifiche che richiedono alcuni minuti per essere propagate all'interfaccia di monitoraggio di Dataflow. Prova ad aggiornare l'interfaccia di monitoraggio cinque minuti dopo aver aggiornato il job.
Latenza di sistema
Questa metrica si applica solo ai job di streaming.
La latenza di sistema è il numero massimo attuale di secondi in cui un elemento di dati è stato elaborato o è in attesa di elaborazione. La metrica include il tempo di attesa degli elementi all'interno di un'origine. Ad esempio, se una destinazione di output smette di accettare richieste di scrittura per un periodo di tempo, i dati potrebbero accumularsi nell'origine, causando un aumento della latenza del sistema. Se le operazioni di scrittura riprendono e la pipeline è in grado di recuperare, la latenza del sistema torna al livello di base.
I seguenti casi sono considerazioni aggiuntive:
- Per più origini e sink, la latenza del sistema è la quantità massima di tempo in cui un elemento attende all'interno di un'origine prima di essere scritto in tutti i sink.
- A volte, un'origine non fornisce un valore per il periodo di tempo per il quale un elemento attende all'interno dell'origine. Inoltre, l'elemento potrebbe non avere metadati per definire l'ora dell'evento. In questo scenario, la latenza del sistema viene calcolata a partire dal momento in cui la pipeline riceve l'elemento per la prima volta.
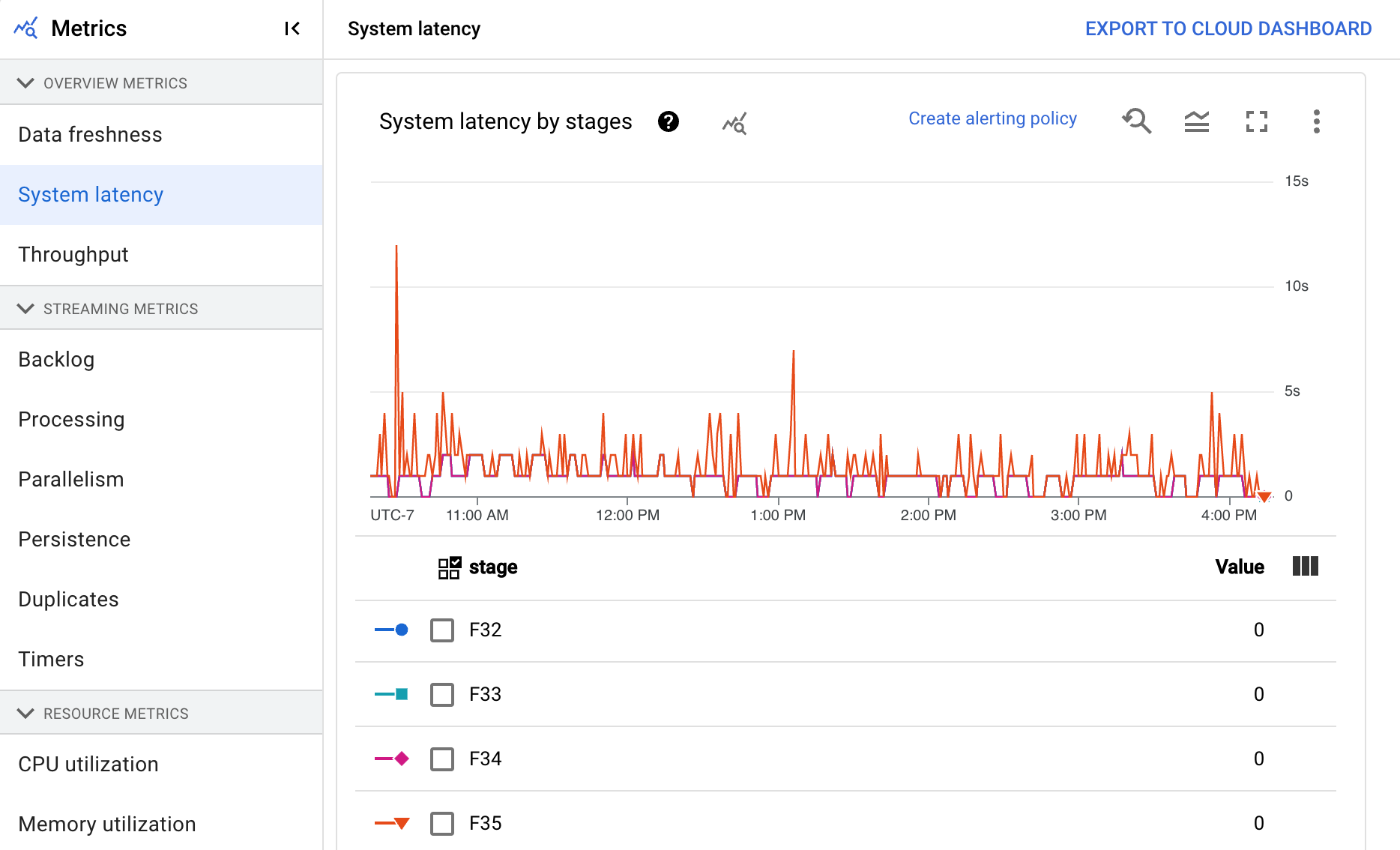
La dashboard include i seguenti due grafici:
- Latenza di sistema per fase
- Latenza di sistema
Velocità effettiva
La velocità effettiva è il volume di dati elaborati in un determinato momento. La dashboard include i seguenti grafici:
- Throughput per passaggio in elementi al secondo
- Throughput per passaggio in byte al secondo
Conteggio log errori del worker
Il Conteggio log errori del worker mostra il tasso di errori osservato in tutti i worker in un momento qualsiasi.

Metriche dei flussi di dati
Le seguenti metriche vengono visualizzate nella sezione Metriche di streaming.
Backlog
Questa metrica si applica solo ai job di streaming.
La dashboard Backlog fornisce informazioni sugli elementi in attesa di elaborazione. La dashboard include i seguenti due grafici:
- Secondi di backlog (solo Streaming Engine)
- Byte di backlog (con e senza Streaming Engine)
Il grafico Secondi di backlog mostra una stima della quantità di tempo in secondi necessaria per smaltire il backlog attuale se non arrivano nuovi dati e la velocità effettiva non cambia. Il tempo stimato di backlog viene calcolato in base alla velocità effettiva e ai byte di backlog dell'origine di input che devono ancora essere elaborati. Questa metrica viene utilizzata dalla funzionalità di scalabilità automatica dello streaming per determinare quando aumentare o diminuire lo scale.
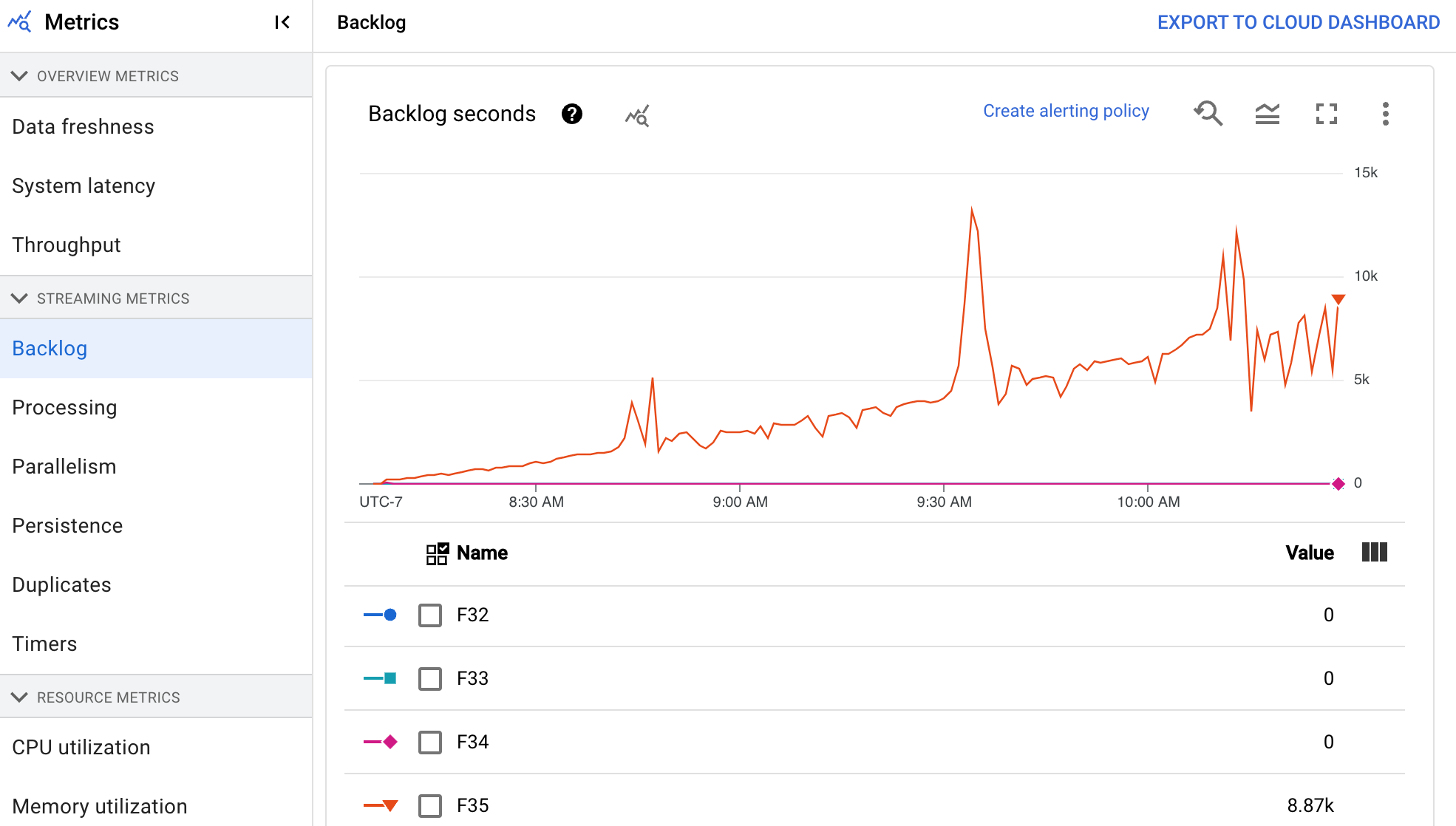
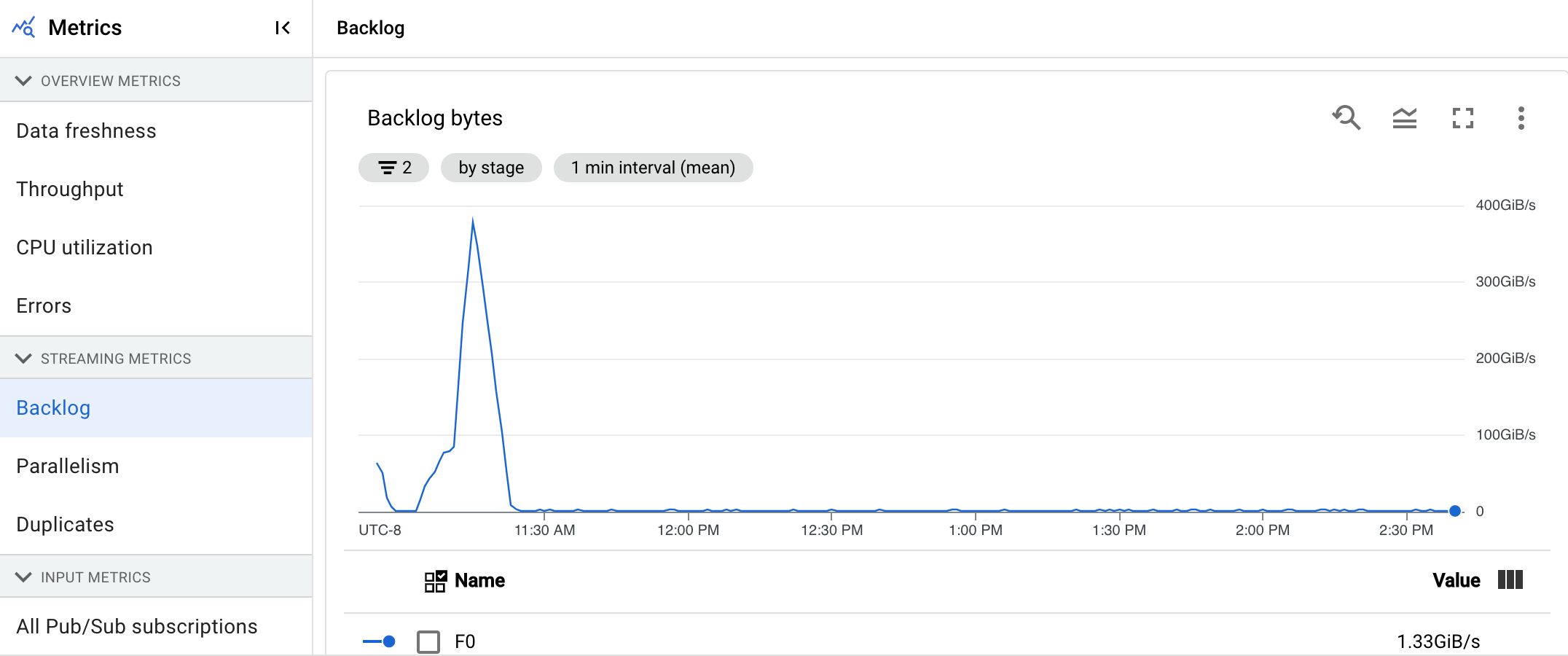
Il grafico Byte backlog mostra la quantità di input non elaborato noto per una fase in byte. Questa metrica confronta i byte rimanenti da consumare in ogni fase con le fasi upstream. Affinché questa metrica venga segnalata con precisione, ogni origine inserita nella pipeline deve essere configurata correttamente. Le origini integrate come Pub/Sub e BigQuery sono già supportate immediatamente, ma le origini personalizzate richiedono un'implementazione aggiuntiva. Per maggiori dettagli, consulta Scalabilità automatica per origini personalizzate senza limiti.
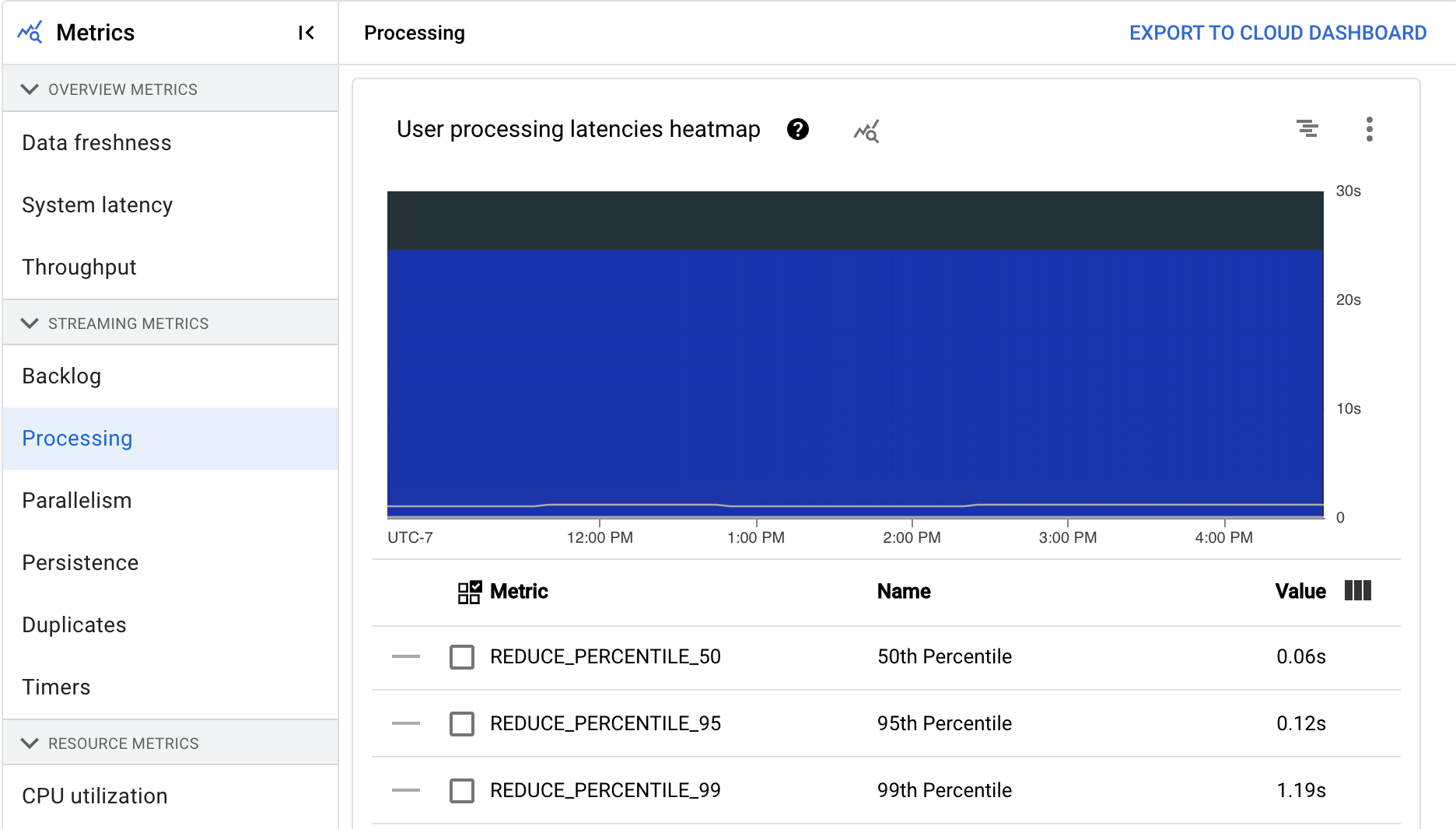
Elaborazione
Questa metrica si applica solo ai job di streaming.
Quando esegui una pipeline Apache Beam sul servizio Dataflow, le attività della pipeline vengono eseguite sulle VM worker. La dashboard Elaborazione fornisce informazioni sulla quantità di tempo in cui le attività sono state elaborate sulle VM worker. La dashboard include i seguenti due grafici:
- Mappa termica delle latenze di elaborazione utente
- Latenze di elaborazione utente per fase
La mappa termica delle latenze di elaborazione utente mostra le latenze massime delle operazioni per le distribuzioni del 50°, 95° e 99° percentile. Utilizza la mappa termica per verificare se le operazioni a coda lunga causano una latenza complessiva elevata del sistema o influiscono negativamente sull'aggiornamento complessivo dei dati.
Per risolvere un problema upstream prima che diventi un problema downstream, imposta un criterio di avviso per latenze elevate nel 50° percentile.
Il grafico Latenze di elaborazione utente per fase mostra il 99° percentile di tutte le attività elaborate dai worker suddivise per fase. Se il codice utente causa un collo di bottiglia, questo grafico mostra in quale fase si verifica. Per eseguire il debug della pipeline, segui questi passaggi:
Utilizza il grafico per trovare una fase con una latenza insolitamente elevata.
Nella pagina dei dettagli del job, nella scheda Dettagli di esecuzione, seleziona Workflow di fase per Visualizzazione grafico. Nel grafico Flusso di lavoro della fase, individua la fase con una latenza insolitamente elevata.
Per trovare le operazioni utente associate, fai clic sul nodo della fase nel grafico.
Per trovare ulteriori dettagli, vai a Cloud Profiler e utilizza Cloud Profiler per eseguire il debug dello analisi dello stack nell'intervallo di tempo corretto. Cerca le operazioni utente che hai identificato nel passaggio precedente.
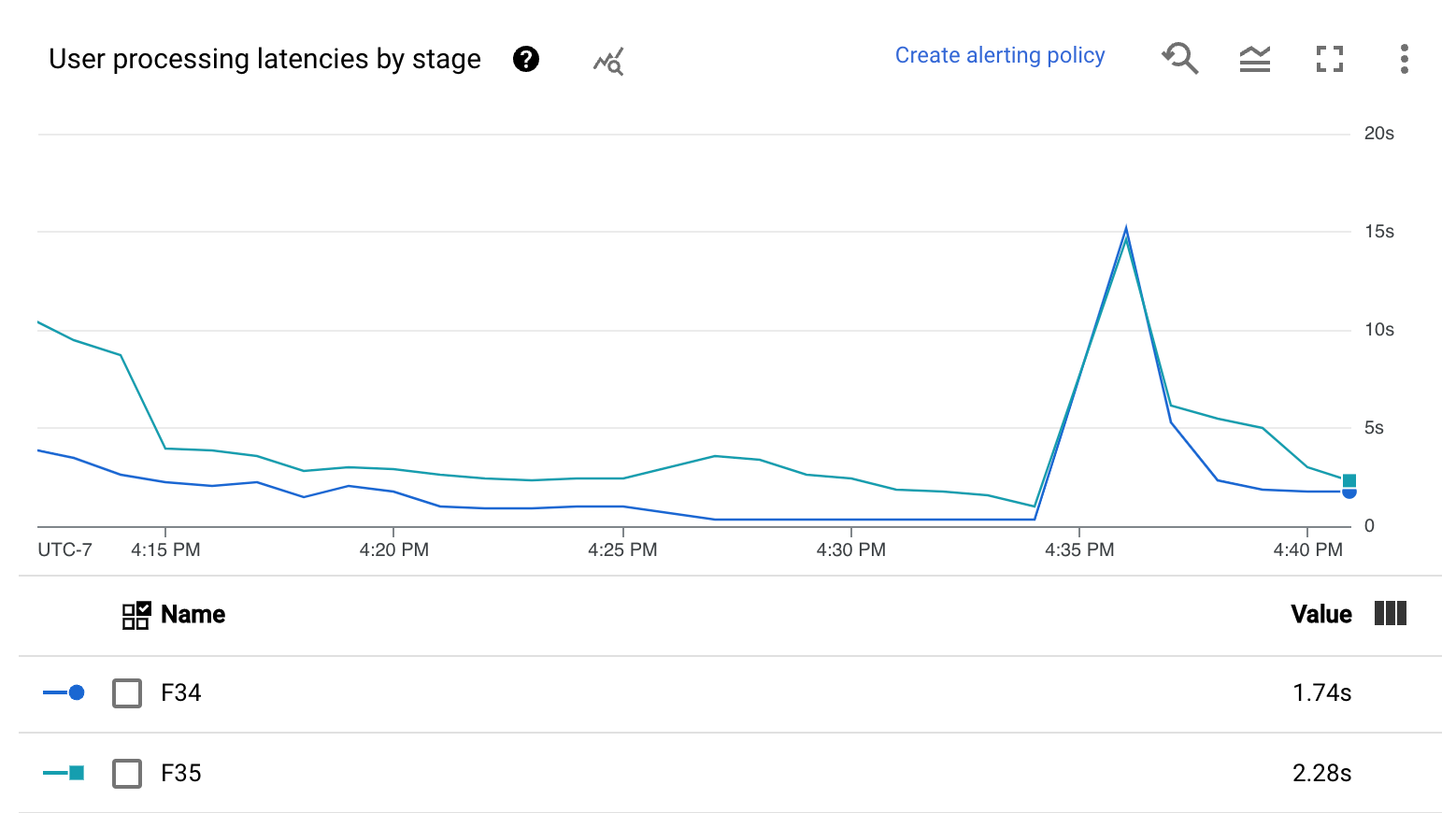
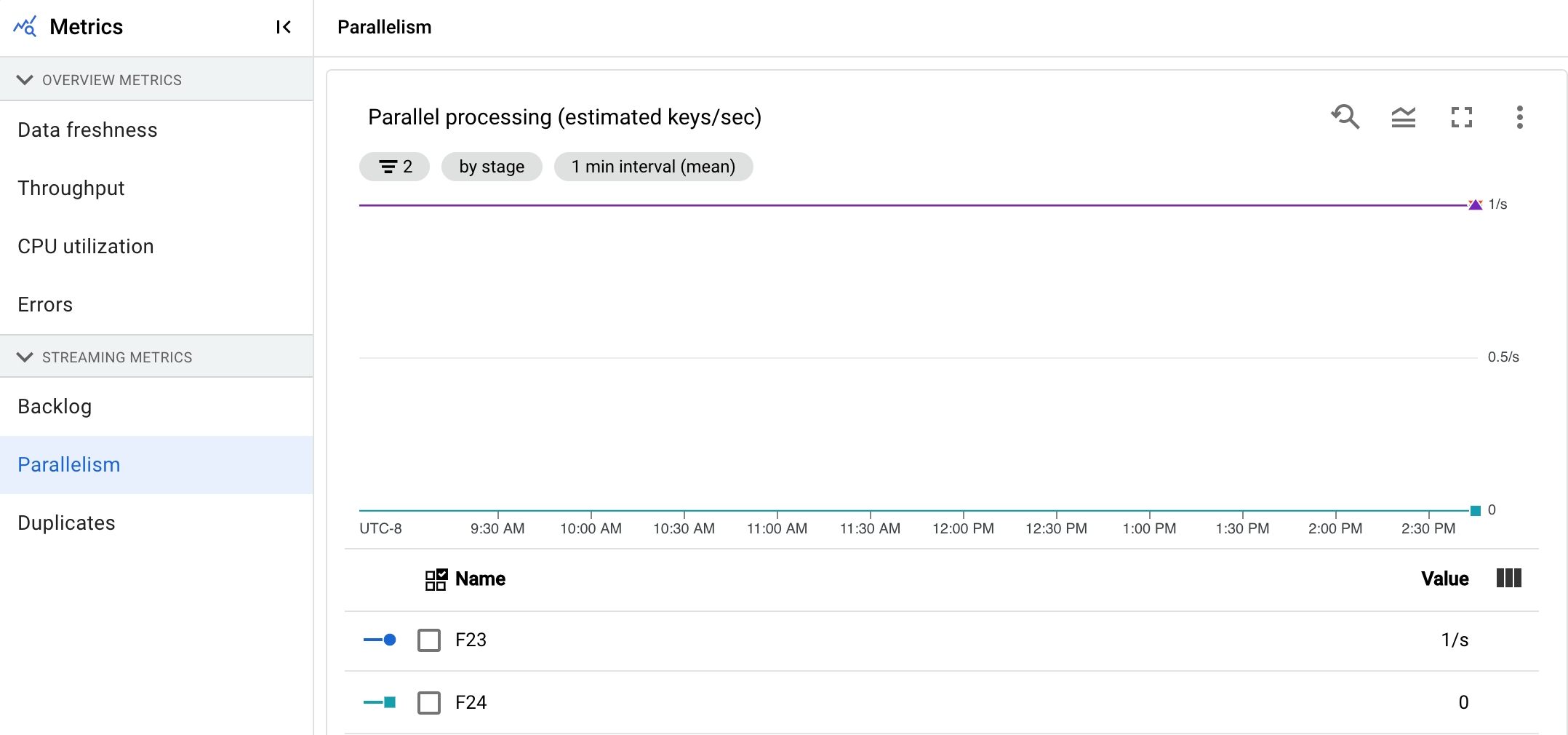
Parallelismo
Questa metrica si applica solo ai job di Streaming Engine.
Il grafico Elaborazione parallela mostra il numero approssimativo di chiavi in uso per l'elaborazione dei dati per ogni fase. Dataflow esegue lo scaling in base al parallelismo di una pipeline.
Quando Dataflow esegue una pipeline, l'elaborazione viene distribuita su più macchine virtuali (VM) Compute Engine, note anche come worker. Il servizio Dataflow parallelizza e distribuisce automaticamente la logica di elaborazione nella pipeline ai worker. L'elaborazione per una determinata chiave viene serializzata, quindi il numero totale di chiavi per una fase rappresenta il parallelismo massimo disponibile in quella fase.
Le metriche di parallelismo possono essere utili per trovare tasti di scelta rapida o colli di bottiglia per pipeline lente o bloccate.
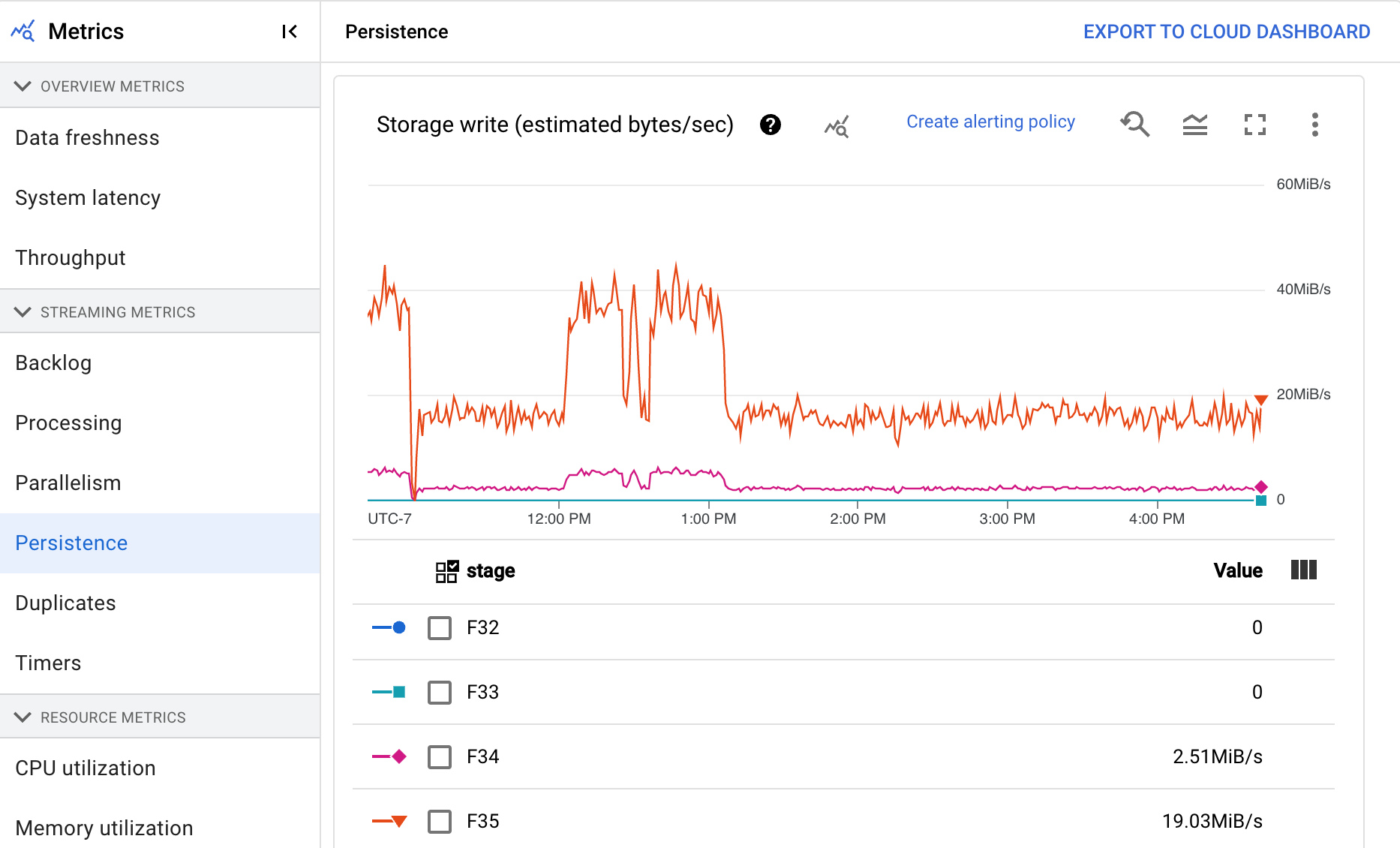
Persistenza
Questa metrica si applica solo ai job di streaming.
Il dashboard Persistenza fornisce informazioni sulla velocità di scrittura e lettura dello spazio di archiviazione permanente in una determinata fase della pipeline in byte al secondo. I byte letti e scritti includono le operazioni sullo stato dell'utente e lo stato per shuffling persistenti, rimozione dei duplicati, input secondari e monitoraggio dei watermark. I codificatori e la memorizzazione nella cache delle pipeline influiscono sui byte letti e scritti. I byte di archiviazione potrebbero differire dai byte elaborati a causa dell'utilizzo dell'archiviazione interna e della memorizzazione nella cache.
La dashboard include i seguenti due grafici:
- Scrittura nello spazio di archiviazione
- Lettura dello spazio di archiviazione
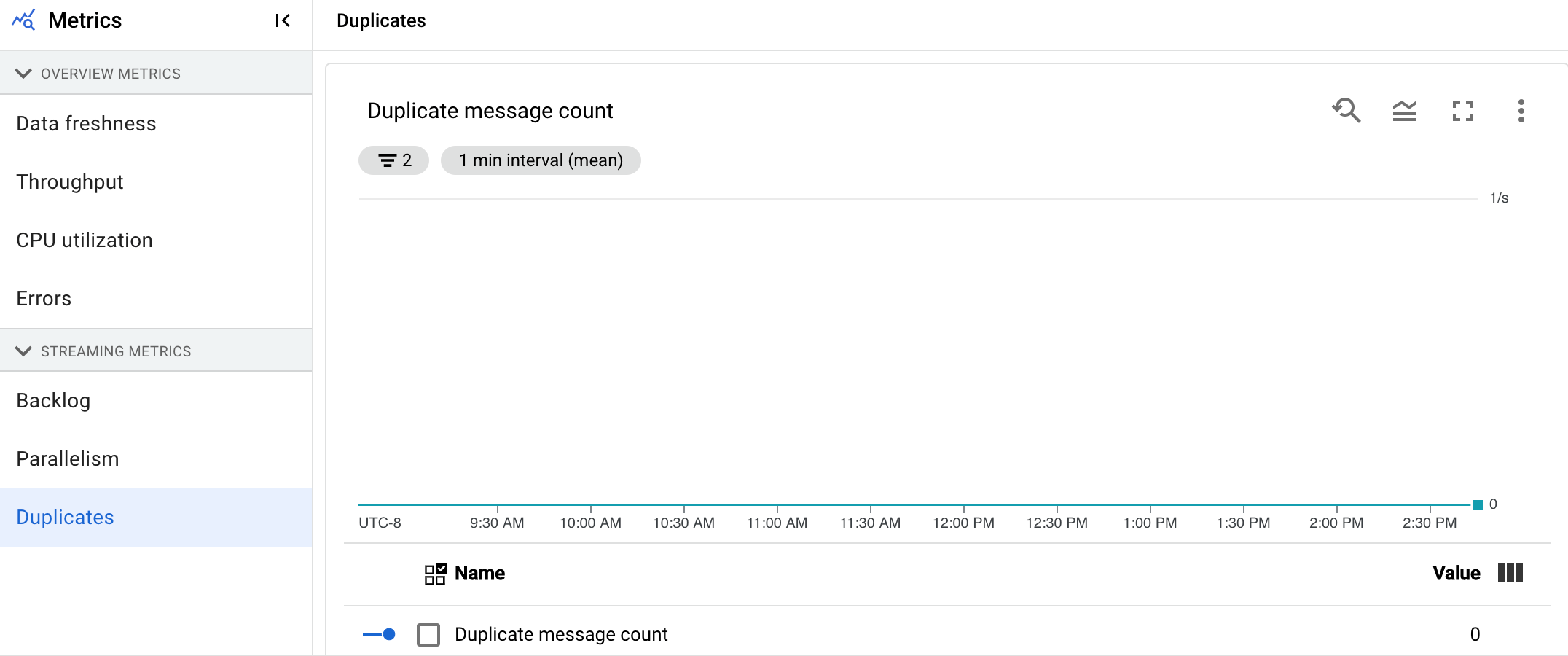
Duplicati
Questa metrica si applica solo ai job di streaming.
Il grafico Duplicati mostra il numero di messaggi elaborati da una determinata fase che sono stati filtrati come duplicati.
Dataflow supporta molte origini e destinazioni che garantiscono la distribuzione at least once. Lo svantaggio della pubblicazione at least once è che può comportare duplicati.
Dataflow garantisce la pubblicazione exactly once, il che significa che i duplicati vengono filtrati automaticamente.
Le fasi downstream vengono salvate dal rielaborazione degli stessi elementi, il che garantisce che lo stato e gli output non vengano interessati.
La pipeline può essere ottimizzata per risorse e rendimento riducendo il numero di duplicati prodotti in ogni fase.
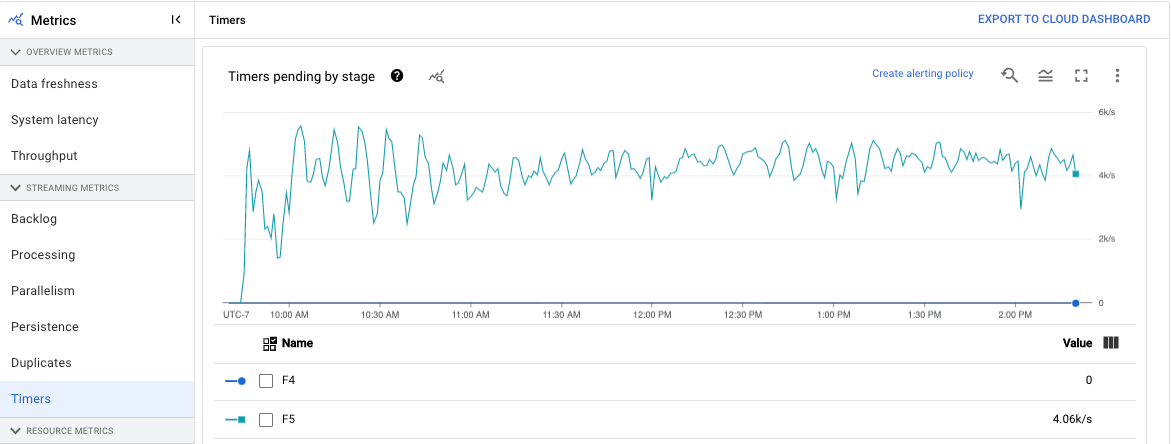
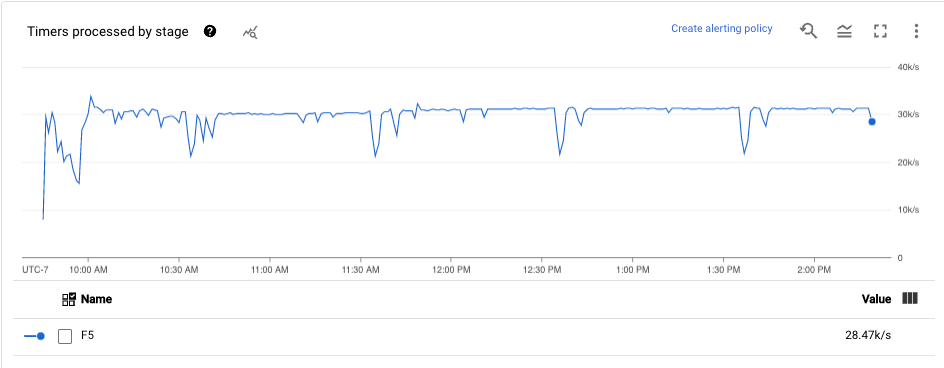
Timer
Questa metrica si applica solo ai job di streaming.
La dashboard Timer fornisce informazioni sul numero di timer in attesa e sul numero di timer già elaborati in una determinata fase della pipeline. Poiché le finestre si basano sui timer, questa metrica ti consente di monitorare l'avanzamento delle finestre.
La dashboard include i seguenti due grafici:
- Timer in attesa per fase
- Elaborazione dei timer per fase
Questi grafici mostrano la velocità con cui le finestre sono in attesa o in elaborazione in un momento specifico. Il grafico Timer in attesa per fase indica il numero di finestre in ritardo a causa di colli di bottiglia. Il grafico Elaborazione dei timer per fase indica quante finestre raccolgono elementi.
Questi grafici mostrano tutti i timer dei job, quindi se i timer vengono utilizzati altrove nel codice, vengono visualizzati anche in questi grafici.
Metriche risorsa
Le seguenti metriche vengono visualizzate nella sezione Metriche delle risorse.
Utilizzo CPU
L'utilizzo della CPU è la quantità di CPU utilizzata divisa per la quantità di CPU disponibile per l'elaborazione. Questa metrica per lavoratore viene visualizzata come percentuale. La dashboard include i seguenti quattro grafici:
- Utilizzo CPU (tutti i worker)
- Utilizzo della CPU (statistiche)
- Utilizzo CPU (primi 4)
- Utilizzo CPU (ultimi 4)
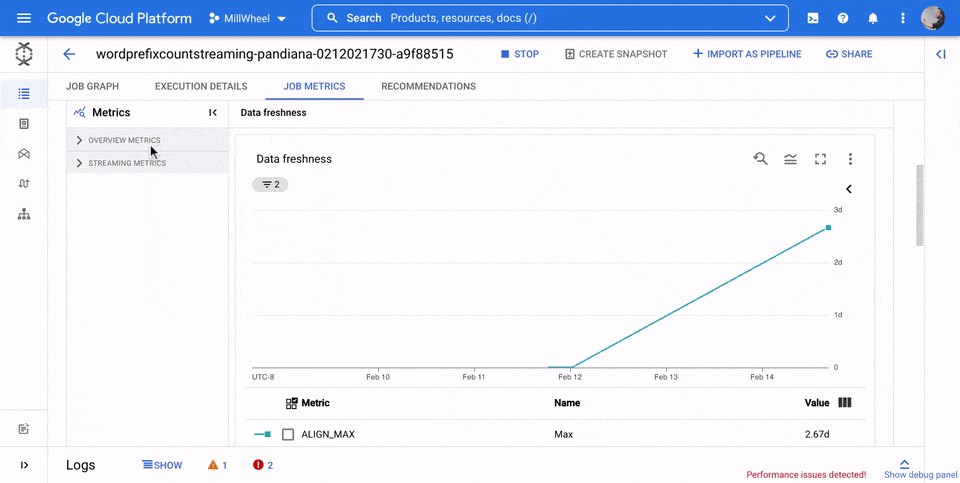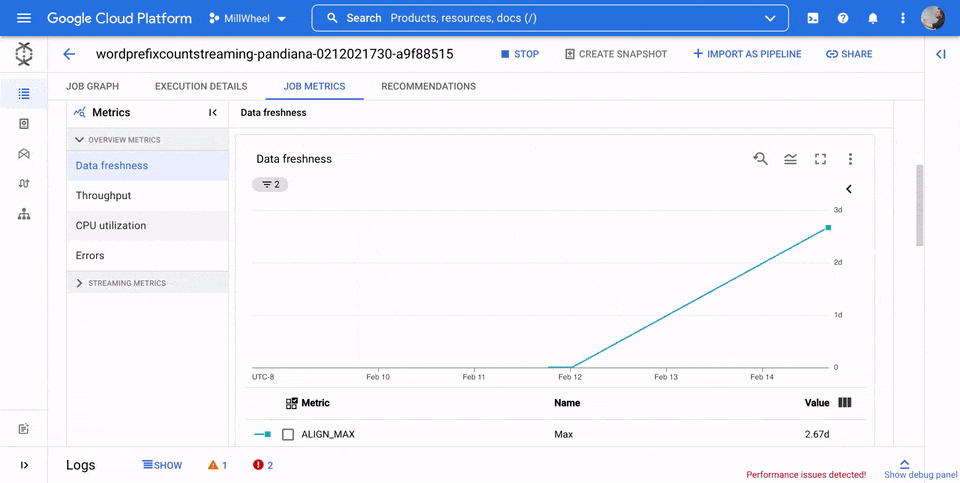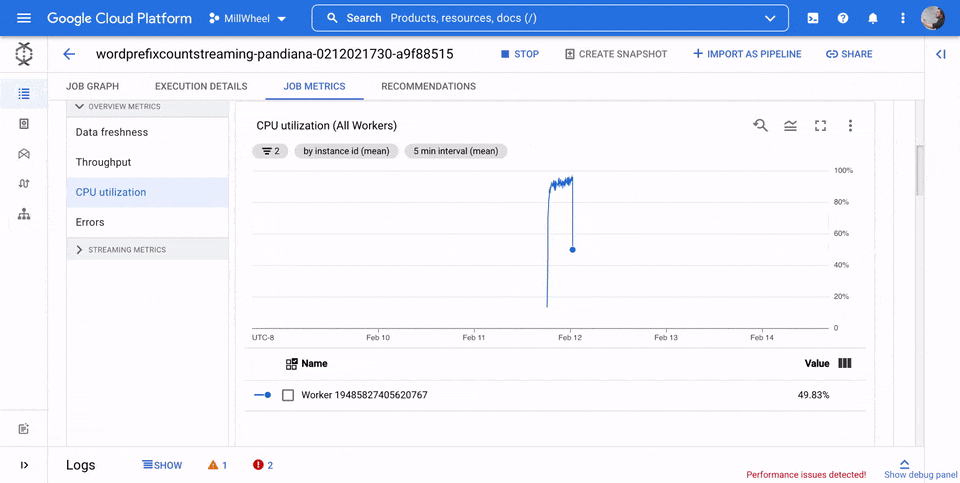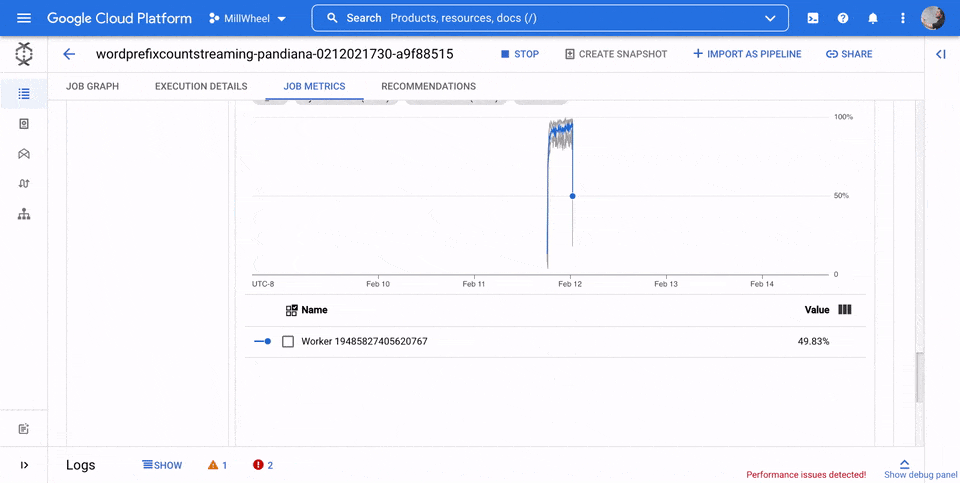
Utilizzo memoria
L'utilizzo della memoria è la quantità stimata di memoria utilizzata dai worker in byte al secondo. La dashboard include i seguenti due grafici:
- Utilizzo massimo della memoria da parte del worker (byte al secondo stimati)
- Utilizzo della memoria (byte al secondo stimati)
Il grafico Utilizzo massimo della memoria del worker fornisce informazioni sui worker che utilizzano la maggior parte della memoria nel job Dataflow in ogni momento. Se, in diversi momenti di un job, il worker che utilizza la quantità massima di memoria cambia, la stessa riga del grafico mostra i dati per più worker. Ogni punto dati nella linea mostra i dati del worker che utilizza la quantità massima di memoria in quel momento. Il grafico confronta la memoria stimata utilizzata dal worker con il limite di memoria in byte.
Puoi utilizzare questo grafico per risolvere i problemi di esaurimento della memoria. Gli arresti anomali per esaurimento della memoria del worker non vengono visualizzati in questo grafico.
Il grafico Utilizzo della memoria mostra una stima della memoria utilizzata da tutti i worker nel job Dataflow rispetto al limite di memoria in byte.
Metriche di input e output
Se il job di streaming Dataflow legge o scrive record utilizzando Pub/Sub, la scheda Metriche job mostra le metriche per le letture o le scritture Pub/Sub.
Tutte le metriche di input dello stesso tipo vengono combinate, così come tutte le metriche di output. Ad esempio, tutte le metriche Pub/Sub sono raggruppate in una sezione. Ogni tipo di metrica è organizzato in una sezione separata. Per modificare le metriche visualizzate, seleziona la sezione a sinistra che rappresenta al meglio le metriche che stai cercando. Le seguenti immagini mostrano tutte le sezioni disponibili.
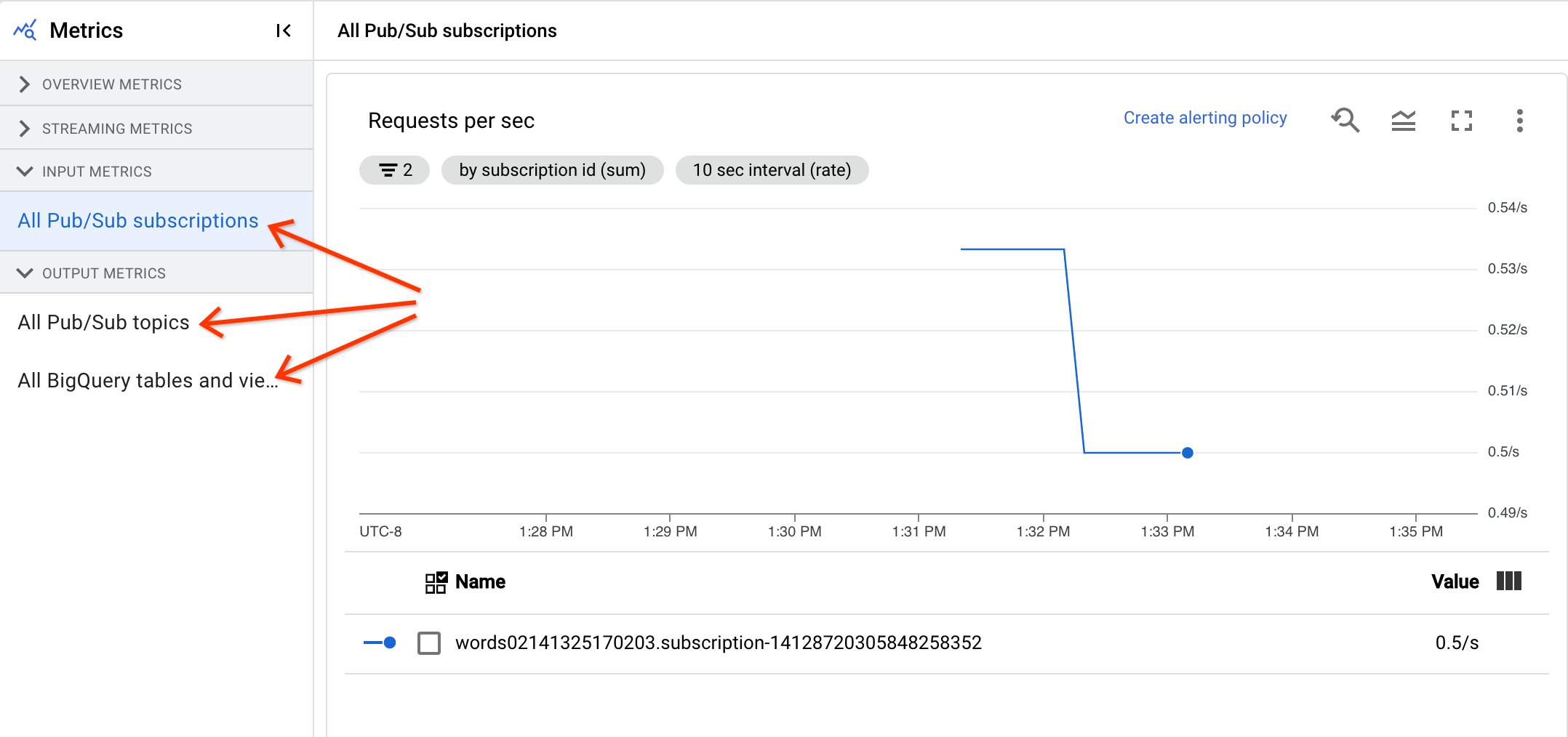
I due grafici seguenti vengono visualizzati nelle sezioni Metriche di input e Metriche di output.
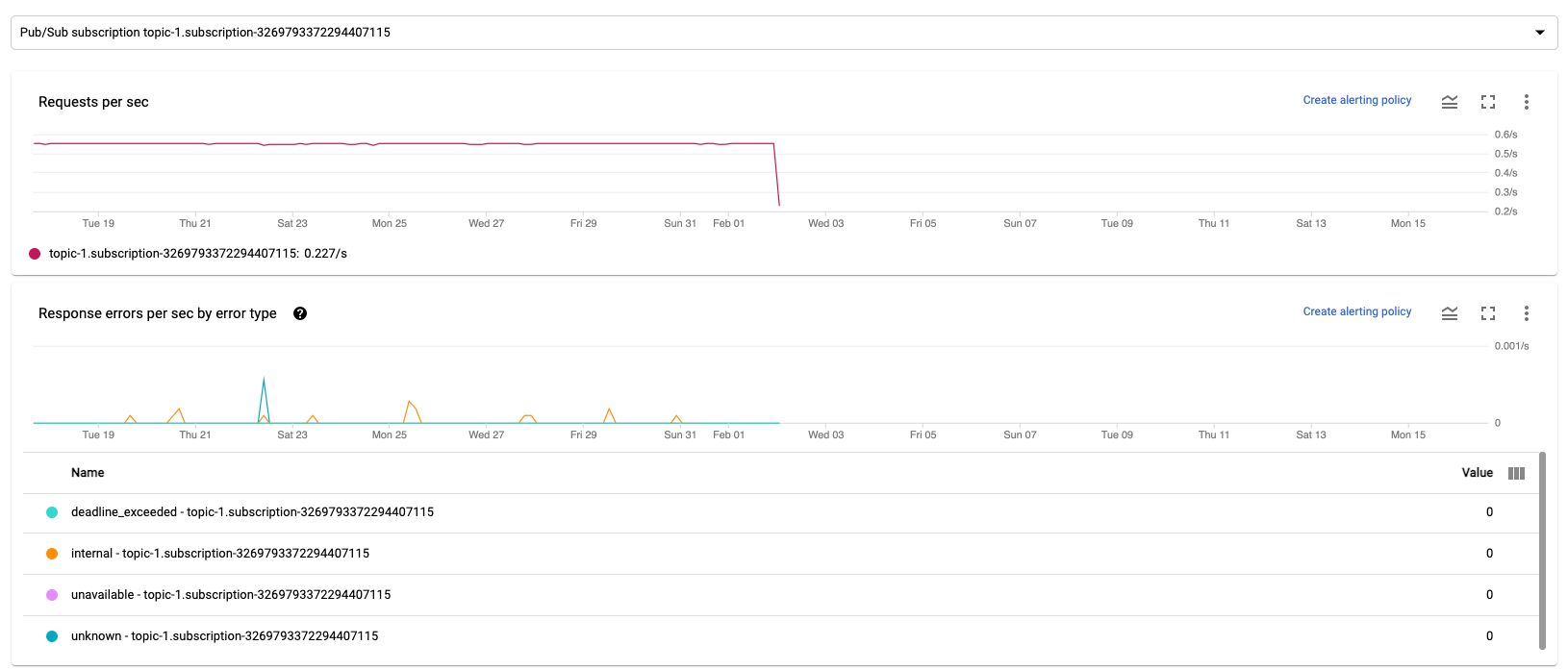
Richieste al secondo
Richieste al secondo è la frequenza delle richieste API per leggere o scrivere dati in base all'origine o al sink nel tempo. Se questo tasso scende a zero o diminuisce in modo significativo per un periodo di tempo prolungato rispetto al comportamento previsto, la pipeline potrebbe non essere in grado di eseguire determinate operazioni. Inoltre, potrebbero non esserci dati da leggere. In questo caso, esamina i passaggi del job con una filigrana di sistema elevata. Inoltre, esamina i log dei worker per verificare la presenza di errori o indicazioni di elaborazione lenta.

Errori di risposta al secondo per tipo di errore
Errori di risposta al secondo per tipo di errore è la frequenza delle richieste API non riuscite per leggere o scrivere dati per origine o sink nel tempo. Se questi errori si verificano di frequente, queste richieste API potrebbero rallentare l'elaborazione. Queste richieste API non riuscite devono essere esaminate. Per risolvere questi problemi, consulta i codici di errore di input e output generali. Esamina anche la documentazione di eventuali codici di errore specifici utilizzati dall'origine o dal sink, ad esempio i codici di errore Pub/Sub.
Per ulteriori informazioni sugli scenari in cui puoi utilizzare queste metriche per il debug, consulta la sezione Strumenti per il debug in "Risolvere i problemi relativi ai job lenti o bloccati".
Usa Cloud Monitoring
Dataflow è completamente integrato con Cloud Monitoring. Utilizza Cloud Monitoring per le seguenti attività:
- Crea avvisi quando il tuo job supera una soglia definita dall'utente.
- Utilizza Esplora metriche per creare query e regolare l'intervallo di tempo delle metriche.
- Visualizzare le metriche che non vengono visualizzate nell'interfaccia di monitoraggio di Dataflow.
Per istruzioni sulla creazione di avvisi e sull'utilizzo di Metrics Explorer, vedi Utilizzare Cloud Monitoring per le pipeline Dataflow.
Per l'elenco completo delle metriche Dataflow, consulta la Google Cloud documentazione sulle metriche.
Crea avvisi di Cloud Monitoring
Cloud Monitoring ti consente di creare avvisi quando il job Dataflow supera una soglia definita dall'utente. Per creare un avviso di Cloud Monitoring da un grafico delle metriche, fai clic su Crea policy di avviso.
Se non riesci a visualizzare i grafici di monitoraggio o a creare avvisi, potresti aver bisogno di ulteriori autorizzazioni di monitoraggio.
Visualizza in Esplora metriche
Puoi visualizzare i grafici delle metriche di Dataflow in Esplora metriche, dove puoi creare query e regolare l'intervallo di tempo delle metriche.
Per visualizzare i grafici Dataflow in Metrics Explorer, nella visualizzazione Metriche job, apri Altre opzioni per i grafici e fai clic su Visualizza in Esplora metriche.
Quando regoli l'intervallo di tempo delle metriche, puoi selezionare una durata predefinita o un intervallo di tempo personalizzato per analizzare il job.
Per impostazione predefinita, per i job di streaming e i job batch in corso, la visualizzazione mostra le metriche delle sei ore precedenti per quel job. Per i job di streaming interrotti o completati, la visualizzazione predefinita mostra l'intero runtime della durata del job.
Metriche I/O di Dataflow
Puoi visualizzare le seguenti metriche I/O di Dataflow in Esplora metriche:
job/pubsub/write_count: richieste di pubblicazione Pub/Sub da PubsubIO.Write nei job Dataflow.job/pubsub/read_count: richieste di pull di Pub/Sub da PubsubIO.Read nei job Dataflow.job/bigquery/write_count: richieste di pubblicazione BigQuery da BigQueryIO.Write nei job Dataflow. Le metrichejob/bigquery/write_countsono disponibili nelle pipeline Python utilizzando la trasformazione WriteToBigQuery conmethod='STREAMING_INSERTS'abilitato su Apache Beam v2.28.0 o versioni successive. Questa metrica è disponibile sia per le pipeline batch che per quelle di streaming.- Se la pipeline utilizza un'origine o un sink BigQuery, per risolvere i problemi relativi alla quota, utilizza le metriche dell'API BigQuery Storage.
Metriche DoFn
Per i job di streaming che utilizzano Streaming Engine
e non utilizzano Runner v2, puoi visualizzare le seguenti
metriche per i singoli DoFns definiti dall'utente:
job/dofn_latency_average: Il tempo medio di elaborazione dei messaggi per un singoloDoFnnegli ultimi 3 minuti, in millisecondi.job/dofn_latency_max: Il tempo massimo di elaborazione dei messaggi per un singoloDoFnnella finestra di 3 minuti precedente, in millisecondi.job/dofn_latency_min: Il tempo minimo di elaborazione dei messaggi per un singoloDoFnnella finestra degli ultimi 3 minuti, in millisecondi.job/dofn_latency_num_messages: Il numero di messaggi elaborati da un singoloDoFnnegli ultimi 3 minuti.job/dofn_latency_total: Il tempo totale di elaborazione dei messaggi per tutti i messaggi in un singoloDoFnnella finestra degli ultimi 3 minuti, in millisecondi.job/oldest_active_message_age: Il tempo di elaborazione del messaggio attivo meno recente all'interno di unDoFn, in millisecondi.
Queste metriche richiedono l'SDK Apache Beam versione 2.53.0 o successive. Per visualizzare queste metriche, utilizza Esplora metriche.
Puoi utilizzare queste metriche per scoprire quali DoFns contribuiscono maggiormente alla latenza di elaborazione nei tuoi job. Ad esempio, se un job è bloccato, utilizza la metrica
job/oldest_active_message_age per trovare il DoFn con il messaggio attivo meno recente. L'immagine seguente mostra un DoFn con un picco elevato in questa metrica:

Per visualizzare il nome del DoFn, tieni il puntatore sopra la linea del grafico.
Passaggi successivi
- Risolvere i problemi relativi ai job lenti o bloccati
- Ottimizzare la scalabilità automatica orizzontale per le pipeline di streaming
- Ottimizza i costi