Puoi visualizzare i grafici di monitoraggio della scalabilità automatica per i job di streaming nell'interfaccia di monitoraggio di Dataflow. Questi grafici mostrano le metriche per la durata di un job della pipeline e includono le seguenti informazioni:
- Il numero di istanze di worker utilizzate dal job in un momento qualsiasi
- I file di log della scalabilità automatica
- Il backlog stimato nel tempo
- L'utilizzo medio della CPU nel tempo
I grafici sono allineati verticalmente in modo da poter correlare le metriche di backlog e utilizzo della CPU con gli eventi di scalabilità dei worker.
Per saperne di più su come Dataflow prende decisioni di scalabilità automatica, consulta la documentazione sulle funzionalità di ottimizzazione automatica. Per ulteriori informazioni sul monitoraggio e sulle metriche di Dataflow, consulta Utilizzare l'interfaccia di monitoraggio di Dataflow.
Accedere ai grafici di monitoraggio della scalabilità automatica
Puoi accedere all'interfaccia di monitoraggio di Dataflow utilizzando Google Cloud console. Per accedere alla scheda delle metriche di Scalabilità automatica:
- Accedi alla console Google Cloud .
- Selezionare il tuo progetto Google Cloud .
- Apri il menu di navigazione.
- In Analytics, fai clic su Dataflow. Viene visualizzato un elenco di job Dataflow insieme al relativo stato.
- Fai clic sul job che vuoi monitorare, quindi sulla scheda Scalabilità automatica.
Monitorare le metriche di scalabilità automatica
Il servizio Dataflow sceglie automaticamente il numero di istanze worker necessarie per eseguire il job di scalabilità automatica. Il numero di istanze worker può cambiare nel tempo in base ai requisiti del job.
Puoi visualizzare le metriche di scalabilità automatica nella scheda Scalabilità automatica dell'interfaccia Dataflow. Ogni metrica è organizzata nei seguenti grafici:
La barra delle azioni di scalabilità automatica mostra lo stato attuale della scalabilità automatica e il conteggio dei worker.
Scalabilità automatica
Il grafico Scalabilità automatica mostra un grafico delle serie temporali del numero attuale di worker, del numero target di worker e del numero minimo e massimo di worker.

Per visualizzare i log di scalabilità automatica, fai clic su Mostra log di scalabilità automatica.
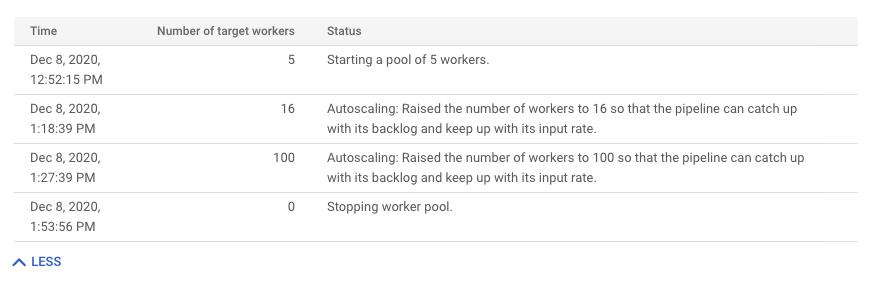
Per visualizzare la cronologia delle modifiche alla scalabilità automatica, fai clic su Altra cronologia. Viene visualizzata una tabella con informazioni sulla cronologia dei worker della pipeline. La cronologia include gli eventi di scalabilità automatica, incluso se il numero di worker ha raggiunto il conteggio minimo o massimo.
Logica di fondo della scalabilità automatica (solo Streaming Engine)
Il grafico Motivazione della scalabilità automatica mostra perché il gestore della scalabilità automatica ha eseguito lo scale up, lo scale down o non ha intrapreso alcuna azione in un determinato periodo di tempo.
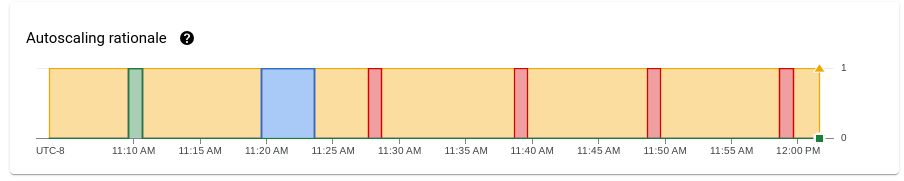
Per visualizzare una descrizione della logica in un punto specifico, tieni premuto il puntatore sopra il grafico.
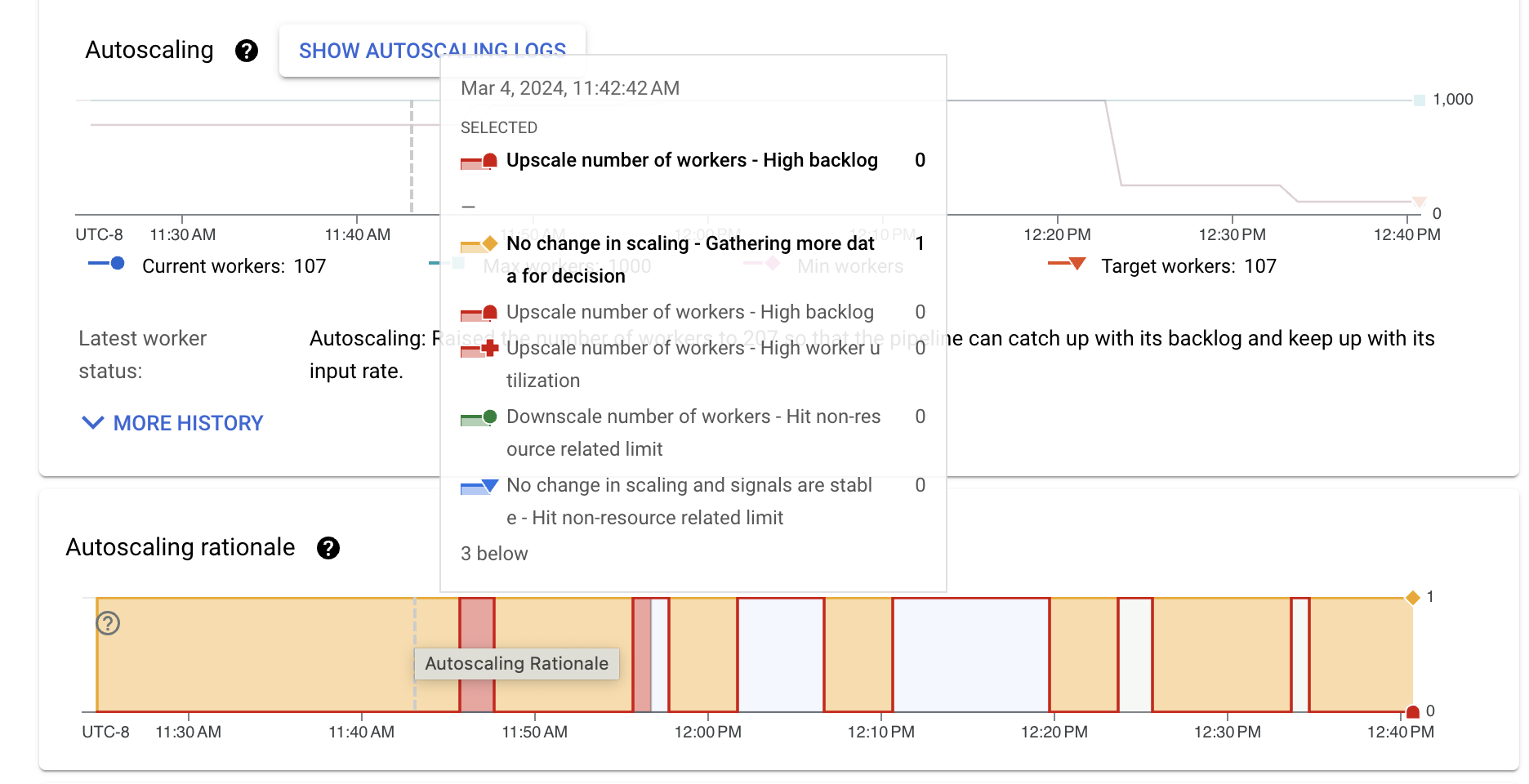
La tabella seguente elenca le azioni di scalabilità e le possibili motivazioni della scalabilità.
| Azione di scalabilità | Rationale | Descrizione |
|---|---|---|
| Nessuna variazione di scalabilità | Raccogliere più dati per la decisione | Lo strumento di scalabilità automatica non dispone di indicatori sufficienti per eseguire lo scale up o lo scale down. Ad esempio, lo stato del pool di lavoratori è cambiato di recente oppure le metriche di backlog o di utilizzo sono fluttuanti. |
| Nessuna variazione di scalabilità, indicatori stabili | Limite non correlato alle risorse raggiunto | Lo scaling è vincolato da un limite, ad esempio il parallelismo delle chiavi o il numero minimo e massimo di worker configurati. |
| Backlog ridotto e utilizzo elevato dei worker | La scalabilità automatica della pipeline è stata impostata su un valore stabile in base al traffico e alla configurazione attuali. Non è necessaria alcuna modifica del ridimensionamento. | |
| Scale up | Backlog elevato | Aumentare le risorse per ridurre il backlog. |
| Utilizzo elevato dei worker | Aumenta le dimensioni per raggiungere l'utilizzo CPU target. | |
| Raggiungere un limite non correlato alle risorse | Il numero minimo di worker è stato aggiornato e il numero attuale di worker è inferiore al minimo configurato. | |
| Scalabilità verso il basso | Utilizzo ridotto dei worker | Riduzione della scalabilità per raggiungere l'utilizzo CPU target. |
| Raggiungere un limite non correlato alle risorse | Il numero massimo di worker è stato aggiornato e il numero attuale di worker è superiore al massimo configurato. |
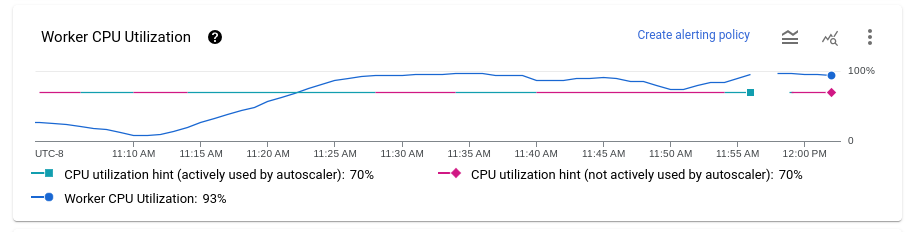
Utilizzo CPU worker
L'utilizzo della CPU è la quantità di CPU utilizzata divisa per la quantità di CPU disponibile per l'elaborazione. Il grafico Utilizzo medio della CPU mostra l'utilizzo medio della CPU per tutti i worker nel tempo, il suggerimento sull'utilizzo dei worker e se Dataflow ha utilizzato attivamente il suggerimento come target.
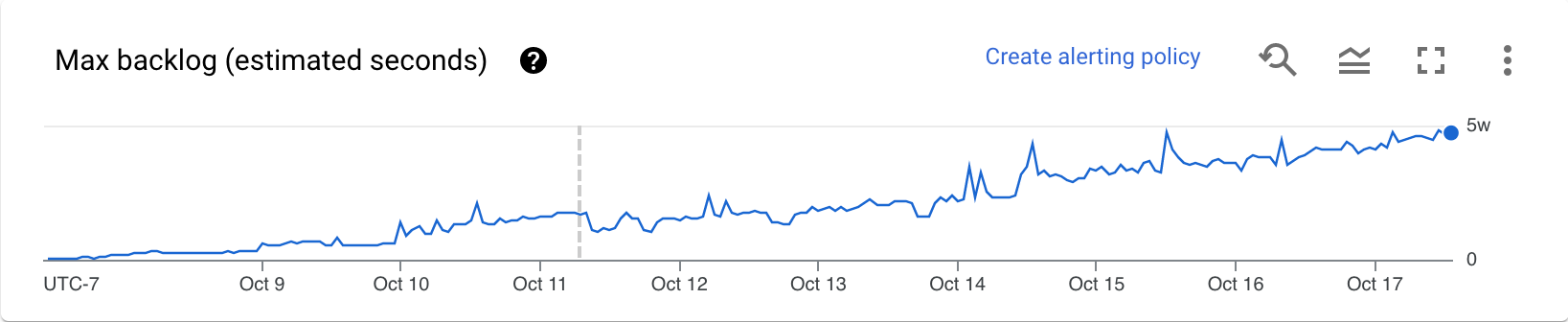
Backlog (solo Streaming Engine)
Il grafico Backlog massimo fornisce informazioni sugli elementi in attesa di elaborazione. Il grafico mostra una stima del tempo in secondi necessario per smaltire il backlog attuale se non arrivano nuovi dati e la velocità effettiva non cambia. Il tempo stimato di backlog viene calcolato in base alla velocità effettiva e ai byte di backlog dell'origine di input che devono ancora essere elaborati. Questa metrica viene utilizzata dalla funzionalità di scalabilità automatica dello streaming per determinare quando aumentare o diminuire lo scale.
I dati per questo grafico sono disponibili solo per i job che utilizzano Streaming Engine. Se il job di streaming non utilizza Streaming Engine, il grafico è vuoto.
Consigli
Di seguito sono riportati alcuni comportamenti che potresti osservare nella pipeline e consigli su come ottimizzare la scalabilità automatica:
Ridimensionamento eccessivo. Se l'utilizzo della CPU target è impostato su un valore troppo alto, potresti notare un pattern in cui Dataflow esegue lo scale down, il backlog inizia a crescere e Dataflow esegue di nuovo lo scale up per compensare, anziché convergere su un numero stabile di worker. Per mitigare questo problema, prova a impostare un suggerimento di utilizzo dei worker inferiore. Osserva l'utilizzo della CPU nel punto in cui il backlog inizia a crescere e imposta l'hint di utilizzo su questo valore.
Upscaling troppo lento. Se lo scale up è troppo lento, potrebbe rimanere indietro rispetto ai picchi di traffico, con conseguenti periodi di latenza maggiore. Prova a ridurre il suggerimento sull'utilizzo dei worker, in modo che Dataflow aumenti le risorse più rapidamente. Osserva l'utilizzo della CPU nel punto in cui il backlog inizia a crescere e imposta il suggerimento di utilizzo su questo valore. Monitora sia la latenza che il costo, perché un valore di suggerimento inferiore può aumentare il costo totale della pipeline se vengono sottoposti a provisioning più worker.
Upscaling eccessivo. Se noti un upscaling eccessivo, con conseguente aumento dei costi, valuta la possibilità di aumentare il suggerimento sull'utilizzo dei worker. Monitora la latenza per assicurarti che rimanga entro limiti accettabili per il tuo scenario.
Per saperne di più, vedi Impostare il suggerimento sull'utilizzo dei lavoratori. Quando provi un nuovo valore di suggerimento per l'utilizzo dei worker, attendi qualche minuto prima che la pipeline si stabilizzi dopo ogni aggiustamento.
Passaggi successivi
- Ottimizzare la scalabilità automatica orizzontale per le pipeline di streaming
- Risolvere i problemi di scalabilità automatica di Dataflow