In der Dataflow-Monitoring-Oberfläche werden im Bereich Step info (Schrittinformationen) Informationen zu einzelnen Schritten in einem Job angezeigt. Ein Schritt stellt eine einzelne Transformation in Ihrer Pipeline dar. Zusammengesetzte Transformationen enthalten Unterschritte.
Im Bereich Schrittinformationen werden die folgenden Informationen angezeigt:
- Messwerte für den Schritt.
- Informationen zu den Eingabe- und Ausgabesammlungen des Schritts.
- Welche Phasen entsprechen diesem Schritt?
- Messwerte zu Nebeneingaben
Im Bereich Schrittinformationen können Sie nachvollziehen, wie Ihr Job in den einzelnen Schritten ausgeführt wird, und Schritte finden, die sich möglicherweise optimieren lassen.
Schrittinformationen ansehen
So rufen Sie Schrittinformationen auf:
Rufen Sie in der Google Cloud Console die Seite Dataflow > Jobs auf.
Wählen Sie einen Job aus.
Klicken Sie auf den Tab Jobgrafik, um die Jobgrafik aufzurufen. Im Job-Diagramm wird jeder Schritt in der Pipeline als Feld dargestellt.
Klicken Sie auf einen Schritt. Informationen zum Schritt werden im Bereich Schrittinformationen angezeigt.
Wenn Sie die Teilschritte für eine zusammengesetzte Transformation aufrufen möchten, klicken Sie auf den Pfeil Knoten maximieren.
Messwerte für Schritte
Im Bereich Schrittinformationen werden die folgenden Messwerte für den Schritt angezeigt.
Systemwasserzeichen und ‑verzögerung
Das Systemwasserzeichen ist der letzte Zeitstempel, für den alle Ereigniszeiten vollständig verarbeitet wurden. Die Systemwasserzeichenverzögerung ist die maximale Zeit, die ein Datenelement auf die Verarbeitung gewartet hat.
Datenwasserzeichen und ‑verzögerung
Das Datenwasserzeichen ist der Zeitstempel, der den geschätzten Abschluss der Dateneingabe für diesen Schritt markiert. Die Verzögerung des Datenwasserzeichens ist die Differenz zwischen der Zeit des letzten Eingabeereignisses und dem Datenwasserzeichen.
Echtzeit
Die Echtzeit ist die ungefähre Zeit, die in allen Threads in allen Workern für die folgenden Aktionen aufgewendet wurde:
- Schritt initialisieren
- Daten verarbeiten
- Daten nach dem Zufallsprinzip verteilen
- Schritt beenden
Bei zusammengesetzten Schritten entspricht die Echtzeit der Summe der für die einzelnen Schritte aufgewendeten Zeit.
Mit der Echtzeit können Sie Schritte ermitteln, die mehr Zeit benötigen, und so feststellen, welcher Teil Ihrer Pipeline mehr Zeit in Anspruch nimmt, als er sollte.
Engpassstatus
Wenn Dataflow einen Engpass erkennt, wird eine Benachrichtigung mit der Ursache angezeigt, sofern bekannt. Weitere Informationen finden Sie unter Engpässe beheben.
Maximale Vorgangslatenz
Die maximale Vorgangslatenz ist die maximale Zeit, die derzeit für diesen Schritt aufgewendet wird, um eingehende Nachrichten oder Fensterablaufzeiten zu verarbeiten. Dieser Messwert wird aggregiert über Schritte hinweg gemessen, die zu einer einzelnen Phase zusammengefasst werden. Der Wert bezieht sich damit auf die gesamte Phase.
Schlüsselparallelität
Die Schlüsselparallelität ist die ungefähre Anzahl der Schlüssel, die für die Datenverarbeitung in diesem Schritt verwendet werden.
Eingabe-/Ausgabesammlungen
Im Bereich Schrittinformationen werden die folgenden Informationen zu jeder der Eingabe- und Ausgabesammlungen im Schritt angezeigt:
Durchsatzdiagramm. Dieses Diagramm zeigt den Durchsatz für die Sammlung. Sie können das Diagramm als Elemente pro Sekunde oder als Byte pro Sekunde anzeigen lassen. Weitere Informationen zu diesem Messwert finden Sie unter Durchsatz.
Anzahl der Elemente, die der Sammlung hinzugefügt wurden.
Geschätzte Größe der Sammlung in Byte.
Optimierte Phasen
Eine Phase stellt eine einzelne Arbeitseinheit dar, die von Dataflow ausgeführt wird. Wenn Sie einen Schritt im Jobdiagramm auswählen, werden im Bereich Schrittinformationen die Namen der Phasen angezeigt, in denen dieser Schritt ausgeführt wird, sowie der aktuelle Status, z. B. „Wird ausgeführt“, „Angehalten“ oder „Erfolgreich“.
Weitere Informationen zu den Phasen in Ihrem Job finden Sie auf dem Tab Ausführungsdetails.
Messwerte zu Nebeneingaben
Eine Nebeneingabe ist eine zusätzliche Eingabe, auf die eine Transformation bei jeder Verarbeitung eines Elements zugreifen kann. Wenn eine Transformation eine Nebeneingabe erstellt oder verwendet, werden im Bereich Zusatzinformationen Messwerte für die Sammlung von Nebeneingaben angezeigt.
Wenn eine zusammengesetzte Transformation eine Nebeneingabe erstellt oder verwendet, erweitern Sie die zusammengesetzte Transformation, bis Sie die spezifische Subtransformation sehen, die die Nebeneingabe erstellt oder verwendet. Wählen Sie diese Subtransformation aus, um die Messwerte zu Nebeneingaben zu sehen.
Transformationen, die eine Nebeneingabe erstellen
Wenn eine Transformation eine Sammlung von Nebeneingaben erstellt, werden im Bereich Messwerte zu Nebeneingaben der Name der Sammlung und die folgenden Messwerte angezeigt:
- Zeit zum Schreiben: Die Ausführungszeit für das Schreiben der Sammlung von Nebeneingaben.
- Geschriebene Byte: Gesamtzahl der Byte, die in die Sammlung der Nebeneingaben geschrieben wurden.
- Zeit und Byte zum Lesen von Nebeneingaben: Eine Tabelle mit zusätzlichen Messwerten für alle Transformationen, die auf die Sammlung der Nebeneingaben zugreifen. Sie werden als Nutzer von Nebeneingaben bezeichnet.
Unter Zeit und Byte zum Lesen von Nebeneingaben werden für jeden Nutzer der Nebeneingaben folgende Informationen angezeigt:
- Nutzer der Nebeneingabe: Transformationsname des Nutzers der Nebeneingabe
- Zeit zum Lesen: Zeit, die für das Lesen der Nebeneingabesammlung benötigt wurde.
- Gelesene Byte: Anzahl der Byte, die dieser Nutzer aus der Nebeneingabesammlung gelesen hat
Das folgende Bild zeigt Messwerte zu Nebeneingaben für eine Transformation, die eine Sammlung von Nebeneingaben erstellt:
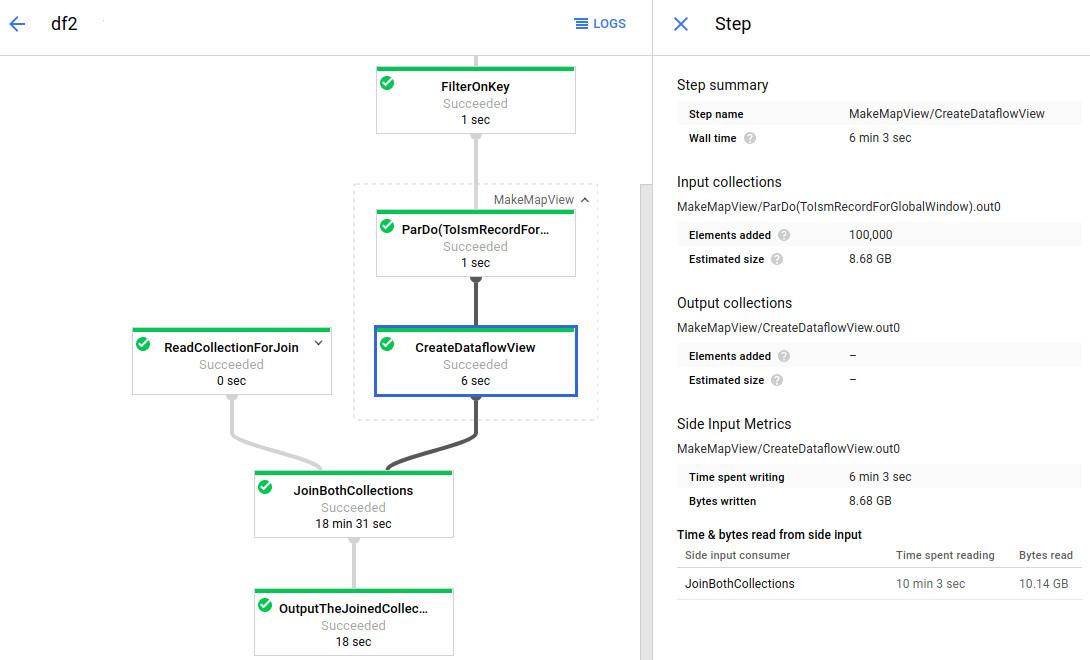
Die Jobgrafik enthält eine erweiterte zusammengesetzte Transformation (MakeMapView). Die Untertransformation, durch die die Nebeneingabe (CreateDataflowView) erstellt wird, ist markiert und die Messwerte zu Nebeneingaben werden im Bereich Details zum Schritt angezeigt.
Transformationen, die Nebeneingaben nutzen
Wenn eine Transformation eine oder mehrere Nebeneingaben nutzt, wird im Bereich Messwerte zu Nebeneingaben die Tabelle Zeit und Byte zum Lesen von Nebeneingaben angezeigt. Diese Tabelle enthält für jede Nebeneingabesammlung folgende Informationen:
- Nebeneingabesammlung: Name der Nebeneingabesammlung
- Zeit zum Lesen: Zum Lesen dieser Nebeneingabesammlung benötigte Zeit
- Gelesene Byte: Anzahl der Byte, die die Transformation aus dieser Nebeneingabesammlung gelesen hat
Das folgende Bild zeigt Messwerte zu Nebeneingaben für eine Transformation, die aus einer Sammlung von Nebeneingaben liest.
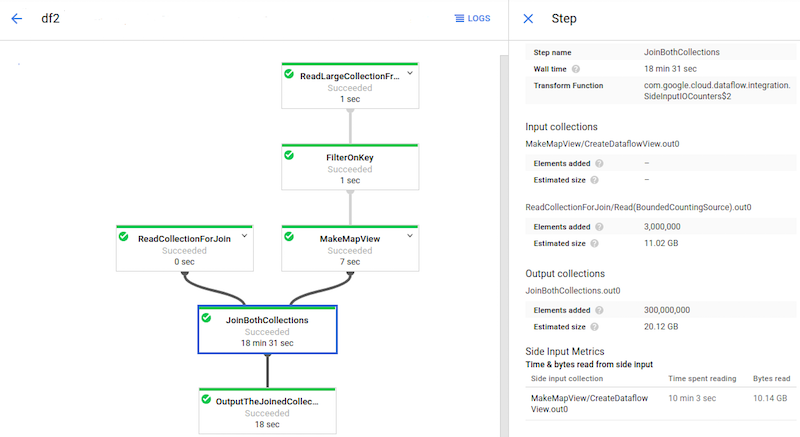
Die Transformation JoinBothCollections liest aus einer Sammlung von Nebeneingaben.
JoinBothCollections ist in der Jobgrafik ausgewählt und die Messwerte zu Nebeneingaben werden im Bereich Details zum Schritt angezeigt.
Leistungsprobleme bei Nebeneingaben identifizieren
Nebeneingaben können sich auf die Leistung Ihrer Pipeline auswirken. Wenn Ihre Pipeline eine Nebeneingabe verwendet, schreibt Dataflow die Sammlung in eine nichtflüchtige Ebene, z. B. auf eine Festplatte, und wandelt die Leseergebnisse aus dieser nichtflüchtigen Sammlung um. Diese Lese- und Schreibvorgänge beeinflussen die Ausführungszeit Ihres Jobs.
Ein häufig auftretendes Leistungsproblem bei Nebeneingaben wird durch Wiederholung verursacht. Wenn die Nebeneingabesammlung PCollection zu groß ist, können die Worker nicht die gesamte Sammlung im Cache speichern.
Das bedeutet, die Worker müssen mehrmals aus der nichtflüchtigen Nebeneingabesammlung lesen.
Im folgenden Bild zeigen die Messwerte der Nebeneingaben, dass die Gesamtzahl der Byte, die aus der Nebeneingabesammlung gelesen werden, viel höher ist als die Größe der Sammlung selbst (insgesamt geschriebene Byte). Die Nebeneingabesammlung ist 563 MB groß und die Summe der Byte, die von den auf die Sammlung zugreifenden Transformationen gelesen werden, beträgt fast 12 GB.
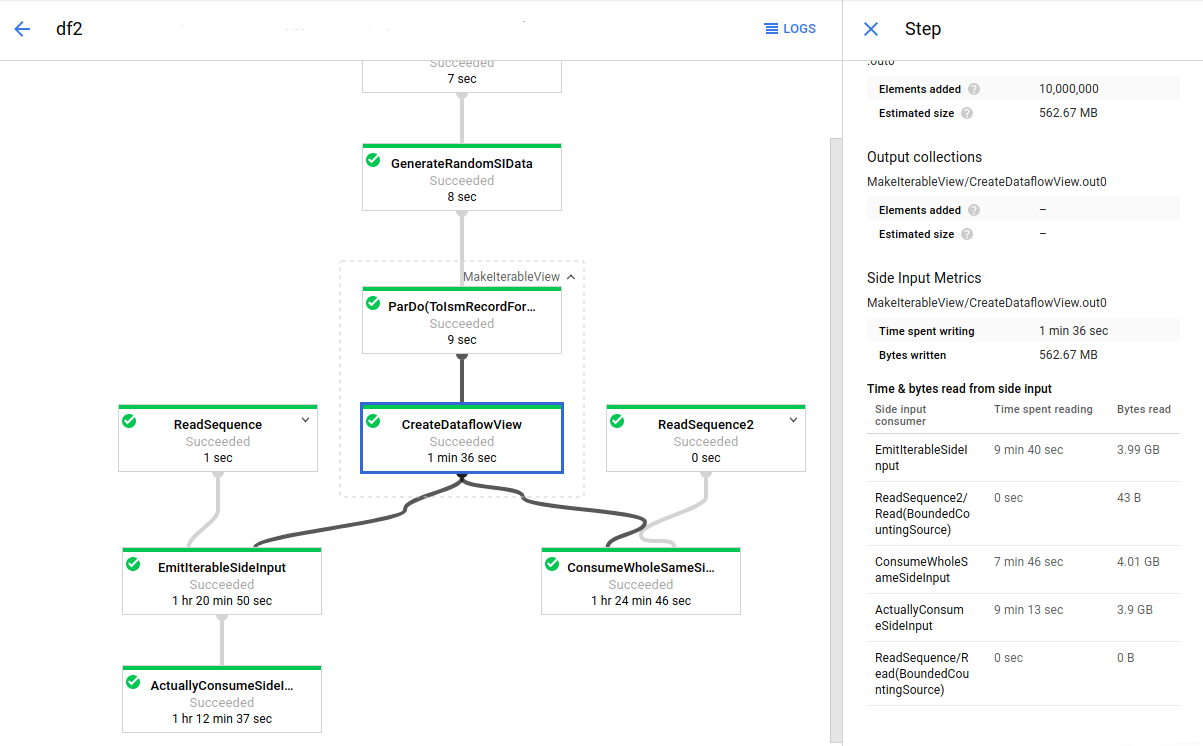
Um die Leistung dieser Pipeline zu verbessern, müssen Sie den Algorithmus neu gestalten, um zu vermeiden, dass die Nebeneingabedaten iteriert oder wiederholt abgerufen werden. In diesem Fall erstellt die Pipeline das kartesische Produkt zweier Sammlungen. Der Algorithmus durchläuft die gesamte Nebeneingabesammlung für jedes Element der Hauptsammlung. Sie können das Zugriffsmuster der Pipeline verbessern, indem Sie mehrere Elemente der Hauptsammlung gruppieren. Diese Änderung verringert die Häufigkeit, mit der Worker das Lesen der Nebeneingabesammlung wiederholen müssen.
Ein weiteres Leistungsproblem kann auftreten, wenn Ihre Pipeline einen Join vornimmt. Dabei wird ein ParDo auf eine oder mehrere große Nebeneingaben angewendet. In diesem Fall können die Worker einen hohen prozentualen Anteil der Verarbeitungszeit für die Join-Vorgänge aus den Sammlungen der Nebeneingaben lesen.
Das folgende Bild zeigt Messwerte für Nebeneingaben, die dieses Problem verdeutlichen:
Die Transformation JoinBothCollections hat eine Verarbeitungszeit von mehr als 18 Minuten. Worker verbringen den Großteil der Verarbeitungszeit (10 Minuten) mit dem Lesen der 10 GB großen Sammlung von Nebeneingaben. Zur Verbesserung der Leistung dieser Pipeline können Sie anstelle von Nebeneingaben CoGroupByKey verwenden.