이 페이지에서는 SAP Landscape Transformation(SLT)을 사용하여 SAP 애플리케이션에서 Google Cloud로 데이터를 실시간으로 복제하는 방법을 설명합니다. 이 페이지의 내용은 Cloud Data Fusion 허브에서 사용할 수 있는 SAP SLT Replication 및 SAP SLT No RFC Replication 플러그인에 적용됩니다. 여기서는 다음 작업을 수행하기 위한 SAP 소스 시스템, SLT, Cloud Storage, Cloud Data Fusion의 구성을 확인할 수 있습니다.
- SAP SLT를 사용하여 SAP 메타데이터와 테이블 데이터를 Google Cloud로 푸시하기
- Cloud Storage 버킷에서 데이터를 읽는 Cloud Data Fusion 복제 작업 만들기
SAP SLT Replication을 사용하면 SAP 소스에서 BigQuery로 실시간 데이터를 지속적으로 복제할 수 있습니다. 코딩하지 않고도 SAP 시스템에서 데이터 전송을 구성하고 실행할 수 있습니다.
Cloud Data Fusion SLT 복제 프로세스는 다음과 같습니다.
- 데이터의 출처는 SAP 소스 시스템입니다.
- SLT는 데이터를 추적하고 읽으며 Cloud Storage에 푸시합니다.
- Cloud Data Fusion은 스토리지 버킷에서 데이터를 가져와서 BigQuery에 기록합니다.
Google Cloud에서 호스팅되는 SAP 시스템을 포함해 지원되는 SAP 시스템에서 데이터를 전송할 수 있습니다.
자세한 내용은 Google Cloud 기반 SAP 개요 및 지원 세부정보를 참조하세요.
시작하기 전에
이 플러그인을 사용하려면 다음 영역에 대한 도메인 지식이 필요합니다.
- Cloud Data Fusion에서 파이프라인 빌드
- IAM으로 액세스 관리
- SAP Cloud 및 온프레미스 엔터프라이즈 리소스 계획(ERP) 시스템 구성
구성을 수행하는 관리자 및 사용자
이 페이지의 작업은 Google Cloud 또는 SAP 시스템에서 다음 역할을 가진 사용자가 실행합니다.
| 사용자 유형 | 설명 |
|---|---|
| Google Cloud 관리자 | 이 역할이 할당된 사용자는 Google Cloud 계정의 관리자입니다. |
| Cloud Data Fusion 사용자 | 이 역할이 할당된 사용자는 데이터 파이프라인을 설계하고 실행할 수 있는 권한이 있습니다. 이 역할에는 최소한의 Data Fusion 뷰어(roles/datafusion.viewer) 역할이 부여됩니다. 역할 기반 액세스 제어를 사용하는 경우 추가 역할이 필요할 수 있습니다.
|
| SAP 관리자 | 이 역할이 할당된 사용자는 SAP 시스템의 관리자입니다. 사용자는 SAP 서비스 사이트에서 소프트웨어를 다운로드할 수 있습니다. IAM 역할이 아닙니다. |
| SAP 사용자 | 이 역할이 할당된 사용자는 SAP 시스템에 연결할 수 있는 권한이 있습니다. IAM 역할이 아닙니다. |
지원되는 복제 작업
SAP SLT Replication 플러그인은 다음 작업을 지원합니다.
데이터 모델링: 이 플러그인에서는 모든 데이터 모델링 작업(레코드 insert, delete, update)이 지원됩니다.
데이터 정의: SAP Note 2055599(확인하려면 SAP 지원 로그인 필요)에 설명된 대로 SLT에서 자동으로 복제되는 소스 시스템 테이블 구조 변경사항에는 제한이 있습니다. 이 플러그인에서는 일부 데이터 정의 작업을 지원하지 않습니다. 수동으로 전파해야 합니다.
- 지원됨:
- 키 필드가 아닌 필드 추가(SE11에서 변경한 후 SE14를 사용하여 테이블 활성화)
- 지원되지 않음
- 키 필드 추가/삭제
- 키 필드가 아닌 필드 삭제
- 데이터 유형 수정
SAP 요구사항
SAP 시스템에 다음 항목이 필요합니다.
- 소스 SAP 시스템(삽입) 또는 전용 SLT 허브 시스템으로 SLT 서버 버전 2011 SP17 이상이 설치되어 있습니다.
- 소스 SAP 시스템이 SAP ECC 또는 SAP S/4HANA이며 DMIS 2011 SP17 이상(DMIS 2018, DMIS 2020)을 지원합니다.
- SAP 사용자 인터페이스 부가기능은 SAP Netweaver 버전과 호환되어야 합니다.
서포트 패키지에서는
/UI2/CL_JSON클래스PL 12이상이 지원됩니다. 그렇지 않으면PL12의 SAP Note 2798102와 같이 사용자 인터페이스 부가기능 버전에 따라/UI2/CL_JSON클래스corrections에 대해 최신 SAP Note를 구현합니다.다음과 같은 보안이 마련되어 있습니다.
Cloud Data Fusion 요구사항
- 에디션에 상관없이 Cloud Data Fusion 인스턴스 버전 6.4.0 이상이 필요합니다.
- Cloud Data Fusion 인스턴스에 할당된 서비스 계정에 필요한 역할이 부여됩니다(서비스 계정 사용자 권한 부여 참조).
- 비공개 Cloud Data Fusion 인스턴스의 경우 VPC 피어링이 필요합니다.
Google Cloud 요구사항
- Google Cloud 프로젝트에서 Cloud Storage API를 사용 설정합니다.
- Cloud Data Fusion 사용자는 Cloud Storage 버킷에서 폴더를 만들 수 있는 권한을 부여받아야 합니다(Cloud Storage에 대한 IAM 역할 참조).
- 선택사항: 조직에 필요한 경우 보관 정책을 설정합니다.
스토리지 버킷 만들기
SLT 복제 작업을 만들기 전에 Cloud Storage 버킷을 만듭니다. 이 작업은 데이터를 버킷으로 전송하고 5분마다 스테이징 버킷을 새로고침합니다. 이 작업을 실행하면 Cloud Data Fusion이 스토리지 버킷에서 데이터를 읽고 이를 BigQuery에 기록합니다.
Google Cloud에 SLT가 설치된 경우:
SLT 서버에는 만든 버킷에서 Cloud Storage 객체를 만들고 수정할 수 있는 권한이 있어야 합니다.
최소한 서비스 계정에 다음 역할을 부여합니다.
- 서비스 계정 토큰 생성자(
roles/iam.serviceAccountTokenCreator) - 서비스 사용량 소비자(
roles/serviceusage.serviceUsageConsumer) - 스토리지 객체 관리자(
roles/storage.objectAdmin)
Google Cloud에 SLT가 설치되지 않은 경우:
내부 메타데이터 엔드포인트에 대한 연결을 허용하도록 SAP VM과 Google Cloud 사이에 Cloud VPN 또는 Cloud Interconnect를 설치합니다(온프레미스 호스트를 위한 비공개 Google 액세스 구성 참조).
내부 메타데이터를 매핑할 수 없는 경우:
SLT가 실행되는 인프라의 운영체제를 기반으로 Google Cloud CLI를 설치합니다.
Cloud Storage가 사용 설정된 Google Cloud 프로젝트에 서비스 계정을 만듭니다.
SLT 운영체제에서 서비스 계정을 사용하여 Google Cloud에 대해 액세스 권한을 부여합니다.
서비스 계정에 대해 API 키를 만들고 Cloud Storage 관련 범위를 승인합니다.
CLI를 사용하여 이전에 설치한 gcloud CLI로 API 키를 가져옵니다.
액세스 토큰을 출력하는 gcloud CLI 명령어를 사용 설정하려면 SLT 시스템의 트랜잭션 SM69 도구에서 SAP 운영체제 명령어를 구성합니다.
액세스 토큰 출력
SAP 관리자는 Google Cloud에서 액세스 토큰을 검색하는 운영체제 명령어 SM69를 구성합니다.-
액세스 토큰을 출력하는 스크립트를 만들고 SAP LT Replication Server 호스트에서 <sid>adm 사용자로 이 스크립트를 호출하도록 SAP 운영체제 명령어를 구성합니다.
Linux
OS 명령어를 만들려면 다음 안내를 따르세요.
SAP LT Replication Server 호스트에서
<sid>adm에 액세스할 수 있는 디렉터리에 다음 줄이 포함된 bash 스크립트를 만듭니다.PATH_TO_GCLOUD_CLI/bin/gcloud auth print-access-token SERVICE_ACCOUNT_NAMESAP 사용자 인터페이스를 사용하여 외부 OS 명령어를 만듭니다.
SM69트랜잭션을 입력합니다.- 만들기를 클릭합니다.
- 외부 명령어 패널의 명령어 섹션에 명령어 이름을 입력합니다(예:
ZGOOGLE_CDF_TOKEN). 정의 섹션에서 다음을 수행합니다.
- 운영체제 명령어 필드에서 스크립트 파일 확장자로
sh를 입력합니다. 운영체제 명령어 매개변수 필드에 다음을 입력합니다.
/PATH_TO_SCRIPT/FILE_NAME.sh
- 운영체제 명령어 필드에서 스크립트 파일 확장자로
저장을 클릭합니다.
스크립트를 테스트하려면 실행을 클릭합니다.
실행을 다시 클릭합니다.
Google Cloud 토큰이 반환되고 SAP 사용자 인터페이스 패널 아래에 표시됩니다.
Windows
SAP 사용자 인터페이스를 사용하여 외부 운영체제 명령어를 만듭니다.
SM69트랜잭션을 입력합니다.- 만들기를 클릭합니다.
- 외부 명령어 패널의 명령어 섹션에 명령어 이름을 입력합니다(예:
ZGOOGLE_CDF_TOKEN). 정의 섹션에서 다음을 수행합니다.
- 운영체제 명령어 필드에
cmd /c을 입력합니다. 운영체제 명령어 매개변수 필드에 다음을 입력합니다.
gcloud auth print-access-token SERVICE_ACCOUNT_NAME
- 운영체제 명령어 필드에
저장을 클릭합니다.
스크립트를 테스트하려면 실행을 클릭합니다.
실행을 다시 클릭합니다.
Google Cloud 토큰이 반환되고 SAP 사용자 인터페이스 패널 아래에 표시됩니다.
SLT 요구사항
SLT 커넥터는 다음 설정을 포함해야 합니다.
- 커넥터가 SAP ECC NW 7.02, DMIS 2011 SP17 이상을 지원합니다.
- SLT와 Cloud Storage 시스템 간에 RFC 또는 데이터베이스 연결을 구성합니다.
- SSL 인증서를 설정합니다.
- Google Trust Services 저장소에서 다음 CA 인증서를 다운로드합니다.
- GTS Root R1
- GTS CA 1C3
- SAP 사용자 인터페이스에서
STRUST트랜잭션을 사용하여 루트 인증서와 하위 인증서를 모두SSL Client (Standard) PSE폴더로 가져옵니다.
- Google Trust Services 저장소에서 다음 CA 인증서를 다운로드합니다.
- 인터넷 통신 관리자(ICM)를 HTTPS로 설정해야 합니다. HTTP 및 HTTPS 포트가 SAP SLT 시스템에서 유지보수되고 활성화되었는지 확인합니다.
트랜잭션 코드
SMICM > Services를 통해 확인할 수 있습니다. - SAP SLT 시스템이 호스팅된 VM에서 Google Cloud API에 대해 액세스를 사용 설정합니다. 이렇게 하면 공개 인터넷을 통해 라우팅하지 않고도 Google Cloud 서비스 간의 비공개 통신이 사용 설정됩니다.
- 네트워크가 SAP 인프라와 Cloud Storage 간에 필요한 데이터 전송 볼륨과 속도를 지원할 수 있는지 확인합니다. 설치를 성공하려면 Cloud VPN 또는 Cloud Interconnect가 권장됩니다. 스트리밍 API의 처리량은 Cloud Storage 프로젝트에 부여된 클라이언트 할당량에 따라 달라집니다.
SLT Replication Server 구성
SAP 사용자는 다음 단계를 수행합니다.
다음 단계에서는 소스 시스템, 복제할 데이터 테이블, 대상 스토리지 버킷을 지정하여 SLT 서버를 소스 시스템과 Cloud Storage의 버킷에 연결합니다.
Google ABAP SDK 구성
데이터 복제용 SLT를 구성하려면(Cloud Data Fusion 인스턴스당 한 번) 다음 단계를 따릅니다.
SAP-User는 데이터를 Cloud Storage로 전송하기 위한 Google Cloud 서비스 계정 키에 대한 다음 정보를 구성 화면(SAP 트랜잭션
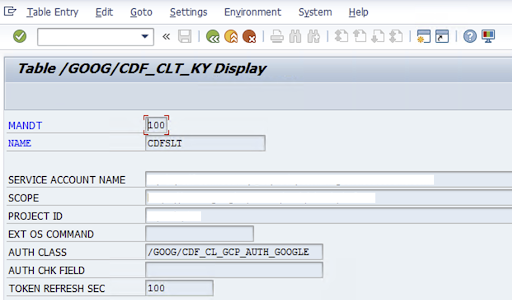
/GOOG/CDF_SETTINGS)에 입력하여 SLT 커넥터를 구성합니다. Transaction SE16를 사용하여 /GOOG/CDF_CLT_KY 테이블에서 다음 속성을 구성하고 이 키를 기록해 둡니다.- NAME: 서비스 계정 키의 이름입니다(예:
CDFSLT). - SERVICE ACCOUNT NAME: IAM 서비스 계정 이름
- SCOPE: 서비스 계정의 범위
- PROJECT_ID: Google Cloud 프로젝트의 ID
- 선택사항: EXT OS 명령어: SLT가 Google Cloud에 설치되어 있지 않은 경우에만 이 필드를 사용합니다.
AUTH CLASS: OS 명령어가 테이
/GOOG/CDF_CLT_KY에 설정된 경우 고정 값/GOOG/CDF_CL_GCP_AUTH를 사용합니다.TOKEN REFRESH SEC: 승인 토큰 새로고침 기간
- NAME: 서비스 계정 키의 이름입니다(예:
복제 구성 만들기
트랜잭션 코드 LTRC에 복제 구성을 만듭니다.
- LTRC 구성을 진행하려면 먼저 SLT와 소스 SAP 시스템 사이에 RFC 연결이 설정되었는지 확인합니다.
- 하나의 SLT 구성에 대해 여러 개의 SAP 테이블이 복제용으로 할당되었을 수 있습니다.
트랜잭션 코드
LTRC로 이동하고 New Configuration(새 구성)을 클릭합니다.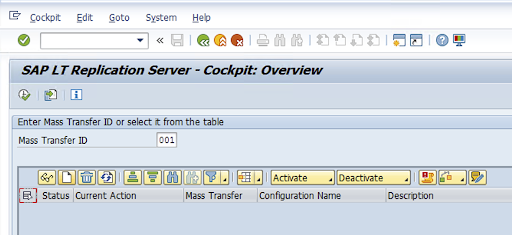
구성 이름 및 설명을 입력하고 다음을 클릭합니다.
SAP 소스 시스템에 RFC 연결을 지정하고 Next(다음)를 클릭합니다.
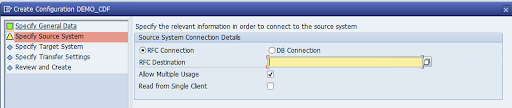
대상 시스템 연결 세부정보에서 Other(기타)를 선택합니다.
Scenario for RFC Communication(RFC 통신 시나리오) 필드를 펼치고 SLT SDK를 선택한 후 다음을 클릭합니다.
Specify Transfer Settings(전송 설정 지정) 창으로 이동하여 애플리케이션 이름
ZGOOGLE_CDF를 입력합니다.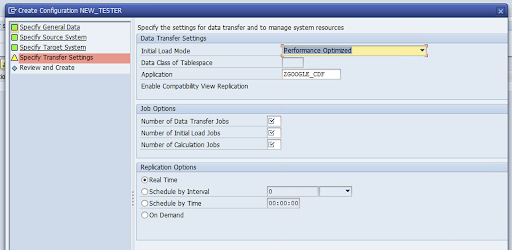
데이터 전송 작업 수, 초기 로드 작업 수, 계산 작업 수를 입력합니다. 성능에 대한 자세한 내용은 SAP LT Replication 서버 성능 최적화 가이드를 참조하세요.
실시간 > 다음을 클릭합니다.
구성을 검토하고 저장을 클릭합니다. 다음 단계는 대량 전송 ID를 참조하세요.
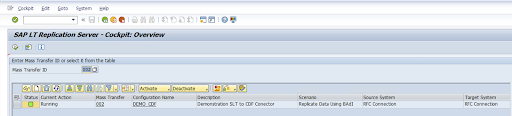
대량 전송 ID 및 SAP 테이블 세부정보를 유지하려면 SAP 트랜잭션(
/GOOG/CDF_SETTINGS)을 실행하세요.실행을 클릭하거나
F8을 누릅니다.행 추가 아이콘을 클릭하여 새 항목을 만듭니다.
대량 전송 ID, 대량 전송 키, GCP 키 이름, 대상 GCS 버킷을 입력합니다. 활성 여부 체크박스를 선택하고 변경사항을 저장합니다.
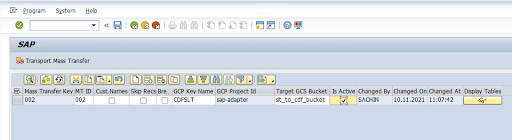
구성 이름 열에서 구성을 선택하고 데이터 프로비저닝을 클릭합니다.
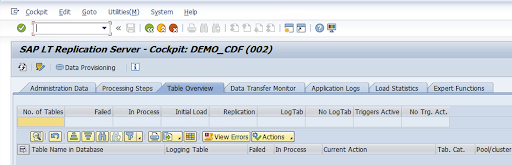
선택사항: 테이블 및 필드 이름을 맞춤설정합니다.
커스텀 이름을 클릭하고 저장합니다.
표시를 클릭합니다.
행 추가 또는 만들기 버튼을 클릭하여 새 항목을 만듭니다.
BigQuery에 사용할 SAP 테이블 이름 및 외부 테이블 이름을 입력하고 변경사항을 저장합니다.
표시 필드 열의 보기 버튼을 클릭하여 테이블 필드 매핑을 유지보수합니다.
추천 매핑과 함께 페이지가 열립니다. 선택사항: 임시 필드 이름 및 필드 설명을 입력한 후 매핑을 저장합니다.
LTRC 트랜잭션으로 이동합니다.
구성 이름 열에서 값을 선택하고 데이터 프로비저닝을 클릭합니다.
데이터베이스의 테이블 이름 필드에 테이블 이름을 입력하고 복제 시나리오를 선택합니다.
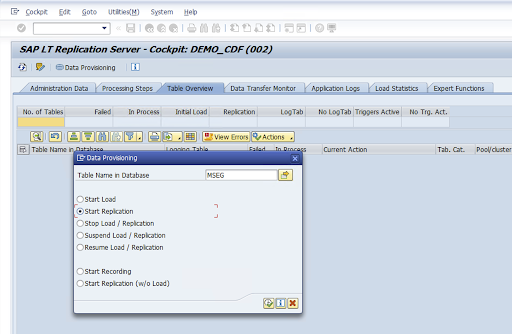
실행을 클릭합니다. 그러면 SLT SDK 구현이 트리거되고 데이터가 Cloud Storage의 대상 버킷으로 전송되기 시작합니다.
SAP 전송 파일 설치
Cloud Data Fusion에서 복제 작업을 설계 및 실행할 수 있도록 SAP 구성요소는 ZIP 파일에 보관처리된 SAP 전송 파일로 제공됩니다. Cloud Data Fusion 허브에서 플러그인을 배포할 때 다운로드할 수 있습니다.
SAP 전송 요청 ID와 관련 파일은 다음 표에 나와 있습니다.
| 전송 ID | Cofile | 데이터 파일 | 콘텐츠 |
|---|---|---|---|
| ED1K900520 | K900520.ED1 | R900520.ED1 | SAP BADI 구현 ES_IUUC_REPL_RUNTIME_OLO_EXIT |
| ED1K900337 | K900337.ED1 | R900337.ED1 | 승인 역할 /GOOG/SLT_CDF_AUTH |
SAP 전송을 설치하려면 다음 단계를 따르세요.
1단계: 전송 요청 파일 업로드
- SAP 인스턴스의 운영체제에 로그인합니다.
- SAP 트랜잭션 코드
AL11을 사용해서DIR_TRANS폴더의 경로를 가져옵니다. 일반적으로 경로는/usr/sap/trans/입니다. - cofile을
DIR_TRANS/cofiles폴더에 복사합니다. - 데이터 파일을
DIR_TRANS/data폴더에 복사합니다. - 데이터와 cofile의 사용자 및 그룹을
<sid>adm및sapsys로 설정합니다.
2단계: 전송 요청 파일 가져오기
SAP 관리자는 SAP 전송 관리 시스템 또는 운영체제를 사용하여 전송 요청 파일을 가져올 수 있습니다.
SAP 전송 관리 시스템
- SAP 시스템에 SAP 관리자로 로그인합니다.
- 트랜잭션 STMS를 입력합니다.
- 개요 > 가져오기를 클릭합니다.
- 대기열 열에서 현재 SID를 더블클릭합니다.
- 기타 > 기타 요청 > 추가를 클릭합니다.
- 전송 요청 ID를 선택하고 계속을 클릭합니다.
- 가져오기 큐에서 전송 요청을 선택한 다음 요청 > 가져오기를 클릭합니다.
- 클라이언트 번호를 입력합니다.
옵션 탭에서 원본 덮어쓰기 및 잘못된 구성요소 버전 무시(가능한 경우)를 선택합니다.
(선택사항) 나중에 전송을 다시 가져오려면 나중에 가져올 수 있도록 큐에 전송 요청 두기 및 전송 요청 다시 가져오기를 클릭합니다. 이는 SAP 시스템 업그레이드 및 백업 복원에 유용합니다.
계속을 클릭합니다.
SE80및PFCG과 같은 트랜잭션을 사용하여 함수 모듈 및 승인 역할을 성공적으로 가져왔는지 확인합니다.
운영체제
- SAP 시스템에 SAP 관리자로 로그인합니다.
가져오기 버퍼에 요청을 추가합니다.
tp addtobuffer TRANSPORT_REQUEST_ID SID예를 들면
tp addtobuffer IB1K903958 DD1입니다.전송 요청을 가져옵니다.
tp import TRANSPORT_REQUEST_ID SID client=NNN U1238NNN을 클라이언트 번호로 바꿉니다. 예:tp import IB1K903958 DD1 client=800 U1238SE80및PFCG과 같은 적절한 트랜잭션을 사용하여 함수 모듈 및 승인 역할을 성공적으로 가져왔는지 확인합니다.
필수 SAP 승인
Cloud Data Fusion에서 데이터 파이프라인을 실행하려면 SAP 사용자가 필요합니다. SAP 사용자는 통신 또는 대화 유형이어야 합니다. SAP 대화 리소스 사용을 방지하려면 통신 유형을 사용하는 것이 좋습니다. SAP 트랜잭션 코드 SU01을 사용하여 SAP 관리자가 사용자를 만들 수 있습니다.
SAP 표준 및 신규 커넥터 승인 객체의 조합으로 SAP용 커넥터를 유지보수하고 구성하려면 SAP 승인이 필요합니다. 조직의 보안 정책에 따라 승인 객체를 유지보수합니다. 다음 목록에서는 커넥터에 필요한 중요한 승인을 설명합니다.
승인 객체: 승인 객체
ZGOOGCDFMT는 전송 요청 역할의 일부로 제공됩니다.역할 만들기: 트랜잭션 코드
PFCG를 사용하여 역할을 만듭니다.
표준 SAP 승인 객체의 경우 조직에서 자체 보안 메커니즘을 사용하여 권한을 관리합니다.
커스텀 승인 객체의 경우 승인 객체
ZGOOGCDFMT의 승인 필드에 값을 제공합니다.세분화된 액세스 제어를 위해
ZGOOGCDFMT에서 승인 그룹 기반 승인을 제공합니다. 승인 그룹에 대한 완전한 액세스 권한 또는 부분적 액세스 권한이 있거나 액세스 권한이 없는 사용자에게 역할에 할당된 승인 그룹에 따라 액세스 권한이 제공됩니다./GOOG/SLT_CDF_AUTH: 모든 승인 그룹에 대해 액세스 권한이 있는 역할입니다. 특정 승인 그룹과 관련된 액세스를 제한하려면 구성에서 승인 그룹 FICDF를 유지보수합니다.
소스의 RFC 대상 만들기
구성을 시작하기 전 소스와 대상 사이에 RFC 연결이 설정되었는지 확인합니다.
SM59트랜잭션 코드로 이동합니다.만들기 > 연결 유형 3(ABAP 연결)을 클릭합니다.
기술 설정 창에서 RFC 대상에 대한 세부정보를 입력합니다.
로그온 및 보안 탭을 클릭하여 RFC 사용자 인증 정보(RFC 사용자 및 비밀번호)를 유지합니다.
저장을 클릭합니다.
Connection Test(연결 테스트)를 클릭합니다. 테스트가 성공적으로 완료된 후 계속 진행할 수 있습니다.
RFC 승인 테스트가 성공했는지 확인합니다.
유틸리티 > 테스트 > 승인 테스트를 클릭합니다.
플러그인 구성
플러그인을 구성하려면 허브에서 플러그인을 배포하고, 복제 작업을 만들고, 다음 단계에 따라 소스와 대상을 구성합니다.
Cloud Data Fusion에 플러그인 배포
Cloud Data Fusion 사용자가 다음 단계를 수행합니다.
Cloud Data Fusion 복제 작업을 실행하려면 먼저 SAP SLT Replication 플러그인을 배포합니다.
인스턴스로 이동합니다.
Google Cloud 콘솔에서 Cloud Data Fusion 인스턴스 페이지를 엽니다.
새 인스턴스 또는 기존 인스턴스에 복제를 사용 설정합니다.
- 새 인스턴스의 경우 인스턴스 만들기를 클릭하고 인스턴스 이름을 입력한 후 가속기 추가를 클릭하고 복제 체크박스를 선택한 다음 저장을 클릭합니다.
- 기존 인스턴스의 경우 기존 인스턴스에 복제 사용 설정을 참조하세요.
인스턴스 보기를 클릭하여 Cloud Data Fusion 웹 인터페이스에서 인스턴스를 엽니다.
허브를 클릭합니다.
다음으로 이동하세요. SAP 탭에서 SAP SLT 를 클릭하고 SAP SLT Replication 플러그인 또는 SAP SLT No RFC Replication 플러그인 값을 반환합니다.
배포를 클릭합니다.
복제 작업 만들기
SAP SLT Replication 플러그인은 Cloud Storage API 스테이징 버킷을 사용하여 SAP 테이블의 콘텐츠를 읽습니다.
데이터 전송을 위한 복제 작업을 만들려면 다음 단계를 따르세요.
열린 Cloud Data Fusion 인스턴스에서 홈 > 복제 > 복제 작업 만들기를 클릭합니다. 복제 옵션이 없으면 인스턴스에 복제를 사용 설정합니다.
복제 작업의 고유한 이름 및 설명을 입력합니다.
다음을 클릭합니다.
소스 구성
다음 필드에 값을 입력하여 소스를 구성합니다.
- 프로젝트 ID: Google Cloud 프로젝트의 ID입니다(이 필드는 미리 채워져 있음).
데이터 복제 GCS 경로: 복제할 데이터가 포함된 Cloud Storage 경로입니다. SAP SLT 작업에서 구성된 경로와 동일한 경로여야 합니다. 내부적으로 제공된 경로는
Mass Transfer ID및Source Table Name과 연결됩니다.형식:
gs://<base-path>/<mass-transfer-id>/<source-table-name>예:
gs://slt_bucket/012/MARAGUID: SLT GUID로 SAP SLT 대량 전송 ID에 할당된 고유 식별자입니다.
대량 전송 ID: SLT 대량 전송 ID로 SAP SLT의 구성에 할당된 고유 식별자입니다.
SAP JCo 라이브러리 GCS 경로: 사용자가 업로드한 SAP JCo 라이브러리 파일을 포함하는 Cloud Storage 경로입니다. SAP JCo 라이브러리는 SAP 지원 포털에서 다운로드할 수 있습니다. (플러그인 버전 0.10.0에서 삭제됨)
SLT 서버 호스트: SLT Server 호스트 이름 또는 IP 주소입니다. (플러그인 버전 0.10.0에서 삭제됨)
SAP 시스템 번호: 시스템 관리자가 제공하는 설치 시스템 번호입니다(예:
00). (플러그인 버전 0.10.0에서 삭제됨)SAP 클라이언트: 사용할 SAP 클라이언트입니다(예:
100). (플러그인 버전 0.10.0에서 삭제됨)SAP 언어: SAP 로그온 언어입니다(예:
EN). (플러그인 버전 0.10.0에서 삭제됨)SAP 로그온 사용자 이름: SAP 사용자 이름입니다. (플러그인 버전 0.10.0에서 삭제됨)
- 권장: SAP 로그온 사용자 이름이 주기적으로 변경되는 경우 매크로를 사용하세요.
SAP 로그온 비밀번호(M): 사용자 인증을 위한 SAP 사용자 비밀번호입니다.
- 권장: 비밀번호와 같은 민감한 값에 보안 매크로를 사용하세요. (플러그인 버전 0.10.0에서 삭제됨)
CDF 작업이 중지될 때 SLT 복제 정지: Cloud Data Fusion 복제 작업이 중지될 때 관련된 테이블에 대해 SLT 복제 작업을 중지하려고 시도합니다. Cloud Data Fusion의 작업이 예기치 않게 중지되면 실패할 수 있습니다.
기존 데이터 복제: 소스 테이블에서 기존 데이터를 복제할지 여부를 나타냅니다. 기본적으로 이 작업은 소스 테이블의 기존 데이터를 복제합니다.
false로 설정하면 소스 테이블의 기존 데이터가 무시되고 작업이 시작된 후 발생한 변경사항만 복제됩니다.서비스 계정 키: Cloud Storage와 상호작용할 때 사용하는 키입니다. 서비스 계정에 Cloud Storage에 쓸 수 있는 권한이 있어야 합니다. Google Cloud VM에서 실행하는 경우
auto-detect로 설정하여 VM에 연결된 서비스 계정을 사용해야 합니다.
다음을 클릭합니다.
대상 구성
BigQuery에 데이터를 기록하기 위해서는 플러그인에 BigQuery 및 스테이징 버킷 모두에 대한 쓰기 액세스 권한이 필요합니다. 변경 이벤트는 먼저 SLT에서 Cloud Storage로 일괄로 기록됩니다. 그런 후 BigQuery의 스테이징 테이블에 로드됩니다. 스테이징 테이블의 변경사항은 BigQuery 병합 쿼리를 사용하여 최종 대상 테이블에 병합됩니다.
최종 대상 테이블에는 소스 테이블의 모든 원본 열과 추가 _sequence_num 열 하나가 포함됩니다. 시퀀스 넘버로 복제기 장애 시나리오에서 데이터가 중복되거나 누락되지 않도록 보장합니다.
다음 필드에 값을 입력하여 소스를 구성합니다.
- 프로젝트 ID: BigQuery 데이터 세트의 프로젝트입니다. 클러스터의 프로젝트를 사용하는 Dataproc 클러스터에서 실행할 때는 이 필드를 비워 둘 수 있습니다.
- 사용자 인증 정보: 사용자 인증 정보를 참조하세요.
- 서비스 계정 키: Cloud Storage 및 BigQuery와 상호 작용할 때 사용하는 서비스 계정 키의 콘텐츠입니다. Dataproc 클러스터에서 실행하는 경우 이 필드를 비워서 클러스터의 서비스 계정을 사용해야 합니다.
- 데이터 세트 이름: BigQuery에서 만들 데이터 세트의 이름입니다. 선택사항이며 기본적으로 데이터 세트 이름은 소스 데이터베이스 이름과 동일합니다. 유효한 이름은 문자, 숫자, 밑줄만 포함해야 하며, 최대 길이는 1024자까지 가능합니다. 잘못된 문자는 최종 데이터 세트 이름에서 밑줄로 바뀌고 길이 제한을 초과하는 문자는 잘립니다.
- 암호화 키 이름: 이 대상으로 생성된 리소스를 보호하기 위해 사용되는 고객 관리 암호화 키(CMEK)입니다. 암호화 키 이름은
projects/<project-id>/locations/<key-location>/keyRings/<key-ring-name>/cryptoKeys/<key-name>형식이어야 합니다. - 위치: BigQuery 데이터 세트 및 Cloud Storage 스테이징 버킷이 생성되는 위치입니다. 예를 들어 리전 버킷의 경우에는
us-east1이고, 멀티 리전 버킷의 경우에는us입니다(위치 참조). 기존 버킷이 지정된 경우 스테이징 버킷과 BigQuery 데이터 세트가 해당 버킷과 동일한 위치에 생성되므로 이 값이 무시됩니다. 스테이징 버킷: 스테이징 테이블에 로드되기 전에 변경 이벤트가 기록되는 버킷입니다. 복제기 이름 및 네임스페이스가 포함된 디렉터리에 변경사항이 기록됩니다. 동일한 인스턴스 내의 여러 복제기에서 동일한 버킷을 사용하는 것이 안전합니다. 여러 인스턴스에서 복제기가 이를 공유하는 경우 네임스페이스와 이름이 고유해야 합니다. 그렇지 않으면 동작이 정의되지 않습니다. 버킷은 BigQuery 데이터 세트와 같은 위치에 있어야 합니다. 버킷이 제공되지 않을 경우 작업마다
df-rbq-<namespace-name>-<job-name>-<deployment-timestamp>라는 이름의 새 버킷이 생성됩니다.로드 간격(초): 데이터 일괄 처리를 BigQuery에 로드하기 전에 기다리는 시간(초)입니다.
스테이징 테이블 프리픽스: 최종 테이블에 병합되기 전 변경사항이 먼저 스테이징 테이블에 기록됩니다. 대상 테이블 이름에 이 프리픽스를 추가하여 스테이징 테이블 이름이 생성됩니다.
수동 삭제 개입 필요: 테이블 삭제 또는 데이터베이스 삭제 이벤트가 발생할 때 테이블 및 데이터베이스 삭제를 위해 수동 관리 작업이 필요한지 여부입니다. true로 설정하면 복제자가 테이블 또는 데이터 세트를 삭제하지 않습니다. 대신 작업이 실패하고 테이블 또는 데이터 세트가 존재하지 않을 때까지 재시도됩니다. 데이터 세트 또는 테이블이 없으면 수동 개입이 필요하지 않습니다. 정상 상태에서는 이 이벤트를 건너뜁니다.
소프트 삭제 사용 설정: true로 설정하면 대상이 삭제 이벤트를 수신할 때 레코드의
_is_deleted열이true로 설정됩니다. 그렇지 않으면 BigQuery 테이블에서 레코드가 삭제됩니다. 이 구성은 잘못된 순서로 이벤트를 생성하고 항상 BigQuery 테이블에서 소프트 삭제되는 소스의 노옵스(no-ops)입니다.
다음을 클릭합니다.
사용자 인증 정보
플러그인이 Dataproc 클러스터에서 실행되는 경우 서비스 계정 키를 자동 감지로 설정해야 합니다. 사용자 인증 정보는 클러스터 환경에서 자동으로 읽혀집니다.
플러그인이 Dataproc 클러스터에서 실행되지 않으면 서비스 계정 키에 대한 경로를 제공해야 합니다. 서비스 계정 키는 Google Cloud 콘솔의 IAM 페이지에서 찾을 수 있습니다. 계정 키에 BigQuery 액세스 권한이 있는지 확인합니다. 서비스 계정 키 파일은 클러스터의 모든 노드에서 사용할 수 있어야 하며 작업을 실행하는 모든 사용자가 읽을 수 있어야 합니다.
제한사항
- 테이블에 복제할 기본 키가 있어야 합니다.
- 테이블 이름 변경 작업은 지원되지 않습니다.
- 테이블 변경은 부분적으로 지원됩니다.
- 기존 null 비허용 열은 null 허용 열로 변경할 수 있습니다.
- 새 null 허용 열을 기존 테이블에 추가할 수 있습니다.
- 테이블 스키마에 대한 다른 유형의 변경은 실패합니다.
- 기본 키 변경은 실패하지 않지만 새 기본 키의 고유성을 준수하도록 기존 데이터가 다시 작성되지 않습니다.
테이블 및 변환 선택
테이블 및 변환 선택 단계에서 SLT 시스템에서 복제하도록 선택된 테이블의 목록이 표시됩니다.
- 복제할 테이블을 선택합니다.
- 선택사항: 삽입, 업데이트, 삭제와 같은 스키마 작업을 추가로 선택합니다.
- 스키마를 보려면 테이블의 복제할 열을 클릭합니다.
선택사항: 스키마에서 열 이름을 바꾸려면 다음 단계를 따르세요.
- 스키마가 표시된 상태에서 변환 > 이름 바꾸기를 클릭합니다.
- 이름 바꾸기 필드에 새 이름을 입력하고 적용을 클릭합니다.
- 새 이름을 저장하려면 새로고침과 저장을 클릭합니다.
다음을 클릭합니다.
선택사항: 고급 속성 구성
한 시간 동안 복제하는 데이터 양을 알고 있으면 적합한 옵션을 선택할 수 있습니다.
평가 검토
평가 검토 단계에서는 복제 중에 발생할 수 있는 스키마 문제, 누락된 특성 또는 연결 문제를 검사합니다.
평가 검토 페이지에서 매핑 보기를 클릭합니다.
문제가 발생한 경우 해결 후 계속 진행해야 합니다.
선택사항: 테이블 및 변환을 선택할 때 열 이름을 바꾼 경우 이 단계에서 새 이름이 올바른지 확인합니다.
다음을 클릭합니다.
요약 보기 및 복제 작업 배포
복제 작업 세부정보 검토 페이지에서 설정을 검토하고 복제 작업 배포를 클릭합니다.
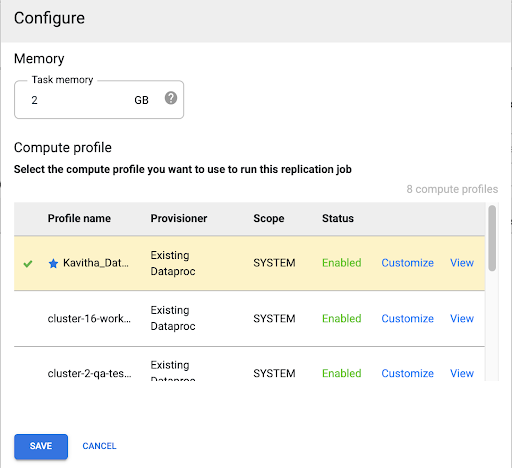
Compute Engine 프로필 선택
복제 작업을 배포한 후 Cloud Data Fusion 웹 인터페이스의 아무 페이지에서나 구성을 클릭합니다.
이 복제 작업을 실행하는 데 사용할 Compute Engine 프로필을 선택합니다.
저장을 클릭합니다.
복제 작업 시작
- 복제 작업을 실행하려면 시작을 클릭합니다.
선택사항: 성능 최적화
기본적으로 플러그인은 최적 성능을 위해 구성됩니다. 추가적인 최적화를 위해서는 런타임 인수를 참조하세요.
SLT 및 Cloud Data Fusion 통신의 성능은 다음 항목에 따라 달라집니다.
- 소스 시스템의 SLT 또는 전용 중앙 SLT 시스템(권장 옵션)
- SLT 시스템의 백그라운드 작업 처리
- 소스 SAP 시스템의 대화 작업 프로세스
- LTRC 관리 탭의 각 Mass Transfer ID에 할당된 백그라운드 작업 프로세스 수
- LTRS 설정
- SLT 시스템의 하드웨어(CPU 및 메모리)
- 사용된 데이터베이스(예: HANA, Sybase, DB2)
- 인터넷 대역폭(인터넷을 통한 SAP 시스템과 Google Cloud 간의 연결)
- 시스템의 기존 사용률(로드)
- 테이블의 열 수입니다. 열이 많을수록 복제가 느려지고 지연 시간이 늘어날 수 있습니다.
초기 로드의 경우 LTRS 설정에서 다음 읽기 유형이 권장됩니다.
| SLT 시스템 | 소스 시스템 | 테이블 유형 | 권장되는 읽기 유형 [초기 로드] |
|---|---|---|---|
| SLT 3.0 독립형 [DMIS 2018_1_752 SP 2] |
S/4 HANA 1909 | 투명성(소형/중간) 투명(대형) 클러스터 테이블 |
1 범위 계산 1 범위 계산 4 발신자 큐 |
| SLT 삽입 [S4CORE 104 HANA 1909] |
해당 사항 없음 | 투명성(소형/중간) 투명(대형) 클러스터 테이블 |
1 범위 계산 1 범위 계산 4 발신자 큐 |
| SLT 2.0 독립형 [DMIS 2011_1_731 SP 17] |
ECC NW 7.02 | 투명성(소형/중간) 투명(대형) 클러스터 테이블 |
발신자 큐 5개 발신자 큐 5개 발신자 큐 4개 |
| SLT 삽입됨 [DMIS 2011_1_700 SP 17] |
해당 사항 없음 | 투명성(소형/중간) 투명(대형) 클러스터 테이블 |
발신자 큐 5개 발신자 큐 5개 발신자 큐 4개 |
- 복제의 경우 성능 향상을 위해 범위 없음을 사용합니다.
- 범위는 지연 시간인 높은 로깅 테이블에 백로그가 생성될 때만 사용해야 합니다.
- 범위 1개 계산 사용: SLT 2.0 및 HANA가 아닌 시스템의 경우 초기 로드에는 읽기 유형을 사용하지 않는 것이 좋습니다.
- 범위 1개 계산 사용: 초기 로드의 읽기 유형으로 인해 BigQuery에서 레코드가 중복될 수 있습니다.
- 독립형 SLT 시스템을 사용하면 성능이 향상됩니다.
- 소스 시스템의 리소스 사용률이 이미 높은 경우 독립형 SLT 시스템을 사용하는 것이 좋습니다.
런타임 인수
snapshot.thread.count:SNAPSHOT/INITIAL데이터 로드를 병렬로 수행하기 위해 스레드 수를 전달합니다. 기본적으로 복제 작업이 실행되는 Dataproc 클러스터에서 사용 가능한 vCPU 수가 사용됩니다.권장: 병렬 스레드 수를 정확하게 제어해야 할 경우에만 이 매개변수를 설정합니다(예: 클러스터의 사용량 감소).
poll.file.count: 웹 인터페이스에서 데이터 복제 GCS 경로 필드에 제공된 Cloud Storage 경로에서 가져올 파일 수를 전달합니다. 기본적으로 값은 가져오기당500이지만 클러스터 구성에 따라 늘리거나 줄일 수 있습니다.권장: 복제 지연에 대한 요구사항이 엄격한 경우에만 이 매개변수를 설정합니다. 값이 낮을수록 지연 시간이 줄어들 수 있습니다. 처리량 향상을 위해 사용할 수 있습니다(응답이 없으면 기본값보다 높은 값 사용).
bad.files.base.path: 복제 중 발견된 모든 오류 또는 잘못된 데이터 파일이 복사되는 기본 Cloud Storage 경로를 전달합니다. 이 방법은 데이터 감사에 대한 요구사항이 엄격하고 실패한 전송을 기록하기 위해 특정 위치를 사용해야 할 경우에 유용합니다.기본적으로 모든 잘못된 파일은 웹 인터페이스에서 데이터 복제 Cloud Storage 경로 필드에 제공된 Cloud Storage 경로에서 복사됩니다.
잘못된 데이터 파일 최종 경로 패턴:
gs://BASE_FILE_PATH/MASS_TRANSFER_ID/SOURCE_TABLE_NAME/bad_files/REPLICATION_JOB_NAME/REPLICATION_JOB_ID/BAD_FILE_NAME
예를 들면 다음과 같습니다.
gs://slt_to_cdf_bucket/001/MARA/bad_files/MaraRepl/05f97349-7398-11ec-9443-8 ac0640fc83c/20220205_1901205168830_DATA_INIT.xml
잘못된 파일의 기준은 손상되었거나 부적합한 XML 파일, 누락된 PK 값, 필드 데이터 유형 불일치 문제입니다.
지원 세부정보
지원되는 SAP 제품 및 버전
- SAP_BASIS 702 출시 버전, SP-Level 0016 이상
- SAP_ABA 702 출시 버전, SP-Level 0016 이상
- DMIS 2011_1_700 출시 버전, SP-Level 0017 이상
지원되는 SLT 버전
SLT 버전 2 및 3이 지원됩니다.
지원되는 SAP 배포 모델
독립형 시스템 SLT 또는 소스 시스템에 삽입된 SLT입니다.
SLT를 사용하기 전 구현해야 하는 SAP Note
서포트 패키지에 PL 12 이상을 위한 /UI2/CL_JSON 클래스 수정 사항이 포함되지 않은 경우 /UI2/CL_JSON 클래스 수정을 위한 최신 SAP Note(예: PL12용 SAP Note 2798102)를 구현합니다.
권장: 중앙 또는 소스 시스템 조건에 따라 CNV_NOTE_ANALYZER_SLT 보고서에서 권장되는 SAP Note를 구현합니다. 자세한 내용은 SAP Note 3016862를 참조하세요(SAP 로그인 필요).
SAP가 이미 설정된 경우에는 추가 note를 구현할 수 없습니다. 특정 오류 또는 문제가 있으면 해당 SLT 출시 버전의 중앙 SAP Note를 참조하세요.
데이터 볼륨 또는 레코드 너비 제한
추출된 데이터 볼륨 및 레코드 너비에 정의된 한도는 없습니다.
SAP SLT Replication 플러그인의 예상 처리량
성능 최적화의 가이드라인에 따라 구성된 환경의 경우 이 플러그인은 초기 로드 의 경우 시간당 약 13GB, 복제(CDC)의 경우 시간당 3GB를 추출할 수 있습니다. 실제 성능은 Cloud Data Fusion 및 SAP 시스템 로드 또는 네트워크 트래픽에 따라 달라질 수 있습니다.
SAP 델타(변경된 데이터) 추출 지원
SAP 델타 추출이 지원됩니다.
필수: Cloud Data Fusion 인스턴스에 대한 테넌트 피어링
내부 IP 주소로 Cloud Data Fusion 인스턴스를 만들 때는 테넌트 피어링이 필요합니다. 테넌트 피어링에 대한 자세한 내용은 비공개 인스턴스 만들기를 참조하세요.
문제 해결
복제 작업이 계속 다시 시작됨
복제 작업이 자동으로 계속 다시 시작되면 복제 작업 클러스터 메모리를 늘리고 복제 작업을 다시 실행합니다.
BigQuery 싱크의 중복
SAP SLT Replication 플러그인의 고급 설정에서 동시 작업 수를 정의하는 경우 테이블이 크면 BigQuery 싱크에 열이 중복되는 오류가 발생합니다.
문제를 방지하려면 데이터를 로드할 때 동시 작업을 삭제합니다.
오류 시나리오
다음 표는 일반적인 오류 메시지를 보여줍니다(런타임 시 따옴표 안의 텍스트가 실제 값으로 대체됨).
| 메시지 ID | 메시지 | 권장 조치 |
|---|---|---|
CDF_SAP_SLT_01402 |
Service account type is not defined for
SERVICE_ACCT_NAME_FROM_UI. |
제공된 Cloud Storage 경로가 올바른지 확인합니다. |
CDF_SAP_SLT_01403 |
Service account key provided is not valid due to error:
ROOT_CAUSE. Please provide a valid service account key for
service account type : SERVICE_ACCT_NAME_FROM_UI. |
메시지에 표시된 근본 원인을 확인하고 적절한 조치를 취합니다. |
CDF_SAP_SLT_01404 |
Mass Transfer ID could not be found. Please ensure that it exists
in given GCS Bucket. |
대량 전송 ID가 올바른 형식인지 확인합니다. |
CDF_SAP_SLT_01502 |
The specified data replication GCS path 'slt_to_cdf_bucket_1' or
Mass Transfer ID '05C' could not be found. Please ensure that it exists in
GCS. |
제공된 Cloud Storage 경로가 올바른지 확인합니다. |
CDF_SAP_SLT_01400 |
Metadata file not found. The META_INIT.json file is not present or
file is present with invalid format. |
메시지에 표시된 근본 원인을 확인하고 적절한 조치를 취합니다. |
CDF_SAP_SLT_03408 |
Failed to start the event reader. |
메시지에 표시된 근본 원인을 확인하고 적절한 조치를 취합니다. |
CDF_SAP_SLT_03409 |
Error while processing TABLE_NAME file for source table
gs://CLOUD_STORAGE_BUCKET_NAME/MT_ID/TABLE_NAME
/FILE_NAME. Root cause: ROOT_CAUSE. |
메시지에 표시된 근본 원인을 확인하고 적절한 조치를 취합니다. |
CDF_SAP_SLT_03410 |
Failed to replicate data for source table TABLE_NAME
from file: gs://CLOUD_STORAGE_BUCKET_NAME/MT_ID/
TABLE_NAME/FILE_NAME. Root cause:
ROOT_CAUSE. |
메시지에 표시된 근본 원인을 확인하고 적절한 조치를 취합니다. |
CDF_SAP_SLT_03411 |
Failed data replication for source table TABLE_NAME.
Root cause: ROOT_CAUSE. |
메시지에 표시된 근본 원인을 확인하고 적절한 조치를 취합니다. |
CDF_SAP_SLT_03412 |
Failed to create target table for source table
TABLE_NAME. Root cause: ROOT_CAUSE. |
메시지에 표시된 근본 원인을 확인하고 적절한 조치를 취합니다. |
데이터 유형 매핑
다음 표에서는 SAP 애플리케이션과 Cloud Data Fusion에 사용되는 데이터 유형 간의 매핑을 보여줍니다.
| SAP 데이터 유형 | ABAP 유형 | 설명(SAP) | Cloud Data Fusion 데이터 유형 |
|---|---|---|---|
| 숫자 | |||
| INT1 | b | 1바이트 정수 | int |
| INT2 | s | 2바이트 정수 | int |
| INT4 | i | 4바이트 정수 | int |
| INT8 | 8 | 8바이트 정수 | long |
| 12월 | p | BCD 형식의 압축 번호(DEC) | decimal |
| DF16_DEC DF16_RAW |
a | 10진 부동 소수점 8바이트 IEEE 754r | decimal |
| DF34_DEC DF34_RAW |
e | 10진 부동 소수점 16바이트 IEEE 754r | decimal |
| FLTP | f | 바이너리 부동 소수점 수 | double |
| 문자 | |||
| CHAR LCHR |
c | 문자열 | string |
| SSTRING GEOM_EWKB |
문자열 | 문자열 | string |
| STRING GEOM_EWKB |
문자열 | 문자열 CLOB | bytes |
| NUMC ACCP |
n | 숫자 텍스트 | string |
| 바이트 | |||
| RAW LRAW |
x | 바이너리 데이터 | bytes |
| RAWSTRING | xstring | 바이트 문자열 BLOB | bytes |
| 날짜/시간 | |||
| DATS | d | 날짜 | date |
| 시간 | t | 시간 | time |
| TIMESTAMP | utcl | ( Utclong ) 타임 스탬프 |
timestamp |
다음 단계
- Cloud Data Fusion 자세히 알아보기
- Google Cloud 기반 SAP 자세히 알아보기