En esta página, se describe cómo ejecutar transformaciones en BigQuery en lugar de en Spark en Cloud Data Fusion.
Para obtener más información, consulta la Descripción general del envío de transformaciones.
Antes de comenzar
El envío de transformaciones está disponible en la versión 6.5.0 y en las posteriores. Si tu canalización se ejecuta en un entorno anterior, puedes actualizar tu instancia a la versión más reciente.
Habilita el envío de transformaciones en tu canalización
Console
Para habilitar el envío de transformaciones en una canalización implementada, haz lo siguiente:
Ve a tu instancia:
En la Google Cloud consola, ve a la página de Cloud Data Fusion.
Para abrir la instancia en Cloud Data Fusion Studio, haz clic en Instancias y, luego, en Ver instancia.
Haz clic en Menú > Lista.
Se abrirá la pestaña de canalización implementada.
Haz clic en la canalización implementada que desees para abrirla en Pipeline Studio.
Haz clic en Configurar > Envío de transformaciones.
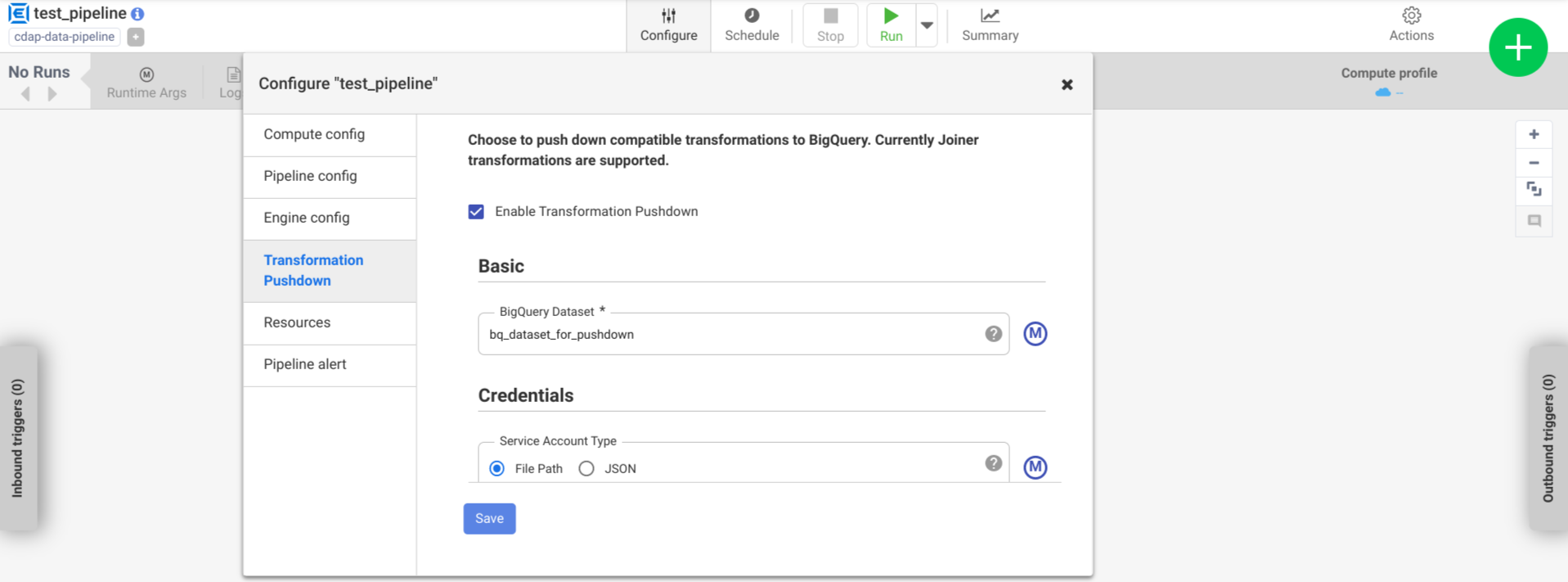
Haz clic en Habilitar el envío de transformaciones.
En el campo Conjunto de datos, ingresa un nombre de conjunto de datos de BigQuery.
Opcional: Para usar una macro, haz clic en M. Para obtener más información, consulta Conjuntos de datos.
Opcional: Configura las opciones si es necesario.
Haz clic en Guardar.
Configuración opcional
.| Propiedad | Admite macros | Versiones compatibles de Cloud Data Fusion | Descripción |
|---|---|---|---|
| Cómo usar la conexión | No | 6.7.0 y versiones posteriores | Si se debe usar una conexión existente. |
| Conexión | Sí | 6.7.0 y versiones posteriores | Es el nombre de la conexión. Esta conexión proporciona información del proyecto y
de la cuenta de servicio. Opcional: Usa la macro de la función, ${conn(connection_name)}. |
| ID del proyecto del conjunto de datos | Sí | 6.5.0 | Si el conjunto de datos se encuentra en un proyecto diferente al en el que se ejecuta el trabajo de BigQuery, ingresa el ID del proyecto del conjunto de datos. Si no se proporciona ningún valor, de forma predeterminada, se usa el ID del proyecto en el que se ejecuta la tarea. |
| ID del proyecto | Sí | 6.5.0 | El Google Cloud ID del proyecto. |
| Tipo de cuenta de servicio | Sí | 6.5.0 | Selecciona una de las siguientes opciones:
|
| Ruta de acceso al archivo de la cuenta de servicio | Sí | 6.5.0 | Es la ruta de acceso del sistema de archivos local a la clave de la cuenta de servicio que se usa para la autorización. Se establece en auto-detect cuando se ejecuta en un clúster de Dataproc. Cuando se ejecuta en otros clústeres, el archivo debe estar presente en cada nodo en el clúster. El valor predeterminado es auto-detect. |
| JSON de la cuenta de servicio | Sí | 6.5.0 | Es el contenido del archivo JSON de la cuenta de servicio. |
| Nombre del bucket temporal | Sí | 6.5.0 | El bucket de Cloud Storage que almacena los datos temporales Si no existe, se crea de forma automática, pero no se borra de forma automática. Los datos de Cloud Storage se borran después de cargarlos en BigQuery. Si no se proporciona este valor, se crea un bucket único y, luego, se lo borra después de que finaliza la ejecución de la canalización. La cuenta de servicio debe tener permiso para crear buckets en el proyecto configurado. |
| Ubicación | Sí | 6.5.0 | Es la ubicación en la que se crea el conjunto de datos de BigQuery.
Este valor se ignora si el conjunto de datos o el bucket temporal ya existe. La opción predeterminada es la multirregión US. |
| Nombre de clave de encriptación | Sí | 6.5.1/0.18.1 | La clave de encriptación administrada por el cliente (CMEK) que encripta los datos escritos en cualquier bucket, conjunto de datos o tabla que creó el complemento. Si el bucket, el conjunto de datos o la tabla ya existe, este valor se ignora. |
| Retención de tablas de BigQuery después de la finalización | Sí | 6.5.0 | Indica si se deben conservar todas las tablas temporales de BigQuery que se crean durante la ejecución de la canalización con fines de depuración y validación. El valor predeterminado es No. |
| TTL de la tabla temporal (en horas) | Sí | 6.5.0 | Establece el TTL de la tabla para las tablas temporales de BigQuery, en horas. Esto es útil como un sistema a prueba de fallas en caso de que se cancele la canalización y se interrumpa el proceso de limpieza (por ejemplo, si el clúster de ejecución se cierra de forma abrupta). Si configuras este valor como 0, se inhabilita el TTL de la tabla. El valor predeterminado es 72 (3 días). |
| Prioridad del trabajo | Sí | 6.5.0 | Es la prioridad que se usa para ejecutar trabajos de BigQuery. Selecciona una de las siguientes opciones:
|
| Etapas para forzar la transferencia | Sí | 6.7.0 | Son las etapas compatibles para ejecutar siempre en BigQuery. Cada nombre de etapa debe estar en una línea separada. |
| Etapas para omitir la transferencia | Sí | 6.7.0 | Etapas compatibles que nunca se ejecutarán en BigQuery. Cada nombre de etapa debe estar en una línea separada. |
| Usa la API de BigQuery Storage Read | Sí | 6.7.0 | Si se debe usar la API de BigQuery Storage Read cuando se extraen registros de BigQuery durante la ejecución de la canalización Esta opción puede mejorar el rendimiento de la transferencia de transformaciones, pero genera costos adicionales. Esto requiere que Scala 2.12 esté instalado en el entorno de ejecución. |
Supervisa los cambios de rendimiento en los registros
Los registros del entorno de ejecución de la canalización incluyen mensajes que muestran las consultas de SQL que se ejecutan en BigQuery. Puedes supervisar qué etapas de la canalización se envían a BigQuery.
En el siguiente ejemplo, se muestran las entradas de registro cuando comienza la ejecución de la canalización. Los registros indican que las operaciones de JOIN en tu canalización se enviaron a BigQuery para su ejecución:
INFO [Driver:i.c.p.g.b.s.BigQuerySQLEngine@190] - Validating join for stage 'Users' can be executed on BigQuery: true
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@131] - Starting push for dataset 'UserProfile'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@131] - Starting push for dataset 'UserDetails'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@292] - Starting join for dataset 'Users'
INFO [Driver:i.c.p.g.b.s.BigQuerySQLEngine@190] - Validating join for stage 'UserPurchases' can be executed on BigQuery: true
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@131] - Starting push for dataset 'Purchases'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@292] - Starting join for dataset 'UserPurchases'
INFO [Driver:i.c.p.g.b.s.BigQuerySQLEngine@190] - Validating join for stage 'MostPopularNames' can be executed on BigQuery: true
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@131] - Starting push for dataset 'FirstNameCounts'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@292] - Starting join for dataset 'MostPopularNames'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@193] - Starting pull for dataset 'MostPopularNames'
En el siguiente ejemplo, se muestran los nombres de las tablas que se asignarán a cada uno de los conjuntos de datos involucrados en la ejecución de envío:
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@145] - Executing Push operation for dataset Purchases stored in table <TABLE_ID>
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@145] - Executing Push operation for dataset UserDetails stored in table <TABLE_ID>
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@145] - Executing Push operation for dataset FirstNameCounts stored in table <TABLE_ID>
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@145] - Executing Push operation for dataset UserProfile stored in table <TABLE_ID>
A medida que la ejecución continúa, los registros muestran la finalización de las etapas de envío y, finalmente, la ejecución de las operaciones de JOIN. Por ejemplo:
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@133] - Completed push for dataset 'UserProfile'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@133] - Completed push for dataset 'UserDetails'
DEBUG [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@235] - Executing join operation for dataset Users
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQueryJoinDataset@118] - Creating table `<TABLE_ID>` using job: <JOB_ID> with SQL statement: SELECT `UserDetails`.id AS `id` , `UserDetails`.first_name AS `first_name` , `UserDetails`.last_name AS `last_name` , `UserDetails`.email AS `email` , `UserProfile`.phone AS `phone` , `UserProfile`.profession AS `profession` , `UserProfile`.age AS `age` , `UserProfile`.address AS `address` , `UserProfile`.score AS `score` FROM `your_project.your_dataset.<DATASET_ID>` AS `UserProfile` LEFT JOIN `your_project.your_dataset.<DATASET_ID>` AS `UserDetails` ON `UserProfile`.id = `UserDetails`.id
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQueryJoinDataset@151] - Created BigQuery table `<TABLE_ID>
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@245] - Executed join operation for dataset Users
Cuando se hayan completado todas las etapas, aparecerá un mensaje que indicará que se completó la operación Pull. Esto indica que se activó el proceso de exportación de BigQuery y que los registros comenzarán a leerse en la canalización después de que comience este trabajo de exportación. Por ejemplo:
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@196] - Completed pull for dataset 'MostPopularNames'
Si la ejecución de la canalización encuentra errores, estos se describen en los registros.
Para obtener detalles sobre la ejecución de las operaciones JOIN de BigQuery, como el uso de recursos, el tiempo de ejecución y las causas de los errores, puedes ver los datos del trabajo de BigQuery con el ID del trabajo, que aparece en los registros del trabajo.
Revisa las métricas de la canalización
Para obtener más información sobre las métricas que proporciona Cloud Data Fusion para la parte de la canalización que se ejecuta en BigQuery, consulta Métricas de canalización de transferencia de BigQuery.
¿Qué sigue?
- Obtén más información sobre el envío de transformaciones en Cloud Data Fusion.