Nesta página, descrevemos como as contas de serviço são usadas no Cloud Data Fusion. Para mais informações, consulte Usar contas de serviço.
Projetos de locatário e cliente
O Cloud Data Fusion configura contas de serviço para acessar recursos nos seguintes projetos:
- Projeto de locatário
O Cloud Data Fusion cria um projeto de locatário para manter os recursos e serviços necessários para gerenciar pipelines em seu nome. Por exemplo: executar pipelines nos clusters do Dataproc que residam no projeto do cliente. Um projeto de locatário não é exposto a você, mas quando você cria uma instância particular, talvez seja necessário usar o nome do projeto de locatário para configurar o peering de VPC.
Para mais informações, consulte a documentação da infraestrutura de serviços sobre projetos de locatário.
- Projeto do cliente
Você cria e é proprietário deste projeto. Por padrão, o Cloud Data Fusion cria um cluster temporário do Dataproc neste projeto para executar seus pipelines.
O diagrama a seguir mostra uma instância do Cloud Data Fusion em execução em um projeto de locatário. Além disso, apresenta um pipeline em execução em um cluster do Dataproc em um projeto de cliente.
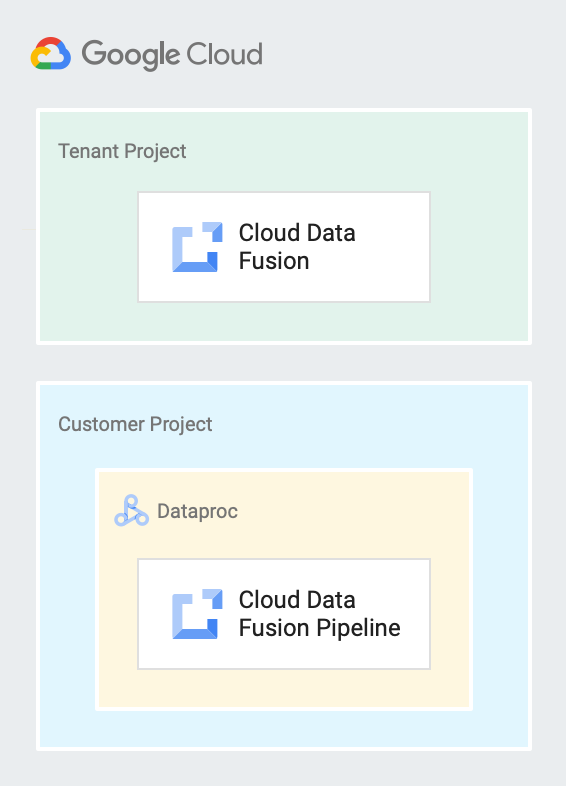
Contas de serviço no Cloud Data Fusion
Uma conta de serviço fornece uma identidade para o Cloud Data Fusion, que oferece acesso ao Cloud aos seus recursos.
Quando você ativa a API Cloud Data Fusion e cria uma instância do Cloud Data Fusion, uma conta de serviço é adicionada ao seu projeto para acessar recursos como Service Networking, Dataproc, Cloud Storage, BigQuery, Spanner e Bigtable. Essa conta de serviço é chamada de agente de serviço da API Cloud Data Fusion. Os papéis são concedidos automaticamente a esse agente de serviço.
Uma conta de serviço é identificada por seu endereço de e-mail, que é exclusivo.
Os seguintes tipos de contas de serviço são usados no Cloud Data Fusion. Para mais informações, consulte Tipos de contas de serviço.
| Conta de serviço | Descrição |
|---|---|
service-CUSTOMER_PROJECT_NUMBER@gcp-sa-
datafusion.iam.gserviceaccount.com |
O agente de serviço, chamado de agente de serviço da API Cloud Data Fusion, que o Cloud Data Fusion cria para ter acesso aos recursos do cliente e poder agir em nome dele. Ela é usada no projeto de locatário para acessar os recursos do projeto do cliente. Por exemplo, a visualização é executada na memória, e não em um cluster do Dataproc. A função
Agente de serviço da API Cloud Data Fusion
( |
CUSTOMER_PROJECT_NUMBER-
compute@developer.gserviceaccount.com |
A conta de serviço padrão do Compute Engine que o Cloud Data Fusion cria para implantar jobs que acessam outros recursos do Google Cloud . Por padrão, ele é anexado a uma VM de cluster do Dataproc para permitir que o Cloud Data Fusion acesse recursos do Dataproc durante uma execução de pipeline. Na edição Enterprise do Cloud Data Fusion, é possível executar pipelines de uma conta serviço gerenciado pelo usuário criando um perfil no console do Cloud Data Fusion → Administrador do sistema → guia "Configuração" e adicionando a conta de serviço personalizada. Nas versões 6.2.3 e posteriores, é possível escolher uma conta de serviço personalizada para anexar ao cluster do Dataproc ao criar uma instância do Cloud Data Fusion. Para mais informações, consulte Contas de serviço no Dataproc. |
A seguir
- Saiba mais sobre como controlar o acesso aos dados.
- Conceder permissões de usuário da conta de serviço.
- Consulte os preços do Cloud Data Fusion.