热图模式
本页介绍了您可能在 Key Visualizer 扫描热图中看到的模式示例,并介绍了每个模式的含义。您可以借助此类信息来诊断 Bigtable 的性能问题。
在阅读本页内容之前,您应该先熟悉 Cloud Bigtable 概览。
常见模式概览
本页介绍了如何解读以下 Key Visualizer 模式。
均匀分布读写操作
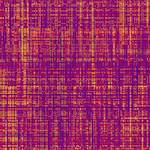
如果热图显示深色和亮色混合良好,则读取和写入均匀分布在整个表中。此热图表示 Bigtable 的有效使用模式,因此您无需采取任何行动。
定期使用

如果热图在某个键范围内交替显示暗色与亮色的色带,则表示您仅在特定时段访问该键范围。例如,您可能是在一天里的特定时间运行访问该键范围的批量作业。
只要这种使用模式不会导致过高 CPU 利用率或过长延迟时间,并且您打算以这种方式访问数据,这种模式就不会成为问题。 如果此模式会导致过高的 CPU 利用率,则您可能需要在高峰使用时段内向集群添加节点。如果您不打算在特定时间段内更频繁地访问数据,请检查您的应用以找出未正常运作的应用。
热键范围
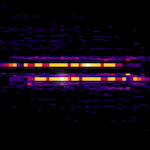
如果热图显示以深色分隔的亮色水平色带,则表示亮色键范围存在下列其中一种问题:
- 如果您正在查看读取压力指数或写入压力指数指标,则热键范围可能会导致高 CPU 利用率或高延迟。如果执行大量读取或写入,或者连续存储超过 256 MB,则可能会出现这些问题。请特别注意此警告是否由单行触发,而不是由一个范围内的行触发。
- 如果您正在查看大型行指标,则键范围包括数据超过 256 MB 的行或平均每行数据超过 200 MB 的行。
- 如果您正在查看其他指标,则可能是您访问该键范围中的行比其他行更频繁。
请至少采取以下一种措施来解决此问题:
- 使用过滤条件来减少您读取的数据量。
- 更改您的架构设计或应用,将频繁使用的行或过大的行中的数据分布到多行中。
- 更新您的应用以缓存从 Bigtable 中读取的结果。
- 更新您的应用以批量删除向 Bigtable 写入的重复数据。
突发增加

如果热图显示的键范围突然从深色变为亮色,则表示发生了以下其中一项变化:
如果您正在查看大型行指标,则会在短时间内向该键范围中的行添加大量数据。
从大型行中删除数据,或更改架构设计,以便在这些行中存储较少的数据。
如果您正在查看其他指标,则可能是您在特定时间点比平常访问这些行更频繁。
只要这种使用模式不会导致过高 CPU 利用率或过长延迟时间,并且您打算以这种方式访问数据,这种模式就不会成为问题。 如果此模式会导致过高的 CPU 利用率,则您可能需要在高峰使用时段内向集群添加节点。如果您不打算在特定时间点开始更频繁地访问数据,请检查您的应用以找出未正常运作的应用。
依序读取和写入
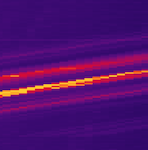
如果热图显示亮色的斜线,则表示您正按顺序访问表中的连续键范围。例如,您可能运行了对表的行键执行迭代操作的批量作业。
只要这种使用模式不会导致过高 CPU 利用率或过长延迟时间,并且您打算以这种方式访问数据,这种模式就不会成为问题。 如果此模式会导致过高的 CPU 利用率,则您可能需要在高峰使用时段内向集群添加节点。如果您不打算按顺序访问表中的行,请检查您的应用以找出未正常运作的应用。
后续步骤
- 了解如何开始使用 Key Visualizer。
- 了解如何详细探索热图。
- 了解可以在热图中查看的指标。