Migrate from Apache Cassandra to Bigtable
This document guides you through the process of migrating data from Apache Cassandra to Bigtable with minimal disruption. It describes how to use open-source tools, such as the Cassandra to Bigtable proxy adapter or the Cassandra to Bigtable client for Java, to perform the migration. Before you begin, make sure you're familiar with Bigtable for Cassandra users.
Choose a migration approach
You can migrate from Apache Cassandra to Bigtable using one of the following approaches:
- Cassandra to Bigtable proxy adapter lets you connect Cassandra-based applications to Bigtable without changing Cassandra drivers. This approach is ideal for applications that require minimal code changes.
- Cassandra to Bigtable client for Java lets you integrate directly with Bigtable and replace your Cassandra drivers. This approach is ideal for applications that require high performance and flexibility.
Cassandra to Bigtable proxy adapter
The Cassandra to Bigtable proxy adapter lets you connect Cassandra-based applications to Bigtable. The proxy adapter functions as a wire-compatible Cassandra interface, and it lets your application interact with Bigtable using CQL. Using the proxy adapter doesn't require you to change Cassandra drivers, and configuration adjustments are minimal.
To set up and configure the proxy adapter, see Cassandra to Bigtable proxy adapter.
To learn which Cassandra versions support the proxy adapter, see Supported Cassandra versions.
Limitations
The Cassandra to Bigtable proxy adapter provides limited support for certain data types, functions, queries, and clauses.
For more information, see Cassandra to Bigtable Proxy - Limitations.
Cassandra keyspace
A Cassandra keyspace stores your tables and manages resources in a similar way to a Bigtable instance. The Cassandra to Bigtable proxy adapter handles keyspace naming transparently, so that you can query using the same keyspaces. However, you must create a new Bigtable instance to achieve logical grouping of your tables. You must also configure Bigtable replication separately.
DDL support
The Cassandra to Bigtable proxy adapter supports Data Definition Language (DDL) operations. DDL operations let you create and manage tables directly through CQL commands. We recommend this approach for setting up your schema because it's similar to SQL but you don't need to define your schema in configuration files and then execute scripts to create tables.
The following examples show how the Cassandra to Bigtable proxy adapter supports DDL operations:
To create a Cassandra table using CQL, run the
CREATE TABLEcommand:CREATE TABLE keyspace.table ( id bigint, name text, age int, PRIMARY KEY ((id), name) );To add a new column to the table, run the
ALTER TABLEcommand:ALTER TABLE keyspace.table ADD email text;To delete a table, run the
DROP TABLEcommand:DROP TABLE keyspace.table;
For more information, see DDL Support for Schema Creation (Recommended Method).
DML support
The Cassandra to Bigtable proxy adapter supports Data Manipulation
Language (DML) operations such as INSERT, DELETE, UPDATE, and SELECT.
To run the raw DML queries, all values except numerics must have single quotes, as shown in the following examples:
SELECT * FROM keyspace.table WHERE name='john doe';INSERT INTO keyspace.table (id, name) VALUES (1, 'john doe');
Achieve zero downtime migration
You can use the Cassandra to Bigtable proxy adapter with the open-source Zero Downtime Migration (ZDM) proxy tool and the Cassandra data migrator tool to migrate data with minimal downtime.
The following diagram shows the steps for migrating from Cassandra to Bigtable using the proxy adapter:
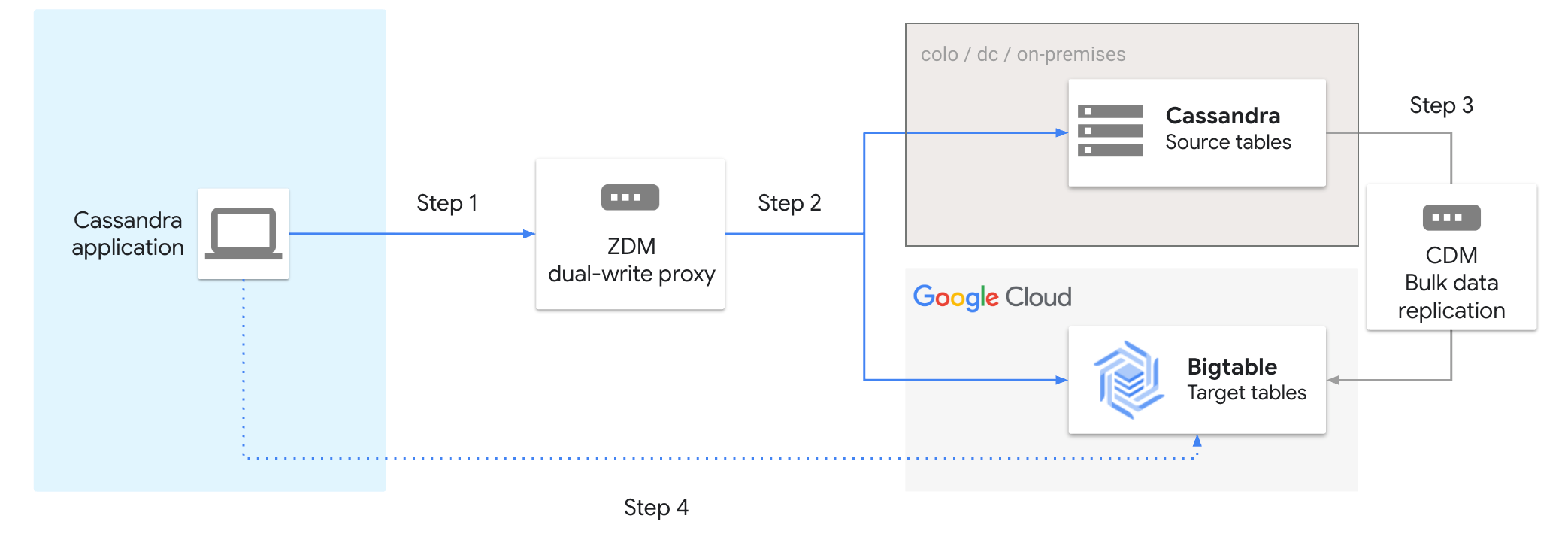
To migrate Cassandra to Bigtable, follow these steps:
- Connect your Cassandra application to the ZDM proxy tool.
- Enable dual writes to Cassandra and Bigtable.
- Move data in bulk using the Cassandra data migrator tool.
- Validate your migration. Once validated, you can terminate the connection to Cassandra and connect directly to Bigtable.
When using the proxy adapter with the ZDM proxy tool, the following migration capabilities are supported:
- Dual writes: maintain data availability during migration
- Asynchronous reads: scale and stress-test your Bigtable instance
- Automated data verification and reporting: ensure data integrity throughout the process
- Data mapping: map field and data types to meet your production standards
To practice migrating Cassandra to Bigtable, see the Migration from Cassandra to Bigtable with a Dual-Write Proxy codelab.
Cassandra to Bigtable client for Java
You can integrate directly with Bigtable and replace your Cassandra drivers, the Cassandra to Bigtable client for Java library lets you integrate Cassandra-based Java applications with Bigtable using CQL.
For instructions on building the library and including the dependency in application code, see Cassandra to Bigtable Client for Java.
The following example shows how to configure your application with the Cassandra to Bigtable client for Java:
Understand performance
Bigtable is designed for high throughput, low latency, and massive scalability. It can handle millions of requests per second on petabytes of data. When you migrate from Cassandra using either the Cassandra to Bigtable client for Java or the Cassandra to Bigtable proxy adapter, understand the following performance implications:
Client and proxy overhead
Both migration approaches introduce minimal performance overhead. They act as a translation layer between the Cassandra Query Language (CQL) and the Bigtable Data API, which is optimized for efficiency.
Performance with Cassandra collection types
If your Cassandra data model uses collection types such as maps, sets, or lists to implement dynamic schemas, then Bigtable can handle these patterns effectively. Both the proxy adapter and the client for Java map these collection operations to Bigtable's underlying data model, which is well-suited for sparse and wide datasets.
Element-level operations within these collections are highly efficient. This includes the following actions:
- To read or write a single value in a map.
- To add or remove an element from a set.
- To append or prepend an element to a list.
Bigtable optimizes these types of point operations on individual collection elements, and their performance is identical to operations on standard scalar columns.
Benchmark your workload
Bigtable performance can vary depending on your workload, schema design, data access patterns, and cluster configuration. To get accurate performance metrics for your use case and ensure that Bigtable meets your specific requirements, we recommend that you benchmark your Cassandra workloads against Bigtable using one of the migration approaches.
For more information about Bigtable performance best practices, see Understand performance.
Additional Cassandra open-source tools
Because of the wire compatibility of the Cassandra to Bigtable proxy adapter with CQL lets you use additional tools in the Cassandra open-source ecosystem. These tools include the following:
- Cqlsh: The CQL shell lets you connect directly to Bigtable through the proxy adapter. You can use it for debugging and quick data lookups using CQL.
- Cassandra Data Migrator (CDM): This Spark-based tool is suitable for migrating large volumes (up to billions of rows) of historical data. The tool provides validation, diff reporting, and replay capabilities, and it's fully compatible with the proxy adapter.