Replicate from HBase to Bigtable
The Cloud Bigtable HBase replication library is a component of the open-source Cloud Bigtable HBase client for Java. The replication library lets you asynchronously replicate data from an HBase cluster to a Bigtable instance using the HBase replication service, so you can perform an online migration from HBase to Bigtable. To review the README and source code, visit the GitHub repository.
For offline migration from HBase to Bigtable, see Migrate data from HBase to Bigtable offline.
Use cases
- Online migration to Bigtable - You can use the Bigtable HBase replication library, in conjunction with an offline migration of your existing HBase data, to migrate from HBase to Bigtable with almost no downtime.
- Data recovery - Prepare for the unexpected by replicating your HBase data to an offsite Bigtable instance.
- Centralizing datasets - Use the library to replicate data from HBase clusters in multiple locations to a single Bigtable instance that automatically handles replication among its clusters.
- Extending your HBase footprint - Replicate to a Bigtable instance that has clusters in locations beyond your current HBase locations.
Overview
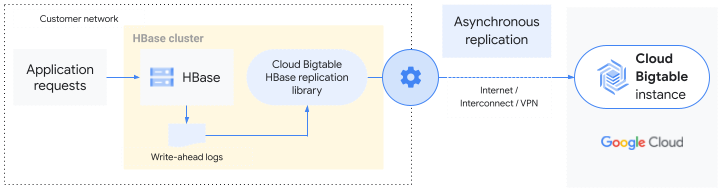
The Bigtable HBase replication library extends the base HBase replication service. Data that is written to an HBase cluster is replicated asynchronously to a Bigtable instance in the same way that standard HBase replication copies data to another HBase cluster. The library uses the write-ahead log (WAL) of the source HBase cluster to push the mutations to the Bigtable instance.
You can replicate an entire HBase cluster to Bigtable or replicate only specific tables or column families. In other words, HBase replication is enabled at the cluster, table, or column family level.
Replication from HBase to Bigtable is eventually consistent.
Migrate to Bigtable
The Bigtable HBase replication library lets you migrate to Bigtable without pausing your application.
At a high level, the steps for online migration from HBase to Bigtable are as follows. See the README for more details.
- Before you begin, follow the setup and configuration steps.
- Enable replication on your HBase cluster.
- Add a Bigtable replication endpoint as a peer.
- Disable the Bigtable peer. This causes writes to HBase from that point onward to buffer on the HBase cluster.
- Once the buffering has started to capture new writes, follow the offline migration guide to migrate a snapshot of your existing HBase data.
- When the offline migration is complete, re-enable the Bigtable peer to let the buffer drain and replay writes on Bigtable.
- After the buffer is drained, restart your application to send requests to Bigtable.
Set up and configure the replication library
Before you can use the Bigtable HBase replication, you need to complete the tasks in this section.
Configure authentication
To ensure that the replication library has permission to write to Bigtable, follow the steps at Create a service account. Assign the role roles/bigtable.user to the newly created service account.
Next, add the following to your hbase-site.xml file across the entire HBase
cluster.
<property>
<name>google.bigtable.auth.json.keyfile</name>
<value>JSON_FILE_PATH</value>
<description>
Service account JSON file to connect to Cloud Bigtable
</description>
</property>
Replace JSON_FILE_PATH with the path to the JSON file that
you downloaded.
For additional properties that you can set, see HBaseToCloudBigtableReplicationConfiguration.
Create a destination instance and tables
Before you can replicate from HBase to Bigtable, create a Bigtable instance. A Bigtable instance can have one cluster or multiple clusters that operate in a multi-primary fashion. Requests from the HBase replication service are routed to the closest cluster in the Bigtable instance, then replicated to the other clusters in the instance.
Your Bigtable destination table needs to have the same name and same column families as your HBase table. For step-by-step instructions on using the Bigtable Schema Translation tool to create a table with the same schema as your HBase table, see Migrate data from HBase to Bigtable offline. Even though you are replicating, rather than importing your data, the steps are the same.
Set the config properties
Add the following to your hbase-site.xml across the entire HBase cluster.
<property>
<name>google.bigtable.project.id</name>
<value>PROJECT_ID</value>
<description>
Bigtable project ID
</description>
</property>
<property>
<name>google.bigtable.instance.id</name>
<value>INSTANCE_ID</value>
<description>
Bigtable instance ID
</description>
</property>
<property>
<name>google.bigtable.app_profile.id</name>
<value>APP_PROFILE_ID</value>
<description>
Bigtable app profile ID
</description>
</property>
Replace the following:
PROJECT_ID: The Google Cloud project that your Bigtable instance is in.INSTANCE_ID: The ID of the Bigtable instance that you are replicating your data to.APP_PROFILE_ID: The ID of the app profile to use to connect to Bigtable.
Install the replication library
To use the Bigtable HBase replication library, you need to install it on every server in the HBase cluster. Use the replication library version that corresponds to your HBase version (1.x or 2.x).
Download the JAR
To get the replication library, run the following in the HBase shell.
wget BIGTABLE_HBASE_REPLICATION_URL
Replace BIGTABLE_HBASE_REPLICATION_URL with the URL of the
latest JAR with dependencies available in the replication library's Maven
repository. The filename is similar to
https://repo1.maven.org/maven2/com/google/cloud/bigtable/bigtable-hbase-1.x-replication/1.0.0/bigtable-hbase-1.x-replication-1.0.0-jar-with-dependencies.jar.
To find the URL or to manually download the JAR, do the following.
- Go to the replication library repository for the version of HBase that you are using.
- Click the most recent version number, such as
1.0.0. - Identify the jar-with-dependencies file (usually at the top).
- Either right-click and copy the URL, or click to download the file.
Install the JAR
On every HBase server, including the master and region servers, copy the file
that you just downloaded to a folder in the HBase classpath. For example,
you might copy the file to /usr/lib/hbase/lib/.
Add a Bigtable peer
To replicate from HBase to Bigtable, you need to add a Bigtable endpoint as a replication peer.
- Restart the HBase servers to ensure that the replication library is loaded.
- Run the following in the HBase shell.
add_peer "PEER_ID_NUMBER", ENDPOINT_CLASSNAME =>
'com.google.cloud.bigtable.hbaseHBASE_VERSION_NUMBER_x.replication.HbaseToCloudBigtableReplicationEndpoint'
Replace the following:
PEER_ID_NUMBER: An integer ID for the Bigtable replication peer. To enable HBase replication of only select tables, use anadd_peeroptional parameter.HBASE_VERSION_NUMBER: The number of the HBase version that you are using. Use1for HBase 1.x and2for HBase 2.x. (HBase 3.x is not supported.)
Enable table replication
After you add the Bigtable peer, enable table replication by running the following command in the HBase shell for each table that you want to replicate to Bigtable:
enable_table_replication TABLE_NAME
Replace TABLE_NAME with the name of the table to replicate.