Replication and performance
Enabling replication affects the performance of a Bigtable instance. The effect is positive for some metrics and negative for others. You should understand potential impacts on performance before deciding to enable replication.
Read throughput
Replication can improve read throughput, especially when you use multi-cluster routing. Additionally, replication can reduce read latency by placing your Bigtable data geographically closer to your application's users.
Write throughput
Although replication can improve availability and read performance, it does not increase write throughput. A write to one cluster must be replicated to all other clusters in the instance. As a result, each cluster is expending CPU resources to pull changes from the other clusters. Write throughput might actually go down because replication requires each cluster to do additional work.
For example, suppose you have a single-cluster instance, and the cluster has 3 nodes:
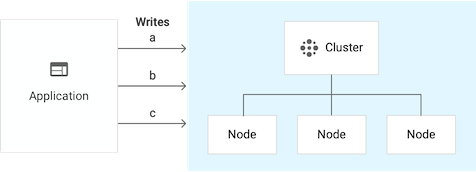
If you add nodes to the cluster, the effect on write throughput is different than if you enable replication by adding a second 3-node cluster to the instance.
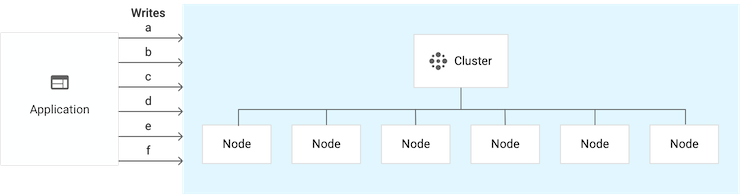
Adding nodes to the original cluster: You can add 3 nodes to the cluster, for a total of 6 nodes. The write throughput for the instance doubles, but the instance's data is available in only one zone:
With replication: Alternatively, you can add a second cluster with 3 nodes, for a total of 6 nodes. The instance now writes each piece of data twice: when the write is first received and again when it is replicated to the other cluster. The write throughput does not increase, and might go down, but you benefit from having your data available in two different zones:
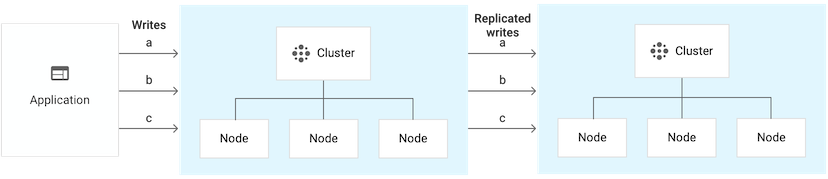
In these examples, the single-cluster instance can handle twice the write throughput that the replicated instance can handle, even though each instance's clusters have a total of 6 nodes.
Replication latency
When you use multi-cluster routing, replication for Bigtable is eventually consistent. As a general rule, it takes longer to replicate data across a greater distance. Replicated clusters in different regions will typically have higher replication latency than replicated clusters in the same region.
Node usage
As explained in Write throughput, when an instance uses replication, each cluster in the instance must handle the work of replication in addition to the load it receives from applications. For this reason, a cluster in a multi-cluster instance often needs more nodes than a cluster in a single-cluster instance with similar traffic.
App profiles and traffic routing
Depending on your use case, you will use one or more app profiles to route your Bigtable traffic. Each app profile uses either multi-cluster or single-cluster routing. The choice of routing can affect performance.
Multi-cluster routing can minimize latency. An app profile with multi-cluster routing automatically routes requests to the closest cluster in an instance from the perspective of the application, and the writes are then replicated to the other clusters in the instance. This automatic choice of the shortest distance results in the lowest possible latency.
An app profile that uses single-cluster routing can be optimal for certain use cases, like separating workloads or to have read-after-write semantics on a single cluster, but it won't reduce latency in the way multi-cluster routing does.
To understand how to configure your app profiles for these and other use cases, see Examples of Replication Settings.
Dropping row ranges
If possible, avoid dropping a row range in an instance that uses replication because the operation is slow and the CPU usage increases during the operation.
What's next
- Read about Failovers.
- Explore Routing options.