This document is for software developers and database administrators who want to migrate existing applications or design new applications for use with Bigtable as a datastore. This document applies your knowledge of Apache Cassandra to using Bigtable to describe concepts that you should understand before migrating. For information about open-source tools that you can use to complete your migration, see Migrating from Cassandra to Bigtable.
Bigtable and Cassandra are distributed databases. They implement multidimensional key-value stores that can support tens of thousands of queries per second (QPS), storage that scales up to petabytes of data, and tolerance for node failure.
When is Bigtable a good destination for Cassandra workloads
The best Google Cloud service for your Cassandra workload depends on your migration goals and the Cassandra functionality that you require after migration.
If one or more of the following conditions apply, Bigtable is optimal:
- You want a fully managed service with no maintenance windows and high availability.
- You need elastic scaling that responds to changes in server traffic automatically.
- You use Cassandra collection types, counters, or materialized views in addition to scalar types.
- You have an application that uses the
USING TIMESTAMPparameter. - Your write throughput and latency are just as important as reads.
- You rely on one of Cassandra's eventually consistent replication models.
- Your use case requires cost-effective storage.
To migrate applications without any code changes, you might choose to self-manage Cassandra on GKE or use a Google Cloud partner such as DataStax or ScyllaDB. If your application is read-heavy and you're willing to refactor your code to obtain relational database capabilities and strong consistency, you might consider Spanner.
This document provides tips on what to consider when refactoring your application, if you choose Bigtable as the migration target for your Cassandra workloads.
How to use this document
You don't need to read this document from start to finish. Although this document provides a comparison of the two databases, you can also focus on topics that apply to your use case or interests.
To help you compare Bigtable and Cassandra, this document does the following:
- Compares terminology, which can differ between the two databases.
- Provides an overview of the two database systems.
- Looks at how each database handles data modeling in order to understand different design considerations.
- Compares the path taken by data during writes and reads.
- Examines the physical data layout to understand aspects of the database architecture.
- Describes how to configure geographic replication to meet your requirements, and how to approach cluster sizing.
- Reviews details about cluster management, monitoring, and security.
Terminology comparison
Although many of the concepts used in Bigtable and Cassandra are similar, each database has slightly different naming conventions and subtle differences.
One of the core building blocks of both databases is the sorted string table (SSTable). In both architectures, SSTables are created to persist data that's used to respond to read queries.
In a blog post (2012), Ilya Grigorik writes the following: "An SSTable is a simple abstraction to efficiently store large numbers of key-value pairs while optimizing for high throughput, sequential read or write workloads."
The following table outlines and describes shared concepts and the corresponding terminology that each product uses:
| Cassandra | Bigtable |
|---|---|
|
primary key: a unique single or multi-field value that determines data placement and ordering. partition key: a single or multi-field value that determines data placement by consistent hash. clustering column: a single or multi-field value that determines the lexicographical data sorting within a partition. |
row key: a unique, single byte string that determines the placement of data by a lexicographical sort. Composite keys are imitated by joining the data of multiple columns by using a common delimiter—for example, the hash (#) or percent (%) symbols. |
| node: a machine responsible for reading and writing data that's associated with a series of primary key partition hash ranges. In Cassandra, data is stored on block-level storage that's attached to the node server. | node: a virtual compute resource responsible for reading and writing data that's associated with a series of row key ranges. In Bigtable, data isn't colocated with the compute nodes. Instead, it's stored in Colossus, Google's distributed file system. Nodes are given temporary responsibility for serving various ranges of data based on the operation load and the health of other nodes in the cluster. |
|
data center: similar to a Bigtable cluster, except some aspects of topology and replication strategy are configurable in Cassandra. rack: a grouping of nodes in a data center that influences replica placement. |
cluster: a group of nodes in the same geographic Google Cloud zone, colocated for latency and replication concerns. |
| cluster: a Cassandra deployment consisting of a collection of data centers. | instance: a group of Bigtable clusters in different Google Cloud zones or regions between which replication and connection routing occur. |
| vnode: a fixed range of hash values assigned to a specific physical node. Data in a vnode is physically stored on the Cassandra node in a series of SSTables. | tablet: an SSTable containing all data for a contiguous range of lexicographically sorted row keys. Tablets are not stored on nodes in Bigtable, but are stored in a series of SSTables on Colossus. |
| replication factor: the number of replicas of a vnode that are maintained across all nodes in the data center. The replication factor is configured independently for each data center. | replication: the process of replicating the data stored in Bigtable to all clusters in the instance. Replication within a zonal cluster is handled by the Colossus storage layer. |
| table (formerly column family): a logical organization of values that's indexed by the unique primary key. | table: a logical organization of values that's indexed by the unique row key. |
| keyspace: a logical table namespace that defines the replication factor for the tables it contains. | Not applicable. Bigtable handles keyspace concerns transparently. |
| map: a Cassandra collection type that holds key-value pairs. | column family: a user-specified namespace that groups column qualifiers for more efficient reads and writes. When querying Bigtable using SQL, column families are treated like Cassandra's maps. |
| map key: key that uniquely identifies a key-value entry in a Cassandra map | column qualifier: a label for a value stored in a table that's indexed by the unique row key. When querying Bigtable using SQL, columns are treated like keys of a map. |
| column: the label for a value stored in a table that's indexed by the unique primary key. | column: the label for a value stored in a table that's indexed by the unique row key. The column name is constructed by combining the column family with the column qualifier. |
| cell: a timestamp value in a table that's associated with the intersection of a primary key with the column. | cell: a timestamp value in a table that's associated with the intersection of a row key with the column name. Multiple timestamped versions can be stored and retrieved for each cell. |
| counter: an incrementable field type optimized for integer sum operations. | counters: cells that use specialized data types for integer sum operations. For more information, see Create and update counters. |
| load balancing policy: a policy that you configure in the application logic to route operations to an appropriate node in the cluster. The policy accounts for the data center topology and vnode token ranges. | application profile: settings that instruct Bigtable how to route a client API call to the appropriate cluster in the instance. You can also use the application profile as a tag to segment metrics. You configure the application profile in the service. |
| CQL: the Cassandra Query Language, a language like SQL that's used for table creation, schema changes, row mutations, and queries. | The Cassandra to Bigtable client for Java is a seamless replacement for your Cassandra drivers. The Java client understands your CQL queries, and lets you use Bigtable transparently with your existing Cassandra-based application without rewriting code. The Cassandra to Bigtable proxy adapter is a standalone layer that you can run parallel to your application and connect to Bigtable as another Cassandra node. The proxy adapter provides compatibility with CQL and supports dual-write and bulk migrations. This functionality is similar to what the Cassandra to Bigtable client for Java offers. Bigtable APIs are the client libraries and the gRPC APIs used for instance and cluster creation, table and column family creation, row mutation, and query execution. The Bigtable SQL API is familiar to CQL users. |
materialized view: a SELECT statement that defines a set
of rows that corresponds to rows in an underlying source table. When the source
table changes, Cassandra updates the materialized view automatically.
|
continuous materialized view: a fully-managed, pre-computed result of a SQL query that is incrementally and automatically updated from a source table. For more information, see Continuous materialized views. |
Product overviews
The following sections provide an overview of the design philosophy and key attributes of Bigtable and Cassandra.
Bigtable
Bigtable provides many of the core features described in the Bigtable: A Distributed Storage System for Structured Data paper. Bigtable separates the compute nodes, which serve client requests, from the underlying storage management. Data is stored on Colossus. The storage layer automatically replicates the data to provide durability that exceeds levels provided by standard Hadoop Distributed File System (HDFS) three-way replication.
This architecture provides consistent reads and writes within a cluster, scales up and down without any storage redistribution cost, and can rebalance workloads without modifying the cluster or schema. If any data processing node becomes impaired, the Bigtable service replaces it transparently. Bigtable also supports asynchronous replication.
In addition to gRPC and client libraries for various programming languages, Bigtable maintains compatibility with the open source Apache HBase Java client library, an alternative open source database engine implementation of the Bigtable paper.
The following diagram shows how Bigtable physically separates the processing nodes from the storage layer:
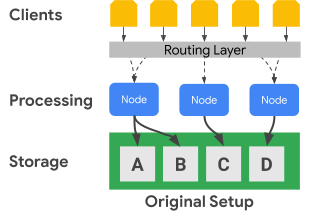
In the preceding diagram, the middle processing node is only responsible for serving data requests for the C dataset in the storage layer. If Bigtable identifies that range-assignment rebalancing is required for a dataset, the data ranges for a processing node are straightforward to change because the storage layer is separated from the processing layer.
The following diagram shows, in simplified terms, a key range rebalancing and a cluster resizing:
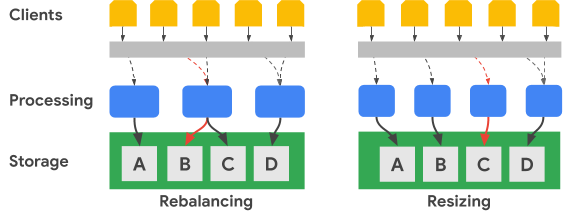
The Rebalancing image illustrates the state of the Bigtable cluster after the leftmost processing node receives an increased number of requests for the A dataset. After the rebalancing occurs, the middle node, instead of the leftmost node, is responsible for serving data requests for the B dataset. The leftmost node continues to service requests for the A dataset.
Bigtable can rearrange row key ranges in order to balance dataset ranges across an increased number of available processing nodes. The Resizing image shows the state of the Bigtable cluster after you add a node.
Cassandra
Apache Cassandra is an open source database that is partly influenced by concepts from the Bigtable paper. It uses a distributed node architecture, where storage is colocated with the servers that respond to data operations. A series of virtual nodes (vnodes) are randomly assigned to each server to serve a portion of the cluster keyspace.
Data is stored in the vnodes based on the partition key. Typically, a consistent hash function is used to generate a token to determine data placement. As with Bigtable, you can use an order-preserving partitioner for token generation, and thus also for data placement. However, the Cassandra documentation discourages this approach because the cluster will likely become unbalanced, a condition that's difficult to remedy. For this reason, this document assumes that you use a consistent hashing strategy to generate tokens that result in data distribution across nodes.
Cassandra provides fault tolerance through availability levels that are correlated with the tunable consistency level, allowing a cluster to serve clients while one or more nodes are impaired. You define geographic replication through a configurable data replication topology strategy.
You specify a consistency level for each operation. The typical setting is
QUORUM (or LOCAL_QUORUM in certain multiple-data center topologies). This
consistency level setting requires a replica node majority to respond to the
coordinator node for the operation to be considered successful. The replication
factor, which you configure for every keyspace, determines the number of data
replicas that are stored in each data center in the cluster. For example, it's
typical to use a replication factor value of 3 to provide a practical balance
between durability and storage volume.
The following diagram shows in simplified terms a cluster of six nodes with each node's key-range divided into five vnodes. In practice, you can have more nodes, and likely will have more vnodes.

In the preceding diagram, you can see the path of a write operation, with a
consistency level of QUORUM, that originates from a client application or
service (Client). For the purposes of this diagram, the key ranges are shown
as alphabetical ranges. In reality, the tokens produced by a hash of the
primary key are very large signed integers.
In this example, the key hash is M, and the vnodes for M are on nodes 2,
4, and 6. The coordinator must contact each node where the key hash ranges are
stored locally so that the write can be processed. Since the consistency level
is QUORUM, two replicas (a majority) must respond to the coordinator node
before the client is notified that the write is complete.
In contrast to Bigtable, moving or changing key ranges in Cassandra requires that you physically copy the data from one node to another. If one node is overloaded with requests for a given token hash range, adding processing for that token range is more complex in Cassandra as compared to Bigtable.
Geographic replication and consistency
Bigtable and Cassandra handle geographic (also known as multi- region) replication and consistency differently. A Cassandra cluster consists of processing nodes grouped into racks, and racks are grouped into data centers. Cassandra uses a network topology strategy that you configure to determine how vnode replicas are distributed across hosts in a data center. This strategy reveals Cassandra's roots as a database originally deployed on physical, on-premises data centers. This configuration also specifies the replication factor for each data center in the cluster.
Cassandra uses data center and rack configurations to improve the fault tolerance of the data replicas. During read and write operations, the topology determines the participant nodes that are required to provide consistency guarantees. You must manually configure nodes, racks, and data centers when you create or extend a cluster. Within a cloud environment, a typical Cassandra deployment treats a cloud zone as a rack and a cloud region as a data center.
You can use Cassandra's quorum controls to adjust the consistency guarantees for
each read or write operation. The strength levels of eventual consistency can
vary, including options that require a single replica node (ONE), a
single-data center replica node majority (LOCAL_QUORUM), or a majority of all
replica nodes across all data centers (QUORUM).
In Bigtable, clusters are zonal resources. A Bigtable instance can contain a single cluster, or it can be a group of fully replicated clusters. You can place instance clusters in any combination of zones across any regions that Google Cloud offers. You can add and remove clusters from an instance with minimal impact to other clusters in the instance.
In Bigtable, writes are performed (with read-your-writes consistency) on a single cluster and will be eventually consistent in the other instance clusters. Because individual cells are versioned by timestamp, no writes are lost, and each cluster serves the cells that have the most current timestamps available.
The service exposes the cluster consistency status. The Cloud Bigtable API provides a mechanism to obtain a table-level consistency token. You can use this token to ascertain whether all changes that were made to that table before the token was created were replicated completely.
Transaction support
Although neither database supports complex multi-row transactions, each has some transaction support.
Cassandra has a lightweight transaction (LWT) method that provides atomicity for updates to column values in a single partition. Cassandra also has compare and set semantics that complete row read operation and value comparison before a write is initiated.
Bigtable supports fully consistent, single-row writes within a cluster. Single-row transactions are further enabled through the read-modify-write and check-and-mutate operations. Multi-cluster routing application profiles don't support single-row transactions.
Data model
Both Bigtable and Cassandra organize data into tables that support lookups and range scans using the row's unique identifier. Both systems are classified as NoSQL wide-column stores.
In Cassandra, you must use CQL to create the full table schema in advance, including the primary key definition along with the column names and their types. Primary keys in Cassandra are unique composite values that consist of a mandatory partition key and an optional cluster key. The partition key determines a row's node placement, and the cluster key determines the sort order within a partition. When creating schemas, you must be aware of potential tradeoffs between executing efficient scans within a single partition and system costs that are associated with maintaining large partitions.
In Bigtable, you need only create the table and define its column families ahead of time. Columns aren't declared when tables are created, but they're created when application API calls add cells to table rows.
Row keys are lexicographically ordered across the Bigtable cluster. Nodes within Bigtable automatically balance nodal responsibility for key ranges, often referred to as tablets and sometimes as splits. Bigtable row keys frequently consist of several field values that are joined using a commonly used separator character that you choose (such as a percent sign). When separated, the individual string components are analogous to the fields of a Cassandra primary key.
Row key design
In Bigtable, the unique identifier of a table row is the row key. The row key must be a single unique value across an entire table. You can create multi-part keys by concatenating disparate elements that are separated by a common delimiter. The row key determines the global data sort order in a table. The Bigtable service dynamically determines the key ranges that are assigned to each node.
In contrast to Cassandra, where the partition key hash determines row placement and the clustering columns determine ordering, the Bigtable row key provides both nodal assignment and ordering. As with Cassandra, you should design a row key in Bigtable so that rows you want to retrieve together are stored together. However, in Bigtable, you're not required to design the row key for placement and ordering before you use a table.
Data types
The Bigtable service doesn't enforce column data types that the client sends. The client libraries provide helper methods to write cell values as bytes, UTF-8 encoded strings, and big-endian encoded 64-bit integers (big-endian encoded integers are required for atomic increment operations).
Column family
In Bigtable, a column family determines which columns in a table are stored and retrieved together. Each table needs at least one column family, though tables frequently have more (the limit is 100 column families for each table). You must explicitly create column families before an application can use them in an operation.
Column qualifiers
Each value that's stored in a table at a row key is associated with a label called a column qualifier. Because column qualifiers are only labels, there's no practical limit to the number of columns that you can have in a column family. Column qualifiers are often used in Bigtable to represent application data.
Cells
In Bigtable, a cell is the intersection of the row key and column name (a column family combined with a column qualifier). Each cell contains one or more timestamped values that can be supplied by the client or automatically applied by the service. Old cell values are reclaimed based on a garbage collection policy that's configured at the column family level.
Secondary indexes
You can use continuous materialized views as asynchronous secondary indexes for tables to query the same data using different lookup patterns or attributes. For more information, see Create an asynchronous secondary index.
Client load balancing and failover
In Cassandra, the client controls the load balancing of requests. The client driver sets a policy that's either specified as a part of configuration or programmatically during session creation. The cluster informs the policy about data centers that are closest to the application, and the client identifies nodes from those data centers to service an operation.
The Bigtable service routes API calls to a destination cluster based on a parameter (an application profile identifier) that's provided with each operation. Application profiles are maintained within the Bigtable service; client operations that don't select a profile use a default profile.
Bigtable has two types of application profile routing policies: single-cluster and multi-cluster. A multi-cluster profile routes operations to the closest available cluster. Clusters in the same region are considered to be equidistant from the perspective of the operation router. If the node that's responsible for the requested key range is overloaded or temporarily unavailable in a cluster, this profile type provides automatic failover.
In terms of Cassandra, a multi-cluster policy provides the failover benefits of a load balancing policy that's aware of data centers.
An application profile that has single-cluster routing directs all traffic to a single cluster. Strong row consistency and single-row transactions are only available in profiles that have single-cluster routing.
The drawback of a single-cluster approach is that in a failover, either the application must be able to retry by using an alternative application profile identifier, or you must manually perform the failover of impacted, single-cluster routing profiles.
Operation routing
Cassandra and Bigtable use different methods to select the processing node for read and write operations. In Cassandra, the partition key is identified, whereas in Bigtable the row key is used.
In Cassandra, the client first inspects the load balancing policy. This client-side object determines the data center that the operation is routed to.
After the data center is identified, Cassandra contacts a coordinator node to manage the operation. If the policy recognizes tokens, the coordinator is a node that serves data from the target vnode partition; otherwise, the coordinator is a random node. The coordinator node identifies the nodes where the data replicas for the operation partition key are located, and then it instructs those nodes to perform the operation.
In Bigtable, as discussed earlier, each operation includes an application profile identifier. The application profile is defined at the service level. The Bigtable routing layer inspects the profile to choose the appropriate destination cluster for the operation. The routing layer then provides a path for the operation to reach the correct processing nodes by using the row key of the operation.
Data write process
Both databases are optimized for fast writes and use a similar process to complete a write. However, the steps that the databases take vary slightly, especially for Cassandra, where, depending on the operation consistency level, communication with additional participant nodes might be required.
After the write request is routed to the appropriate nodes (Cassandra) or node (Bigtable), writes are first persisted to disk sequentially in a commit log (Cassandra) or a shared log (Bigtable). Next, the writes are inserted into an in-memory table (also known as a memtable) that's ordered like the SSTables.
After these two steps, the node responds to indicate that the write is complete. In Cassandra, several replicas (depending on the consistency level specified for each operation) must respond before the coordinator informs the client that the write is complete. In Bigtable, because each row key is only assigned to a single node at any point in time, a response from the node is all that's needed to confirm that a write is successful.
Later, if necessary, you can flush the memtable to disk in the form of a new SSTable. In Cassandra, the flush occurs when the commit log reaches a maximum size, or when the memtable exceeds a threshold that you configure. In Bigtable, a flush is initiated to create new immutable SSTables when the memtable reaches a maximum size that's specified by the service. Periodically, a compaction process merges SSTables for a given key range into a single SSTable.
Data updates
Both databases handle data updates similarly. However, Cassandra allows only one value for each cell, whereas Bigtable can keep a large number of versioned values for each cell.
When the value at the intersection of a unique row identifier and column is modified, the update is persisted as described earlier in the data write process section. The write timestamp is stored alongside the value in the SSTable structure.
If you haven't flushed an updated cell to an SSTable, you can store only the cell value in the memtable, but the databases differ on what's stored. Cassandra saves only the newest value in the memtable, whereas Bigtable saves all versions in the memtable.
Alternatively, if you've flushed at least one version of a cell value to disk in separate SSTables, the databases handle requests for that data differently. When the cell is requested from Cassandra, only the most recent value according to the timestamp is returned; in other words, the last write wins. In Bigtable, you use filters to control which versions of cells that a read request returns.
Row deletes
Because both databases use immutable SSTable files to persist data to disk, it isn't possible to delete a row immediately. To ensure that queries return the correct results after a row is deleted, both databases handle deletes using the same mechanism. A marker (called a tombstone in Cassandra) is added first to the memtable. Eventually, a newly written SSTable contains a timestamped marker indicating that the unique row identifier is deleted and shouldn't be returned in query results.
Time to live
The time to live (TTL) capabilities in the two databases are similar except for one disparity. In Cassandra, you can set the TTL for either a column or table, whereas in Bigtable, you can only set TTLs for the column family. A method exists for Bigtable that can simulate cell-level TTL.
Garbage collection
Because immediate data updates or deletes aren't possible with immutable SSTables, as discussed earlier, garbage collection occurs during a process called a compaction. The process removes cells or rows that shouldn't be served in query results.
The garbage collection process excludes a row or cell when an SSTable merge occurs. If a marker or tombstone exists for a row, that row isn't included in the resultant SSTable. Both databases can exclude a cell from the merged SSTable. If the cell timestamp exceeds a TTL qualification, the databases exclude the cell. If there are two timestamped versions for a given cell, Cassandra only includes the most recent value in the merged SSTable.
Data read path
When a read operation reaches the appropriate processing node, the read process to obtain data to satisfy a query result is the same for both databases.
For each SSTable on disk that might contain query results, a Bloom filter is checked to determine if each file contains rows to be returned. Because Bloom filters are guaranteed to never provide a false negative, all the qualifying SSTables are added to a candidate list to be included in further read result processing.
The read operation is performed using a merged view created from the memtable and the candidate SSTables on disk. Because all keys are lexicographically sorted, it's efficient to obtain a merged view that's scanned to obtain query results.
In Cassandra, a set of processing nodes that are determined by the operation consistency level must participate in the operation. In Bigtable, only the node responsible for the key range needs to be consulted. For Cassandra, you need to consider the implications for compute sizing because it's likely that multiple nodes will process each read.
Read results can be limited at the processing node in slightly different ways.
In Cassandra, the WHERE clause in a CQL query restricts the rows returned. The
constraint is that columns in the primary key or columns included in a secondary
index might be used to limit results.
Bigtable offers a rich filter assortment of filters that affect the rows or cells that a read query retrieves.
There are three categories of filters:
- Limiting filters, which control the rows or cells that the response includes.
- Modifying filters, which affect the data or metadata for individual cells.
- Composing filters, which let you combine multiple filters into one filter.
Limiting filters are the most commonly used—for example, the column family regular expression and column qualifier regular expression.
Physical data storage
Bigtable and Cassandra both store data in SSTables, which are regularly merged during a compaction phase. SSTable data compression offers similar benefits for reducing storage size. However, compression is applied automatically in Bigtable and is a configuration option in Cassandra.
When comparing the two databases, you should understand how each database physically stores data differently in the following aspects:
- The data distribution strategy
- The number of cell versions available
- The storage disk type
- The data durability and replication mechanism
Data distribution
In Cassandra, a consistent hash of the primary key's partition columns is the recommended method of determining data distribution across the various SSTables served by cluster nodes.
Bigtable uses a variable prefix to the full row key in order to lexicographically place data in SSTables.
Cell versions
Cassandra keeps only one active cell value version. If two writes are made to a cell, a last-write-wins policy ensures that only one value is returned.
Bigtable doesn't limit the number of timestamped versions for each cell. Other row size limits might apply. If not set by the client request, the timestamp is determined by the Bigtable service at the moment that the processing node receives the mutation. Cell versions can be pruned using a garbage collection policy that can be different for each table's column family, or can be filtered from a query result set through the API.
Disk storage
Cassandra stores SSTables on disks that are attached to each cluster node. To rebalance data in Cassandra, the files must be physically copied between servers.
Bigtable uses Colossus to store SSTables. Because Bigtable uses this distributed file system, it's possible for the Bigtable service to almost instantly reassign SSTables to different nodes.
Data durability and replication
Cassandra delivers data durability through the replication factor setting. The
replication factor determines the number of SSTable copies that are stored on
different nodes in the cluster. A typical setting for the replication factor is
3, which still allows stronger consistency guarantees with QUORUM or
LOCAL_QUORUM even if a node failure occurs.
With Bigtable, high data-durability guarantees are provided through the replication that Colossus provides.
The following diagram illustrates the physical data layout, compute processing nodes, and routing layer for Bigtable:

In the Colossus storage layer, each node is assigned to serve the data that's stored in a series of SSTables. Those SSTables contain the data for the row key ranges that are dynamically assigned to each node. While the diagram shows three SSTables for each node, it's likely there are more because SSTables are continually created as the nodes receive new changes to data.
Each node has a shared log. Writes processed by each node are immediately persisted to the shared log before the client receives a write acknowledgment. Because a write to Colossus is replicated multiple times, the durability is ensured even if nodal hardware failure occurs before the data is persisted to an SSTable for the row range.
Application interfaces
Originally, Cassandra database access was exposed through a Thrift API, but this method of access is deprecated. The recommended client interaction is through CQL.
Similar to Cassandra's original Thrift API, Bigtable database access is provided through an API that reads and writes data based on the provided row keys.
Like Cassandra, Bigtable has both a command-line interface,
called the
cbt CLI
, and client libraries that support many common
programming languages. These libraries are built on top of the gRPC and REST
APIs. Applications that are written for Hadoop and rely on the open source
Apache HBase library for Java can connect
without significant change
to Bigtable. For applications that don't require HBase
compatibility, we recommend that you use the built-in Bigtable
Java client.
Bigtable's Identity and Access Management (IAM) controls are fully integrated with Google Cloud, and tables can also be used as an external data source from BigQuery.
Database setup
When you set up a Cassandra cluster, you have several configuration decisions to make and steps to complete. First, you must configure your server nodes to provide compute capacity and provision local storage. When you use a replication factor of three, the recommended and most common setting, you must provision storage to store three times the amount of data that you expect to hold in your cluster. You must also determine and set configurations for vnodes, racks, and replication.
The separation of compute from storage in Bigtable simplifies scaling clusters up and down as compared to Cassandra. In a normally running cluster, you are typically only concerned with the total storage used by the managed tables, which determines the minimum number of nodes, and having enough nodes to keep up the current QPS.
You can quickly adjust the Bigtable cluster size if the cluster is over- or under-provisioned based on production load.
Bigtable storage
Other than the geographic location of the initial cluster, the only choice that you need to make when you create your Bigtable instance is the storage type. Bigtable offers two options for storage: solid-state drives (SSD) or hard disk drives (HDD). All clusters in an instance must share the same storage type.
When you account for storage needs with Bigtable, you don't need to account for storage replicas as you would when sizing a Cassandra cluster. There's no loss of storage density to achieve fault tolerance as is seen in Cassandra. Furthermore, because storage doesn't need to be expressly provisioned, you're only charged for the storage in use.
SSD
The SSD node's capacity of 5 TB, which is preferred for most workloads, provides higher storage density in comparison with the recommended configuration for Cassandra machines, which have a practical maximum storage density of less than 2 TB for each node. When you assess storage capacity needs, remember that Bigtable only counts one copy of the data; by comparison, Cassandra needs to account for three copies of the data under most configurations.
While write QPS for SSD is about the same as HDD, SSD provides significantly higher read QPS than HDD. SSD storage is priced at or near the costs of provisioned SSD persistent disks and varies by region.
HDD
The HDD storage type allows for considerable storage density—16 TB for each node. The trade-off is that random reads are significantly slower, supporting only 500 rows read per second for each node. HDD is preferred for write-intensive workloads where reads are expected to be range scans associated with batch processing. HDD storage is priced at or near the cost associated with Cloud Storage and varies by region.
Cluster size considerations
When you size a Bigtable instance to prepare for migrating a Cassandra workload, there are considerations when you compare single-data center Cassandra clusters to single-cluster Bigtable instances, and Cassandra multiple-data center clusters to multi-cluster Bigtable instances. The guidelines in the following sections assume that no significant data model changes are needed to migrate, and that there's equivalent storage compression between Cassandra and Bigtable.
A single-data center cluster
When you compare a single-data center cluster to a single-cluster
Bigtable instance, you should first consider the storage
requirements. You can estimate the unreplicated size of each keyspace by using
the
nodetool tablestats command
and dividing the total, flushed storage size by the keyspace's replication
factor. Then, you divide the unreplicated storage amount of all keyspaces by
3.5 TB
(5 TB * .70)
to determine the suggested number of SSD nodes to handle the storage alone. As
discussed, Bigtable handles storage replication and durability
within a separate tier that's transparent to the user.
Next, you should consider the compute requirements for the number of nodes. You can consult Cassandra server and client application metrics to get an approximate number of sustained reads and writes that have been executed. To estimate the minimum number of SSD nodes to perform your workload, divide that metric by 10,000. You likely need more nodes for applications that require low-latency query results. Google recommends that you test the performance of Bigtable with representative data and queries to establish a metric for the per-node QPS that's achievable for your workload.
The number of nodes that's required for the cluster should be equal to the larger of the storage and compute needs. If you're in doubt about your storage or throughput needs, you can match up the number of Bigtable nodes with the number of typical Cassandra machines. You can scale a Bigtable cluster up or down to match workload needs with minimal effort and zero downtime.
A multiple-data center cluster
With multiple-data center clusters, it's more difficult to determine the configuration of a Bigtable instance. Ideally, you should have a cluster in the instance for every data center in the Cassandra topology. Each Bigtable cluster in the instance must store all data within the instance and must be able to handle the total insert rate across the entire cluster. Clusters in an instance can be created in any supported cloud region across the globe.
The technique for estimating storage needs is similar to the approach for
single-data center clusters. You use nodetool to capture the storage size of
each keyspace in the Cassandra cluster and then divide that size by the number
of replicas. You need to remember that a table's keyspace might have different
replication factors for each data center.
The number of nodes in each cluster in an instance should be able to handle all writes across the cluster and all reads to at least two data centers in order to maintain service level objectives (SLOs) during a cluster outage. A common approach is to start with all clusters having the equivalent node capacity of the busiest data center in the Cassandra cluster. Bigtable clusters in an instance can be individually scaled up or down to match workload needs with zero downtime.
Administration
Bigtable provides fully managed components for common administration functions performed in Cassandra.
Backup and restore
Bigtable provides two methods to cover common backup needs: Bigtable backups and managed data exports.
You can think of Bigtable backups as analogous to a managed
version of Cassandra's nodetool snapshot feature.
Bigtable backups create restorable copies of a table, which are
stored as member objects of a cluster. You can restore backups as a new table in
the cluster that initiated the backup. The backups are designed to create
restore points if application-level corruption occurs. Backups that you create
through this utility don't consume node resources and are priced at or near
Cloud Storage prices. You can invoke Bigtable backups
programmatically or through the Google Cloud console for Bigtable.
Another way you can back up Bigtable is to use a managed data export to Cloud Storage. You can export into the Avro, Parquet, or Hadoop Sequence file formats. Compared to Bigtable backups, exports take longer to execute and incur extra compute costs because the exports use Dataflow. However, these exports create portable data files that you can query offline or import into another system.
Resizing
Because Bigtable separates storage and compute, you can add or remove Bigtable nodes in response to query demand more seamlessly than you can in Cassandra. Cassandra's homogeneous architecture requires you to rebalance nodes (or vnodes) across the machines in the cluster.
You can change the cluster size manually in the Google Cloud console or programmatically using the Cloud Bigtable API. Adding nodes to a cluster can yield noticeable performance improvements within minutes. Some customers have successfully used an open source autoscaler developed by Spotify.
Internal maintenance
The Bigtable service seamlessly handles common Cassandra internal maintenance tasks such as OS patching, node recovery, node repair, storage compaction monitoring, and SSL certificate rotation.
Monitoring
Connecting Bigtable to metrics visualization or alerting doesn't require administration or development effort. The Bigtable Google Cloud console page comes with prebuilt dashboards for tracking throughput and utilization metrics at the instance, cluster, and table levels. Custom views and alerts can be created in the Cloud Monitoring dashboards, where metrics are automatically available.
The Bigtable Key Visualizer, a monitoring feature in the Google Cloud console, lets you perform advanced performance tuning.
IAM and security
In Bigtable, authorization is fully integrated into Google Cloud's IAM framework and requires minimal setup and maintenance. Local user accounts and passwords are not shared with client applications; instead, granular permissions and roles are granted to organization-level users and service accounts.
Bigtable automatically encrypts all data at rest and in transit. There are no options to disable these features. All administrative access is fully logged. You can use VPC Service Controls to control access to Bigtable instances from outside of approved networks.
What's next
- Read about Bigtable schema design.
- Try the Bigtable for Cassandra users codelab.
- Learn about the Bigtable emulator.
- Explore reference architectures, diagrams, and best practices about Google Cloud. Take a look at our Cloud Architecture Center.