Von DynamoDB zu Bigtable migrieren
Bigtable und DynamoDB sind verteilte Schlüssel/Wert-Paar-Speicher, die Millionen von Abfragen pro Sekunde (Queries per second, QPS) unterstützen, Speicher für eine Skalierung bis zu Petabyte an Daten sowie eine Toleranz bei Knotenausfällen bieten.
Dieses Dokument richtet sich an DynamoDB-Entwickler und Datenbankadministratoren, die zu Bigtable migrieren möchten. Es ist auch nützlich, wenn Sie Anwendungen für die Verwendung von Bigtable als Datenspeicher entwerfen möchten.
Verwenden Sie zum Einstieg ein von Google bereitgestelltes Migrationstool, mit dem Sie von DynamoDB zu Bigtable migrieren können. Auf dieser Seite wird das Migrationstool beschrieben. Außerdem werden die beiden Datenbanksysteme verglichen und die zugrunde liegende Architektur sowie die Interaktionsdetails beschrieben, die sich unterscheiden und die vor der Migration wichtig sind.
Erste Schritte mit dem DynamoDB-zu-Bigtable-Migrationstool
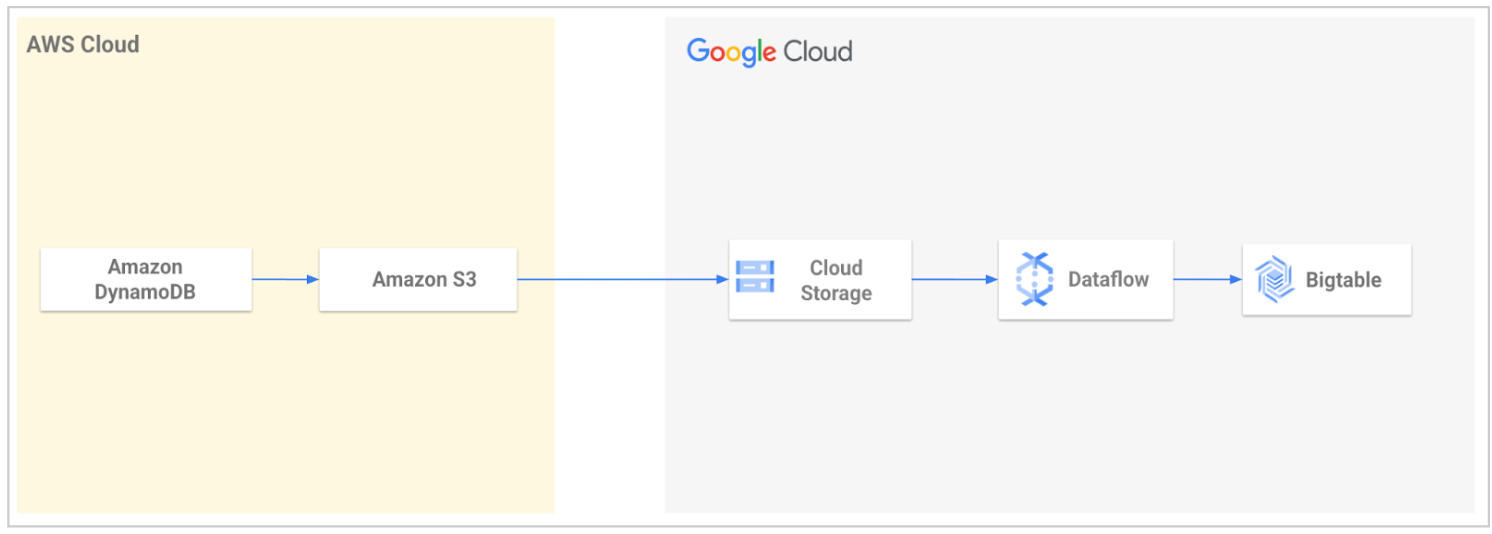
Google Cloud Professional Services bietet ein Open-Source-Migrationstool an, um die Migration von Daten von DynamoDB zu Bigtable zu optimieren. Das Tool automatisiert den Prozess des Importierens Ihrer Daten in Google Cloud und des anschließenden Ladens in Bigtable.
Mit dem Tool exportieren Sie Ihre DynamoDB-Tabelle und übertragen sie dann in Cloud Storage. Das Tool liest die exportierten Dateien aus Ihrem Cloud Storage-Bucket und verwendet eine Dataflow-Vorlage, um die Daten so zu transformieren, dass sie mit Bigtable kompatibel sind. Diese Transformation umfasst die Zuordnung von DynamoDB-Attributen zu Bigtable-Zeilen. Der Dataflow-Job schreibt die transformierten Daten dann in Ihre Bigtable-Tabelle.
Weitere Informationen oder eine Anleitung für die ersten Schritte finden Sie unter DynamoDB to Bigtable Migration Utility.
Vergleich von DynamoDB und Bigtable
In diesem Abschnitt werden die Ähnlichkeiten und Unterschiede zwischen DynamoDB und Bigtable untersucht.
Steuerungsebene
In DynamoDB und Bigtable können Sie mit der Steuerungsebene Ihre Kapazität konfigurieren sowie Ressourcen einrichten und verwalten. DynamoDB ist ein serverloses Produkt. Die höchste Interaktionsebene mit DynamoDB ist die Tabellenebene. Im Modus mit bereitgestellter Kapazität können Sie hier Ihre Lese- und Schreibanfrageeinheiten bereitstellen, Ihre Regionen und die Replikation auswählen und Sicherungen verwalten. Bigtable ist kein serverloses Produkt. Sie müssen eine Instanz mit einem oder mehreren Clustern erstellen, deren Kapazität durch die Anzahl der Knoten bestimmt wird. Weitere Informationen zu diesen Ressourcen finden Sie unter Instanzen, Cluster und Knoten.
In der folgenden Tabelle werden die Ressourcen der Steuerungsebene für DynamoDB und Bigtable verglichen.
| DynamoDB | Bigtable |
|---|---|
| Tabelle : Eine Sammlung von Elementen mit einem definierten Primärschlüssel. Tabellen haben Einstellungen für Sicherungen, Replikation und Kapazität. | Instanz:Eine Gruppe von Bigtable-Clustern in verschiedenen Google Cloud Zonen oder -Regionen, zwischen denen Replikation und Verbindungsrouting stattfinden. Replikationsrichtlinien werden auf Instanzebene festgelegt. Cluster:Eine Gruppe von Knoten in derselben geografischenGoogle Cloud -Zone, die aus Latenz- und Replikationsgründen idealerweise am selben Standort wie Ihr Anwendungsserver untergebracht sind. Die Kapazität wird durch Anpassen der Anzahl der Knoten in jedem Cluster verwaltet. Tabelle: Eine logische Struktur von Werten, die durch den Zeilenschlüssel indexiert sind. Sicherungen werden auf Tabellenebene gesteuert. |
Lese- und Schreibkapazitätseinheit (RCU und WCU):
Einheiten, die Lese- oder Schreibvorgänge pro Sekunde mit einer festen Nutzlastgröße ermöglichen. Für jeden Vorgang mit größeren Nutzlastgrößen werden Ihnen Lese- oder Schreibeinheiten in Rechnung gestellt.UpdateItem-Vorgänge verbrauchen die Schreibkapazität, die für die größte Größe eines aktualisierten Elements verwendet wird – entweder vor oder nach der Aktualisierung –, auch wenn die Aktualisierung nur eine Teilmenge der Attribute des Elements betrifft. |
Knoten:Eine virtuelle Computing-Ressource, die für das Lesen und Schreiben von Daten zuständig ist. Die Anzahl der Knoten in einem Cluster wirkt sich auf die Durchsatzlimits für Lese-, Schreib- und Scanvorgänge aus. Sie können die Anzahl der Knoten anpassen, je nach Kombination aus Latenzzielen, Anzahl der Anfragen und Nutzlastgröße. SSD-Knoten bieten den gleichen Durchsatz für Lese- und Schreibvorgänge, im Gegensatz zum erheblichen Unterschied zwischen RCU und WCU. Weitere Informationen finden Sie unter Leistung bei typischen Arbeitslasten. |
| Partition : Ein Block zusammenhängender Zeilen, der von Solid-State-Laufwerken (SSDs) gesichert wird, die sich am selben Standort wie die Knoten befinden. Für jede Partition gilt ein festes Limit von 1.000 WCUs, 3.000 RCUs und 10 GB Daten. |
Tablet : Ein Block zusammenhängender Zeilen, der vom Speichermedium der Wahl (SSD oder HDD) unterstützt wird. Tabellen werden in Tabellenreihen unterteilt, um die Arbeitslast auszugleichen. Tabellenreihen werden nicht auf Knoten in Bigtable gespeichert, sondern im verteilten Dateisystem von Google. Dies ermöglicht eine schnelle Neuverteilung von Daten beim Skalieren und bietet zusätzliche Beständigkeit durch die Aufbewahrung mehrerer Kopien. |
| Globale Tabellen : Eine Möglichkeit, die Verfügbarkeit und Langlebigkeit Ihrer Daten zu erhöhen, indem Datenänderungen automatisch in mehreren Regionen weitergegeben werden. | Replikation : Eine Möglichkeit, die Verfügbarkeit und Langlebigkeit Ihrer Daten zu erhöhen, indem Datenänderungen automatisch in mehreren Regionen oder mehreren Zonen innerhalb derselben Region weitergegeben werden. |
| Nicht zutreffend (–) | Anwendungsprofil : Einstellungen, die festlegen, wie Bigtable einen Client-API-Aufruf an den entsprechenden Cluster in der Instanz weiterleiten soll. Sie können auch ein App-Profil als Tag verwenden, um Messwerte für die Attribution zu segmentieren. |
Geografische Replikation
Die Replikation wird verwendet, um die Kundenanforderungen für Folgendes zu erfüllen:
- Hochverfügbarkeit für Geschäftskontinuität im Falle eines zonalen oder regionalen Ausfalls.
- Die Daten Ihres Dienstes werden in unmittelbarer Nähe der Endnutzer gespeichert, um eine geringe Latenz zu ermöglichen, unabhängig davon, wo sich die Nutzer auf der Welt befinden.
- Arbeitslastisolation, wenn Sie eine Batcharbeitslast in einem Cluster implementieren und die Replikation für Serving-Cluster nutzen müssen.
Bigtable unterstützt replizierte Cluster in so vielen Zonen, wie in bis zu acht Google Cloud Regionen verfügbar sind, in denen Bigtable verfügbar ist. Die meisten Regionen haben drei Zonen. Weitere Informationen finden Sie unter Regionen und Zonen.
Bigtable repliziert Daten automatisch zwischen Clustern in einer Multi-Primary-Topologie. Das bedeutet, dass Sie in jedem Cluster Lese- und Schreibvorgänge ausführen können. Die Bigtable-Replikation ist letztendlich konsistent. Weitere Informationen finden Sie unter Replikation.
DynamoDB bietet globale Tabellen zur Unterstützung der Tabellenreplikation in mehreren Regionen. Globale Tabellen sind Multi-Primary und werden automatisch regionenübergreifend repliziert. Die Replikation unterliegt der Eventual Consistency.
In der folgenden Tabelle sind die Replikationskonzepte aufgeführt und ihre Verfügbarkeit in DynamoDB und Bigtable beschrieben.
| Attribut | DynamoDB | Bigtable |
|---|---|---|
| Replikation mit mehreren primären Instanzen | Ja. Sie können Daten in jede globale Tabelle lesen und schreiben. |
Ja. Sie können Daten in jeden Bigtable-Cluster lesen und schreiben. |
| Konsistenzmodell | Letztendlich konsistent. Read-Your-Writes-Konsistenz auf regionaler Ebene für globale Tabellen. |
Letztendlich konsistent. Read-Your-Writes-Konsistenz auf Clusterebene für alle Tabellen, sofern Sie sowohl Lese- als auch Schreibvorgänge an denselben Cluster senden. |
| Replikationslatenz | Es gibt kein Service Level Agreement (SLA). Sekunden |
Kein SLA. Sekunden |
| Konfigurationsgranularität | Tabellenebene. | Instanzebene. Eine Instanz kann mehrere Tabellen enthalten. |
| Implementierung | Erstellen Sie eine globale Tabelle mit einer Tabellenreplik in jeder ausgewählten Region. Regionale Ebene. Automatische Replikation über Replikate hinweg durch Konvertieren einer Tabelle in eine globale Tabelle. In den Tabellen müssen DynamoDB-Streams aktiviert sein. Der Stream muss sowohl die neuen als auch die alten Bilder des Elements enthalten. Wenn Sie eine Region löschen, wird auch die globale Tabelle in dieser Region entfernt. |
Erstellen Sie eine Instanz mit mehreren Clustern. Die Replikation erfolgt automatisch zwischen den Clustern in dieser Instanz. Zonenebene. Cluster zu einer Bigtable-Instanz hinzufügen und daraus entfernen. |
| Replikationsoptionen | Pro Tabelle. | Pro Instanz. |
| Traffic-Routing und ‑Verfügbarkeit | Traffic wird an das geografisch nächstgelegene Replikat weitergeleitet. Im Fehlerfall wenden Sie benutzerdefinierte Geschäftslogik an, um zu bestimmen, wann Anfragen an andere Regionen weitergeleitet werden sollen. |
Verwenden Sie Anwendungsprofile, um Richtlinien für das Routing von Cluster-Traffic zu konfigurieren. Mit Multi-Cluster-Routing können Sie Traffic automatisch an den nächsten fehlerfreien Cluster weiterleiten. Im Fehlerfall unterstützt Bigtable das automatische Failover zwischen Clustern für Hochverfügbarkeit. |
| Skalierung | Die Schreibkapazität in replizierten Schreibanfrageeinheiten (R-WRU) wird über Replikate hinweg synchronisiert. Die Lesekapazität in replizierten Lesekapazitätseinheiten (R-RCU) gilt pro Replikat. |
Sie können Cluster unabhängig voneinander skalieren, indem Sie nach Bedarf Knoten zu den einzelnen replizierten Clustern hinzufügen oder daraus entfernen. |
| Kosten | R-WRUs kosten 50% mehr als reguläre WRUs. | Die Knoten und der Speicherplatz jedes Clusters werden Ihnen in Rechnung gestellt. Für die regionale Replikation über Zonen hinweg fallen keine Kosten für die Netzwerkreplikation an. Kosten fallen an, wenn die Replikation regions- oder kontinentübergreifend erfolgt. |
| SLA | 99,999 % | 99,999 % |
Datenebene
In der folgenden Tabelle werden die Konzepte für das Datenmodell für DynamoDB und Bigtable verglichen. Jede Zeile in der Tabelle beschreibt analoge Funktionen. Ein Element in DynamoDB entspricht beispielsweise einer Zeile in Bigtable.
| DynamoDB | Bigtable |
|---|---|
| Artikel : Eine Gruppe von Attributen, die durch ihren Primärschlüssel eindeutig von allen anderen Artikeln unterschieden werden kann. Die maximal zulässige Größe beträgt 400 KB. | Zeile : Eine einzelne Entität, die durch den Zeilenschlüssel identifiziert wird. Die maximal zulässige Größe beträgt 256 MB. |
| – | Spaltenfamilie:Ein benutzerdefinierter Namespace, der Spalten gruppiert. |
| Attribut : Eine Gruppierung aus einem Namen und einem Wert. Ein Attributwert kann ein skalarer Wert, ein Set oder ein Dokumenttyp sein. Es gibt kein explizites Limit für die Attributgröße. Da jedes Element jedoch auf 400 KB begrenzt ist, kann das Attribut eines Elements mit nur einem Attribut bis zu 400 KB minus der Größe des Attributnamens betragen. | Spaltenqualifizierer : Die eindeutige Kennung für eine Spalte innerhalb einer Spaltenfamilie. Die vollständige Kennung einer Spalte wird als „Spaltenfamilie:Spaltenqualifizierer“ angegeben. Spaltenqualifizierer werden innerhalb der Spaltenfamilie lexikografisch sortiert. Die maximal zulässige Größe für einen Spaltenqualifizierer beträgt 16 KB. Zelle:Eine Zelle enthält die Daten für eine bestimmte Zeile, Spalte und einen bestimmten Zeitstempel. Eine Zelle enthält einen Wert, der bis zu 100 MB groß sein kann. |
| Primärschlüssel : Eine eindeutige Kennung für ein Element in einer Tabelle. Es kann sich um einen Partitionierungsschlüssel oder einen zusammengesetzten Schlüssel handeln. Partitionierungsschlüssel: Ein einfacher Primärschlüssel, der aus einem Attribut besteht. Damit wird die physische Partition festgelegt, in der sich der Artikel befindet. Die maximal zulässige Größe beträgt 2 KB. Sortierschlüssel: Ein Schlüssel, der die Reihenfolge der Zeilen innerhalb einer Partition bestimmt. Die maximal zulässige Größe beträgt 1 KB. Zusammengesetzter Schlüssel: Ein Primärschlüssel, der aus zwei Attributen besteht, dem Partitionierungsschlüssel und einem Sortierschlüssel oder Bereichsattribut. |
Zeilenschlüssel : Eine eindeutige Kennung für ein Element in einer Tabelle.
Wird in der Regel durch eine Verkettung von Werten und Trennzeichen dargestellt.
Die maximal zulässige Größe beträgt 4 KB. Mit Spaltenqualifizierern lässt sich ein Verhalten erzielen, das dem Sortierschlüssel von DynamoDB entspricht. Zusammengesetzte Schlüssel können mit verketteten Zeilenschlüsseln und Spaltenqualifizierern erstellt werden. Weitere Informationen finden Sie im Beispiel zur Schemaübersetzung im Abschnitt „Schemadesign“ in diesem Dokument. |
| Gültigkeitsdauer : Anhand der Zeitstempel für die einzelnen Elemente wird bestimmt, wann ein Element nicht mehr benötigt wird. Nach dem Datum und der Uhrzeit des angegebenen Zeitstempels wird das Element aus Ihrer Tabelle gelöscht, ohne dass Schreibdurchsatz verbraucht wird. | Automatische Speicherbereinigung : Anhand von Zeitstempeln pro Zelle wird bestimmt, wann ein Element nicht mehr benötigt wird. Bei der automatischen Speicherbereinigung werden abgelaufene Elemente während eines Hintergrundprozesses namens Verdichtung gelöscht. Richtlinien für die automatische Speicherbereinigung werden auf der Ebene der Spaltenfamilie festgelegt. Elemente können nicht nur anhand ihres Alters gelöscht werden, sondern auch entsprechend der Anzahl der Versionen, die der Nutzer beibehalten möchte. Sie müssen bei der Dimensionierung Ihrer Cluster keine Kapazität für die Komprimierung berücksichtigen. |
| Globaler sekundärer Index : Eine Tabelle, die ausgewählte Attribute aus der Basistabelle enthält, die nach einem Primärschlüssel organisiert sind, der sich von dem der Tabelle unterscheidet. Der Indexschlüssel muss keine der Schlüsselattribute aus der Tabelle enthalten. Sie muss nicht dasselbe Schlüssel-Schema wie die Tabelle haben. DynamoDB aktualisiert globale sekundäre Indexe asynchron. | Asynchroner sekundärer Index : Wenn Sie dieselben Daten mit verschiedenen Suchmustern oder Attributen abfragen möchten, können Sie einen asynchronen sekundären Index erstellen. Dieser Index enthält ausgewählte Attribute aus der Basistabelle. Diese Attribute werden durch einen Schlüssel organisiert, der sich vom eigenen Schlüssel der Tabelle unterscheidet. Das Verhalten ähnelt dem von globalen sekundären Indexen in DynamoDB. |
Vorgänge
Mit Data Plane-Vorgängen können Sie CRUD-Aktionen (Erstellen, Lesen, Aktualisieren und Löschen) für Daten in einer Tabelle ausführen. In der folgenden Tabelle werden ähnliche Datenebenenoperationen für DynamoDB und Bigtable verglichen.
| DynamoDB | Bigtable |
|---|---|
CreateTable |
CreateTable |
PutItemBatchWriteItem |
MutateRow MutateRowsIn Bigtable werden Schreibvorgänge als Upserts behandelt. |
UpdateItem
|
In Bigtable werden Schreibvorgänge als Upserts behandelt. |
GetItemBatchGetItem, Query, Scan |
`ReadRow`` ReadRows` (range, prefix, reverse scan)Bigtable unterstützt effizientes Scannen nach Zeilenschlüsselpräfix, regulärem Ausdruck oder Zeilenschlüsselbereich vorwärts oder rückwärts. |
Datentypen
Sowohl Bigtable als auch DynamoDB sind schemalos. Spalten können zur Schreibzeit definiert werden, ohne dass die Existenz von Spalten oder Datentypen für die gesamte Tabelle erzwungen wird. Ebenso kann sich der Datentyp einer bestimmten Spalte oder eines bestimmten Attributs von Zeile zu Zeile oder von Element zu Element unterscheiden. Die DynamoDB- und Bigtable-APIs verarbeiten Datentypen jedoch unterschiedlich.
Jede DynamoDB-Schreibanfrage enthält eine Typdefinition für jedes Attribut, die mit der Antwort für Leseanfragen zurückgegeben wird.
In Bigtable wird alles als Byte behandelt. Der Clientcode muss den Typ und die Codierung kennen, damit der Client die Antworten richtig parsen kann. Eine Ausnahme bilden Inkrementierungsvorgänge, bei denen die Werte als 64-Bit-Big-Endian-Ganzzahlen mit Vorzeichen interpretiert werden.
In der folgenden Tabelle werden die Unterschiede bei Datentypen zwischen DynamoDB und Bigtable verglichen.
| DynamoDB | Bigtable |
|---|---|
| Skalare Typen : Werden als Tokens für Datentypdeskriptoren in der Serverantwort zurückgegeben. | Bytes : Bytes werden in der Clientanwendung in die vorgesehenen Typen umgewandelt. Bei Increment wird der Wert als 64-Bit-Big-Endian-Ganzzahl mit Vorzeichen interpretiert. |
| Menge : Eine unsortierte Sammlung eindeutiger Elemente. | Spaltenfamilie : Sie können Spaltenqualifizierer als Set-Mitgliedsnamen verwenden und für jeden einen einzelnen 0-Byte-Wert als Zellwert angeben. Mengenmitglieder werden innerhalb ihrer Spaltenfamilie lexikografisch sortiert. |
| Map : Eine unsortierte Sammlung von Schlüssel/Wert-Paaren mit eindeutigen Schlüsseln. | Spaltenfamilie Verwenden Sie den Spaltenqualifizierer als Mapschlüssel und den Zellwert als Wert. Die Schlüssel von Maps werden lexikografisch sortiert. |
| Liste : Eine sortierte Sammlung von Elementen. | Spaltenqualifizierer Verwenden Sie den Einfügezeitstempel, um das Äquivalent des list_append-Verhaltens zu erreichen. Verwenden Sie den umgekehrten Einfügezeitstempel, um voranzustellen. |
Schemadesign
Eine wichtige Überlegung beim Schemadesign ist, wie die Daten gespeichert werden. Zu den wichtigsten Unterschieden zwischen Bigtable und DynamoDB gehört, wie sie Folgendes handhaben:
- Aktualisierungen einzelner Werte
- Datensortierung
- Versionsverwaltung für Daten
- Speichern großer Werte
Aktualisierungen einzelner Werte
UpdateItem-Vorgänge in DynamoDB verbrauchen die Schreibkapazität für die größere der Elementgrößen „vor“ und „nach“ dem Vorgang, auch wenn das Update nur eine Teilmenge der Attribute des Elements umfasst. Das bedeutet, dass Sie in DynamoDB häufig aktualisierte Spalten in separate Zeilen einfügen können, auch wenn sie logisch mit anderen Spalten in derselben Zeile enthalten sein sollten.
Bigtable kann eine Zelle genauso effizient aktualisieren, unabhängig davon, ob sie die einzige Spalte in einer bestimmten Zeile oder eine von vielen Tausenden ist. Weitere Informationen finden Sie unter Einfache Schreibvorgänge.
Datensortierung
In DynamoDB werden Partitionsschlüssel gehasht und zufällig verteilt, während in Bigtable Zeilen in lexikografischer Reihenfolge nach Zeilenschlüssel gespeichert werden und das Hashing dem Nutzer überlassen wird.
Die zufällige Schlüsselverteilung ist nicht für alle Zugriffsmuster optimal. Dadurch wird das Risiko von Hot-Row-Bereichen verringert, aber Zugriffsmuster, die Scans umfassen, die Partitionsgrenzen überschreiten, werden teuer und ineffizient. Diese unbegrenzten Scans sind häufig, insbesondere bei Anwendungsfällen mit einer Zeitdimension.
Für die Verarbeitung dieses Zugriffsmusters – Scans, die Partitionsgrenzen überschreiten – ist in DynamoDB ein sekundärer Index erforderlich, in Bigtable jedoch nicht. Sie können den lexikografischen Zeilenschlüssel in Bigtable so gestalten, dass viele Scanmuster effizient verarbeitet werden. Bigtable unterstützt aber auch asynchrone sekundäre Indexe, die Sie als kontinuierliche materialisierte Ansichten implementieren können, um effiziente, letztendlich konsistente Suchvorgänge für alternative Abfragemuster zu ermöglichen. In DynamoDB sind Abfrage- und Scanvorgänge ebenfalls auf 1 MB gescannter Daten beschränkt, was über dieses Limit hinaus eine Paginierung erfordert. Für Bigtable gilt keine solche Beschränkung.
Trotz der zufällig verteilten Partitionsschlüssel kann es in DynamoDB weiterhin Hot Partitions geben, wenn ein ausgewählter Partitionsschlüssel den Traffic nicht gleichmäßig verteilt, was sich negativ auf den Durchsatz auswirkt. Um dieses Problem zu beheben, empfiehlt DynamoDB Write-Sharding, bei dem Schreibvorgänge zufällig auf mehrere logische Partitionsschlüsselwerte aufgeteilt werden.
Um dieses Designmuster anzuwenden, müssen Sie eine Zufallszahl aus einer festen Menge (z. B. 1 bis 10) erstellen und diese Zahl dann als logischen Partitionsschlüssel verwenden. Da Sie den Partitionierungsschlüssel zufällig festlegen, werden die Schreibvorgänge in die Tabelle gleichmäßig auf alle Werte des Partitionierungsschlüssels verteilt.
In Bigtable wird dieses Verfahren als Schlüssel-Salting bezeichnet. Es kann eine effektive Methode sein, um häufig genutzte Tabellen zu vermeiden.
Versionsverwaltung für Daten
Jede Bigtable-Zelle hat einen Zeitstempel und der neueste Zeitstempel ist immer der Standardwert für eine bestimmte Spalte. Ein häufiger Anwendungsfall für Zeitstempel ist die Versionsverwaltung. Dabei wird eine neue Zelle in eine Spalte geschrieben, die sich von früheren Versionen der Daten für diese Zeile und Spalte durch ihren Zeitstempel unterscheidet.
DynamoDB hat kein solches Konzept und erfordert komplexe Schemadesigns, um die Versionsverwaltung zu unterstützen. Bei diesem Ansatz werden zwei Kopien jedes Elements erstellt: eine Kopie mit dem Versionsnummernpräfix 0, z. B. v0_, am Anfang des Sortierschlüssels und eine weitere Kopie mit dem Versionsnummernpräfix 1, z. B. v1_. Jedes Mal, wenn das Element aktualisiert wird, verwenden Sie das nächsthöhere Versionspräfix im Sortierschlüssel der aktualisierten Version und kopieren den aktualisierten Inhalt in das Element mit dem Versionspräfix 0. So wird sichergestellt, dass die neueste Version eines Elements mit der Null vor der Versionsnummer gefunden werden kann. Diese Strategie erfordert nicht nur Anwendungslogik, sondern macht auch das Schreiben von Daten sehr teuer und langsam, da für jeden Schreibvorgang ein Lesen des vorherigen Werts sowie zwei Schreibvorgänge erforderlich sind.
Transaktionen mit mehreren Zeilen im Vergleich zu großer Zeilenkapazität
Bigtable unterstützt keine mehrzeiligen Transaktionen. Da Sie damit jedoch Zeilen speichern können, die viel größer sind als Elemente in DynamoDB, können Sie die beabsichtigte Transaktionalität oft erreichen, indem Sie Ihre Schemas so gestalten, dass relevante Elemente unter einem gemeinsamen Zeilenschlüssel gruppiert werden. Ein Beispiel für diesen Ansatz finden Sie unter Entwurfsmuster für einzelne Tabellen.
Große Werte speichern
Da ein DynamoDB-Element, das einer Bigtable-Zeile entspricht, auf 400 KB begrenzt ist, müssen große Werte entweder auf mehrere Elemente aufgeteilt oder in anderen Medien wie S3 gespeichert werden. Beide Ansätze erhöhen die Komplexität Ihrer Anwendung. Im Gegensatz dazu kann eine Bigtable-Zelle bis zu 100 MB und eine Bigtable-Zeile bis zu 256 MB speichern.
Beispiele für die Schemaübersetzung
In den Beispielen in diesem Abschnitt werden Schemas von DynamoDB in Bigtable übersetzt. Dabei werden die wichtigsten Unterschiede beim Entwurf von Schlüsselschemas berücksichtigt.
Einfache Schemas migrieren
Produktkataloge sind ein gutes Beispiel für das grundlegende Schlüssel/Wert-Muster. So könnte ein solches Schema in DynamoDB aussehen.
| Primärschlüssel | Attribute | |||
|---|---|---|---|---|
| Partitionsschlüssel | Sortierschlüssel | Beschreibung | Preis | Miniaturansicht |
| Hüte | fedoras#brandA | Aus hochwertiger Wolle gefertigt… | 30 | https://storage… |
| Hüte | fedoras#brandB | Robustes, wasserabweisendes Canvas-Material, das… | 28 | https://storage… |
| Hüte | newsboy#brandB | Verleihe deinem Alltagslook einen Hauch von Vintage-Charme. | 25 | https://storage… |
| Schuhe | sneakers#brandA | Mit diesen Produkten sind Sie immer stilvoll und bequem unterwegs: | 40 | https://storage… |
| Schuhe | sneakers#brandB | Klassische Funktionen mit modernen Materialien… | 50 | https://storage… |
Für diese Tabelle ist die Zuordnung von DynamoDB zu Bigtable einfach: Sie wandeln den zusammengesetzten Primärschlüssel von DynamoDB in einen zusammengesetzten Bigtable-Zeilenschlüssel um. Sie erstellen eine Spaltenfamilie (SKU), die dieselben Spalten enthält.
| SKU | |||
|---|---|---|---|
| Zeilenschlüssel | Beschreibung | Preis | Miniaturansicht |
| hüte#filzhüte#markeA | Aus hochwertiger Wolle gefertigt… | 30 | https://storage… |
| hüte#fedoras#brandB | Robustes, wasserabweisendes Canvas-Material, das… | 28 | https://storage… |
| hats#newsboy#brandB | Verleihe deinem Alltagslook einen Hauch von Vintage-Charme. | 25 | https://storage… |
| shoes#sneakers#brandA | Mit diesen Produkten sind Sie immer stilvoll und bequem unterwegs: | 40 | https://storage… |
| schuhe#sneakers#markeB | Klassische Funktionen mit modernen Materialien… | 50 | https://storage… |
Muster für einzelne Tabellen
Bei diesem Designmuster werden mehrere Tabellen aus einer relationalen Datenbank in einer einzigen Tabelle in DynamoDB zusammengeführt. Sie können das Schema aus dem vorherigen Beispiel unverändert in Bigtable duplizieren. Es ist jedoch besser, die Probleme des Schemas im Prozess zu beheben.
In diesem Schema enthält der Partitionsschlüssel die eindeutige ID für ein Video. So können alle Attribute, die sich auf dieses Video beziehen, für einen schnelleren Zugriff zusammengefasst werden. Aufgrund der Beschränkungen für die Elementgröße in DynamoDB können Sie nicht unbegrenzt viele Freitextkommentare in eine einzelne Zeile einfügen. Daher wird ein Sortierschlüssel mit dem Muster VideoComment#reverse-timestamp verwendet, um jeden Kommentar in eine separate Zeile innerhalb der Partition zu schreiben, die in umgekehrt chronologischer Reihenfolge sortiert ist.
Angenommen, dieses Video hat 500 Kommentare und der Rechteinhaber möchte das Video entfernen. Das bedeutet, dass auch alle Kommentare und Videoattribute gelöscht werden müssen. Dazu müssen Sie in DynamoDB alle Schlüssel in dieser Partition scannen und dann mehrere Löschanfragen stellen, wobei Sie jeden Schlüssel durchlaufen. DynamoDB unterstützt Transaktionen mit mehreren Zeilen, aber diese Löschanfrage ist zu groß, um sie in einer einzelnen Transaktion auszuführen.
| Primärschlüssel | Attribute | |||
|---|---|---|---|---|
| Partitionsschlüssel | Sortierschlüssel | UploadDate | Formate | |
| 0123 | Video | 2023-09-10T15:21:48 | {"480": "https://storage…", "720": "https://storage…", "1080p": "https://storage…"} | |
| VideoComment#98765481 | Inhalt | |||
| Das gefällt mir sehr gut. Spezialeffekte sind beeindruckend. | ||||
| VideoComment#86751345 | Inhalt | |||
| Bei 1:05 scheint ein Audiofehler aufzutreten. | ||||
| VideoStatsLikes | Anzahl | |||
| 3 | ||||
| VideoStatsViews | Anzahl | |||
| 156 | ||||
| 0124 | Video | 2023-09-10T17:03:21 | {"480": "https://storage…", "720": "https://storage…"} | |
| VideoComment#97531849 | Inhalt | |||
| Ich habe das mit allen meinen Freunden geteilt. | ||||
| VideoComment#87616471 | Inhalt | |||
| Der Stil erinnert mich an einen Filmregisseur, aber ich kann ihn nicht genau zuordnen. | ||||
| VideoStats | ViewCount | |||
| 45 | ||||
Passen Sie dieses Schema während der Migration an, damit Sie Ihren Code vereinfachen und Datenanfragen schneller und kostengünstiger stellen können. Bigtable-Zeilen haben eine viel größere Kapazität als DynamoDB-Elemente und können eine große Anzahl von Kommentaren verarbeiten. Wenn ein Video Millionen von Kommentaren erhält, können Sie eine Richtlinie für die Garbage Collection festlegen, um nur eine bestimmte Anzahl der neuesten Kommentare beizubehalten.
Da Zähler aktualisiert werden können, ohne dass die gesamte Zeile aktualisiert werden muss, müssen Sie sie auch nicht aufteilen. Sie müssen auch keine UploadDate-Spalte verwenden oder einen umgekehrten Zeitstempel berechnen und als Sortierschlüssel festlegen, da Bigtable-Zeitstempel die Kommentare automatisch in umgekehrt chronologischer Reihenfolge liefern. Das Schema wird dadurch erheblich vereinfacht. Wenn ein Video entfernt wird, können Sie die Zeile des Videos einschließlich aller Kommentare in einer einzigen Anfrage transaktional entfernen.
Da Spalten in Bigtable lexikografisch sortiert sind, können Sie die Spalten als Optimierung so umbenennen, dass ein schneller Bereichsscan – von den Videoattributen bis zu den N neuesten Kommentaren – in einer einzigen Leseanfrage möglich ist. Das ist sinnvoll, wenn das Video geladen wird. Später können Sie dann durch die restlichen Kommentare blättern, während der Zuschauer scrollt.
| Attribute | ||||
|---|---|---|---|---|
| Zeilenschlüssel | Formate | „Mag ich“-Bewertungen | Aufrufe | UserComments |
| 0123 | {"480": "https://storage…", "720": "https://storage…", "1080p": "https://storage…"} @2023-09-10T15:21:48 | 3 | 156 | Das gefällt mir sehr gut. Spezialeffekte sind beeindruckend. @
2023-09-10T19:01:15 Bei 1:05 scheint ein Audiofehler aufzutreten. @ 2023-09-10T16:30:42 |
| 0124 | {"480": "https://storage…", "720":"https://storage…"} @2023-09-10T17:03:21 | 45 | Der Stil erinnert mich an einen Filmregisseur, aber ich kann ihn nicht genau zuordnen. @2023-10-12T07:08:51 | |
Designmuster für Adjazenzliste
Eine leicht abweichende Version dieses Designs wird in DynamoDB oft als „Adjacency List Design Pattern“ bezeichnet.
| Primärschlüssel | Attribute | |||
|---|---|---|---|---|
| Partitionsschlüssel | Sortierschlüssel | DateCreated | Details | |
| Invoice-0123 | Invoice-0123 | 2023-09-10T15:21:48 | {"discount": 0.10, "sales_tax_usd":"8", "due_date":"2023-10-03.."} |
|
| Payment-0680 | 2023-09-10T15:21:40 | {"amount_usd": 120, "bill_to":"John…", "address":"123 Abc St…"} |
||
| Payment-0789 | 2023-09-10T15:21:31 | {"amount_usd": 120, "bill_to":"Jane…", "address":"13 Xyz St…"} |
||
| Invoice-0124 | Invoice-0124 | 2023-09-09T10:11:28 | {"discount": 0.20, "sales_tax_usd":"11", "due_date":"2023-10-03.."} |
|
| Payment-0327 | 2023-09-09T10:11:10 | {"amount_usd": 180, "bill_to":"Bob…", "address":"321 Cba St…"} |
||
| Payment-0275 | 2023-09-09T10:11:03 | {"amount_usd": 70, "bill_to":"Kate…", "address":"21 Zyx St…"} |
||
In dieser Tabelle basieren die Sortierschlüssel nicht auf der Zeit, sondern auf Zahlungs-IDs. Sie können also ein anderes Muster für breite Spalten verwenden und diese IDs in separate Spalten in Bigtable aufteilen. Das hat ähnliche Vorteile wie im vorherigen Beispiel.
| Rechnung | Zahlung | |||
|---|---|---|---|---|
| Zeilenschlüssel | Details | 0680 | 0789 | |
| 0123 | {"discount": 0.10, "sales_tax_usd":"8", "due_date":"2023-10-03.."} @ 2023-09-10T15:21:48 |
{"amount_usd": 120, "bill_to":"John…", "address":"123 Abc St…"} @ 2023-09-10T15:21:40 |
{"amount_usd": 120, "bill_to":"Jane…", "address":"13 Xyz St…"} @ 2023-09-10T15:21:31 |
|
| Zeilenschlüssel | Details | 0275 | 0327 | |
| 0124 | {"discount": 0.20, "sales_tax_usd":"11", "due_date":"2023-10-03.."} @ 2023-09-09T10:11:28 |
{"amount_usd": 70, "bill_to":"Kate…", "address":"21 Zyx St…"} @ 2023-09-09T10:11:03 |
{"amount_usd": 180, "bill_to":"Bob…", "address":"321 Cba St…"} @ 2023-09-09T10:11:10 |
|
Wie Sie in den vorherigen Beispielen sehen, kann das Wide-Column-Modell von Bigtable mit dem richtigen Schemadesign sehr leistungsstark sein und viele Anwendungsfälle abdecken, die in anderen Datenbanken teure Transaktionen mit mehreren Zeilen, sekundäre Indexierung oder das Kaskadenverhalten beim Löschen erfordern würden.
Nächste Schritte
- Erfahren Sie mehr über das Bigtable-Schemadesign.
- Erfahren Sie mehr über den Bigtable-Emulator.
- Referenzarchitekturen, Diagramme und Best Practices zuGoogle Cloudkennenlernen. Weitere Informationen zu Cloud Architecture Center