La trascrizione vocale ti consente di convertire i dati audio in streaming in testo trascritto in tempo reale. Agent Assist formula suggerimenti basati sul testo, pertanto i dati audio devono essere convertiti prima di poter essere utilizzati. Puoi anche utilizzare l'audio in streaming trascritto con Conversational Insights per raccogliere dati in tempo reale sulle conversazioni degli agenti (ad esempio, Topic Modeling).
Esistono due modi per trascrivere l'audio in streaming da utilizzare con Agent Assist: utilizzando la funzionalità SIPREC o effettuando chiamate gRPC con dati audio come payload. Questa pagina descrive il processo di trascrizione dei dati audio in streaming utilizzando le chiamate gRPC.
La trascrizione vocale funziona utilizzando il riconoscimento vocale in streaming di Speech-to-Text. Speech-to-Text offre più modelli di riconoscimento, standard e avanzati. La trascrizione vocale è supportata a livello di GA solo se utilizzata con il modello telefonia.
Prerequisiti
- Crea un progetto in Google Cloud.
- Abilita l'API Dialogflow.
- Contatta il tuo rappresentante di Google per assicurarti che il tuo account abbia accesso ai modelli migliorati di Speech-to-Text.
Creare un profilo di conversazione
Per creare un profilo di conversazione, utilizza la console Agent Assist o chiama il metodo create sulla risorsa ConversationProfile direttamente.
Per la trascrizione vocale, ti consigliamo di configurare
ConversationProfile.stt_config come InputAudioConfig predefinito quando invii
dati audio in una conversazione.
![]()
Ottenere trascrizioni durante l'esecuzione della conversazione
Per ottenere le trascrizioni in fase di runtime della conversazione, devi creare i partecipanti alla conversazione e inviare i dati audio per ciascun partecipante.
Creare partecipanti
Esistono tre tipi di
partecipante.
Per maggiori dettagli sui ruoli, consulta la documentazione
di riferimento. Chiama il metodo create su
participant e specifica role. Solo un partecipante END_USER o HUMAN_AGENT
può chiamare StreamingAnalyzeContent, che è necessario per ottenere una
trascrizione.
Inviare dati audio e ricevere una trascrizione
Puoi utilizzare
StreamingAnalyzeContent
per inviare l'audio di un partecipante a Google e ottenere la trascrizione, con i
seguenti parametri:
La prima richiesta nel flusso deve essere
InputAudioConfig. I campi configurati qui sostituiscono le impostazioni corrispondenti inConversationProfile.stt_config. Non inviare alcun input audio fino alla seconda richiesta.audioEncodingdeve essere impostato suAUDIO_ENCODING_LINEAR_16oAUDIO_ENCODING_MULAW.model: il modello di sintesi vocale che vuoi utilizzare per trascrivere l'audio. Imposta questo campo sutelephony. La variante non influisce sulla qualità della trascrizione, quindi puoi lasciare Variante del modello di riconoscimento vocale non specificata o scegliere Usa la migliore disponibile.singleUtterancedeve essere impostato sufalseper una qualità ottimale della trascrizione. Non devi aspettartiEND_OF_SINGLE_UTTERANCEsesingleUtteranceèfalse, ma puoi fare affidamento suisFinal==trueall'interno diStreamingAnalyzeContentResponse.recognition_resultper chiudere a metà lo stream.- Parametri aggiuntivi facoltativi: i seguenti parametri sono
facoltativi. Per ottenere l'accesso a questi parametri, contatta il tuo rappresentante di Google.
languageCode:language_codedell'audio. Il valore predefinito èen-US.alternativeLanguageCodes: questa è una funzionalità di anteprima. Altre lingue che potrebbero essere rilevate nell'audio. Agent Assist utilizza il campolanguage_codeper rilevare automaticamente la lingua all'inizio dell'audio e la imposta come predefinita in tutti i turni di conversazione successivi. Il campoalternativeLanguageCodesti consente di specificare più opzioni tra cui scegliere per Agent Assist.phraseSets: il nome della risorsa adattamento del modello Speech-to-TextphraseSet. Per utilizzare l'adattamento del modello con la trascrizione vocale, devi prima crearephraseSetutilizzando l'API Speech-to-Text e specificare il nome della risorsa qui.
Dopo aver inviato la seconda richiesta con il payload audio, dovresti iniziare a ricevere alcuni
StreamingAnalyzeContentResponsesdallo stream.- Puoi chiudere a metà lo stream (o interrompere l'invio in alcune lingue come
Python) quando vedi
is_finalimpostato sutrueinStreamingAnalyzeContentResponse.recognition_result. - Dopo aver chiuso parzialmente lo stream, il server invierà la risposta contenente la trascrizione finale, insieme a potenziali suggerimenti di Dialogflow o di Assistente agente.
- Puoi chiudere a metà lo stream (o interrompere l'invio in alcune lingue come
Python) quando vedi
Puoi trovare la trascrizione finale nelle seguenti posizioni:
StreamingAnalyzeContentResponse.message.content.- Se attivi le notifiche Pub/Sub, puoi visualizzare anche la trascrizione in Pub/Sub.
Avvia un nuovo stream dopo la chiusura di quello precedente.
- Invio di nuovo dell'audio: i dati audio generati dopo l'ultimo
speech_end_offsetdella risposta conis_final=trueal nuovo orario di inizio dello stream devono essere inviati di nuovo aStreamingAnalyzeContentper una migliore qualità della trascrizione.
- Invio di nuovo dell'audio: i dati audio generati dopo l'ultimo
Ecco il diagramma che illustra il funzionamento dello stream.
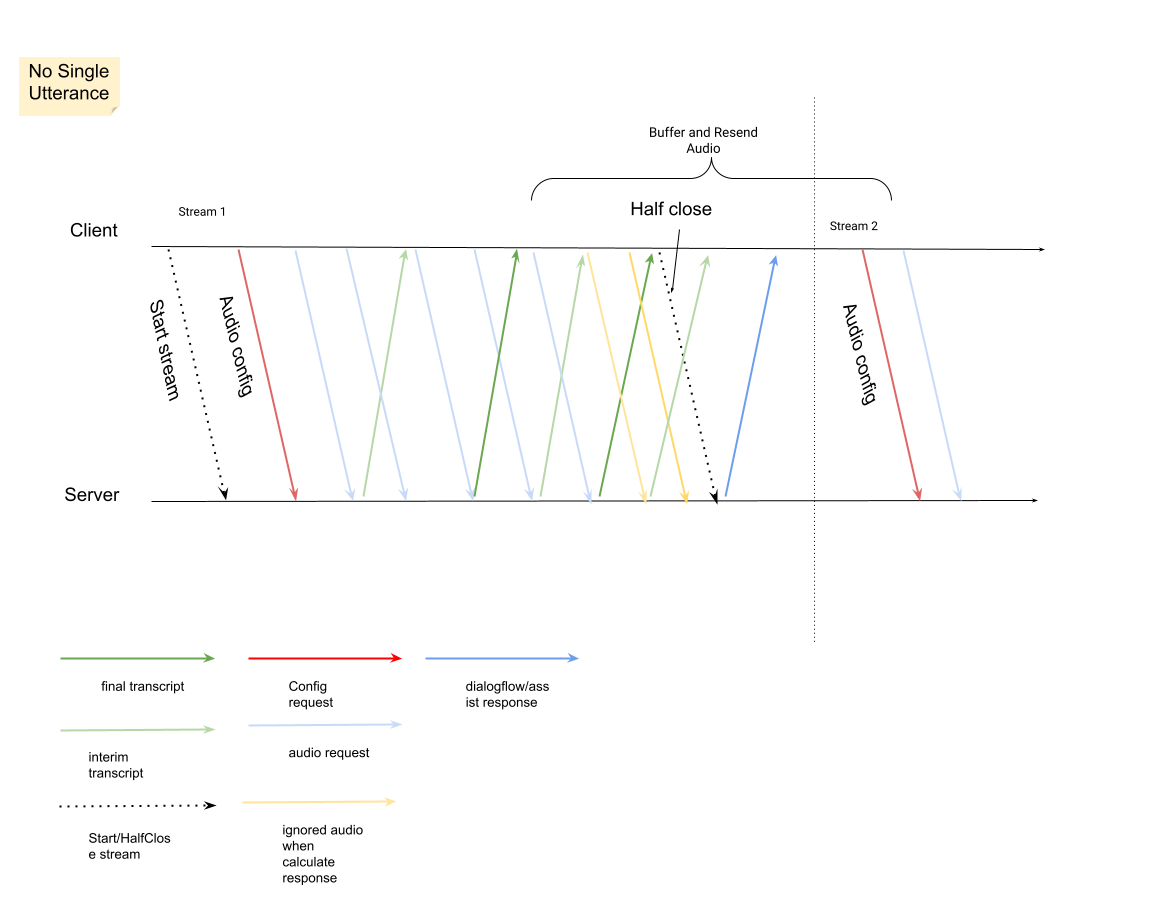
Esempio di codice di richiesta di riconoscimento di audio in streaming
Il seguente esempio di codice mostra come inviare una richiesta di trascrizione in streaming:
Python
Per eseguire l'autenticazione in Agent Assist, configura le Credenziali predefinite dell'applicazione. Per ulteriori informazioni, consulta Configura l'autenticazione per un ambiente di sviluppo locale.