Voice transcription lets you convert your streaming audio data to transcripted text in real time. Agent Assist makes suggestions based on text, so audio data must be converted before it can be used. You can also use transcripted streaming audio with Conversational Insights to gather real-time data about agent conversations (for example, Topic Modeling).
There are two ways to transcribe streaming audio for use with Agent Assist: By using the SIPREC feature, or by making gRPC calls with audio data as payload. This page describes the process of transcribing streaming audio data using gRPC calls.
Voice transcription works using Speech-to-Text streaming speech recognition. Speech-to-Text offers multiple recognition models, standard and enhanced. Voice transcription is supported at the GA level only when it's used with the telephony model.
Prerequisites
- Create a project in Google Cloud.
- Enable the Dialogflow API.
- Contact your Google representative to make sure that your account has access to Speech-to-Text enhanced models.
Create a conversation profile
To create a conversation profile, use
the
Agent Assist console or call the create method on the
ConversationProfile
resource directly.
For voice transcription, we recommend that you configure
ConversationProfile.stt_config as the default InputAudioConfig when sending
audio data in a conversation.
![]()
Get transcriptions at conversation runtime
To get transcriptions at conversation runtime, you need to create participants for the conversation, and send audio data for each participant.
Create participants
There are three types of
participant.
See the reference
documentation
for more details about their roles. Call the create method on the
participant and specify the role. Only an END_USER or a HUMAN_AGENT
participant can call StreamingAnalyzeContent, which is required to get a
transcription.
Send audio data and get a transcript
You can use
StreamingAnalyzeContent
to send a participant's audio to Google and get transcription, with the
following parameters:
The first request in the stream must be
InputAudioConfig. (The fields configured here override the corresponding settings atConversationProfile.stt_config.) Don't send any audio input until the second request.audioEncodingneeds to be set toAUDIO_ENCODING_LINEAR_16orAUDIO_ENCODING_MULAW.model: This is the Speech-to-Text model that you want to use to transcribe your audio. Set this field totelephony. The variant doesn't impact transcription quality so, you can leave Speech model variant unspecified or choose Use best available.singleUtteranceshould be set tofalsefor best transcription quality. You should not expectEND_OF_SINGLE_UTTERANCEifsingleUtteranceisfalse, but you can depend onisFinal==trueinsideStreamingAnalyzeContentResponse.recognition_resultto half-close the stream.- Optional additional parameters: The following parameters are
optional. To gain access to these parameters, contact your Google
representative.
languageCode:language_codeof the audio. The default value isen-US.alternativeLanguageCodes: This is a preview feature. Additional languages that might be detected in the audio. Agent Assist uses thelanguage_codefield to automatically detect the language at the beginning of the audio and defaults to it in all following conversation turns. ThealternativeLanguageCodesfield lets you specify more options for Agent Assist to choose from.phraseSets: The Speech-to-Text model adaptationphraseSetresource name. To use model adaptation with voice transcription you must first create thephraseSetusing the Speech-to-Text API and specify the resource name here.
After you send the second request with audio payload, you should start receiving some
StreamingAnalyzeContentResponsesfrom the stream.- You can half close the stream (or stop sending in some languages like
Python) when you see
is_finalset totrueinStreamingAnalyzeContentResponse.recognition_result. - After you half-close the stream, the server will send back the response containing final transcript, along with potential Dialogflow suggestions or Agent Assist suggestions.
- You can half close the stream (or stop sending in some languages like
Python) when you see
You can find the final transcription in the following locations:
StreamingAnalyzeContentResponse.message.content.- If you enable Pub/Sub notifications, you can also see the transcription in Pub/Sub.
Start a new stream after the previous stream is closed.
- Audio re-send: Audio data generated after last
speech_end_offsetof the response withis_final=trueto the new stream start time needs to be re-sent toStreamingAnalyzeContentfor best transcription quality.
- Audio re-send: Audio data generated after last
Here is the diagram illustrate how stream works.
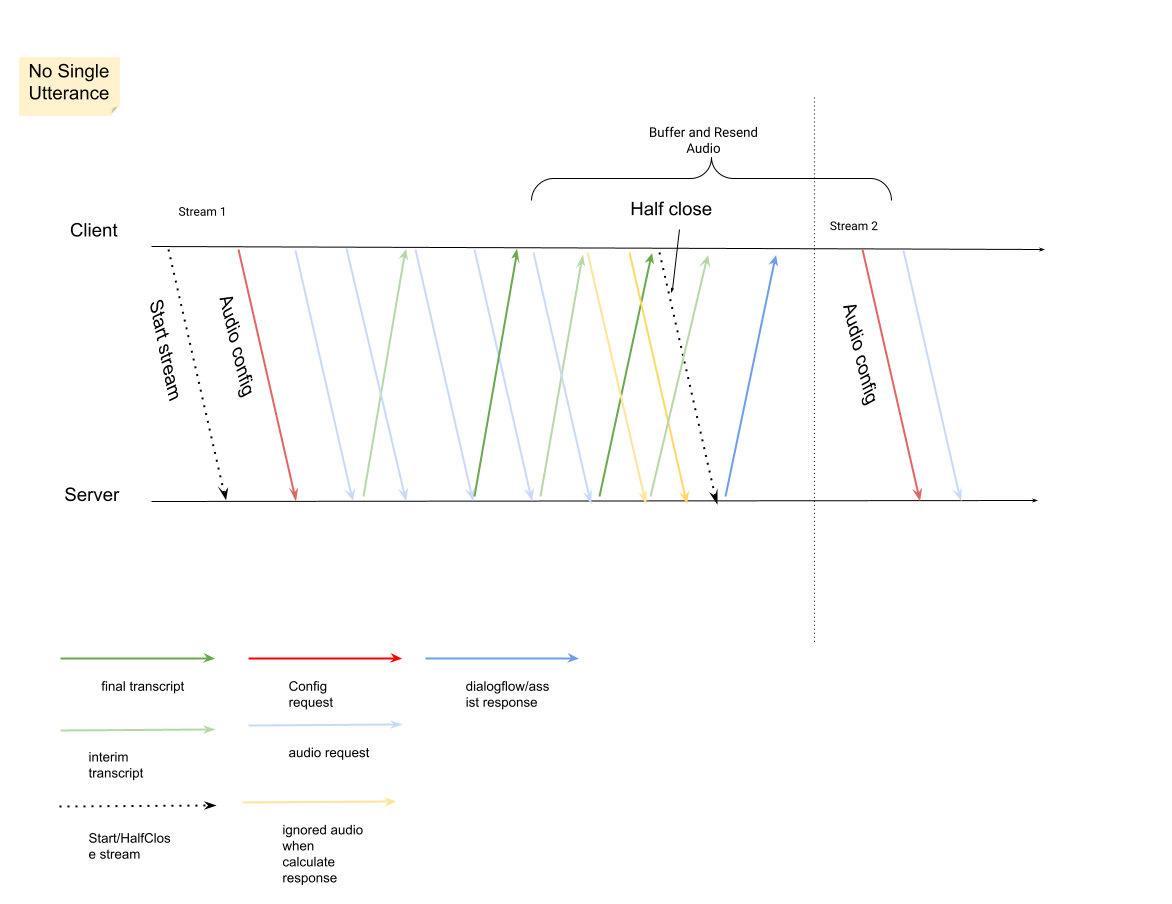
Streaming recognition request code sample
The following code sample illustrates how to send a streaming transcription request:
Python
To authenticate to Agent Assist, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.