Explore 쿼리 추적기와 Explore 성능 패널은 Explore 쿼리에 대한 단계별 성능 데이터를 제공합니다. 이 데이터는 쿼리의 성능 문제를 해결하기 위한 주요 진입점을 식별하고 개선을 위한 추천을 제공하는 데 도움이 됩니다.
Explore 쿼리 추적기
Explore 쿼리 추적기는 쿼리가 실행되는 동안 쿼리의 세 단계를 통해 Explore 쿼리의 진행 상황을 표시합니다.
![]()
쿼리를 실행하는 데 시간이 오래 걸리는 경우 쿼리 추적기를 통해 성능 문제를 일으키는 쿼리 단계를 파악할 수 있습니다. 이는 성능 문제가 발생할 수 있는 위치와 최적화 작업이 가장 효과적일 수 있는 위치를 파악하는 데 유용합니다.
Explore가 실행 중일 때 Explore 시각화 패널이나 Explore 데이터 패널이 열려 있는 동안에 쿼리 추적기가 표시됩니다.
실적 패널 살펴보기
Explore 성능 패널을 보려면 실행된 모든 Explore 쿼리에서 사용할 수 있는 성능 세부정보 보기 링크를 클릭합니다.

성능 패널에는 세 가지 쿼리 단계 각각에서 쿼리가 소비한 시간이 표시되며, 성능 문서와 쿼리 기록 시스템 활동 대시보드로 연결되는 링크가 포함되어 있습니다. 이 대시보드에는 쿼리 및 쿼리를 만드는 데 사용된 Explore의 현재 및 이전 성능 데이터가 표시됩니다.
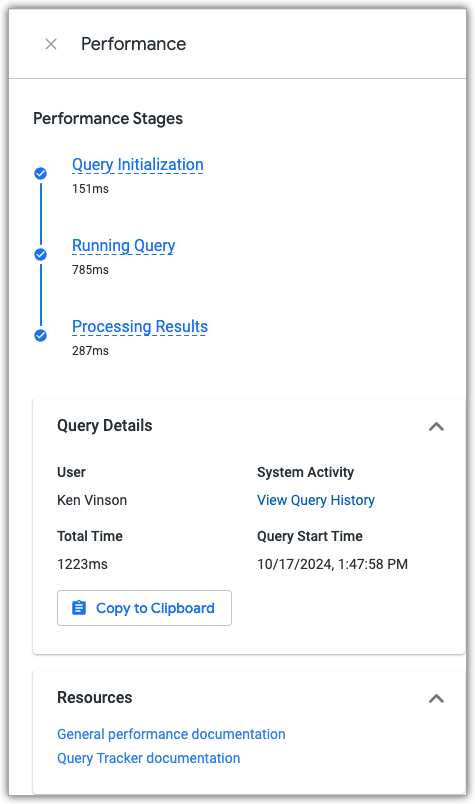
쿼리 단계
Looker Explore에서 데이터베이스 쿼리를 실행하면 쿼리는 다음과 같이 3단계로 실행됩니다.
쿼리 초기화 단계
쿼리 초기화 단계에서 Looker는 쿼리가 데이터베이스로 전송되기 전에 필요한 모든 태스크를 수행합니다. 쿼리 초기화 단계에는 다음 태스크가 포함됩니다.
- LookML 모델 컴파일
- 영구 파생 테이블(PDT)을 빌드해야 하는지 확인
- 쿼리 SQL 생성
- 데이터베이스 연결 획득
쿼리 성능 측정항목 이해 문서 페이지에서는 시스템 활동의 쿼리 성능 측정항목 Explore를 사용하여 쿼리의 세부 분석을 확인하는 방법을 설명합니다. 쿼리 추적기의 쿼리 초기화 단계에는 쿼리 성능 측정항목 Explore의 비동기 작업자 단계, 초기화 단계, 연결 처리 단계에 설명된 이벤트가 포함됩니다.
쿼리 실행 단계
쿼리 실행 단계는 Looker가 데이터베이스에 접속 및 쿼리하고 쿼리 결과를 반환하는 단계입니다. 이 단계에서 발생하는 성능 문제는 재빌드하는 데 시간이 오래 걸리고 최적화가 필요할 수 있는 PDT 또는 최적화가 필요할 수 있는 외부 데이터베이스 테이블과 같은 외부 데이터베이스 관련 문제일 수 있습니다. 쿼리 실행 단계에는 다음 태스크가 포함됩니다.
- Explore 쿼리에 필요한 PDT를 데이터베이스에 빌드
- 데이터베이스에서 요청된 쿼리 실행
쿼리 성능 측정항목 이해 문서 페이지에서는 시스템 활동의 쿼리 성능 측정항목 Explore를 사용하여 쿼리의 세부 분석을 확인하는 방법을 설명합니다. 쿼리 추적기의 쿼리 실행 단계에는 쿼리 성능 측정항목 Explore의 기본 쿼리 단계에 설명된 이벤트가 포함됩니다.
이 단계에서 성능 문제가 발생하는 경우 취할 수 있는 단계는 다음과 같습니다.
- 가능하면
many_to_one조인을 사용하여 Explore를 빌드하세요. 가장 세분화된 수준에서 가장 높은 수준의 세부정보(many_to_one)까지 뷰를 조인하면 일반적으로 쿼리 성능이 가장 뛰어납니다. - 가능한 경우 ETL 정책과 동기화하도록 캐싱을 극대화하여 데이터베이스 쿼리 트래픽을 줄입니다. 기본적으로 Looker는 1시간 동안 쿼리를 캐시합니다.
persist_with매개변수를 사용하여 Explore 내에서 데이터 그룹을 적용하여 캐싱 정책을 제어하고 Looker 데이터 새로고침을 ETL 프로세스와 동기화할 수 있습니다. 캐싱을 최대화하면 Looker가 백엔드 데이터 파이프라인과 더 긴밀하게 통합되므로 오래된 데이터를 분석할 위험 없이 캐시 사용량을 최대화할 수 있습니다. 이름이 지정된 캐싱 정책은 전체 모델 또는 개별 Explore 및 영구 파생 테이블 (PDT)에 적용할 수 있습니다. - Looker의 집계 인식 기능을 사용하여 Looker가 가능한 경우 쿼리에 사용할 수 있는 롤업 또는 요약 테이블을 만듭니다. 특히 대규모 데이터베이스의 일반적인 쿼리에 유용합니다. 집계 인식을 사용하여 전체 대시보드의 성능을 대폭 개선할 수도 있습니다. 자세한 내용은 집계 인식 튜토리얼을 참조하세요.
- PDT를 사용하여 쿼리 속도를 높입니다. 뷰가 미리 조인되어 런타임 전에 준비되도록 하려면 Explore를 여러 복잡한 조인 또는 성능이 떨어지는 조인으로, 또는 하위 쿼리나 하위 선택이 있는 측정기준을 PDT로 변환합니다.
- 데이터베이스 언어에서 증분 PDT를 지원하는 경우 Looker가 PDT 테이블을 다시 빌드하는 시간을 줄이도록 증분 PDT를 구성하세요.
- Looker에 정의된 연결된 기본 키에서 Explore에 뷰를 조인하지 마세요. 대신 뷰에서 연결된 기본 키를 구성하는 기본 필드를 조인합니다. 또는 뷰의 LookML이 아닌 테이블의 SQL 정의에 연결된 기본 키가 사전 정의된 PDT로 뷰를 다시 만듭니다.
- 벤치마킹에 SQL Runner의 Explain을 사용하세요.
EXPLAIN은 지정된 SQL 쿼리에 대한 데이터베이스의 쿼리 실행 계획에 대한 개요를 생성하므로 최적화할 수 있는 쿼리 구성요소를 감지할 수 있습니다.EXPLAIN으로 SQL을 최적화하는 방법 커뮤니티 게시물에서 자세히 알아보세요. - 색인을 선언합니다. 테이블의 톱니바퀴 아이콘을 클릭하고 색인 표시를 선택하면 SQL Runner에서 바로 Looker에서 각 테이블의 색인을 볼 수 있습니다.
색인의 혜택을 받을 수 있는 가장 일반적인 열은 중요한 날짜와 외래 키입니다. 이러한 열에 색인을 추가하면 거의 모든 쿼리의 성능이 향상됩니다. 이는 PDT에도 적용됩니다.
indexes,sort keys,distribution과 같은 LookML 매개변수를 적절하게 적용할 수 있습니다.
결과 처리 단계
결과 처리 단계에서 Looker는 쿼리 결과를 처리하고 렌더링합니다. 결과 처리 단계에는 다음 태스크가 포함됩니다.
- 쿼리 결과를 캐시로 스트리밍
- 테이블 계산 해결
- Liquid 템플릿 언어의 결과 형식 지정
- 쿼리 병합
- 합계 및 소계 계산
쿼리 성능 측정항목 이해 문서 페이지에서는 시스템 활동의 쿼리 성능 측정항목 Explore를 사용하여 쿼리의 세부 분석을 확인하는 방법을 설명합니다. 쿼리 추적기의 결과 처리 단계에는 쿼리 성능 측정항목 Explore의 쿼리 후 단계에 설명된 이벤트가 포함됩니다.
이 단계에서 성능 문제가 발생하는 경우 취할 수 있는 단계는 다음과 같습니다.
- 병합 결과, 커스텀 필드, 테이블 계산과 같은 기능은 가급적 사용하지 마세요. 이 기능은 모델을 설계하는 데 도움이 되는 개념 증명으로 사용됩니다. 데이터베이스에서 처리할 SQL을 생성하는 LookML에서 자주 사용되는 계산과 함수를 하드코딩하는 것이 좋습니다. 과도한 계산은 Looker 인스턴스에서 Java 메모리를 놓고 경쟁할 수 있으므로 Looker 인스턴스가 더 느리게 응답하게 됩니다.
- 뷰 파일이 많은 경우 모델에 포함하는 뷰의 수를 제한합니다. 단일 모델에 모든 뷰를 포함하면 성능이 저하될 수 있습니다. 프로젝트에 많은 수의 뷰가 있는 경우 각 모델에 필요한 뷰 파일만 포함하는 것이 좋습니다. 모델 내에 뷰 그룹을 포함할 수 있도록 뷰 파일 이름에 전략적 이름 지정 규칙을 사용하는 것이 좋습니다. 예시는
includes매개변수 문서에 설명되어 있습니다. - 대시보드 타일과 Look 내에서 기본적으로 많은 수의 데이터 포인트를 반환하지 마세요. 수천 개의 데이터 포인트를 반환하는 쿼리는 더 많은 메모리를 사용합니다. 프런트엔드
필터를 대시보드, Look, Explore, 그리고
required filters,conditionally_filter및sql_always_where매개변수가 있는 LookML 수준에 적용하여 최대한 데이터를 제한합니다. - 모든 결과 옵션을 꼭 필요한 경우에만 사용하여 쿼리를 다운로드하거나 전송하세요. 일부 쿼리는 매우 크며 처리 시 Looker 서버에 부담을 줄 수 있습니다.