Looker では、派生テーブルは、クエリ結果をデータベース内の実際のテーブルのように使用できるクエリのことです。
たとえば、多数の列を含む orders という名前のデータベース テーブルがあるとします。それぞれのお客様が行った注文の数や、それぞれのお客様が最初の注文を行った時刻など、お客様レベルの集計メトリクスを計算する必要があります。ネイティブ派生テーブルまたは SQL ベースの派生テーブルのいずれかを使用して、これらの指標を含む customer_order_summary という名前の新しいデータベース テーブルを作成できます。
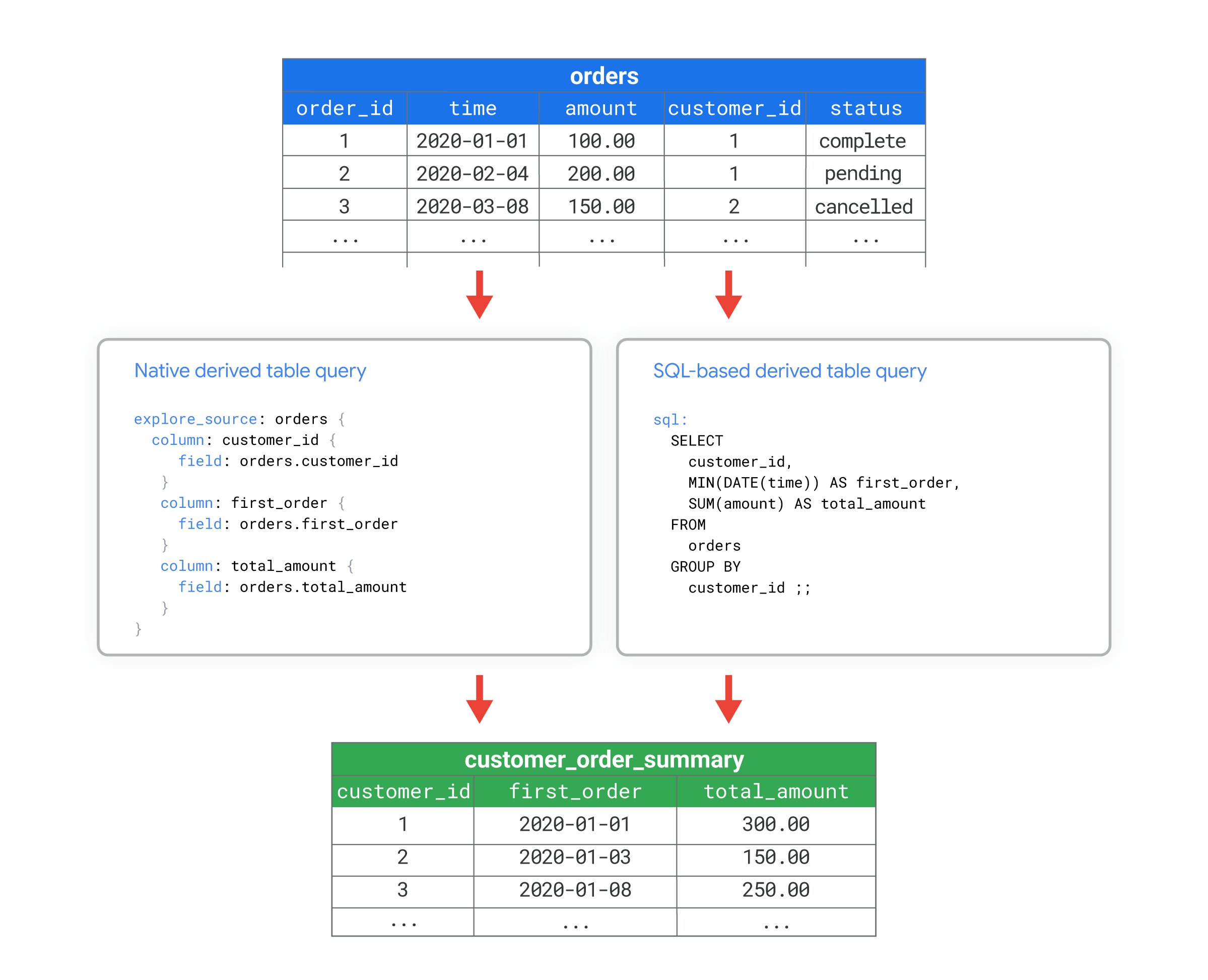
これにより、customer_order_summary 派生テーブルを、データベース内の他のテーブルと同様に扱えるようになります。
派生テーブルの一般的なユースケースについては、Looker クックブック: Looker の派生テーブルを最大限に活用するをご覧ください。
ネイティブ派生テーブルとSQLベースの派生テーブル
Looker プロジェクトで派生テーブルを作成するには、view パラメータの下にある derived_table パラメータを使用します。derived_table パラメータ内には、派生テーブルのクエリを次の 2 つの方法のいずれかで定義できます。
- ネイティブ派生テーブルに対する、LookML ベースのクエリを使用した派生テーブルの定義
- SQL ベースの派生テーブルに対する、SQL クエリを使用した派生テーブルの定義
たとえば、次のビューファイルは、LookML を使用して customer_order_summary 派生テーブルからビューを作成する方法を示しています。2つのバージョンのLookMLは、LookMLとSQLのどちらを使用して派生テーブルのクエリを定義しても、同等の派生テーブルを作成できることを示しています。
- ネイティブ派生テーブルは、
explore_sourceパラメータで LookML を使用してクエリを定義します。この例では、クエリは既存のordersビューに基づいており、このビューは、この例では示されていない別のファイルで定義されています。ネイティブ派生テーブルのexplore_sourceクエリは、ordersビューファイルからcustomer_id、first_order、total_amountの各フィールドを取得します。 - SQL ベースの派生テーブルは、
sqlパラメータで SQL を使用してクエリを定義します。この例では、SQL クエリはデータベース内のordersテーブルへの直接クエリです。
view: customer_order_summary {
derived_table: {
explore_source: orders {
column: customer_id {
field: orders.customer_id
}
column: first_order {
field: orders.first_order
}
column: total_amount {
field: orders.total_amount
}
}
}
dimension: customer_id {
type: number
primary_key: yes
sql: ${TABLE}.customer_id ;;
}
dimension_group: first_order {
type: time
timeframes: [date, week, month]
sql: ${TABLE}.first_order ;;
}
dimension: total_amount {
type: number
value_format: "0.00"
sql: ${TABLE}.total_amount ;;
}
}
view: customer_order_summary {
derived_table: {
sql:
SELECT
customer_id,
MIN(DATE(time)) AS first_order,
SUM(amount) AS total_amount
FROM
orders
GROUP BY
customer_id ;;
}
dimension: customer_id {
type: number
primary_key: yes
sql: ${TABLE}.customer_id ;;
}
dimension_group: first_order {
type: time
timeframes: [date, week, month]
sql: ${TABLE}.first_order ;;
}
dimension: total_amount {
type: number
value_format: "0.00"
sql: ${TABLE}.total_amount ;;
}
}
どちらのバージョンも、customer_id、first_order,、total_amount の各列を含む orders テーブルをベースとする customer_order_summary というビューを作成します。
derived_table パラメータとそのサブパラメータを除き、この customer_order_summary ビューは他のビューファイルと同じように機能します。派生テーブルのクエリを LookML または SQL のどちらで定義しても、派生テーブルの列に基づく LookML の measure やディメンションを作成できます。
派生テーブルの定義が完了したら、データベース内の他のテーブルと同様に使用することができます。
ネイティブ派生テーブル
ネイティブ派生テーブルは、LookMLの用語を使用して定義するクエリに基づいています。ネイティブ派生テーブルを作成するには、view パラメータの derived_table パラメータ内で explore_source パラメータを使用します。ネイティブ派生テーブルの列は、モデル内のLookML DimensionまたはMeasureを参照して作成します。前の例のネイティブ派生テーブルのビュー ファイルをご覧ください。
SQLベースの派生テーブルと比較すると、ネイティブ派生テーブルでは、データをモデル化するときの読みやすさと理解しやすさが向上します。
ネイティブ派生テーブルの作成について詳しくは、ネイティブ派生テーブルの作成のドキュメント ページをご覧ください。
SQLベースの派生テーブル
SQLベースの派生テーブルを作成するには、SQL用語でクエリを定義し、SQLクエリを使用してテーブルに列を作成します。SQLベースの派生テーブルでLookMLのDimensionとMeasureを参照先とすることはできません。前の例の SQL ベースの派生テーブルのビューファイルをご覧ください。
通常、SQL クエリの定義は、ビュー パラメータの derived_table パラメータ内で sql パラメータを使用します。
Looker で SQL ベースのクエリを作成する便利なショートカットは、SQL Runner を使用して SQL クエリを作成し、作成したクエリを派生テーブル定義に変換することです。
特定のエッジケースでは、sql パラメータの使用が許可されない場合があります。このような場合、Looker では永続的な派生テーブル(PDT)の SQL クエリを定義するために次のパラメータをサポートしています。
create_process: PDT にsqlパラメータを使用する場合は、バックグラウンドで Looker が言語のCREATE TABLEデータ定義言語(DDL)ステートメントをラップし、SQL クエリから PDT を作成します。一部の言語は、単独のステップでの SQLCREATE TABLEステートメントに対応していません。これらの言語については、sqlパラメータを指定して PDT を作成することはできません。代わりに、create_processパラメータを使用して、複数のステップで PDT を作成できます。情報と例については、create_processパラメータのドキュメント ページをご覧ください。sql_create: ユースケースでカスタムの DDL コマンドが必要であり、言語で DDL(Google の予測 BigQuery ML など)がサポートされている場合は、sqlパラメータを使用する代わりに、sql_createパラメータを使用して PDT を作成できます。情報と例については、sql_createのドキュメント ページをご覧ください。
sql、create_process、sql_create のどのパラメータを使用している場合であっても、派生テーブルの定義には SQL クエリが使用されるため、これらはすべて SQL ベースの派生テーブルとみなされます。
SQL ベースの派生テーブルを定義する場合は、AS を使用して、各列に明確なエイリアスを設定してください。これは、ディメンションで結果セットの列名(${TABLE}.first_order など)の参照が必要になるためです。これが前の例で、MIN(DATE(time)) をそのまま使用するのではなく MIN(DATE(time)) AS first_order を使用している理由です。
一時的な派生テーブルと永続的な派生テーブル
ネイティブ派生テーブルと SQL ベースの派生テーブルの対比だけではなく、一時的な派生テーブル(データベースに書き込まれない)と永続的な派生テーブル(PDT)(データベースのスキーマに書き込まれる)の違いもあります。
ネイティブ派生テーブルとSQLベースの派生テーブルは、一時的、または永続的のどちらにもできます。
一時的な派生テーブル
先ほど示した派生テーブルは、一時的な派生テーブルの例です。derived_table パラメータで永続性戦略が定義されていないため、これらは一時的なものです。
一時的な派生テーブルは、データベースに書き込まれません。ユーザーが 1 つ以上の派生テーブルを含む Explore クエリを実行すると、Looker では派生テーブルの SQL とリクエストされたフィールド、結合、フィルタ値の言語固有の組み合わせを使用して SQL クエリが構成されます。その組み合わせが以前に実行されたものであり、キャッシュ内の結果がまだ有効な場合には、Lookerはキャッシュされた結果を使用します。Looker でのクエリ キャッシュ保存の詳細については、クエリのキャッシングのドキュメント ページをご覧ください。
Looker がキャッシュに保存された結果を使用できない場合は、ユーザーが一時的な派生テーブルからデータをリクエストするたびに、Looker ではデータベースで新しいクエリを実行する必要があります。このため、一時的な派生テーブルが高パフォーマンスで、データベースに過度な負担をかけないことを確認する必要があります。クエリの実行に時間を要する多くの場合で、PDT を使用する方が適しています。
一時的な派生テーブルに対応するデータベースダイアレクト
Lookerプロジェクトで派生テーブルに対応するためには、データベースダイアレクトでも派生テーブルに対応している必要があります。次の表に、Looker の最新リリースで派生テーブルをサポートする言語を示します。
表を表示するには、ここをクリックします。
| 方言 | サポート対象 |
|---|---|
| Actian Avalanche | ○ |
| Amazon Athena | はい |
| Amazon Aurora MySQL | はい |
| Amazon Redshift | はい |
| Amazon Redshift 2.1+ | はい |
| Amazon Redshift Serverless 2.1+ | はい |
| Apache Druid | はい |
| Apache Druid 0.13+ | はい |
| Apache Druid 0.18+ | はい |
| Apache Hive 2.3+ | はい |
| Apache Hive 3.1.2+ | はい |
| Apache Spark 3+ | はい |
| ClickHouse | はい |
| Cloudera Impala 3.1+ | はい |
| Cloudera Impala 3.1+ with Native Driver | はい |
| Cloudera Impala with Native Driver | はい |
| DataVirtuality | はい |
| Databricks | はい |
| Denodo 7 | はい |
| Denodo 8 & 9 | はい |
| Dremio | はい |
| Dremio 11+ | はい |
| Exasol | はい |
| Google BigQuery Legacy SQL | はい |
| Google BigQuery Standard SQL | はい |
| Google Cloud PostgreSQL | はい |
| Google Cloud SQL | はい |
| Google Spanner | はい |
| Greenplum | はい |
| HyperSQL | はい |
| IBM Netezza | はい |
| MariaDB | はい |
| Microsoft Azure PostgreSQL | はい |
| Microsoft Azure SQL Database | はい |
| Microsoft Azure Synapse Analytics | はい |
| Microsoft SQL Server 2008+ | はい |
| Microsoft SQL Server 2012+ | はい |
| Microsoft SQL Server 2016 | はい |
| Microsoft SQL Server 2017+ | はい |
| MongoBI | はい |
| MySQL | はい |
| MySQL 8.0.12+ | はい |
| Oracle | はい |
| Oracle ADWC | はい |
| PostgreSQL 9.5+ | はい |
| PostgreSQL pre-9.5 | はい |
| PrestoDB | はい |
| PrestoSQL | はい |
| SAP HANA | はい |
| SAP HANA 2+ | はい |
| SingleStore | はい |
| SingleStore 7+ | はい |
| Snowflake | はい |
| Teradata | はい |
| Trino | はい |
| Vector | はい |
| Vertica | ○ |
永続的な派生テーブル
永続的な派生テーブル(PDT)とは、データベースのスクラッチ スキーマに書き込まれ、永続性戦略で指定したスケジュールで再生成される派生テーブルのことです。
PDT はネイティブの派生テーブルまたは SQL ベースの派生テーブルのいずれかです。
PDT の要件
Looker プロジェクトで永続的な派生テーブル(PDT)を使用するには、次のものが必要です。
- PDTに対応するデータベースダイアレクト。永続的な SQL ベースの派生テーブルと永続的なネイティブ派生テーブルをサポートする言語のリストについては、このページで後述する PDT でサポートされているデータベース言語セクションをご覧ください。
データベースのスクラッチスキーマ。これは、データベース上のどのスキーマでもかまいませんが、この目的専用の新しいスキーマを作成することをお勧めします。データベース管理者は、Lookerデータベースユーザーの書き込みを許可するスキーマを構成する必要があります。
[PDT を有効にする] 切り替えボタンをオンにして構成された Looker 接続。通常、この [PDT を有効にする] 設定は、Looker の初回構成の際に行いますが(データベース言語に関する手順については Looker 言語のドキュメント ページを参照)、初回構成後に接続に対して PDT を有効にすることもできます。
PDTに対応するデータベースダイアレクト
LookerプロジェクトでPDTに対応するためには、データベースダイアレクトでもPDTに対応している必要があります。
任意の種類の PDT(LookML ベースまたは SQL ベース)をサポートするには、言語がその他の要件に沿って、データベースへの書き込みに対応している必要があります。読み取り専用データベース構成の中には、永続性の動作を許可しないものもあります(Postgres ホットスワップ レプリカ データベースに頻繁に見られます)。こうした場合には、代わりに一時派生テーブルを使用できます。
次の表に、Looker の最新リリースで永続的な SQL ベースの派生テーブルに対応する言語を示します。
表を表示するには、ここをクリックします。
| 方言 | サポート対象 |
|---|---|
| Actian Avalanche | ○ |
| Amazon Athena | はい |
| Amazon Aurora MySQL | はい |
| Amazon Redshift | はい |
| Amazon Redshift 2.1+ | はい |
| Amazon Redshift Serverless 2.1+ | はい |
| Apache Druid | いいえ |
| Apache Druid 0.13+ | いいえ |
| Apache Druid 0.18+ | いいえ |
| Apache Hive 2.3+ | ○ |
| Apache Hive 3.1.2+ | はい |
| Apache Spark 3+ | はい |
| ClickHouse | いいえ |
| Cloudera Impala 3.1+ | ○ |
| Cloudera Impala 3.1+ with Native Driver | はい |
| Cloudera Impala with Native Driver | はい |
| DataVirtuality | いいえ |
| Databricks | ○ |
| Denodo 7 | いいえ |
| Denodo 8 & 9 | いいえ |
| Dremio | いいえ |
| Dremio 11+ | いいえ |
| Exasol | ○ |
| Google BigQuery Legacy SQL | はい |
| Google BigQuery Standard SQL | はい |
| Google Cloud PostgreSQL | はい |
| Google Cloud SQL | はい |
| Google Spanner | いいえ |
| Greenplum | ○ |
| HyperSQL | いいえ |
| IBM Netezza | ○ |
| MariaDB | はい |
| Microsoft Azure PostgreSQL | はい |
| Microsoft Azure SQL Database | はい |
| Microsoft Azure Synapse Analytics | はい |
| Microsoft SQL Server 2008+ | はい |
| Microsoft SQL Server 2012+ | はい |
| Microsoft SQL Server 2016 | はい |
| Microsoft SQL Server 2017+ | はい |
| MongoBI | いいえ |
| MySQL | ○ |
| MySQL 8.0.12+ | はい |
| Oracle | はい |
| Oracle ADWC | はい |
| PostgreSQL 9.5+ | はい |
| PostgreSQL pre-9.5 | はい |
| PrestoDB | はい |
| PrestoSQL | はい |
| SAP HANA | はい |
| SAP HANA 2+ | はい |
| SingleStore | はい |
| SingleStore 7+ | はい |
| Snowflake | はい |
| Teradata | はい |
| Trino | はい |
| Vector | はい |
| Vertica | ○ |
永続的なネイティブ派生テーブル(LookML ベースのクエリを含む)をサポートするには、言語が CREATE TABLE DDL 関数にも対応している必要があります。Looker の最新リリースで永続的なネイティブ(LookML ベース)派生テーブルに対応する言語のリストを以下に示します。
表を表示するには、ここをクリックします。
| 方言 | サポート対象 |
|---|---|
| Actian Avalanche | ○ |
| Amazon Athena | はい |
| Amazon Aurora MySQL | はい |
| Amazon Redshift | はい |
| Amazon Redshift 2.1+ | はい |
| Amazon Redshift Serverless 2.1+ | はい |
| Apache Druid | いいえ |
| Apache Druid 0.13+ | いいえ |
| Apache Druid 0.18+ | いいえ |
| Apache Hive 2.3+ | ○ |
| Apache Hive 3.1.2+ | はい |
| Apache Spark 3+ | はい |
| ClickHouse | いいえ |
| Cloudera Impala 3.1+ | ○ |
| Cloudera Impala 3.1+ with Native Driver | はい |
| Cloudera Impala with Native Driver | はい |
| DataVirtuality | いいえ |
| Databricks | ○ |
| Denodo 7 | いいえ |
| Denodo 8 & 9 | いいえ |
| Dremio | いいえ |
| Dremio 11+ | いいえ |
| Exasol | ○ |
| Google BigQuery Legacy SQL | はい |
| Google BigQuery Standard SQL | はい |
| Google Cloud PostgreSQL | はい |
| Google Cloud SQL | いいえ |
| Google Spanner | いいえ |
| Greenplum | ○ |
| HyperSQL | いいえ |
| IBM Netezza | ○ |
| MariaDB | はい |
| Microsoft Azure PostgreSQL | はい |
| Microsoft Azure SQL Database | はい |
| Microsoft Azure Synapse Analytics | はい |
| Microsoft SQL Server 2008+ | はい |
| Microsoft SQL Server 2012+ | はい |
| Microsoft SQL Server 2016 | はい |
| Microsoft SQL Server 2017+ | はい |
| MongoBI | いいえ |
| MySQL | ○ |
| MySQL 8.0.12+ | はい |
| Oracle | はい |
| Oracle ADWC | はい |
| PostgreSQL 9.5+ | はい |
| PostgreSQL pre-9.5 | はい |
| PrestoDB | はい |
| PrestoSQL | はい |
| SAP HANA | はい |
| SAP HANA 2+ | はい |
| SingleStore | はい |
| SingleStore 7+ | はい |
| Snowflake | はい |
| Teradata | はい |
| Trino | はい |
| Vector | はい |
| Vertica | ○ |
PDTの増分構築
増分 PDT は、Looker がテーブル全体を再構築するのではなく、テーブルに新しいデータを追加して構築する永続的な派生テーブルです。
言語が増分 PDT をサポートしており、PDT でトリガーベースの永続性戦略(datagroup_trigger、sql_trigger_value、または interval_trigger)を使用すると、PDT を増分 PDT として定義できます。
詳しくは、増分 PDT のドキュメント ページをご覧ください。
増分PDT対応のデータベースダイアレクト
Lookerプロジェクトで増分PDTに対応するためには、データベースダイアレクトでも増分PDTに対応している必要があります。Looker の最新リリースで増分 PDT に対応する言語を次の表に示します。
表を表示するには、ここをクリックします。
| 方言 | サポート対象 |
|---|---|
| Actian Avalanche | いいえ |
| Amazon Athena | いいえ |
| Amazon Aurora MySQL | いいえ |
| Amazon Redshift | ○ |
| Amazon Redshift 2.1+ | はい |
| Amazon Redshift Serverless 2.1+ | はい |
| Apache Druid | いいえ |
| Apache Druid 0.13+ | いいえ |
| Apache Druid 0.18+ | いいえ |
| Apache Hive 2.3+ | いいえ |
| Apache Hive 3.1.2+ | いいえ |
| Apache Spark 3+ | いいえ |
| ClickHouse | いいえ |
| Cloudera Impala 3.1+ | いいえ |
| Cloudera Impala 3.1+ with Native Driver | いいえ |
| Cloudera Impala with Native Driver | いいえ |
| DataVirtuality | いいえ |
| Databricks | ○ |
| Denodo 7 | いいえ |
| Denodo 8 & 9 | いいえ |
| Dremio | いいえ |
| Dremio 11+ | いいえ |
| Exasol | いいえ |
| Google BigQuery Legacy SQL | いいえ |
| Google BigQuery Standard SQL | ○ |
| Google Cloud PostgreSQL | はい |
| Google Cloud SQL | いいえ |
| Google Spanner | いいえ |
| Greenplum | ○ |
| HyperSQL | いいえ |
| IBM Netezza | いいえ |
| MariaDB | いいえ |
| Microsoft Azure PostgreSQL | ○ |
| Microsoft Azure SQL Database | いいえ |
| Microsoft Azure Synapse Analytics | ○ |
| Microsoft SQL Server 2008+ | いいえ |
| Microsoft SQL Server 2012+ | いいえ |
| Microsoft SQL Server 2016 | いいえ |
| Microsoft SQL Server 2017+ | いいえ |
| MongoBI | いいえ |
| MySQL | ○ |
| MySQL 8.0.12+ | はい |
| Oracle | いいえ |
| Oracle ADWC | いいえ |
| PostgreSQL 9.5+ | ○ |
| PostgreSQL pre-9.5 | はい |
| PrestoDB | いいえ |
| PrestoSQL | いいえ |
| SAP HANA | いいえ |
| SAP HANA 2+ | いいえ |
| SingleStore | いいえ |
| SingleStore 7+ | いいえ |
| Snowflake | ○ |
| Teradata | いいえ |
| Trino | いいえ |
| Vector | いいえ |
| Vertica | ○ |
PDT の作成
派生テーブルを永続的な派生テーブル(PDT)にするには、テーブルの永続性戦略を定義します。パフォーマンスを最適化するには、最適化戦略も追加する必要があります。
永続性戦略
派生テーブルの永続性は、Looker で管理できるほか、マテリアライズド ビューに対応する言語については、マテリアライズド ビューを使用してデータベースで管理できます。
派生テーブルを永続的なものにするには、次のいずれかのパラメータを derived_table 定義に追加します。
- Looker 管理の永続性パラメータ:
- データベース管理の永続性パラメータ:
トリガーベースの永続性戦略(datagroup_trigger、sql_trigger_value、interval_trigger)では、Looker は PDT が再構築のためにトリガーされるまで PDT をデータベースに保持します。PDTがトリガーされると、LookerはPDTを再構築し、前のバージョンと置き換えます。つまり、トリガーベースの PDT では、ユーザーが PDT からの Explore クエリの回答を得るために、PDT の構築を待つ必要はありません。
datagroup_trigger
データグループは、最も柔軟性の高い永続性作成メソッドです。データグループを sql_trigger または interval_trigger を使用して定義した場合、datagroup_triggerパラメータを使用して永続的な派生テーブル(PDT)の再構築を開始できます。
Lookerでは、PDTのデータグループがトリガーされるまで、そのPDTをデータベースに保持します。データグループがトリガーされると、LookerはPDTを再構築し、前のバージョンと置き換えます。ほとんどの場合、これにより、ユーザーが PDT の構築を待つ必要がなくなります。PDT が構築中であり、クエリ結果がキャッシュに格納されていない場合にユーザーが PDT からデータをリクエストすると、Looker は新しい PDT が構築されるまで、既存の PDT からデータを返します。データグループの概要については、クエリのキャッシングをご覧ください。
このリジェネレータで PDT を構築する方法について詳しくは、Looker のリジェネレータ セクションをご覧ください。
sql_trigger_value
sql_trigger_value パラメータは、指定した SQL ステートメントに基づいて永続的な派生テーブル(PDT)の再生成をトリガーします。SQL文の結果が前の値と異なる場合、PDTが再生成されます。それ以外の場合は、既存のPDTがデータベースに保持されます。ほとんどの場合、これにより、ユーザーが PDT の構築を待つ必要がなくなります。PDT が構築中であり、クエリ結果がキャッシュに格納されていない場合にユーザーが PDT からデータをリクエストすると、Looker は新しい PDT が構築されるまで、既存の PDT からデータを返します。
このリジェネレータで PDT を構築する方法について詳しくは、Looker のリジェネレータ セクションをご覧ください。
interval_trigger
interval_trigger パラメータは、"24 hours" や "60 minutes" など、指定した時間間隔に基づいて、永続的な派生テーブル(PDT)の再生成をトリガーします。sql_trigger パラメータと同様に、これは通常、ユーザーがクエリすると PDT が事前に構築されることを意味します。PDT が構築中であり、クエリ結果がキャッシュに格納されていない場合にユーザーが PDT からデータをリクエストすると、Looker は新しい PDT が構築されるまで、既存の PDT からデータを返します。
persist_for
もう 1 つのオプションは、persist_for パラメータを使用して、派生テーブルが期限切れとマークされ、クエリに使用されなくなりデータベースから削除されるまでの保存期間を設定するというものです。
persist_for 永続的な派生テーブル(PDT)は、ユーザーが PDT のクエリを最初に実行したときに構築されます。Looker では、PDT の persist_for パラメータで指定された期間は PDT をデータベースに保持します。ユーザーが persist_for 期間中にPDTのクエリを実行すると、Lookerは可能であればキャッシュされている結果を使用し、それ以外の場合はそのPDTでクエリを実行します。
persist_for 期間を超過すると、Looker はデータベースから PDT を消去し、その PDT は次回、ユーザーがクエリしたときに再構築されます。したがって、そのクエリでは再構築を待つ必要があります。
persist_for を使用する PDT は、PDT の依存カスケードの場合を除いて、Looker のリジェネレータによって自動的に再構築されません。persist_for テーブルが、トリガーベースの PDT(datagroup_trigger、interval_trigger、または sql_trigger_value の永続性戦略を使用する PDT)の依存関係カスケードの一部である場合、リジェネレーターは、persist_for テーブルをモニタリングして再構築し、カスケード内の他のテーブルを再構築します。このページの Looker によるカスケード派生テーブルのビルド方法セクションをご覧ください。
materialized_view: yes
マテリアル化ビューでは、データベースの機能を利用して、Looker プロジェクトで派生テーブルを永続化させることができます。データベース言語がマテリアライズド ビューをサポートしており、Looker の接続が [PDT を有効にする] 切り替えボタンをオンにして構成されている場合は、派生テーブルの materialized_view: yes を指定してマテリアライズド ビューを作成できます。マテリアライズド ビューは、ネイティブ派生テーブルと SQL ベースの派生テーブルの両方でサポートされています。
マテリアライズド ビューは永続的な派生テーブル(PDT)と同様に、データベースのスクラッチ スキーマにテーブルとして保存されるクエリ結果です。PDTとマテリアライズド ビューの主な違いは、テーブルの更新方法です。
- PDTでは、永続性戦略はLookerで定義され、その永続性はLookerで管理されます。
- マテリアライズド ビューでは、データベースがテーブル内のデータの管理と更新を担当します。
このため、マテリアル化ビューの機能を使用するには、ダイアレクトとその機能に関する高度な知識が必要になります。ほとんどの場合、データベースでは、マテリアル化ビューでクエリされるテーブル内に新規データが検出されるたびに、マテリアル化ビューが更新されます。マテリアライズド ビューは、リアルタイムデータが必要なシナリオに最適です。
言語のサポート、要件、重要な考慮事項については、materialized_view パラメータのドキュメント ページをご覧ください。
最適化戦略
永続的な派生テーブル(PDT)はデータベースに保存されるため、言語でサポートされているとおり、以下の戦略を使用して PDT を最適化する必要があります。
たとえば、派生テーブルの例に永続性を追加するには、データグループ orders_datagroup がトリガーされたときに再構築するように設定し、customer_id と first_order の両方に次のようにインデックスを追加します。
view: customer_order_summary {
derived_table: {
explore_source: orders {
...
}
datagroup_trigger: orders_datagroup
indexes: ["customer_id", "first_order"]
}
}
インデックス(またはご使用のダイアレクトでそれに相当するもの)を追加しない場合、クエリのパフォーマンス改善のため追加するよう Looker から警告が表示されます。
PDT のユースケース
永続的な派生テーブル(PDT)は、クエリの結果をテーブル内に保持することでクエリのパフォーマンスを向上させることができるため有用です。
一般的なベスト プラクティスとして、デベロッパーは、絶対的に不可欠になるまで PDT を使用せずにデータをモデル化する必要があります。
場合によっては、他の方法でデータを最適化できます。たとえば、インデックスを追加したり、列のデータ型を変更したりすることで、PDT を作成しなくても問題を解決できる場合があります。SQL Runner ツールの Explain を使用して、実行速度が遅いクエリの実行プランを分析します。
頻繁に実行されるクエリのクエリ時間とデータベース負荷の削減だけでなく、PDT には他にも次のようなユースケースがあります。
テーブル内の行を一意の主キーとして識別する適切な方法がない場合は、PDT を使用して主キーを定義することもできます。
PDT を使用して最適化をテストする
PDT を使用すると、DBA や ETL デベロッパーから多くのサポートがなくても、さまざまなインデックス、分散、その他の最適化オプションをテストできます。
テーブルが 1 つあり、さまざまなインデックスをテストする必要があるとします。ビューの最初の LookML は、次のようになります。
view: customer {
sql_table_name: warehouse.customer ;;
}
最適化戦略をテストするには、indexes パラメータを使用して、次のように LookML にインデックスを追加します。
view: customer {
# sql_table_name: warehouse.customer
derived_table: {
sql: SELECT * FROM warehouse.customer ;;
persist_for: "8 hours"
indexes: [customer_id, customer_name, salesperson_id]
}
}
ビューを 1 回クエリして PDT を生成します。次に、テストクエリを実行して結果を比較します。結果に問題がなければ、DBA または ETL チームにインデックスを元のテーブルに追加するように依頼できます。
ビューコードを元に戻して PDT を削除してください。
PDT を使用してデータを事前結合または集計する
大量のデータや複数の種類のデータに対してクエリの最適化を調整するには、データを事前結合または集計すると便利です。
たとえば、初回注文日を基準に顧客をコホート別に分類するクエリを作成するとします。このクエリは、データがリアルタイムで必要となるたびに複数回実行すると費用がかさむ可能性があります。ただし、クエリを 1 回だけ計算し、PDT で結果を再利用できます。
view: customer_order_facts {
derived_table: {
sql: SELECT
c.customer_id,
MIN(o.order_date) OVER (PARTITION BY c.customer_id) AS first_order_date,
MAX(o.order_date) OVER (PARTITION BY c.customer_id) AS most_recent_order_date,
COUNT(o.order_id) OVER (PARTITION BY c.customer_id) AS lifetime_orders,
SUM(o.order_value) OVER (PARTITION BY c.customer_id) AS lifetime_value,
RANK() OVER (PARTITION BY c.customer_id ORDER BY o.order_date ASC) AS order_sequence,
o.order_id
FROM warehouse.customer c LEFT JOIN warehouse.order o ON c.customer_id = o.customer_id
;;
sql_trigger_value: SELECT CURRENT_DATE ;;
indexes: [customer_id, order_id, order_sequence, first_order_date]
}
}
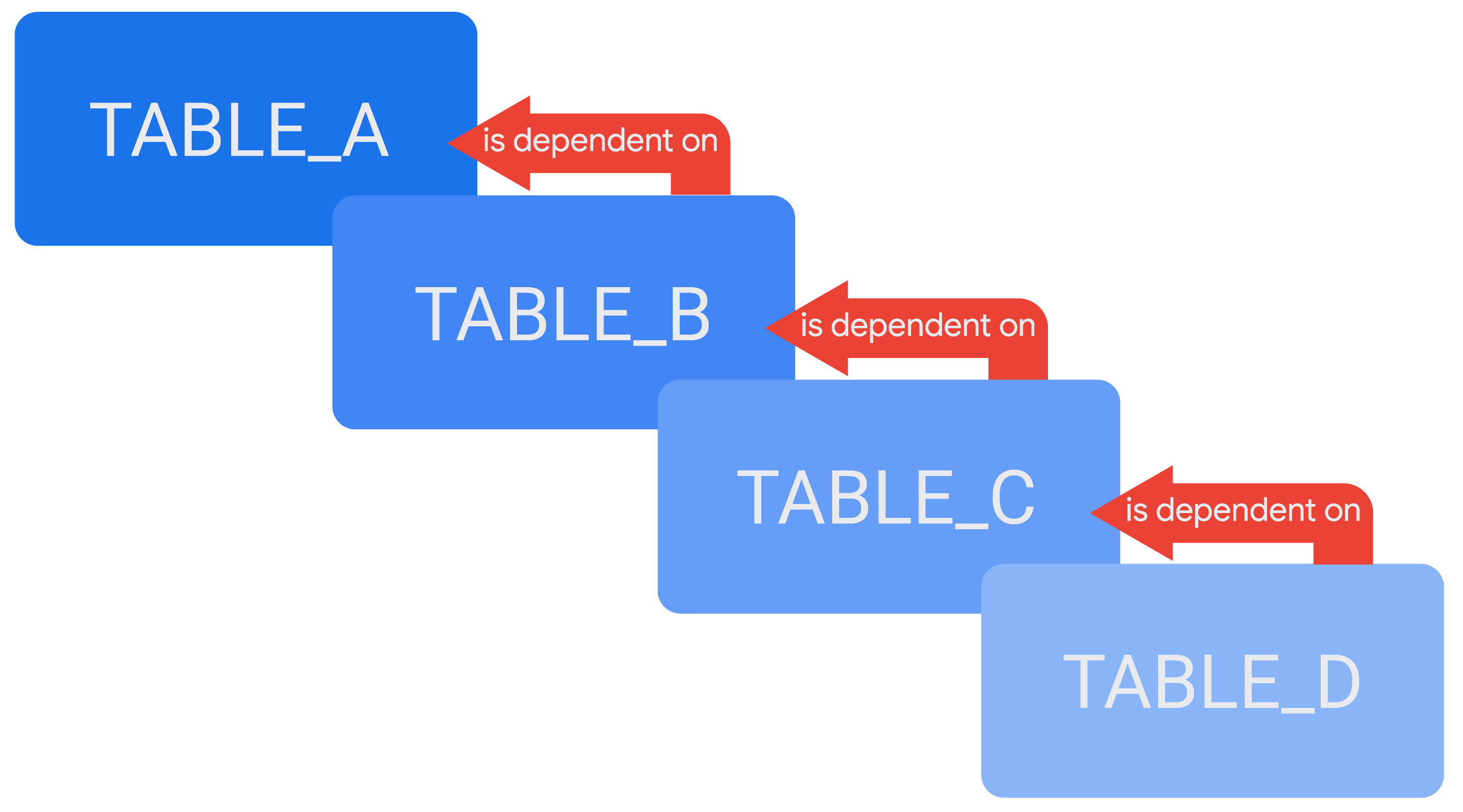
カスケード派生テーブル
場合によっては、カスケード派生テーブル、または永続的なカスケード派生テーブル(PDT)のチェーンを作成し、1 つの派生テーブルを別の定義で参照することが可能です。派生テーブルのカスケードの例は、TABLE_D です。このテーブルは別のテーブル TABLE_C に依存し、TABLE_C は TABLE_B に依存し、TABLE_B は TABLE_A に依存します。
派生テーブル参照の構文
他の派生テーブル内の派生テーブルを参照するには、次の構文を使用します。
`${derived_table_or_view_name.SQL_TABLE_NAME}`
この形式では、SQL_TABLE_NAME はリテラル文字列です。たとえば、次の構文で clean_events 派生テーブルを参照できます。
`${clean_events.SQL_TABLE_NAME}`
この同じ構文を使用してLookMLビューを参照することもできます。この場合も、SQL_TABLE_NAME はリテラル文字列です。
次の例では、データベースの events テーブルから clean_events PDT が作成されます。clean_events PDT は、events データベース テーブルから不要な行を除外します。2 つ目の PDT が表示されます。event_summary PDT は clean_events PDT の概要です。clean_events に新しい行が追加されるたびに、event_summary テーブルが再生成されます。
event_summary PDT と clean_events PDT はカスケード PDT であり、event_summary は clean_events に依存しています(event_summary は clean_events PDT を使用して定義されているため)。この特定の例は、1つのPDTでより効率的に行うことができますが、派生テーブルの参照を示すのに役立ちます。
view: clean_events {
derived_table: {
sql:
SELECT *
FROM events
WHERE type NOT IN ('test', 'staff') ;;
datagroup_trigger: events_datagroup
}
}
view: events_summary {
derived_table: {
sql:
SELECT
type,
date,
COUNT(*) AS num_events
FROM
${clean_events.SQL_TABLE_NAME} AS clean_events
GROUP BY
type,
date ;;
datagroup_trigger: events_datagroup
}
}
必ず必要なわけではありませんが、この方法で派生テーブルを参照する場合は、一般に次の形式でテーブルのエイリアスを作成すると有用です。
${derived_table_or_view_name.SQL_TABLE_NAME} AS derived_table_or_view_name
前の例では次のように行います:
${clean_events.SQL_TABLE_NAME} AS clean_events
ここでは、PDTにはデータベース内で長いコードの名前が付けられているため、エイリアスの使用が役立ちます。場合によっては(特に ON 句を使用する場合)、この長い名前を取得するために ${derived_table_or_view_name.SQL_TABLE_NAME} 構文を使用する必要があることを忘れがちになります。エイリアスを付与することで、こうした誤りを避けることができます。
Lookerによるカスケード派生テーブルのビルド方法
一時的なカスケード派生テーブルの場合、ユーザーのクエリ結果がキャッシュにない場合、Looker はクエリに必要なすべての派生テーブルを構築します。TABLE_C への参照が定義に含まれる TABLE_D がある場合、TABLE_D は TABLE_C に依存します。つまり、TABLE_D に対してクエリを実行し、そのクエリが Looker のキャッシュにない場合、Looker は TABLE_D を再構築します。ただし、まずは TABLE_C を再構築する必要があります。
TABLE_A に依存する TABLE_B に依存する TABLE_C に依存する TABLE_D の一時的なカスケード派生テーブルのシナリオについて考えてみましょう。Lookerのキャッシュに TABLE_C に対する有効なクエリ結果がない場合、Lookerはそのクエリに必要なすべてのテーブルをビルドします。そのため、Looker は、TABLE_A、TABLE_B、TABLE_C の順に構築します。
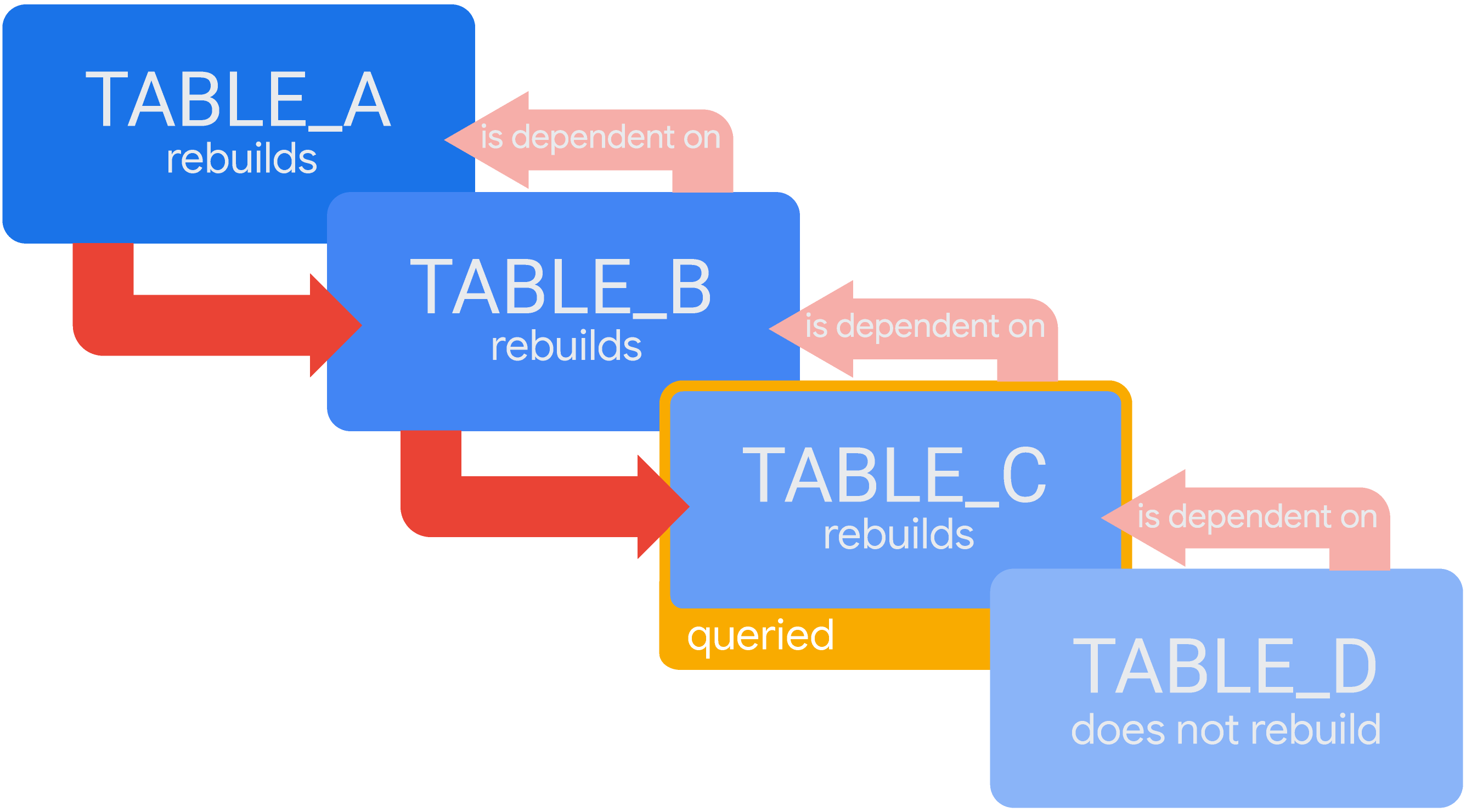
このシナリオでは、Looker が TABLE_B の生成を開始する前に TABLE_A の生成が完了している必要があり、Looker が TABLE_C の生成を開始する前に TABLE_B の生成が完了している必要があります。TABLE_C が完了すると、Looker はクエリ結果を提供します。(このクエリへの応答に TABLE_D は不要なため、現時点では Looker は TABLE_D を再構築しません。)
同じデータグループを使用するカスケード PDT のシナリオの例については、datagroup パラメータのドキュメント ページをご覧ください。
PDT にも同じ基本ロジックが適用されます。Looker は、依存関係のチェーン全体まで、クエリへの応答に必要なすべてのテーブルを構築します。ただし、PDT では、テーブルがすでに存在し、再構築する必要がない場合もあります。カスケード PDT に関する標準のユーザークエリでは、Looker はデータベース内にその PDT の有効なバージョンがない場合のみ、カスケード内の PDT を再構築します。カスケード内のすべての PDT の再構築を強制する場合は、Explore を使用してクエリのテーブルを手動で再構築できます。
重要な論理ポイントは、PDT カスケードの場合、基本的に依存 PDT がその依存先である PDT をクエリしていることです。これは特に、persist_for 戦略を使用している PDT にとって重要です。通常、persist_for PDT は、ユーザーが PDT をクエリしたときに構築され、persist_for 間隔が経過するまでデータベースに残り、次にユーザーによってクエリが実行されるまで再構築されません。ただし、persist_for PDT がトリガーベースの PDT(datagroup_trigger、interval_trigger、または sql_trigger_value の永続性戦略を使用する PDT)である場合は、基本的に依存する PDT が再構築されるたびに persist_for PDT がクエリされます。そのため、この場合、persist_for PDT は依存 PDT のスケジュールに基づいて再構築されます。つまり、persist_for PDT は、それに依存する永続性戦略の影響を受けるということです。
手動によるクエリ用の永続的なテーブルの再構築
ユーザーは Explore のメニューから [派生テーブルを再構築して実行する] オプションを選択すると、永続性設定がオーバーライドされ、Explore の現在のクエリに必要なすべての永続的な派生テーブル(PDT)と集計テーブルを再構築できます。
![Explore アクション ボタンをクリックすると [Explore] メニューが開き、[Rebuild Derived Tables & Run] を選択できます。](https://cloud-dot-devsite-v2-prod.appspot.com/static/looker/docs/images/develop-caching-rebuild-derived-tables-720.png?hl=ja)
このオプションは、ユーザーに develop 権限があり、データ探索クエリが読み込まれた後にのみ表示されます。
[派生テーブルを再構築して実行する] オプションは、永続性戦略に関係なく、クエリへの応答に必要なすべての永続テーブル(すべての PDT と集約テーブル)を再構築します。これには、現在のクエリの集約テーブルと PDT が含まれます。また、現在のクエリの集約テーブルと PDT によって参照されている集約テーブルと PDT も含まれます。
増分 PDT の場合、[派生テーブルを再構築して実行する] オプションによって新しい増分の構築がトリガーされます。増分 PDT の場合、増分には、increment_key パラメータで指定された期間と、存在する場合は、increment_offset パラメータで指定された過去の期間の数が含まれます。構成に応じて増分 PDT がどのようにビルドされるかを示すシナリオの例については、増分 PDT のドキュメント ページをご覧ください。
カスケード PDT の場合、カスケード内のすべての派生テーブルを上から順に再構築します。これは、一時的な派生テーブルのカスケードでテーブルをクエリする場合と同じ動作です。
派生テーブルを手動で再構築する場合は、次の点に注意してください。
- [派生テーブルを再構築して実行する] オプションを開始したユーザーの場合、クエリは、テーブルが再構築されるのを待ってから結果を読み込みます。他のユーザーのクエリには、引き続き既存のテーブルが使用されます。永続的なテーブルが再構築された後、すべてのユーザーは再構築されたテーブルを使用します。このプロセスは、テーブルの再構築中に他のユーザーのクエリを中断しないように設計されていますが、データベースへの負荷増大という形で他のユーザーに影響が及ぶ可能性はあります。業務時間内に再構築をトリガーするとデータベースに許容できない負荷が生じうる状況においては、その時間に特定のPDTや集計テーブルを再構築しないようユーザーへの周知が必要となる場合もあります。
ユーザーが Development Mode で操作しており、Explore が開発テーブルをベースとしている場合は、派生テーブルの作成と実行オペレーションを実行すると、Explore に対して本番環境テーブルではなく、開発テーブルが再構築されます。ただし、Development Mode で Explore が派生テーブルの本番環境バージョンを使用している場合は、本番環境テーブルが再構築されます。開発テーブルと本番環境テーブルについては、Development Mode の永続テーブルをご覧ください。
Looker ホスト型のインスタンスの場合、派生テーブルの再構築に 1 時間以上かかると、テーブルは正常に再構築されず、ブラウザ セッションがタイムアウトします。Looker プロセスに影響する可能性のあるタイムアウトの詳細については、管理者設定 - クエリのドキュメント ページのクエリのタイムアウトとキューイングのセクションをご覧ください。
開発モードの永続テーブル
Looker には、Development Mode で永続テーブルを管理するための特別な動作があります。
定義を変更することなく Development Mode で永続テーブルに対してクエリを実行すると、Looker によって対象テーブルの本番環境バージョンに対してクエリが実行されます。 テーブルの定義や、テーブルに対するクエリの方法を変更するテーブル定義に変更を加えると、次回テーブルに対してクエリを実行したときに、新しい開発バージョンのテーブルが作成されます。このような開発テーブルがあれば、ユーザーに影響を及ぼすことなく変更内容をテストできます。
Lookerで開発テーブルが作成されるきっかけ
可能な場合、Lookerは、開発モードかどうかに関係なく、既存のプロダクションテーブルを使用してクエリに答えます。ただし、Lookerは開発モードでクエリにプロダクションテーブルを使用できない次のような場合もあります:
- 永続テーブル内に、Development Mode で作業時間を短縮するためにデータセットを絞り込むパラメータがある場合
- テーブル内のデータに影響を与える変更を永続テーブルの定義に加えた場合
Development Mode で操作しており、if prod ステートメントと if dev ステートメントで条件付き WHERE 句を使用して定義された SQL ベースの派生テーブルをクエリすると、Looker は開発テーブルを構築します。
Development Mode でデータセットを絞り込むパラメータがない永続テーブルでは、テーブルの定義を変更してから、Development Mode でテーブルをクエリしない限り、Looker は、Development Mode でテーブルの本番環境バージョンを使用してクエリに応答します。これによって、テーブル内のデータやテーブルのクエリ方法に影響を及ぼす変更がテーブルに加えられる場合があります。
Lookerで永続テーブルの開発バージョンが作成されるきっかけとなる変更タイプの例を次に示します(Lookerは、これらの変更を加えた後に続けてテーブルがクエリされた場合にのみ、テーブルを作成します)。
- 永続テーブル自体または必要なテーブル(カスケード派生テーブルの場合)での
explore_source、sql、query、sql_create、またはcreate_processの各パラメータを変更するなど、永続テーブルの基になるクエリの変更 - テーブルの永続性戦略の変更(テーブルの
datagroup_trigger、sql_trigger_value、interval_trigger、またはpersist_forの各パラメータの変更など) - 派生テーブルの
viewの名前を変更する - 増分 PDT の
increment_keyまたはincrement_offsetの変更 - 関連するモデルで使用されている
connectionの変更
テーブルのデータを変更しない、または Looker がテーブルをクエリする方法に影響しない変更については、開発テーブルは作成されません。典型的な例は publish_as_db_view パラメータです。開発モードでは、派生テーブルの publish_as_db_view 設定のみを変更する場合、Looker は派生テーブルを再構築する必要がないため、開発テーブルを作成しません。
Lookerが開発テーブルを永続化する期間
テーブルの実際の永続性戦略に関係なく、Looker では、開発の永続テーブルは persist_for: "24 hours" の永続性戦略があるものとして扱われます。Looker では、これによって開発テーブルを1日以上永続させないようにしています。これは Looker 開発者が開発中、非常に多くのテーブルを反復クエリし、毎回新しい開発テーブルがビルドされることがあるためです。開発テーブルによってデータベースが雑然とならないように、Looker では persist_for: "24 hours" 戦略を適用して、テーブルが頻繁にデータベースから削除されるようにします。
そうしない場合、Looker は本番環境モードで永続テーブルを構築する場合と同じ方法で、Development Mode で永続的な派生テーブル(PDT)と集約テーブルを構築します。
PDT または集計テーブルに変更をデプロイしたとき、データベース上で開発テーブルが永続化されている場合、Looker はユーザーがテーブルをクエリするときにテーブルが作成されるのを待つ必要がないようにするために、その開発テーブルを本番環境テーブルとして扱うことが頻繁に見られます。
変更をデプロイする場合、状況によっては、そのテーブルをプロダクションでクエリ対象として引き続き再構築しなければならない場合があります。
- Development Mode でテーブルをクエリしてから 24 時間超経過すると、テーブルの開発バージョンに期限切れとのタグが付けられ、クエリに使用されなくなります。Looker IDE を使用して、または永続的な派生テーブルページの [開発環境] タブを使用してビルドされていない PDT を確認できます。未作成のPDTがある場合は、変更を加える直前に開発モードで未作成のPDTをクエリすることで、開発テーブルをプロダクションで使用できるようになります。
- 永続テーブルに
dev_filtersパラメータ(ネイティブ派生テーブルの場合)が含まれている、またはif prodステートメントとif devステートメントを使用する条件付きのWHERE句が含まれている場合(SQL ベースの派生テーブルの場合)、開発バージョンに省略されたデータセットが含まれているため、開発テーブルを本番環境バージョンとして使用できません。このような場合は、テーブルの開発が完了してから変更をデプロイする前に、dev_filtersパラメータまたは条件付きWHERE句をコメントアウトして、Development Mode でテーブルに対してクエリを実行できます。こうすることで、Lookerは変更をデプロイした後もプロダクションで使用可能なフルバージョンのテーブルを構築します。
一方、本番環境テーブルとして使用可能である有効な開発テーブルがない場合に変更をデプロイすると、Looker は次回テーブルが本番環境モードでクエリされたとき(persist_for 戦略を使用する永続テーブルの場合)、または次回リジェネレータを実行したとき(datagroup_trigger、interval_trigger、または sql_trigger_value を使用する永続テーブルの場合)にテーブルを再構築します。
開発モードでの未作成のPDTの有無の確認
永続的な派生テーブル(PDT)または集約テーブルに変更をデプロイしたとき、データベース上で開発テーブルが永続化されている場合、Looker はユーザーがテーブルをクエリするときにテーブルが構築されるのを待つ必要がないようにするために、その開発テーブルを本番環境テーブルとして扱うことが頻繁に見られます。詳しくは、このページの Looker が開発テーブルを保持する期間と Looker で開発テーブルが作成されるきっかけのセクションをご覧ください。
したがって、プロダクションにデプロイする時点ですべての PDT が作成済みであり、それらのテーブルをプロダクションバージョンとして直ちに使用できるのが最善です。
[プロジェクトの健全性] パネルで、PDT が再ビルドされていないプロジェクトを確認できます。Looker IDE で [プロジェクトの健全性] アイコンをクリックして [プロジェクトの健全性] パネルを開きます。次に、[PDTステータスの検証] ボタンをクリックします。

未構築のPDTが検出されると、[プロジェクトの健全性] パネルに一覧表示されます。
![[プロジェクトの健全性] パネルには、プロジェクトの未ビルドの PDT のリストと [PDT 管理に移動] ボタンの両方が表示されます。](https://cloud-dot-devsite-v2-prod.appspot.com/static/looker/docs/images/dev-unbuilt-pdts-list-2116.png?hl=ja)
see_pdts 権限を付与されている場合は、[PDT 管理に移動] ボタンをクリックできます。[永続的な派生テーブル] ページの [開発] タブが開き、結果が特定の LookML プロジェクトにフィルタされます。同じ場所で、どの開発 PDT が作成済みで、どの開発 PDT が未作成かを確認でき、その他のトラブルシューティング情報にアクセスできます。詳細については、管理者設定 - 永続的な派生テーブルのドキュメント ページをご覧ください。
プロジェクトで構築されていない PDT を特定したら、テーブルをクエリする Explore を開いて、[Explore] メニューの [派生テーブルを再構築して実行する] オプションを使用して開発版を構築することができます。このページのクエリ用の永続テーブルを手動で再構築するセクションをご覧ください。
テーブルの共有とクリーンアップ
任意のLookerインスタンス内で永続テーブルの定義と永続性メソッド設定が同一である場合、ユーザー間でそのテーブルを共有します。さらに、テーブルの定義が存在しなくなった場合には、Looker はそのテーブルを期限切れとしてマークします。
これにはいくつかの利点があります。
- Development Mode でテーブルに対して変更を加えていない場合には、既存の本番環境テーブルがクエリで使用されます。この内容が該当するのは、テーブルが
if prodステートメントとif devステートメントで条件付きWHERE句を使用して定義された SQL ベースの派生テーブルではない場合です。条件付きWHERE句でテーブルが定義されている場合は、Development Mode でそのテーブルをクエリすると、Looker が開発テーブルをビルドします。(dev_filtersパラメータが含まれるネイティブ派生テーブルの場合、テーブルの定義を変更してから、Development Mode でテーブルをクエリしない限り、Looker は本番環境テーブルを使用して Development Mode でクエリに応答するロジックに基づいて動作します)。 - 開発者2人が開発モードでテーブルに同一の変更を加えた場合には、これらの開発者の間で同じ開発テーブルが共有されます。
- 開発モードからプロダクションモードへ変更内容をプッシュすると、古いプロダクションの定義は存在しなくなるため、古いプロダクションテーブルは期限切れとしてマークされ、削除されます。
- 開発モードの変更を廃棄することを決定した場合には、そのテーブルの定義は存在しなくなるため、不要な開発テーブルは期限切れとしてマークされ、削除されます。
開発モードでの作業の効率化
作成中の永続的な派生テーブル(PDT)を生成するのに長時間を要する場合もあり、Development Mode で多数の変更内容をテストしている場合は、時間がかかることがあります。このような場合は、Development Mode で操作している際に、Looker でよりサイズの小さい派生テーブルが作成されるように指定できます。
ネイティブ派生テーブルの場合、explore_source の dev_filters サブパラメータを使用して、派生テーブルの開発版にのみ適用されるフィルタを指定できます。
view: e_faa_pdt {
derived_table: {
...
datagroup_trigger: e_faa_shared_datagroup
explore_source: flights {
dev_filters: [flights.event_date: "90 days"]
filters: [flights.event_date: "2 years", flights.airport_name: "Yucca Valley Airport"]
column: id {}
column: airport_name {}
column: event_date {}
}
}
...
}
この例では、過去 90 日間のデータをフィルタリングして表示する dev_filters パラメータと、過去 2 年間かつ Yucca Valley Airport のデータをフィルタリングして表示する filters パラメータが含まれています。
dev_filters パラメータは filters パラメータと連動して動作し、すべてのフィルタがテーブルの開発バージョンに適用されるようになります。dev_filters と filters の両方が同じ列のフィルタを指定した場合、テーブルの開発バージョンには dev_filters が優先されます。この例では、開発バージョンのテーブルは過去90日間のYucca Valley Airportのデータをフィルタリングして表示します。
SQL ベースの派生テーブルの場合、Looker ではテーブルの本番環境(if prod)版と開発(if dev)版でさまざまなオプションを使用して、条件付き WHERE 句がサポートされます。
view: my_view {
derived_table: {
sql:
SELECT
columns
FROM
my_table
WHERE
-- if prod -- date > '2000-01-01'
-- if dev -- date > '2020-01-01'
;;
}
}
この例では、プロダクションモードのクエリでは2000年以降のすべてのデータが含まれますが、開発モードのクエリでは2020年以降のデータのみが含まれます。この機能を戦略的に使用して結果セットを制限し、クエリ速度を向上させることで、開発モードの変更の検証が大幅にしやすくなります。
Looker による PDT の構築の仕組み
永続的な派生テーブル(PDT)が定義され、永続性戦略に従って再構築するため、リジェネレータによって初回実行されるか、またはトリガーされるかのいずれかの後、Looker は以下の手順を実施します。
- 派生テーブルの SQL を使用して CREATE TABLE AS SELECT(CTAS)ステートメントを作成し、実行します。たとえば、
customer_orders_factsという PDT を再構築するには、次のようにします。CREATE TABLE tmp.customer_orders_facts AS SELECT ... FROM ... WHERE ... - テーブルの構築時にインデックスを作成するステートメントを発行する
- テーブルの名前を LC$..(「Looker Create」)から LR$..(「Looker Read」)に変更し、テーブルが使用可能であることを確認する
- 使用しなくなった古いバージョンのテーブルを削除する
重要な意味合いがいくつかあります。
- 派生テーブルを形成する SQL は、CTAS ステートメント内で有効である必要があります。
- SELECT ステートメントの結果セットの列エイリアスは、有効な列名である必要があります。
- 分布、ソートキー、インデックスを指定するときに使用する名前は、LookML で定義されたフィールド名ではなく、派生テーブルの SQL 定義にリストされる列名にする必要があります。
Lookerリジェネレータ
Lookerリジェネレーターは、トリガー永続テーブルのステータスをチェックし、再構築を開始します。トリガー永続テーブルは、永続的な派生テーブル(PDT)または集約テーブルで、トリガーを永続性戦略として使用します。
sql_trigger_valueを使用するテーブルの場合、トリガーはテーブルのsql_trigger_valueパラメータで指定されたクエリです。Lookerリジェネレータは、直近のトリガークエリチェックの結果が前回のトリガークエリチェックの結果と異なる場合に、テーブルの再構築をトリガーします。たとえば、派生テーブルが SQL クエリSELECT CURDATE()で永続化されている場合、Looker リジェネレータは、日付が変わった後、次にトリガーをチェックするときにテーブルを再構築します。interval_triggerを使用するテーブルの場合、トリガーはテーブルのinterval_triggerパラメータで指定された期間です。Lookerリジェネレータは、指定した時間が経過すると、テーブルの再構築をトリガーします。datagroup_triggerを使用するテーブルの場合、トリガーは、関連するデータグループのsql_triggerパラメータで指定されたクエリ、またはデータグループのinterval_triggerパラメータで指定された期間のいずれかです。
Looker のリジェネレータは、persist_for パラメータを使用する永続テーブルの再ビルドも開始しますが、これは、persist_for テーブルがトリガー永続テーブルの依存関係カスケードである場合に限られます。この場合、Looker のリジェネレータは persist_for テーブルの再構築を開始します。これは、このテーブルが他のカスケードのテーブルを再構築するのに必要であるためです。それ以外の場合、リジェネレータは persist_for 戦略を使用する永続テーブルをモニタリングしません。
Looker のリジェネレータ サイクルは、Looker 管理者がデータベース接続の [メンテナンス スケジュール] で構成した定期的な間隔で開始されます(デフォルトは 5 分間隔)。ただし、Looker の リジェネレータは、すべてのチェックが完了し、前のサイクルから PDT が再ビルドされるまで、新しいサイクルは開始しません。つまり、長時間実行される PDT ビルドがある場合、Looker のリジェネレータ サイクルは [メンテナンス スケジュール] で定義する頻度よりも低頻度で実行される可能性があります。テーブルの再構築に必要な時間は、このページの永続テーブルの導入に関する重要な考慮事項のセクションで説明するように、他の要素にも影響されることがあります。
PDT の構築に失敗した場合、リジェネレータは次のリジェネレータ サイクルでテーブルの再構築を試みる可能性があります。
- [Retry Failed PDT Builds] 設定をデータベース接続で有効にすると、Looker のリジェネレータは、テーブルのトリガー条件が満たされていない場合でも、次のリジェネレータ サイクル中にテーブルの再ビルドを試行します。
- [Retry Failed PDT Builds] 設定が無効になっている場合、Looker のリジェネレータは、PDT のトリガー条件が満たされるまで、テーブルの再ビルドを試行しません。
ユーザーがビルド中の永続テーブルからのデータをリクエストし、そのクエリ結果がキャッシュされていない場合、Looker は既存のテーブルがまだ有効であるかどうかをチェックします。(新バージョンのテーブルと互換性がない旧テーブルは無効になる場合があります。これは、新テーブルに異なる定義がある、新テーブルで別のデータベース接続を使用している、または新テーブルがLookerの別のバージョンで作成されている場合に発生する可能性があります)。既存のテーブルがまだ有効な場合、Lookerは新しいテーブルがビルドされるまで既存のテーブルからデータを返します。一方、既存のテーブルが有効でない場合、Lookerは新しいテーブルが再ビルドされてからクエリ結果を返します。
永続テーブルの導入に関する重要な考慮事項
永続テーブル(PDT と集約テーブル)の有用性を考慮すると、多くのテーブルを Looker インスタンスに蓄積できます。Looker リジェネレーターが同時に多数のテーブルをビルドする必要があるシナリオを作成できます。特に、カスケード テーブルや実行時間の長いテーブルでは、テーブルの再構築までに時間がかかるシナリオや、データベースがテーブルを生成しょうとしている最中にそのテーブルからクエリ結果を得ようとすると遅延が発生するシナリオを作成できます。
Looker のリジェネレータにより、PDT トリガーがトリガー永続テーブルを再構築すべきかどうかが確認されます。リジェネレータ サイクルは、Looker 管理者がデータベース接続の [メンテナンス スケジュール] で構成した定期的な間隔で設定されます(デフォルトは 5 分間隔)。
テーブルの再構築にかかる時間には、いくつかの要因が影響します。
- Looker 管理者は、データベース接続の [メンテナンス スケジュール] の設定を使用して、リジェネレータ トリガーのチェック間隔を変更している可能性があります。
- Looker の リジェネレータは、すべてのチェックが完了し、前のサイクルから PDT が再ビルドされるまで、新しいサイクルは開始しません。そのため、長時間実行される PDT ビルドがある場合は、Looker のリジェネレータ サイクルが [メンテナンス スケジュール] の設定ほど頻繁に行われない場合があります。
- デフォルトでは、リジェネレーターは1つの接続で1回、1つのPDTか集計テーブルの再ビルドを開始できます。Looker 管理者は、接続設定の [PDT ビルダーの最大接続数] フィールドを使用して、リジェネレータが同時に再構築できる回数を調整できます。
- 同じ
datagroupによってトリガーされるすべての PDT および集計テーブルは、同じ再生成プロセスで再構築されます。直接、またはカスケードの依存関係の結果として、データグループを使用しているテーブルが多数ある場合、負荷が大きくなる可能性があります。
また、前述の考慮事項に加え、以下のように派生テーブルへ永続性を追加すべきでない状況もあります。
- 派生テーブルが拡張されるとき - PDT の各拡張によって、データベースにテーブルの新しいコピーが作成されます。
- 派生テーブルがテンプレート フィルタまたは Liquid パラメータを使用している場合 - テンプレート フィルタまたは Liquid パラメータを使用する派生テーブルでは、永続性はサポートされていません。
- ネイティブ派生テーブルが
access_filtersまたはsql_always_whereでユーザー属性を使用する Explore からビルドされている場合 - テーブルのコピーが指定された任意のユーザー属性値ごとにデータベースでビルドされます。 - 基盤となるデータが頻繁に変更され、データベース言語が増分 PDT をサポートしていない場合。
- PDT の作成にかかるコストと時間が大きすぎる場合。
Looker 接続での永続テーブルの数と複雑さによっては、サイクルごとにチェックし、再構築する必要のある永続テーブルがキューに多数含まれることになります。このため、Looker インスタンスに派生テーブルを導入するには、これらの要素を念頭に置くことが重要です。
API を使用した大規模な PDT の管理
インスタンスで多くの PDT を作成すると、さまざまなスケジュールで更新される永続的な派生テーブル(PDT)の監視と管理がより複雑になります。Looker の Apache Airflow 統合を使用して、他の ETL プロセスや ELT プロセスとともに PDT スケジュールを管理することを検討してください。
PTDの監視とトラブルシューティング
永続的な派生テーブル(PDT)、特にカスケード PDT を使用する場合は、PDT のステータスを確認すると便利です。Looker の 永続的な派生テーブルの管理ページを使用すると、PDT のステータスを確認できます。PDT のトラブルシューティング ツリーで、デバッグの手順を確認することもできます。
PDT のトラブルシューティングを行う際の留意点は次のとおりです。
- PDT イベントログの調査時には、開発テーブルとプロダクション テーブルの対比に特に注意を払う。
- Looker 接続の [一時データベース] 設定が、実際のスクラッチ スキーマまたはデータベースと一致していることを確認します。接続の [一時データベース] 設定がデータベースのスクラッチ スキーマと一致しない場合は、Looker が永続的な派生テーブルをデータベースに保存できるように、[一時データベース] 設定を更新します。
- すべてのPDTに関して問題があるのか、または1つのみに関して問題があるのかを判断する。1つのみに問題がある場合には、LookMLまたはSQLのエラーが問題の原因である可能性が高くなります。
- PDTに関する問題が再構築のスケジュールされている時間に発生するかどうかを判断する。
- すべての
sql_trigger_valueクエリの評価が正しく行われており、1 行と 1 列のみが返されることを確認します。SQL ベースの PDT の場合は、SQL Runner で実行することで実行できます(ランナウェイクエリからLIMITの保護を適用します)。SQL Runner を使用して派生テーブルをデバッグする際の詳細については、sql runner を使用して派生テーブルをテストするのコミュニティ投稿をご覧ください。 - SQLベースのPDTの場合には、SQL Runnerを使用して対象のPDTのSQLがエラーなく実行することを検証する (適切なクエリ時間を保つため、SQL Runner では必ず
LIMITを適用してください)。 - SQL ベースの派生テーブルでは、共通テーブル式(CTE)の使用を避けてください。DT で CTE を使用すると、ネストされた
WITHステートメントが作成され、警告なしで PDT が失敗する可能性があります。代わりに、CTE の SQL を使用してセカンダリ DT を作成し、${derived_table_or_view_name.SQL_TABLE_NAME}構文を使用して最初の DT からその DT を参照します。 - 問題の PDT が依存するテーブル(通常のテーブルまたは PDT 自体)が存在し、クエリが可能であることを確認してください。
- 問題の PDT の依存対象となるテーブルに、共有ロックや排他ロックがないことを確認します。Looker が PDT を正常にビルドするには、更新が必要なテーブルの排他ロックを獲得する必要があります。これは、テーブルに現在適用されている共有ロックまたは排他ロックと競合します。他のすべてのロックがクリアされるまで、LookerはPDTを更新できません。このことは、Looker が PDT をビルドする際のベースとなるテーブルのどの排他ロックにも該当します。テーブルに排他ロックがある場合、排他ロックがクリアされるまでは、Looker はクエリ実行のために共有ロックを獲得することができません。
- SQL Runner で [プロセスを表示] ボタンを使用する。多数のプロセスがアクティブとなっている場合には、クエリに要する時間が長くなる可能性があります。
- 対象のクエリ内のコメントを監視する。このページの PDT のクエリコメントセクションをご覧ください。
PDTのクエリコメント
データベース管理者は、通常のクエリと永続的な派生テーブル(PDT)を生成するクエリを区別できます。Looker は、対象の PDT の LookML モデルおよびビュー、さらに Looker インスタンスの一意の識別子(スラッグ)を含む CREATE TABLE ... AS SELECT ... ステートメントにコメントを追加します。対象の PDT がユーザーに代わり Development Mode で生成されている場合には、コメントにはユーザーの ID が表示されます。PDT生成コメントは、次のパターンに従います。
-- Building `<view_name>` in dev mode for user `<user_id>` on instance `<instance_slug>`
CREATE TABLE `<table_name>` SELECT ...
-- finished `<view_name>` => `<table_name>`
Explore のクエリに代わり Looker が PDT を生成した場合には、PDT 生成コメントが Explore の SQL タブに表示されます。コメントはSQLステートメントの上部に表示されます。

最後に、クエリ管理ページで各クエリのクエリの詳細ポップアップの情報タブにあるメッセージフィールドに PDT 生成コメントが表示されます。
障害の後のPDTの再構築
永続的な派生テーブル(PDT)に障害が発生した場合、その PDT に対してクエリが実行されると次のことが発生します。
- 同じクエリがすでに実行されていた場合は、Lookerがキャッシュ内の結果を使用します。(仕組みについては、クエリのキャッシングのドキュメント ページをご覧ください。)
- 結果がキャッシュにない場合、Looker はデータベース内に有効な PDT バージョンがあれば、その PDT から結果を pull します。
- データベース内に有効なPDTがない場合は、PDTの再構築が試行されます。
- PDT を再構築できない場合、Looker はクエリのエラーを返します。Looker のリジェネレータは、次に PDT がクエリされたとき、または PDT の永続性戦略が再構築をトリガーしたときに、PDT の再構築を試みます。
カスケード PDTにも同じロジックが適用されますが、カスケード PDT に関しては次の点が例外となります。
- 1つのテーブルのビルドに失敗したため、依存関係チェーン下方のPDTを構築できない。
- 依存 PDT は基本的に依存先である PDT をクエリするため、あるテーブルの永続性戦略が、依存関係で上位にある PDT の再構築をトリガーする場合がある。
前述のカスケード テーブルの例をもう一度見てみましょう。TABLE_A に依存する TABLE_B に依存する TABLE_C に TABLE_D が依存しています。
TABLE_B が失敗した場合、TABLE_B には標準(カスケードなし)の動作がすべて適用されます。
TABLE_Bがクエリされると、Looker はまずキャッシュを使用して結果を返そうとします。- この試行が失敗した場合、Looker は可能であれば、テーブルの以前のバージョンの使用を試みます。
- この試行も失敗した場合、Looker はテーブルの再構築を試みます。
- 最後に、
TABLE_Bを再構築できない場合、Looker はエラーを返します。
Looker は、テーブルが次回クエリされたとき、またはテーブルの永続性戦略が次回再構築をトリガーしたときに、TABLE_B をもう一度再構築しようとします。
これは TABLE_B の依存関係についても同様です。そのため、TABLE_B を構築できず、TABLE_C に対するクエリがある場合は、次のシーケンスが発生します。
- Looker は、
TABLE_Cに対するクエリにキャッシュを使用しようとします。 - 結果がキャッシュにない場合、Looker はデータベースの
TABLE_Cから結果を pull しようとします。 TABLE_Cの有効なバージョンがない場合、Looker はTABLE_Cの再構築を試み、これによってTABLE_Bに対するクエリが作成されます。- その後、Looker が
TABLE_Bの再構築を試みます(TABLE_Bが修正されていない場合は、失敗します)。 TABLE_Bを再構築できない場合、TABLE_Cが再構築できないため、Looker はTABLE_Cに対するクエリに対してエラーを返します。- 次に、Looker は通常の永続性戦略に従って、または次に PDT がクエリされたとき(
TABLE_DはTABLE_Cに依存するため、これには次回TABLE_Dが再構築を試みる場合も含まれます)に、TABLE_Cの再構築を試みます。
TABLE_B の問題が解決したら、TABLE_B とそれに依存する各テーブルが、永続性戦略に従って、または次回クエリされたとき(これには次回、依存 PDT が再構築を試みた場合も含まれます)に、再構築を試みます。あるいは、カスケード内のPDTの開発バージョンが開発モードでビルドされている場合は、開発バージョンが新しいプロダクションPDTとして使用される場合があります。(仕組みについては、このページの Development Mode の永続テーブル セクションをご覧ください)。また、Explore を使用して TABLE_D に対するクエリを実行してから、クエリの PDT を手動で再構築することもできます。これにより、依存関係カスケードの上方の PDT すべてが強制的に再構築されます。
PDT のパフォーマンスの改善
永続的な派生テーブル(PDT)を作成する場合、パフォーマンスが懸念されることがあります。特にテーブルが非常に大規模である場合は、データベース内の大規模なテーブルの場合と同様に、テーブルに対するクエリの実行速度が低下する可能性があります。
パフォーマンスを改善するには、データをフィルタリングするか、PDT 内のデータの並べ替え方法とインデックス登録方法を制御します。
フィルタを追加してデータセットを制限する
特に大規模なデータセットでは、多数の行が存在すると永続的な派生テーブル(PDT)に対するクエリの実行速度が低下します。最近のデータのみをクエリすることが多い場合は、PDT の WHERE 句にフィルタを追加して、テーブルを 90 日以内のデータに制限することを検討してください。これにより、テーブルが再構築されるたびに関連データのみが追加されるため、クエリの実行が大幅に高速化されます。次に、履歴分析用に別の大きな PDT を作成して、最近のデータに対する高速クエリと古いデータのクエリの両方を可能にすることができます。
indexes または sortkeys と distribution の使用
大規模な永続的な派生テーブル(PDT)を作成する際は、テーブルのインデックス処理(MySQL や Postgres などの言語の場合)やソートキーと分布の追加(Redshift の場合)によってパフォーマンスを改善できます。
通常は、ID フィールドまたは日付フィールドに indexes パラメータを追加するのが最適です。
Redshift の場合は、通常、ID フィールドまたは日付フィールドに sortkeys パラメータを追加し、結合に使用されるフィールドに distribution パラメータを追加することをおすすめします。
パフォーマンスを改善するための推奨設定
次の設定は、永続的な派生テーブル(PDT)のデータの並べ替えとインデックス登録の方法を制御します。これらの設定は省略可能ですが、強くおすすめします。
- Redshift と Aster の場合は、
distributionパラメータを使用して、クラスタ全体にデータを分散するために値が使用される列名を指定します。2 つのテーブルがdistributionパラメータで指定された列で結合されると、データベースは同じノードで結合データを見つけることができるため、ノード間の I/O が最小限に抑えられます。 - Redshift の場合は、
distribution_styleパラメータをallに設定して、各ノードにデータの完全なコピーを保持するようにデータベースに指示します。この手法は、比較的小さなテーブルが結合されている場合に、ノード間の I/O を最小限に抑えるために頻繁に使用されます。この値をevenに設定すると、分布列を使用せずにクラスタ全体でデータを均等に分散するようデータベースに指示できます。この値は、distributionが指定されていない場合にのみ指定できます。 - Redshift の場合は、
sortkeysパラメータを使用します。これらの値は、検索を容易にするためにディスク上のデータを並べ替える際に検索に使用される PDT の列を指定します。Redshift では、sortkeysまたはindexesのどちらか一方のみ使用できます。 - ほとんどのデータベースでは、
indexesパラメータを使用します。これらの値は、PDT のどの列にインデックスを付けるかを指定します(Redshift では、インデックスはインターリーブされた並べ替えキーの生成に使用されます)。