Halaman ini menjelaskan konsep dan fitur utama Inference Gateway Google Kubernetes Engine (GKE), ekstensi ke Gateway GKE untuk penayangan aplikasi AI generatif yang dioptimalkan.
Halaman ini mengasumsikan bahwa Anda mengetahui hal-hal berikut:
- Orkestrasi AI/ML di GKE
- Terminologi AI generatif
- Konsep jaringan GKE, termasuk Layanan, dan GKE Gateway API
- Load balancing di Google Cloud, terutama cara load balancer berinteraksi dengan GKE
Halaman ini ditujukan untuk persona berikut:
- Engineer machine learning (ML), Admin dan operator platform, serta Spesialis Data dan AI yang tertarik untuk menggunakan kemampuan orkestrasi kontainer Kubernetes untuk melayani beban kerja AI/ML.
- Arsitek cloud dan spesialis Jaringan yang berinteraksi dengan jaringan Kubernetes.
Ringkasan
Gateway Inferensi GKE adalah ekstensi untuk Gateway GKE yang menyediakan perutean dan load balancing yang dioptimalkan untuk melayani workload Kecerdasan Buatan (AI) generatif. Layanan ini menyederhanakan deployment, pengelolaan, dan kemampuan pengamatan workload inferensi AI.
Untuk memilih strategi load balancing yang optimal untuk workload AI/ML Anda, lihat Memilih strategi load balancing untuk inferensi AI di GKE.
Fitur dan manfaat
GKE Inference Gateway menyediakan kemampuan utama berikut untuk menayangkan model AI generatif secara efisien untuk aplikasi AI generatif di GKE:
- Metrik yang didukung:
KV cache hits: jumlah pencarian yang berhasil dalam cache key-value (KV).- Penggunaan GPU atau TPU: persentase waktu GPU atau TPU memproses secara aktif.
- Panjang antrean permintaan: jumlah permintaan yang menunggu untuk diproses.
- Load balancing yang dioptimalkan untuk inferensi: mendistribusikan permintaan untuk mengoptimalkan performa penyaluran model AI. Layanan ini menggunakan metrik dari server model, seperti
KV cache hitsdanqueue length of pending requestsuntuk menggunakan akselerator (seperti GPU dan TPU) secara lebih efisien untuk beban kerja AI generatif. Hal ini memungkinkan Prefix-Cache Aware Routing, fitur utama yang mengirimkan permintaan dengan konteks bersama, yang diidentifikasi dengan menganalisis isi permintaan, ke replika model yang sama dengan memaksimalkan cache hit. Pendekatan ini secara signifikan mengurangi komputasi yang berlebihan dan meningkatkan Time-to-First-Token, sehingga sangat efektif untuk AI percakapan, Retrieval-Augmented Generation (RAG), dan beban kerja AI generatif berbasis template lainnya. - Penayangan model yang di-fine-tune LoRA dinamis: mendukung penayangan model yang di-fine-tune LoRA dinamis pada akselerator umum. Cara ini mengurangi jumlah GPU dan TPU yang diperlukan untuk menyajikan model dengan memultipleksing beberapa model yang di-fine-tune LoRA pada model dasar dan akselerator umum.
- Penskalaan otomatis yang dioptimalkan untuk inferensi: Autoscaler Pod Horizontal (HPA) GKE menggunakan metrik server model untuk menskalakan otomatis, yang membantu memastikan penggunaan resource komputasi yang efisien dan performa inferensi yang dioptimalkan.
- Perutean yang mendukung model: merutekan permintaan inferensi berdasarkan nama model yang ditentukan dalam spesifikasi
OpenAI APIdalam cluster GKE Anda. Anda dapat menentukan kebijakan perutean Gateway, seperti pembagian traffic dan duplikasi permintaan, untuk mengelola berbagai versi model dan menyederhanakan peluncuran model. Misalnya, Anda dapat merutekan permintaan untuk nama model tertentu ke objekInferencePoolyang berbeda, yang masing-masing menayangkan versi model yang berbeda. Untuk mengetahui informasi selengkapnya tentang cara mengonfigurasi hal ini, lihat Mengonfigurasi Perutean Berbasis Isi. - Pemfilteran konten dan keamanan AI terintegrasi: GKE Inference Gateway terintegrasi dengan Google Cloud Model Armor untuk menerapkan pemeriksaan keamanan AI dan pemfilteran konten pada perintah dan respons di gateway. Model Armor menyediakan log permintaan, respons, dan pemrosesan untuk analisis dan pengoptimalan retrospektif. Antarmuka terbuka GKE Inference Gateway memungkinkan penyedia dan developer pihak ketiga mengintegrasikan layanan kustom ke dalam proses permintaan inferensi.
- Penyajian khusus model
Priority: memungkinkan Anda menentukanPrioritypenyajian model AI. Prioritaskan permintaan yang sensitif terhadap latensi daripada tugas inferensi batch yang toleran terhadap latensi. Misalnya, Anda dapat memprioritaskan permintaan dari aplikasi yang sensitif terhadap latensi dan membatalkan tugas yang kurang sensitif terhadap waktu saat resource terbatas. - Observabilitas inferensi: menyediakan metrik observabilitas untuk permintaan inferensi, seperti rasio permintaan, latensi, error, dan saturasi. Pantau performa dan perilaku layanan inferensi Anda melalui Cloud Monitoring dan Cloud Logging, dengan memanfaatkan dasbor bawaan khusus untuk mendapatkan insight mendetail. Untuk mengetahui informasi selengkapnya, lihat Melihat dasbor GKE Inference Gateway.
- Pengelolaan API Tingkat Lanjut dengan Apigee: terintegrasi dengan Apigee untuk meningkatkan kualitas gateway inferensi Anda dengan fitur seperti keamanan API, pembatasan kapasitas, dan kuota. Untuk petunjuk mendetail, lihat Mengonfigurasi Apigee untuk autentikasi dan pengelolaan API.
- Ekstensibilitas: dibangun di atas Ekstensi Inferensi API Gateway Kubernetes open source yang dapat diperluas yang mendukung algoritma Pemilih Endpoint yang dikelola pengguna.
Memahami konsep utama
GKE Inference Gateway meningkatkan kualitas GKE
Gateway yang ada yang menggunakan objek
GatewayClass. GKE Inference Gateway memperkenalkan Definisi Resource Kustom (CRD) Gateway API baru berikut, yang selaras dengan ekstensi OSS Kubernetes Gateway API untuk Inferensi:
- Objek
InferencePool: merepresentasikan grup Pod (penampung) yang berbagi konfigurasi komputasi, jenis akselerator, model bahasa dasar, dan server model yang sama. Hal ini secara logis mengelompokkan dan mengelola resource penayangan model AI Anda. Satu objekInferencePooldapat mencakup beberapa Pod di berbagai node GKE dan memberikan skalabilitas serta ketersediaan tinggi. - Objek
InferenceObjective: menentukan nama model penayangan dariInferencePoolsesuai dengan spesifikasiOpenAI API. ObjekInferenceObjectivejuga menentukan properti penayangan model, sepertiPrioritymodel AI. Gateway Inferensi GKE memberikan preferensi pada workload dengan nilai prioritas yang lebih tinggi. Dengan begitu, Anda dapat memultipleks workload AI yang sensitif terhadap latensi dan yang toleran terhadap latensi di cluster GKE. Anda juga dapat mengonfigurasi objekInferenceObjectiveuntuk menayangkan model yang di-fine-tune LoRA.
Diagram berikut mengilustrasikan GKE Inference Gateway dan integrasinya dengan keamanan AI, kemampuan observasi, dan penayangan model dalam cluster GKE.
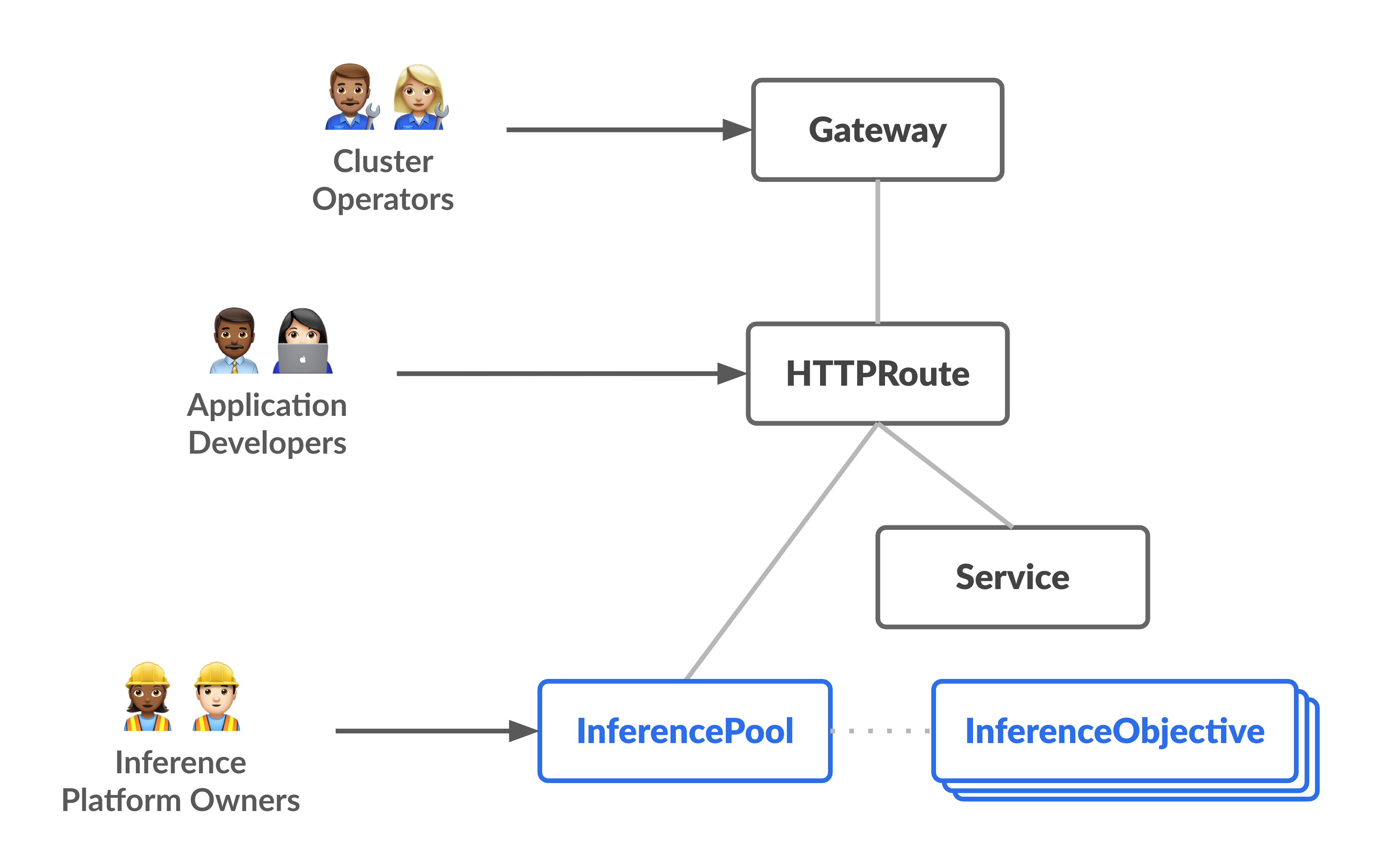
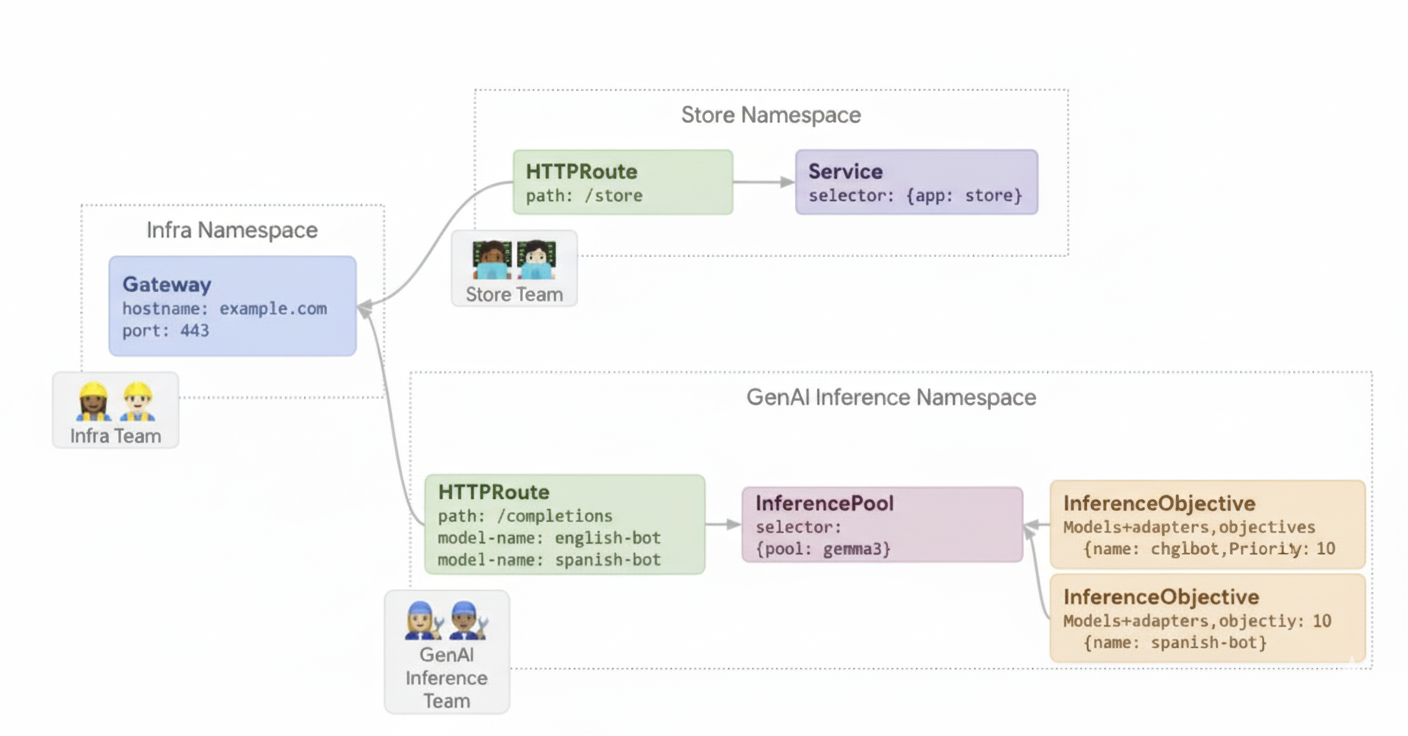
Diagram berikut mengilustrasikan model resource yang berfokus pada dua persona yang berfokus pada inferensi baru dan resource yang mereka kelola.
Cara kerja GKE Inference Gateway
GKE Inference Gateway menggunakan ekstensi Gateway API dan logika pemilihan rute khusus model untuk menangani permintaan klien ke model AI. Langkah-langkah berikut menjelaskan alur permintaan.
Cara kerja alur permintaan
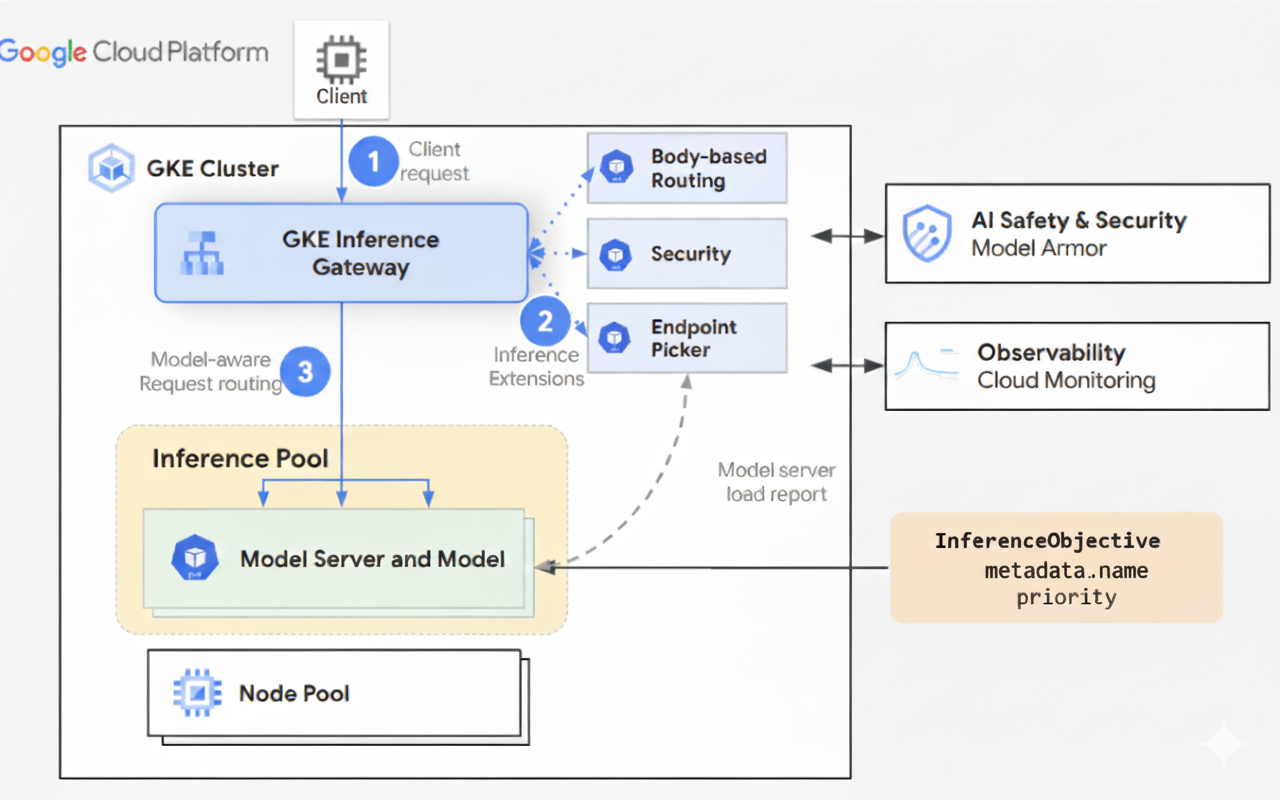
GKE Inference Gateway merutekan permintaan klien dari permintaan awal ke instance model. Bagian ini menjelaskan cara GKE Inference Gateway menangani permintaan. Alur permintaan ini umum untuk semua klien.
- Klien mengirimkan permintaan, yang diformat seperti yang dijelaskan dalam spesifikasi OpenAI API, ke model yang berjalan di GKE.
- GKE Inference Gateway memproses permintaan menggunakan ekstensi inferensi berikut:
- Ekstensi perutean berbasis isi: mengekstrak ID model dari isi permintaan klien dan mengirimkannya ke GKE Inference Gateway.
Kemudian, GKE Inference Gateway menggunakan ID ini untuk merutekan
permintaan berdasarkan aturan yang ditentukan dalam objek
HTTPRouteGateway API. Perutean isi permintaan mirip dengan perutean berdasarkan jalur URL. Perbedaannya adalah perutean isi permintaan menggunakan data dari isi permintaan. - Ekstensi keamanan: menggunakan Model Armor atau solusi pihak ketiga yang didukung untuk menerapkan kebijakan keamanan khusus model, yang mencakup pemfilteran konten, deteksi ancaman, pembersihan, dan pencatatan. Ekstensi keamanan menerapkan kebijakan ini ke jalur pemrosesan permintaan dan respons.
- Ekstensi pemilih endpoint: memantau metrik utama dari server model
dalam
InferencePool. Metrik ini melacak pemanfaatan cache nilai kunci (KV-cache), panjang antrean permintaan yang tertunda, indeks cache awalan, dan adaptor LoRA aktif di setiap server model. Kemudian, permintaan akan dirutekan ke replika model yang optimal berdasarkan metrik ini untuk meminimalkan latensi dan memaksimalkan throughput untuk inferensi AI.
- Ekstensi perutean berbasis isi: mengekstrak ID model dari isi permintaan klien dan mengirimkannya ke GKE Inference Gateway.
Kemudian, GKE Inference Gateway menggunakan ID ini untuk merutekan
permintaan berdasarkan aturan yang ditentukan dalam objek
- GKE Inference Gateway merutekan permintaan ke replika model yang ditampilkan oleh ekstensi pemilih endpoint.
Diagram berikut mengilustrasikan alur permintaan dari klien ke instance model melalui GKE Inference Gateway.
Cara kerja distribusi traffic
GKE Inference Gateway secara dinamis mendistribusikan permintaan inferensi ke server model dalam objek InferencePool. Hal ini membantu mengoptimalkan penggunaan resource dan mempertahankan performa dalam berbagai kondisi beban.
GKE Inference Gateway menggunakan dua mekanisme berikut untuk mengelola distribusi traffic:
Pemilihan endpoint: memilih server model yang paling sesuai secara dinamis untuk menangani permintaan inferensi. Load balancer memantau beban dan ketersediaan server, lalu membuat keputusan perutean yang optimal dengan menghitung
scoreuntuk setiap server dengan menggabungkan sejumlah heuristik pengoptimalan:- Perutean yang kompatibel dengan cache awalan: GKE Inference Gateway melacak indeks cache awalan yang tersedia di setiap server model, dan memberikan skor yang lebih tinggi ke server dengan kecocokan cache awalan yang lebih panjang.
- Perutean yang sadar beban: GKE Inference Gateway memantau beban server (penggunaan cache KV dan kedalaman antrean yang tertunda), dan memberikan skor yang lebih tinggi ke server dengan beban yang lebih rendah.
- Perutean yang kompatibel dengan LoRA: saat penayangan LoRA dinamis diaktifkan, GKE Inference Gateway akan memantau adaptor LoRA aktif per server, dan memberikan skor yang lebih tinggi ke server dengan adaptor LoRA yang diminta aktif, atau ruang tambahan untuk memuat adaptor LoRA yang diminta secara dinamis. Server dengan skor total tertinggi dari semua server sebelumnya akan dipilih.
Pengantrean dan pelepasan: mengelola alur permintaan dan mencegah kelebihan beban traffic. GKE Inference Gateway menyimpan permintaan masuk dalam antrean dan memprioritaskan permintaan berdasarkan prioritas yang ditentukan.
GKE Inference Gateway menggunakan sistem Priority numerik, yang juga dikenal sebagai
Criticality, untuk mengelola alur permintaan dan mencegah kelebihan beban. Priority ini adalah
kolom bilangan bulat opsional yang ditentukan oleh pengguna untuk setiap InferenceObjective. Nilai yang lebih tinggi menandakan permintaan yang lebih penting. Saat sistem mengalami
tekanan, permintaan dengan Priority kurang dari 0 dianggap memiliki
prioritas lebih rendah dan akan dibatalkan terlebih dahulu, sehingga menampilkan error 429 untuk melindungi workload yang lebih
kritis. Secara default, Priority adalah 0. Permintaan hanya
dibatalkan karena prioritas jika Priority ditetapkan secara eksplisit ke nilai yang lebih
kecil dari 0. Sistem ini memungkinkan Anda memprioritaskan traffic inferensi online yang sensitif terhadap latensi daripada tugas batch yang kurang sensitif terhadap waktu.
GKE Inference Gateway mendukung inferensi streaming untuk aplikasi seperti chatbot dan terjemahan live, yang memerlukan update berkelanjutan atau mendekati real-time. Inferensi streaming memberikan respons dalam potongan atau segmen inkremental, bukan output lengkap tunggal. Jika terjadi error selama respons streaming, streaming akan berakhir, dan klien akan menerima pesan error. GKE Inference Gateway tidak mencoba lagi respons streaming.
Mempelajari contoh aplikasi
Bagian ini memberikan contoh penggunaan GKE Inference Gateway untuk menangani berbagai skenario aplikasi AI generatif.
Contoh 1: Menyajikan beberapa model AI generatif di cluster GKE
Perusahaan ingin men-deploy beberapa model bahasa besar (LLM) untuk melayani berbagai workload. Misalnya, mereka mungkin ingin men-deploy model Gemma3 untuk antarmuka chatbot dan model Deepseek untuk aplikasi rekomendasi. Perusahaan perlu memastikan performa penayangan yang optimal untuk LLM ini.
Dengan GKE Inference Gateway, Anda dapat men-deploy LLM ini di cluster GKE dengan konfigurasi akselerator pilihan Anda di InferencePool. Kemudian, Anda dapat merutekan permintaan berdasarkan nama model (seperti
chatbot dan recommender) dan properti Priority.
Diagram berikut menggambarkan cara GKE Inference Gateway merutekan permintaan
ke model yang berbeda berdasarkan nama model dan Priority.
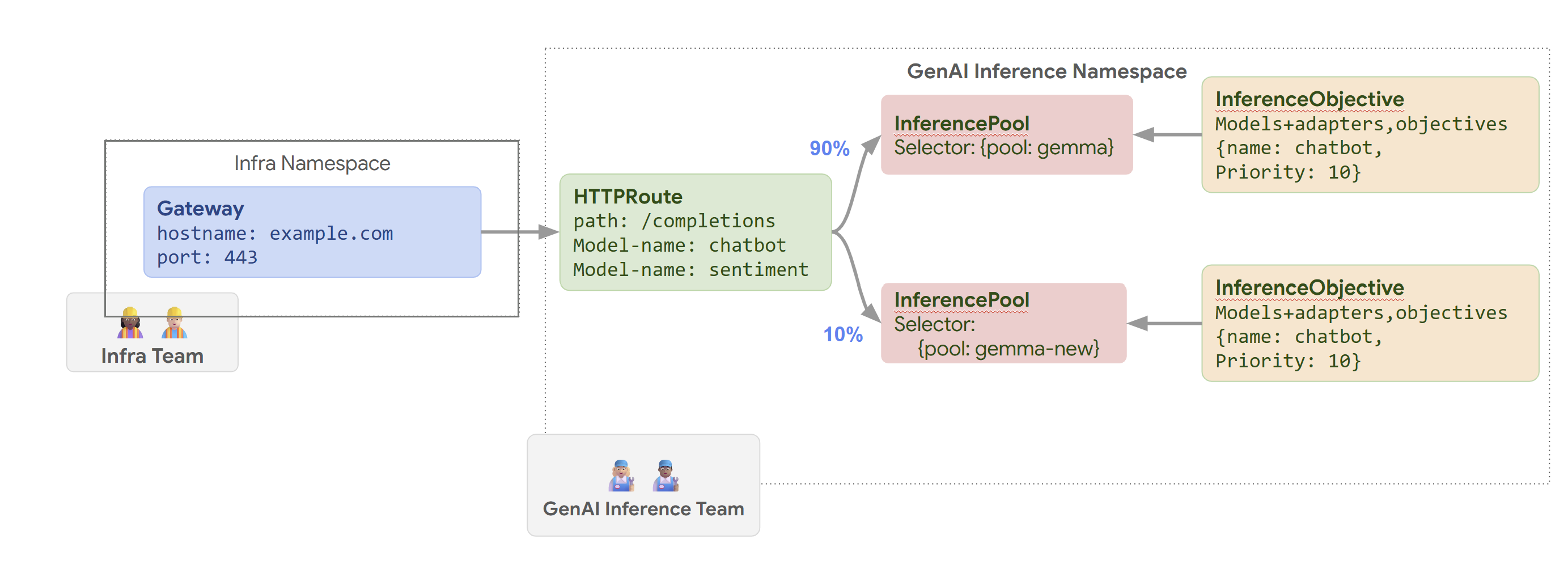
Diagram ini mengilustrasikan cara permintaan ke layanan GenAI di
example.com/completions ditangani oleh GKE Inference Gateway. Permintaan
pertama-tama mencapai Gateway di namespace Infra. Gateway ini meneruskan
permintaan ke HTTPRoute di namespace GenAI Inference, yang
dikonfigurasi untuk menangani permintaan untuk model chatbot dan sentimen. Untuk model chatbot, HTTPRoute membagi traffic: 90% diarahkan ke InferencePool yang menjalankan versi model saat ini (dipilih oleh {pool: gemma}), dan 10% masuk ke kumpulan dengan versi yang lebih baru ({pool: gemma-new}), biasanya untuk pengujian canary.
Kedua kumpulan tersebut ditautkan ke InferenceObjective yang menetapkan Priority sebesar 10
untuk permintaan model chatbot, sehingga memastikan permintaan ini diperlakukan sebagai
prioritas tinggi.
Contoh 2: Menyajikan adaptor LoRA pada akselerator bersama
Sebuah perusahaan ingin menayangkan LLM untuk analisis dokumen dan berfokus pada audiens dalam beberapa bahasa, seperti Inggris dan Spanyol. Mereka telah menyempurnakan model untuk setiap bahasa, tetapi perlu menggunakan kapasitas GPU dan TPU secara efisien. Anda dapat
menggunakan GKE Inference Gateway untuk men-deploy adapter yang di-fine-tune LoRA dinamis untuk
setiap bahasa (misalnya, english-bot dan spanish-bot) pada model dasar
umum (misalnya, llm-base) dan akselerator. Hal ini memungkinkan Anda mengurangi jumlah akselerator yang diperlukan dengan mengemas beberapa model secara padat pada akselerator umum.
Diagram berikut mengilustrasikan cara GKE Inference Gateway menayangkan beberapa adaptor LoRA pada akselerator bersama.
Langkah berikutnya
- Deploy GKE Inference Gateway
- Menyesuaikan konfigurasi GKE Inference Gateway
- Menyajikan LLM dengan GKE Inference Gateway