Anda dapat membuat pemberitahuan Monitoring yang memberi tahu Anda saat metrik cluster atau tugas Dataproc melebihi batas yang ditentukan.
Membuat pemberitahuan
Buka halaman Alerting di konsol Google Cloud .
Klik + Buat Kebijakan untuk membuka halaman Buat kebijakan pemberitahuan.
- Klik Pilih Metrik.
- Di kotak input "Filter menurut nama resource atau metrik", ketik "dataproc" untuk mencantumkan metrik Dataproc. Jelajahi hierarki metrik Cloud Dataproc untuk memilih metrik cluster, tugas, batch, atau sesi.
- Klik Terapkan.
- Klik Berikutnya untuk membuka panel Konfigurasi pemicu pemberitahuan.
- Tetapkan nilai minimum untuk memicu pemberitahuan.
- Klik Next untuk membuka panel Configure notifications and finalize alert.
- Tetapkan saluran notifikasi, dokumentasi, dan nama kebijakan pemberitahuan.
- Klik Berikutnya untuk meninjau kebijakan pemberitahuan.
- Klik Buat Kebijakan untuk membuat pemberitahuan.
Contoh pemberitahuan
Bagian ini menjelaskan contoh pemberitahuan untuk tugas yang dikirimkan ke layanan Dataproc dan pemberitahuan untuk tugas yang dijalankan sebagai aplikasi YARN.
Pemberitahuan tugas Dataproc yang berjalan lama
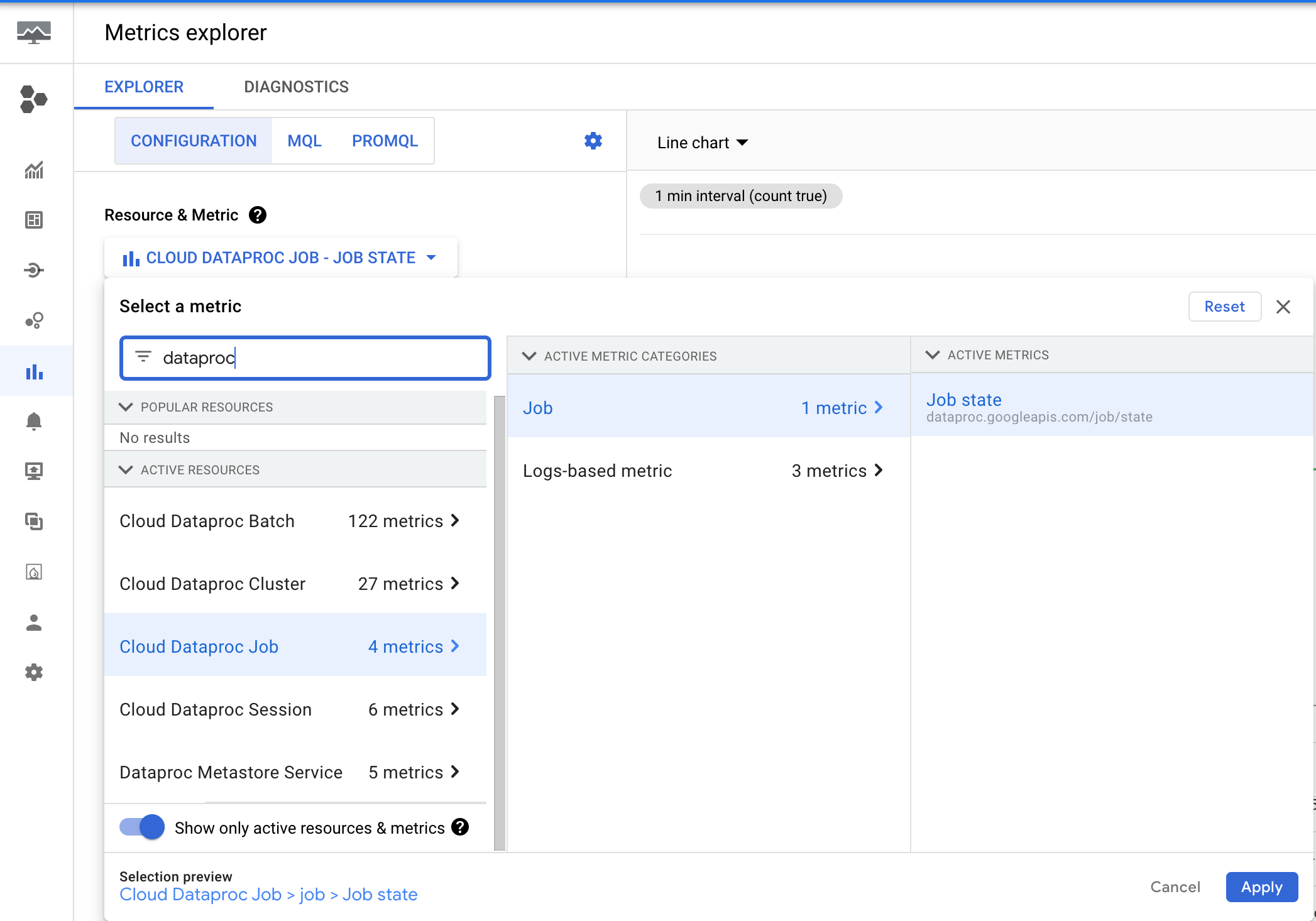
Dataproc memancarkan metrik dataproc.googleapis.com/job/state,
yang melacak berapa lama tugas berada dalam berbagai status. Metrik ini dapat ditemukan
di Metrics Explorer konsol Google Cloud di bagian resource Cloud Dataproc Job
(cloud_dataproc_job).
Anda dapat menggunakan metrik ini untuk menyiapkan pemberitahuan yang memberi tahu Anda saat status RUNNING tugas melebihi batas durasi.
Penyiapan pemberitahuan durasi tugas
Contoh ini menggunakan Monitoring Query Language (MQL) untuk membuat kebijakan pemberitahuan (lihat Membuat kebijakan pemberitahuan MQL (konsol)).
fetch cloud_dataproc_job
| metric 'dataproc.googleapis.com/job/state'
| filter metric.state == 'RUNNING'
| group_by [resource.job_id, metric.state], 1m
| condition val() == true()
Dalam contoh berikut, pemberitahuan dipicu saat tugas telah berjalan selama lebih dari 30 menit.

Anda dapat mengubah kueri dengan memfilter resource.job_id untuk menerapkannya
ke tugas tertentu:
fetch cloud_dataproc_job
| metric 'dataproc.googleapis.com/job/state'
| filter (resource.job_id == '1234567890') && (metric.state == 'RUNNING')
| group_by [resource.job_id, metric.state], 1m
| condition val() == true()
Pemberitahuan aplikasi YARN yang berjalan lama
Contoh sebelumnya menunjukkan pemberitahuan yang dipicu saat tugas Dataproc berjalan lebih lama
dari durasi yang ditentukan, tetapi hanya berlaku untuk tugas yang dikirimkan ke layanan
Dataproc menggunakan konsol Google Cloud , Google Cloud CLI, atau dengan panggilan langsung ke
Dataproc jobs API. Anda juga dapat menggunakan metrik OSS untuk menyiapkan pemberitahuan serupa yang memantau waktu berjalan aplikasi YARN.
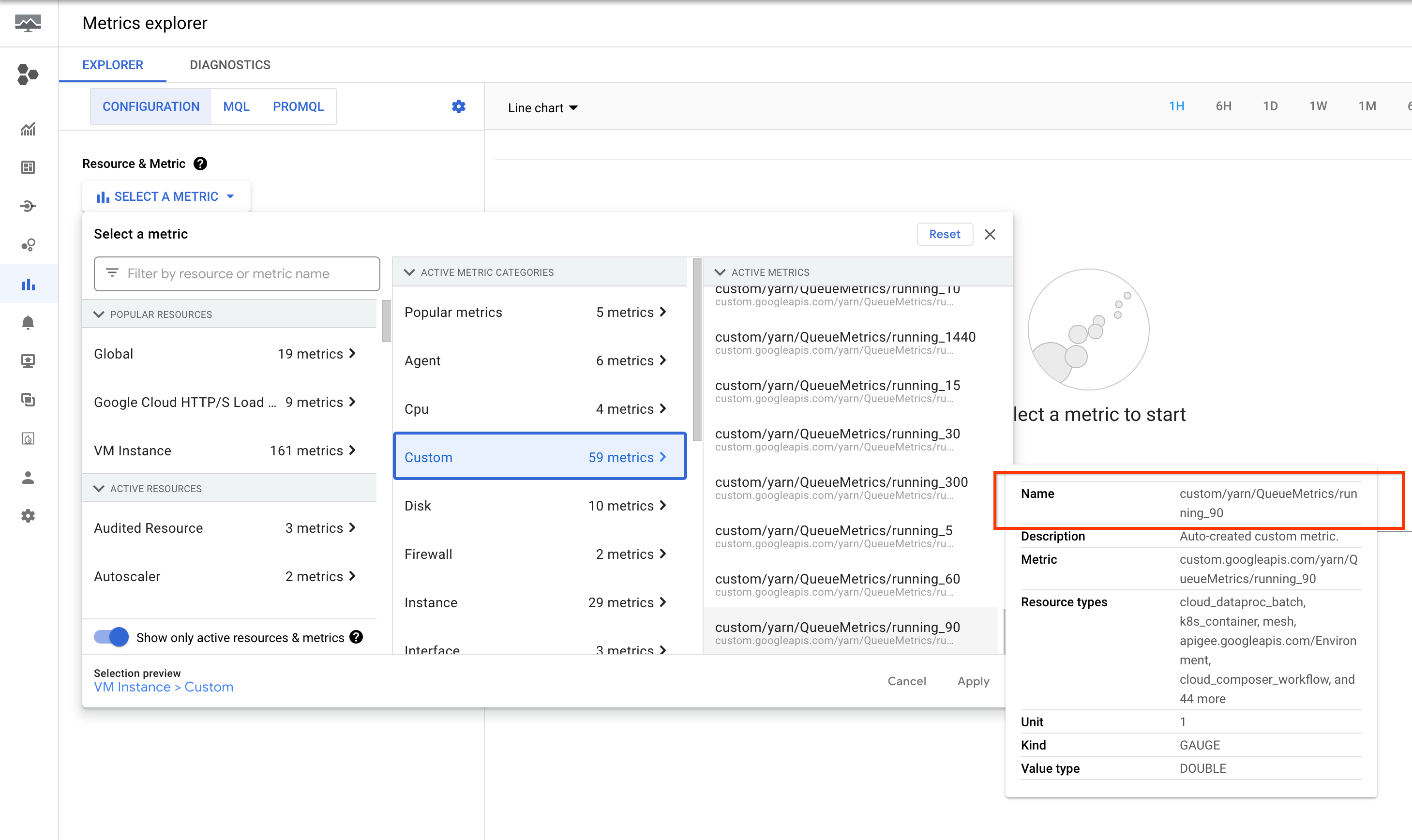
Pertama, beberapa latar belakang. YARN memancarkan metrik waktu berjalan ke dalam beberapa bucket.
Secara default, YARN mempertahankan 60, 300, dan 1440 menit sebagai nilai minimum bucket
dan memancarkan 4 metrik, running_0, running_60, running_300, dan running_1440:
running_0mencatat jumlah tugas dengan runtime antara 0 dan 60 menit.running_60mencatat jumlah tugas dengan runtime antara 60 dan 300 menit.running_300mencatat jumlah tugas dengan runtime antara 300 dan 1.440 menit.running_1440mencatat jumlah tugas dengan runtime lebih dari 1440 menit.
Misalnya, tugas yang berjalan selama 72 menit akan dicatat di running_60, tetapi tidak di running_0.
Nilai minimum bucket default ini dapat diubah dengan meneruskan nilai baru ke
yarn:yarn.resourcemanager.metrics.runtime.buckets
properti cluster
selama pembuatan cluster Dataproc. Saat menentukan nilai minimum bucket kustom,
Anda juga harus menentukan penggantian metrik. Misalnya, untuk menentukan nilai minimum bucket
30, 60, dan 90 menit, perintah gcloud dataproc clusters create
harus menyertakan flag berikut:
nilai minimum bucket:
‑‑properties=yarn:yarn.resourcemanager.metrics.runtime.buckets=30,60,90penggantian metrik:
‑‑metric-overrides=yarn:ResourceManager:QueueMetrics:running_0, yarn:ResourceManager:QueueMetrics:running_30,yarn:ResourceManager:QueueMetrics:running_60, yarn:ResourceManager:QueueMetrics:running_90
Contoh perintah pembuatan cluster
gcloud dataproc clusters create test-cluster \ --properties ^#^yarn:yarn.resourcemanager.metrics.runtime.buckets=30,60,90 \ --metric-sources=yarn \ --metric-overrides=yarn:ResourceManager:QueueMetrics:running_0,yarn:ResourceManager:QueueMetrics:running_30,yarn:ResourceManager:QueueMetrics:running_60,yarn:ResourceManager:QueueMetrics:running_90
Metrik ini tercantum di Google Cloud Metrics Explorer konsol di bagian resource VM Instance (gce_instance).
Penyiapan pemberitahuan aplikasi YARN
Buat cluster dengan bucket dan metrik yang diperlukan diaktifkan .
Buat kebijakan pemberitahuan yang dipicu saat jumlah aplikasi dalam bucket metrik YARN melebihi batas yang ditentukan.
Secara opsional, tambahkan filter untuk memberikan pemberitahuan pada cluster yang cocok dengan pola.
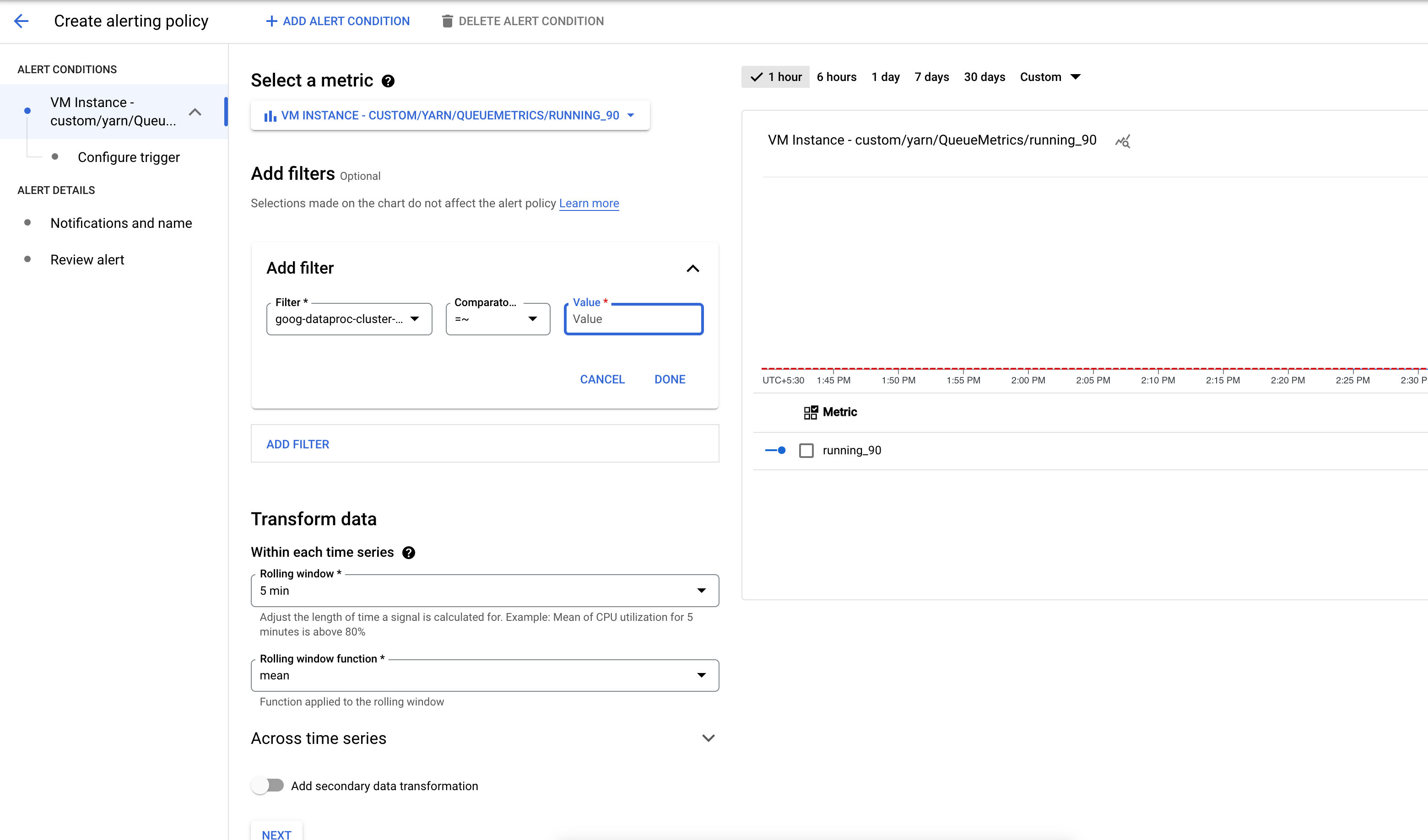
Konfigurasi nilai minimum untuk memicu pemberitahuan.
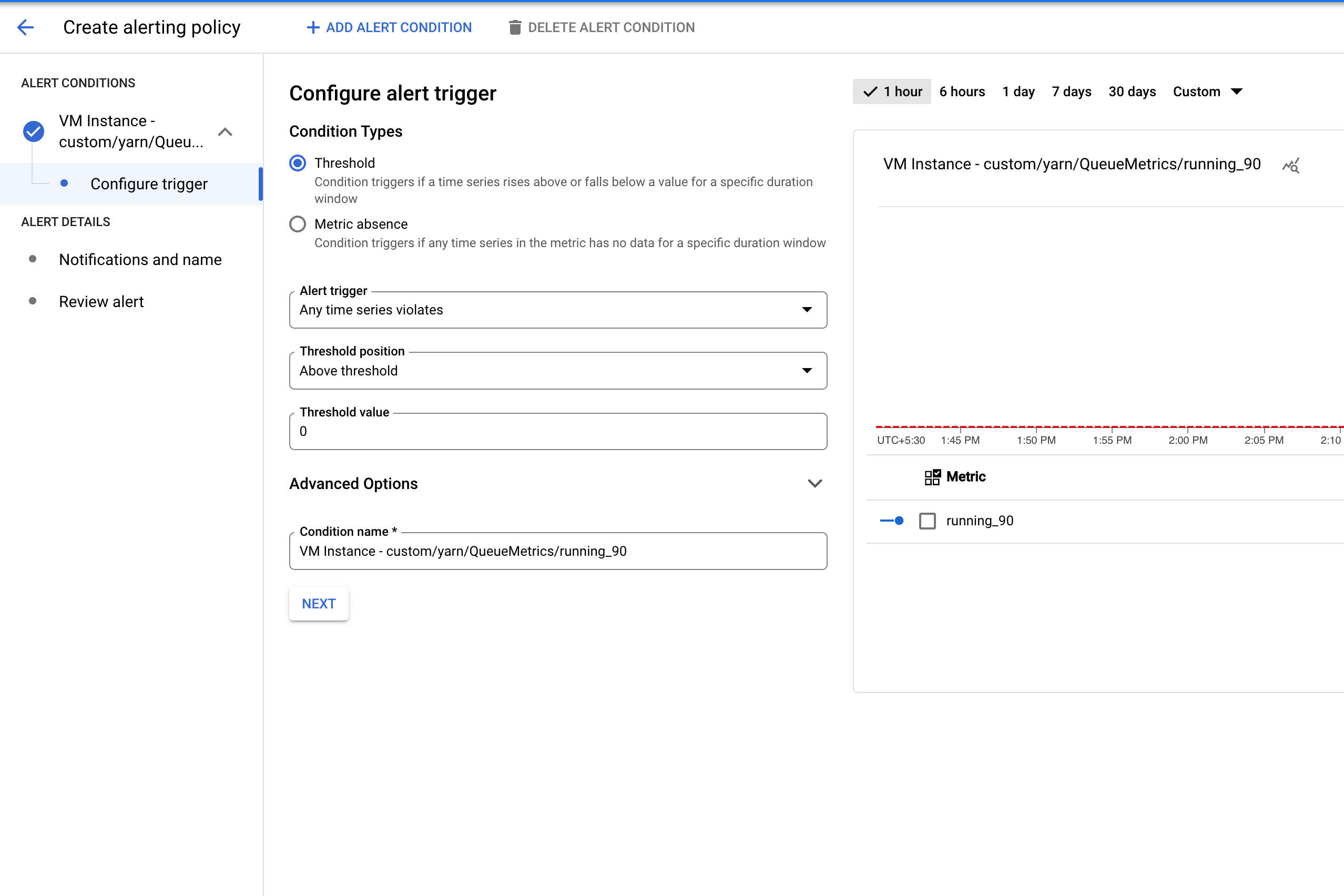
Pemberitahuan tugas Dataproc yang gagal
Anda juga dapat menggunakan metrik dataproc.googleapis.com/job/state
(lihat Pemberitahuan tugas Dataproc yang berjalan lama),
untuk memberi tahu Anda saat tugas Dataproc gagal.
Penyiapan info lowongan terbaru gagal
Contoh ini menggunakan Monitoring Query Language (MQL) untuk membuat kebijakan pemberitahuan (lihat Membuat kebijakan pemberitahuan MQL (konsol)).
MQL Pemberitahuan
fetch cloud_dataproc_job
| metric 'dataproc.googleapis.com/job/state'
| filter metric.state == 'ERROR'
| group_by [resource.job_id, metric.state], 1m
| condition val() == true()
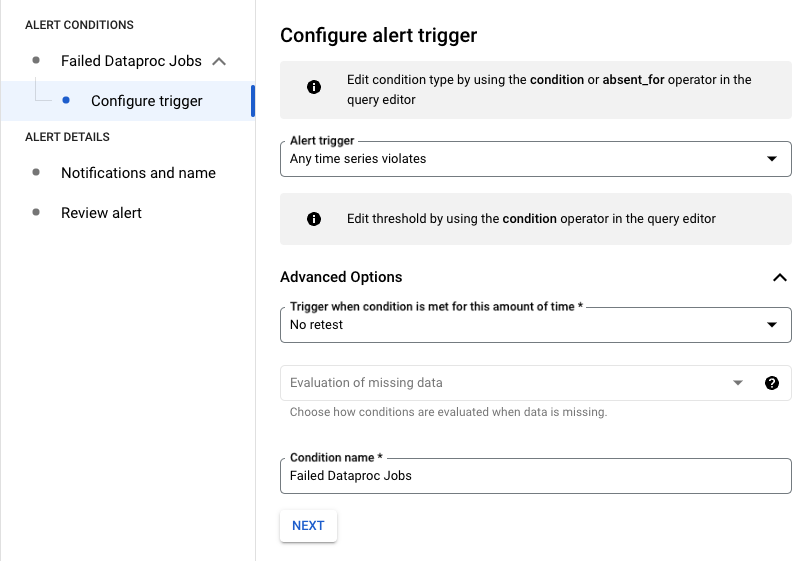
Konfigurasi pemicu pemberitahuan
Pada contoh berikut, pemberitahuan dipicu saat ada tugas Dataproc yang gagal di project Anda.
Anda dapat mengubah kueri dengan memfilter resource.job_id untuk menerapkannya
ke tugas tertentu:
fetch cloud_dataproc_job
| metric 'dataproc.googleapis.com/job/state'
| filter (resource.job_id == '1234567890') && (metric.state == 'ERROR')
| group_by [resource.job_id, metric.state], 1m
| condition val() == true()
Peringatan penyimpangan kapasitas cluster
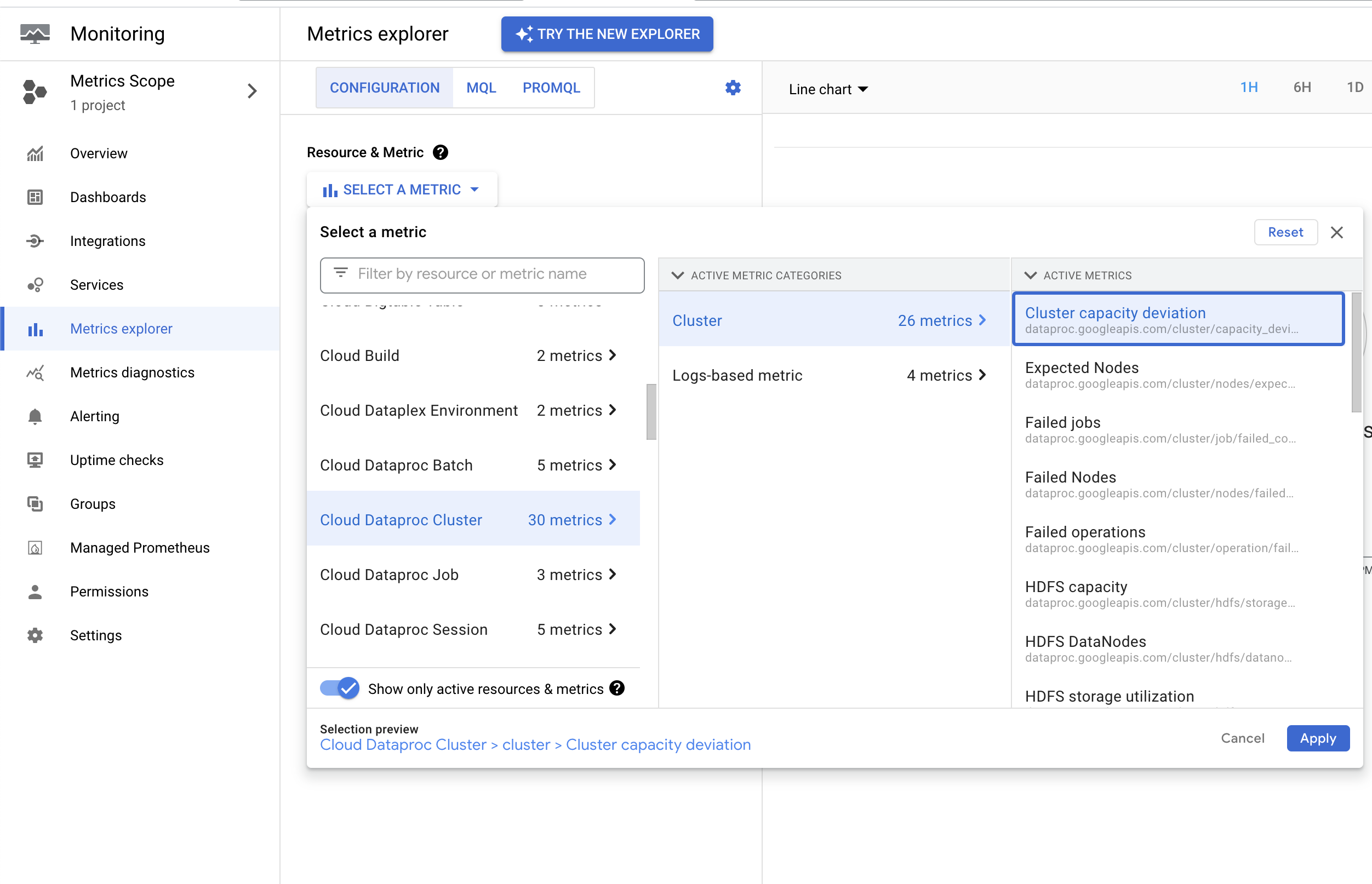
Dataproc memancarkan metrik dataproc.googleapis.com/cluster/capacity_deviation, yang melaporkan perbedaan antara jumlah node yang diharapkan dalam cluster dan jumlah node YARN aktif. Anda dapat menemukan metrik ini di
Google Cloud Metrics Explorer konsol di bagian resource
Cluster Cloud Dataproc. Anda dapat menggunakan metrik ini untuk membuat pemberitahuan yang memberi tahu Anda saat kapasitas cluster menyimpang dari kapasitas yang diharapkan selama durasi ambang batas yang ditentukan.
Operasi berikut dapat menyebabkan kurangnya pelaporan sementara node cluster dalam metrik capacity_deviation. Untuk menghindari pemberitahuan positif palsu, tetapkan nilai minimum pemberitahuan metrik untuk memperhitungkan operasi ini:
Pembuatan dan update cluster: Metrik
capacity_deviationtidak dipancarkan selama operasi pembuatan atau update cluster.Tindakan inisialisasi cluster: Tindakan inisialisasi dilakukan setelah node disediakan.
Pembaruan worker sekunder: Worker sekunder ditambahkan secara asinkron, setelah operasi pembaruan selesai.
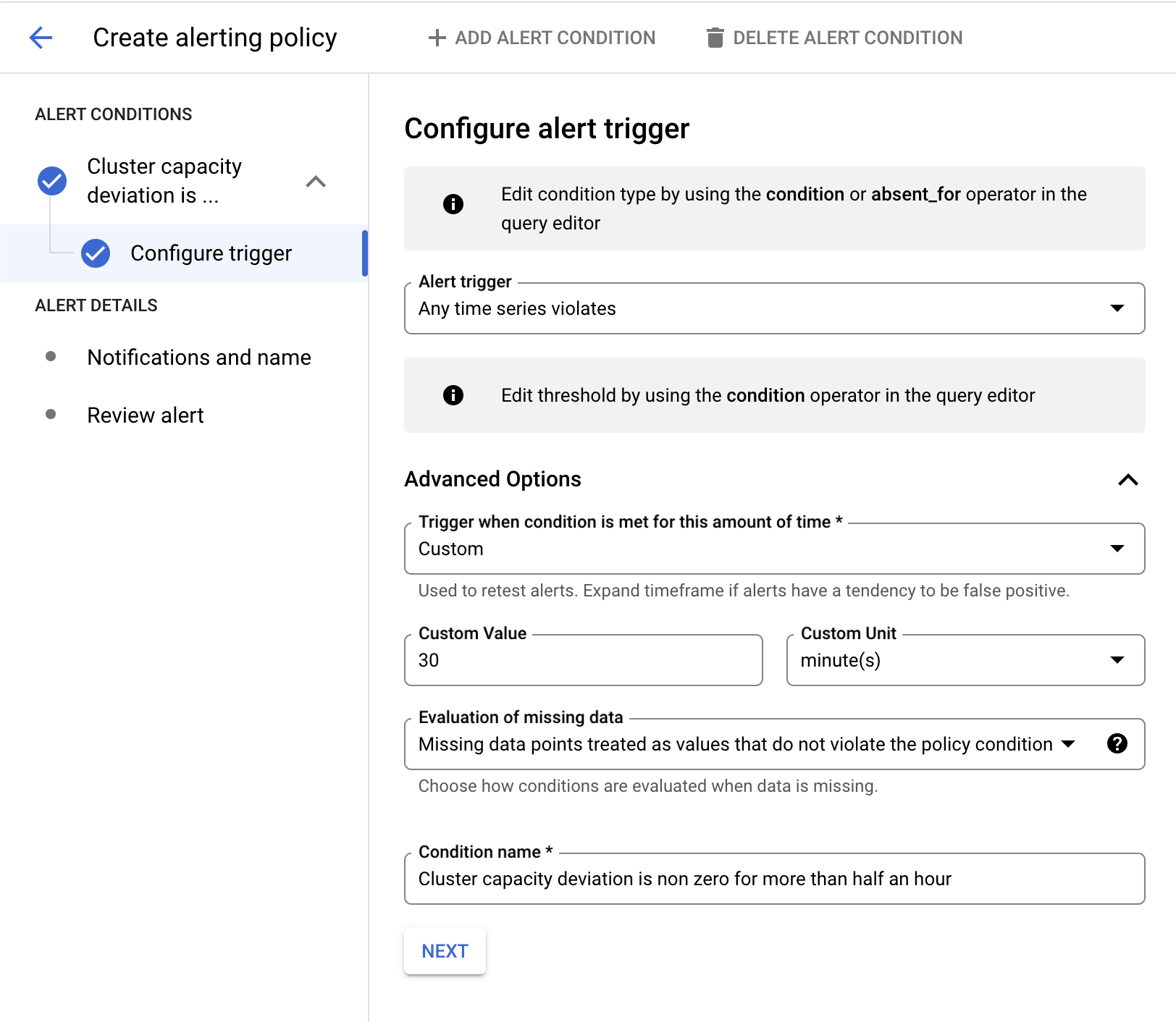
Penyiapan pemberitahuan penyimpangan kapasitas
Contoh ini menggunakan Monitoring Query Language (MQL) untuk membuat kebijakan pemberitahuan.
fetch cloud_dataproc_cluster
| metric 'dataproc.googleapis.com/cluster/capacity_deviation'
| every 1m
| condition val() <> 0 '1'
Pada contoh berikutnya, pemberitahuan dipicu saat penyimpangan kapasitas cluster tidak nol selama lebih dari 30 menit.
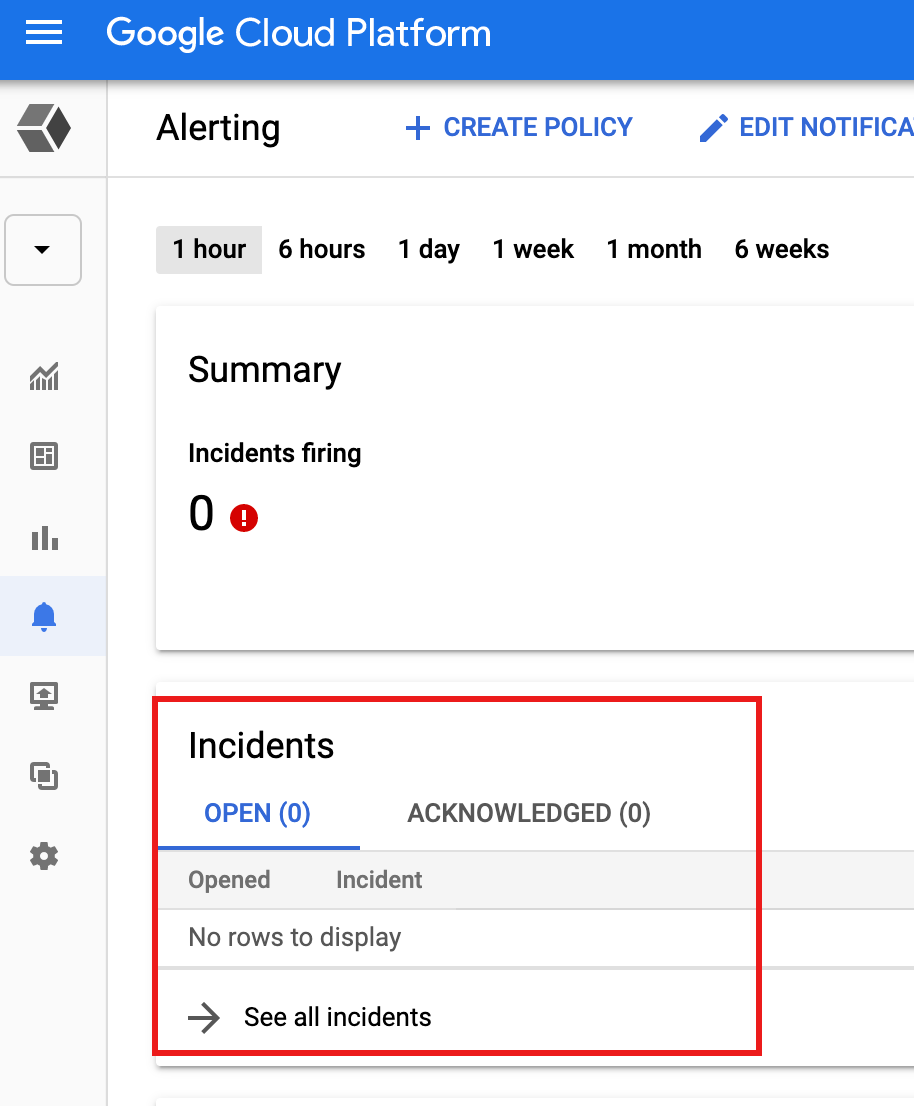
Lihat pemberitahuan
Saat pemberitahuan dipicu oleh kondisi nilai minimum metrik, Monitoring akan membuat insiden dan peristiwa yang sesuai. Anda dapat melihat insiden dari halaman Monitoring alerting di Google Cloud console.
Jika Anda menentukan mekanisme notifikasi dalam kebijakan pemberitahuan, seperti notifikasi email atau SMS, Monitoring akan mengirimkan notifikasi insiden.
Langkah berikutnya
- Lihat Pengantar pemberitahuan.