Questa pagina descrive le best practice da utilizzare durante lo sviluppo delle pipeline Dataflow. L'utilizzo di queste best practice offre i seguenti vantaggi:
- Migliora l'osservabilità e il rendimento della pipeline
- Maggiore produttività degli sviluppatori
- Migliorare la testabilità della pipeline
Gli esempi di codice Apache Beam in questa pagina utilizzano Java, ma i contenuti si applicano agli SDK Apache Beam Java, Python e Go.
Domande da considerare
Quando progetti la pipeline, considera le seguenti domande:
- Dove sono archiviati i dati di input della pipeline? Quanti set di dati di input hai?
- Che aspetto hanno i tuoi dati?
- Cosa vuoi fare con i tuoi dati?
- Dove devono essere inviati i dati di output della pipeline?
- Il tuo job Dataflow utilizza Assured Workloads?
Utilizzare i modelli
Per accelerare lo sviluppo della pipeline, anziché crearla scrivendo codice Apache Beam, utilizza un modello Dataflow, se possibile. I modelli offrono i seguenti vantaggi:
- I modelli sono riutilizzabili.
- I modelli ti consentono di personalizzare ogni job modificando parametri specifici della pipeline.
- Chiunque autorizzi può utilizzare il modello per eseguire il deployment della pipeline. Ad esempio, uno sviluppatore può creare un job da un modello e un data scientist dell'organizzazione può eseguire il deployment del modello in un secondo momento.
Puoi utilizzare un modello fornito da Google oppure crearne uno personalizzato. Alcuni modelli forniti da Google ti consentono di aggiungere una logica personalizzata come passaggio della pipeline. Ad esempio, il modello da Pub/Sub a BigQuery fornisce un parametro per eseguire una funzione JavaScript definita dall'utente (UDF) memorizzata in Cloud Storage.
Poiché i modelli forniti da Google sono open source ai sensi della licenza Apache 2.0, puoi utilizzarli come base per nuove pipeline. I modelli sono utili anche come esempi di codice. Visualizza il codice del modello nel repository GitHub.
Assured Workloads
Assured Workloads contribuisce a far rispettare i requisiti di sicurezza e conformità per i clienti di Google Cloud Platform. Ad esempio, Regioni UE e assistenza con controlli di sovranità contribuisce a garantire la residenza e la sovranità dei dati per i clienti con sede nell'UE. Per fornire queste funzionalità, alcune funzionalità di Dataflow sono limitate o soggette a restrizioni. Se utilizzi Assured Workloads con Dataflow, tutte le risorse a cui accede la pipeline devono trovarsi nel progetto o nella cartella Assured Workloads della tua organizzazione. Le risorse includono:
- Bucket Cloud Storage
- Set di dati di BigQuery
- Argomenti e sottoscrizioni Pub/Sub
- Set di dati Firestore
- Connettori I/O
In Dataflow, per i job di streaming creati dopo il 7 marzo 2024, tutti i dati utente vengono criptati con CMEK.
Per i job di streaming creati prima del 7 marzo 2024, le chiavi dei dati utilizzate nelle operazioni basate sulle chiavi, come la creazione di finestre, il raggruppamento e l'unione, non sono protette dalla crittografia CMEK. Per abilitare questa crittografia per i tuoi job, svuota o annulla il job e poi riavvialo. Per saperne di più, consulta Crittografia degli artefatti di stato della pipeline.
Condividere i dati tra le pipeline
Non esiste un meccanismo di comunicazione tra pipeline specifico di Dataflow per la condivisione di dati o del contesto di elaborazione tra le pipeline. Puoi utilizzare una memoria durevole come Cloud Storage o una cache in memoria come App Engine per condividere i dati tra le istanze della pipeline.
Pianifica job
Puoi automatizzare l'esecuzione della pipeline nei seguenti modi:
- Utilizza Cloud Scheduler.
- Utilizza l'operatore Dataflow di Apache Airflow, uno dei diversi operatori Google Cloud in un flusso di lavoro Cloud Composer.
- Esegui processi di job personalizzati (cron) su Compute Engine.
Best practice per la scrittura del codice della pipeline
Le sezioni seguenti forniscono le best practice da utilizzare quando crei pipeline scrivendo codice Apache Beam.
Strutturare il codice Apache Beam
Per creare pipeline, è comune utilizzare la trasformazione
ParDo
di elaborazione parallela Apache Beam generica.
Quando applichi una trasformazione ParDo, fornisci il codice sotto forma di oggetto DoFn. DoFn è una classe SDK Apache Beam che definisce una funzione di elaborazione distribuita.
Puoi considerare il codice DoFn come piccole entità indipendenti: possono
potenzialmente essere molte istanze in esecuzione su macchine diverse, ognuna delle quali non
conosce le altre. Pertanto, ti consigliamo di creare funzioni pure, che
sono ideali per la natura parallela e distribuita degli elementi DoFn.
Le funzioni pure hanno le seguenti caratteristiche:
- Le funzioni pure non dipendono da stati nascosti o esterni.
- Non hanno effetti collaterali osservabili.
- Sono deterministici.
Il modello di funzione pura non è strettamente rigido. Quando il codice non dipende da
elementi non garantiti dal servizio Dataflow, le informazioni
sullo stato o i dati di inizializzazione esterni possono essere validi per DoFn e altri
oggetti funzione.
Quando strutturi le trasformazioni ParDo e crei gli elementi DoFn,
considera le seguenti linee guida:
- Quando utilizzi l'elaborazione exactly-once,
il servizio Dataflow garantisce che ogni elemento dell'
PCollectiondi input venga elaborato da un'istanzaDoFnesattamente una volta. - Il servizio Dataflow non garantisce il numero di volte in cui viene richiamato un
DoFn. - Il servizio Dataflow non garantisce la modalità esatta di raggruppamento degli elementi distribuiti. Non garantisce quali elementi, se presenti, vengono elaborati insieme.
- Il servizio Dataflow non garantisce il numero esatto di istanze
DoFncreate nel corso di una pipeline. - Il servizio Dataflow è tollerante agli errori e potrebbe riprovare a eseguire il codice più volte se i worker riscontrano problemi.
- Il servizio Dataflow potrebbe creare copie di backup del tuo codice. Potrebbero verificarsi problemi con gli effetti collaterali manuali, ad esempio se il codice si basa su file temporanei con nomi non univoci o li crea.
- Il servizio Dataflow serializza l'elaborazione degli elementi per istanza
DoFn. Il tuo codice non deve essere rigorosamente thread-safe, ma qualsiasi stato condiviso tra più istanze diDoFndeve essere thread-safe.
Creare librerie di trasformazioni riutilizzabili
Il modello di programmazione Apache Beam consente di riutilizzare le trasformazioni. Creando una libreria condivisa di trasformazioni comuni, puoi migliorare la riutilizzabilità, la testabilità e la proprietà del codice da parte di team diversi.
Considera i due esempi di codice Java riportati di seguito, che leggono entrambi gli eventi di pagamento. Supponendo che entrambe le pipeline eseguano la stessa elaborazione, possono utilizzare le stesse trasformazioni tramite una libreria condivisa per i passaggi di elaborazione rimanenti.
Il primo esempio proviene da un'origine Pub/Sub senza limiti:
PipelineOptions options = PipelineOptionsFactory.create();
Pipeline p = Pipeline.create(options)
// Initial read transform
PCollection<PaymentEvent> payments =
p.apply("Read from topic",
PubSubIO.readStrings().withTimestampAttribute(...).fromTopic(...))
.apply("Parse strings into payment events",
ParDo.of(new ParsePaymentEventFn()));
Il secondo esempio proviene da un'origine di database relazionale delimitata:
PipelineOptions options = PipelineOptionsFactory.create();
Pipeline p = Pipeline.create(options);
PCollection<PaymentEvent> payments =
p.apply(
"Read from database table",
JdbcIO.<PaymentEvent>read()
.withDataSourceConfiguration(...)
.withQuery(...)
.withRowMapper(new RowMapper<PaymentEvent>() {
...
}));
Il modo in cui implementi le best practice per il riutilizzo del codice varia in base al linguaggio di programmazione e allo strumento di compilazione. Ad esempio, se utilizzi Maven, puoi separare il codice di trasformazione in un modulo separato. Puoi quindi includere il modulo come sottomodulo in progetti multimodulo più grandi per pipeline diverse, come mostrato nel seguente esempio di codice:
// Reuse transforms across both pipelines
payments
.apply("ValidatePayments", new PaymentTransforms.ValidatePayments(...))
.apply("ProcessPayments", new PaymentTransforms.ProcessPayments(...))
...
Per ulteriori informazioni, consulta le seguenti pagine della documentazione di Apache Beam:
- Requisiti per la scrittura del codice utente per le trasformazioni Apache Beam
- Guida di stile per
PTransform: una guida di stile per gli autori di nuove raccolte riutilizzabili diPTransform
Utilizzare le code dei messaggi non recapitabili per la gestione degli errori
A volte la pipeline non riesce a elaborare gli elementi. I problemi relativi ai dati sono una causa comune. Ad esempio, un elemento che contiene dati JSON formattati in modo errato può causare errori di analisi.
Anche se puoi rilevare le eccezioni all'interno del metodo
DoFn.ProcessElement, registrare l'errore ed eliminare l'elemento, questo approccio comporta la perdita dei dati
e impedisce di esaminarli in un secondo momento per la gestione manuale o la risoluzione dei problemi.
Utilizza invece un pattern chiamato coda di messaggi non recapitabili (coda di messaggi non elaborati).
Rileva le eccezioni nel metodo DoFn.ProcessElement e registra
gli errori. Anziché eliminare l'elemento non riuscito,
utilizza gli output di ramificazione per scrivere gli elementi non riusciti in un oggetto PCollection
separato. Questi elementi vengono quindi scritti in un data sink per essere ispezionati
e gestiti in un secondo momento con una trasformazione separata.
Il seguente esempio di codice Java mostra come implementare il pattern della coda di messaggi non recapitabili.
TupleTag<Output> successTag = new TupleTag<>() {};
TupleTag<Input> deadLetterTag = new TupleTag<>() {};
PCollection<Input> input = /* ... */;
PCollectionTuple outputTuple =
input.apply(ParDo.of(new DoFn<Input, Output>() {
@Override
void processElement(ProcessContext c) {
try {
c.output(process(c.element()));
} catch (Exception e) {
LOG.severe("Failed to process input {} -- adding to dead-letter file",
c.element(), e);
c.sideOutput(deadLetterTag, c.element());
}
}).withOutputTags(successTag, TupleTagList.of(deadLetterTag)));
// Write the dead-letter inputs to a BigQuery table for later analysis
outputTuple.get(deadLetterTag)
.apply(BigQueryIO.write(...));
// Retrieve the successful elements...
PCollection<Output> success = outputTuple.get(successTag);
// and continue processing ...
Utilizza Cloud Monitoring per applicare diverse politiche di monitoraggio e avviso per la coda di messaggi non recapitabili della pipeline. Ad esempio, puoi visualizzare il numero e le dimensioni degli elementi elaborati dalla trasformazione dead letter e configurare gli avvisi da attivare se vengono soddisfatte determinate condizioni di soglia.
Gestire le modifiche allo schema
Puoi gestire i dati con schemi imprevisti ma validi utilizzando un pattern
dead-letter, che scrive gli elementi non riusciti in un oggetto PCollection separato.
In alcuni casi, vuoi gestire automaticamente gli elementi
che riflettono uno schema modificato come elementi validi. Ad esempio, se lo schema di un elemento riflette una mutazione come l'aggiunta di nuovi campi, puoi adattare lo schema del sink dei dati per accogliere le mutazioni.
La mutazione automatica dello schema si basa sull'approccio di output ramificato utilizzato dal pattern di coda dei messaggi non recapitabili. Tuttavia, in questo caso viene attivata una trasformazione che modifica lo schema di destinazione ogni volta che vengono rilevati schemi additivi. Per un esempio di questo approccio, consulta Come gestire gli schemi JSON mutanti in una pipeline di streaming, con Square Enix sul Google Cloud blog.
Decidere come unire i set di dati
L'unione dei set di dati è un caso d'uso comune per le pipeline di dati. Puoi utilizzare
input laterali o la trasformazione CoGroupByKey per eseguire join nella pipeline.
Ognuno presenta vantaggi e svantaggi.
Gli input secondari
offrono un modo flessibile per risolvere problemi comuni di elaborazione dei dati, come l'arricchimento dei dati e le ricerche basate su chiavi. A differenza degli oggetti PCollection, gli input laterali sono
mutabili e possono essere determinati in fase di runtime. Ad esempio, i valori in un
input secondario potrebbero essere calcolati da un altro ramo della pipeline o determinati
chiamando un servizio remoto.
Dataflow supporta gli input secondari rendendo persistenti i dati nell'archiviazione permanente, in modo simile a un disco condiviso. Questa configurazione rende disponibile l'input laterale completo a tutti i worker.
Tuttavia, le dimensioni degli input secondari possono essere molto grandi e potrebbero non rientrare nella memoria del worker. La lettura da un input secondario di grandi dimensioni può causare problemi di prestazioni se i worker devono leggere costantemente dallo spazio di archiviazione permanente.
La trasformazione CoGroupByKey è una
trasformazione Apache Beam di base
che unisce (appiattisce) più oggetti PCollection e raggruppa gli elementi che
hanno una chiave comune. A differenza di un input secondario, che rende disponibili tutti i dati dell'input secondario
a ogni worker, CoGroupByKey esegue un'operazione di rimescolamento (raggruppamento)
per distribuire i dati tra i worker. CoGroupByKey è quindi ideale quando gli oggetti PCollection che vuoi unire sono molto grandi e non rientrano nella memoria del worker.
Segui queste linee guida per decidere se utilizzare gli input laterali o
CoGroupByKey:
- Utilizza gli input secondari quando uno degli oggetti
PCollectionche stai unendo è sproporzionatamente più piccolo degli altri e l'oggettoPCollectionpiù piccolo rientra nella memoria del worker. Il caching dell'input secondario interamente in memoria rende il recupero degli elementi rapido ed efficiente. - Utilizza gli input aggiuntivi quando hai un oggetto
PCollectionche deve essere unito più volte nella pipeline. Anziché utilizzare più trasformazioniCoGroupByKey, crea un singolo input laterale che possa essere riutilizzato da più trasformazioniParDo. - Utilizza
CoGroupByKeyse devi recuperare una parte significativa di un oggettoPCollectionche supera notevolmente la memoria del worker.
Per saperne di più, vedi Risolvere gli errori di esaurimento della memoria di Dataflow.
Ridurre al minimo le operazioni costose per elemento
Un'istanza DoFn elabora batch di elementi chiamati
bundle,
che sono unità di lavoro atomiche composte da zero o più
elementi. I singoli elementi vengono poi elaborati dal metodo
DoFn.ProcessElement, che viene eseguito per ogni elemento. Poiché il metodo DoFn.ProcessElement
viene chiamato per ogni elemento, qualsiasi operazione dispendiosa in termini di tempo o di calcolo
richiamata da questo metodo
viene eseguita per ogni singolo elemento elaborato dal metodo.
Se devi eseguire operazioni costose una sola volta per un batch di elementi,
includi queste operazioni nel metodo DoFn.Setup o nel metodo DoFn.StartBundle
anziché nell'elemento DoFn.ProcessElement. Alcuni esempi includono le seguenti operazioni:
Analisi di un file di configurazione che controlla alcuni aspetti del comportamento dell'istanza
DoFn. Richiama questa azione una sola volta, quando l'istanza diDoFnviene inizializzata, utilizzando il metodoDoFn.Setup.Creazione di un client di breve durata riutilizzato in tutti gli elementi di un bundle, ad esempio quando tutti gli elementi del bundle vengono inviati tramite una singola connessione di rete. Richiama questa azione una volta per bundle utilizzando il metodo
DoFn.StartBundle.
Limitare le dimensioni dei batch e le chiamate simultanee ai servizi esterni
Quando chiami servizi esterni, puoi ridurre i sovraccarichi per chiamata utilizzando la
trasformazione GroupIntoBatches. Questa trasformazione crea batch di elementi di una dimensione specificata.
Il batching invia gli elementi a un servizio esterno come un unico payload anziché
singolarmente.
In combinazione con il batching, limita il numero massimo di chiamate parallele (simultanee) al servizio esterno scegliendo chiavi appropriate per partizionare i dati in entrata. Il numero di partizioni determina il parallelismo massimo. Ad esempio, se a ogni elemento viene assegnata la stessa chiave, una trasformazione downstream per chiamare il servizio esterno non viene eseguita in parallelo.
Prendi in considerazione uno dei seguenti approcci per generare le chiavi per gli elementi:
- Scegli un attributo del set di dati da utilizzare come chiavi dei dati, ad esempio gli ID utente.
- Genera chiavi dei dati per dividere gli elementi in modo casuale in un numero fisso di partizioni, dove il numero di valori chiave possibili determina il numero di partizioni. Devi creare un numero sufficiente di partizioni per il parallelismo.
Ogni partizione deve contenere un numero sufficiente di elementi per rendere utile la trasformazione
GroupIntoBatches.
Il seguente esempio di codice Java mostra come dividere in modo casuale gli elementi in dieci partizioni:
// PII or classified data which needs redaction.
PCollection<String> sensitiveData = ...;
int numPartitions = 10; // Number of parallel batches to create.
PCollection<KV<Long, Iterable<String>>> batchedData =
sensitiveData
.apply("Assign data into partitions",
ParDo.of(new DoFn<String, KV<Long, String>>() {
Random random = new Random();
@ProcessElement
public void assignRandomPartition(ProcessContext context) {
context.output(
KV.of(randomPartitionNumber(), context.element()));
}
private static int randomPartitionNumber() {
return random.nextInt(numPartitions);
}
}))
.apply("Create batches of sensitive data",
GroupIntoBatches.<Long, String>ofSize(100L));
// Use batched sensitive data to fully utilize Redaction API,
// which has a rate limit but allows large payloads.
batchedData
.apply("Call Redaction API in batches", callRedactionApiOnBatch());
Identificare i problemi di rendimento causati dai passaggi uniti
Dataflow crea un grafico di passaggi che rappresenta la pipeline in base alle trasformazioni e ai dati che hai utilizzato per costruirla. Questo grafico è chiamato grafico di esecuzione della pipeline.
Quando esegui il deployment della pipeline, Dataflow potrebbe modificare
il grafico di esecuzione della pipeline per migliorare le prestazioni. Ad esempio, Dataflow
potrebbe unire alcune operazioni, un processo noto come
ottimizzazione della fusione,
per evitare l'impatto su prestazioni e costi della scrittura di ogni oggetto
PCollection intermedio nella pipeline.
In alcuni casi, Dataflow potrebbe determinare in modo errato il modo ottimale per unire le operazioni nella pipeline, il che può limitare la capacità del job di utilizzare tutti i worker disponibili. In questi casi, puoi impedire la fusione delle operazioni.
Considera il seguente esempio di codice Apache Beam. Una trasformazione
GenerateSequence
crea un piccolo oggetto PCollection delimitato, che viene poi ulteriormente
elaborato da due trasformazioni ParDo downstream.
La trasformazione Find Primes Less-than-N potrebbe essere costosa dal punto di vista computazionale e
probabilmente verrà eseguita lentamente per numeri elevati. Al contrario, la
trasformazione Increment Number viene completata rapidamente.
import com.google.common.math.LongMath;
...
public class FusedStepsPipeline {
final class FindLowerPrimesFn extends DoFn<Long, String> {
@ProcessElement
public void processElement(ProcessContext c) {
Long n = c.element();
if (n > 1) {
for (long i = 2; i < n; i++) {
if (LongMath.isPrime(i)) {
c.output(Long.toString(i));
}
}
}
}
}
public static void main(String[] args) {
Pipeline p = Pipeline.create(options);
PCollection<Long> sequence = p.apply("Generate Sequence",
GenerateSequence
.from(0)
.to(1000000));
// Pipeline branch 1
sequence.apply("Find Primes Less-than-N",
ParDo.of(new FindLowerPrimesFn()));
// Pipeline branch 2
sequence.apply("Increment Number",
MapElements.via(new SimpleFunction<Long, Long>() {
public Long apply(Long n) {
return ++n;
}
}));
p.run().waitUntilFinish();
}
}
Il seguente diagramma mostra una rappresentazione grafica della pipeline nell'interfaccia di monitoraggio di Dataflow.
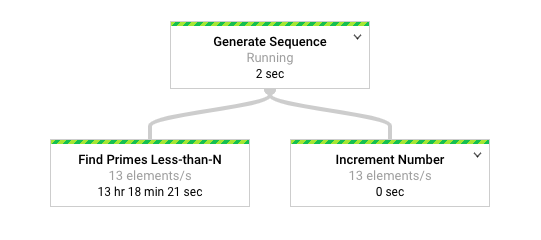
L'interfaccia di monitoraggio di Dataflow mostra che la stessa velocità di elaborazione lenta si verifica per entrambe le trasformazioni, in particolare 13 elementi al secondo. Potresti aspettarti che la trasformazione Increment Number elabori
gli elementi rapidamente, ma sembra invece essere legata alla stessa velocità di
elaborazione di Find Primes Less-than-N.
Il motivo è che Dataflow ha unito i passaggi in un'unica
fase, impedendone l'esecuzione indipendente. Puoi utilizzare il
comando gcloud dataflow jobs describe
per trovare ulteriori informazioni:
gcloud dataflow jobs describe --full job-id --format json
Nell'output risultante, i passaggi uniti sono descritti nell'oggetto
ExecutionStageSummary
nell'array
ComponentTransform:
...
"executionPipelineStage": [
{
"componentSource": [
...
],
"componentTransform": [
{
"name": "s1",
"originalTransform": "Generate Sequence/Read(BoundedCountingSource)",
"userName": "Generate Sequence/Read(BoundedCountingSource)"
},
{
"name": "s2",
"originalTransform": "Find Primes Less-than-N",
"userName": "Find Primes Less-than-N"
},
{
"name": "s3",
"originalTransform": "Increment Number/Map",
"userName": "Increment Number/Map"
}
],
"id": "S01",
"kind": "PAR_DO_KIND",
"name": "F0"
}
...
In questo scenario, poiché la trasformazione Find Primes Less-than-N è il passaggio lento,
interrompere la fusione prima di questo passaggio è una strategia appropriata. Un metodo per
separare i passaggi consiste nell'inserire una
trasformazione GroupByKey e raggruppare prima del passaggio, come mostrato nel seguente esempio di codice Java.
sequence
.apply("Map Elements", MapElements.via(new SimpleFunction<Long, KV<Long, Void>>() {
public KV<Long, Void> apply(Long n) {
return KV.of(n, null);
}
}))
.apply("Group By Key", GroupByKey.<Long, Void>create())
.apply("Emit Keys", Keys.<Long>create())
.apply("Find Primes Less-than-N", ParDo.of(new FindLowerPrimesFn()));
Puoi anche combinare questi passaggi di separazione in una trasformazione composita riutilizzabile.
Dopo aver separato i passaggi, quando esegui la pipeline, Increment Number
viene completato in pochi secondi e la trasformazione Find Primes Less-than-N, che richiede molto più tempo,
viene eseguita in una fase separata.
Questo esempio applica un'operazione di raggruppamento e separazione ai passaggi di fusione.
Puoi utilizzare altri approcci per altre circostanze. In questo caso, la gestione
dell'output duplicato non è un problema, dato l'output consecutivo della
trasformazione GenerateSequence.
Gli oggetti KV con chiavi duplicate vengono deduplicati in una singola chiave nella trasformazione del gruppo (GroupByKey) e nella trasformazione di separazione (Keys). Per conservare i duplicati dopo le operazioni di raggruppamento e separazione,
crea coppie chiave-valore seguendo questi passaggi:
- Utilizza una chiave casuale e l'input originale come valore.
- Raggruppa utilizzando la chiave casuale.
- Emetti i valori per ogni chiave come output.
Puoi anche utilizzare una
trasformazione
Reshuffle
per impedire la fusione delle trasformazioni circostanti. Tuttavia, gli effetti collaterali della
trasformazione Reshuffle non sono trasferibili tra diversi
runner Apache Beam.
Per ulteriori informazioni sull'ottimizzazione del parallelismo e della fusione, consulta Ciclo di vita della pipeline.
Utilizzare le metriche Apache Beam per raccogliere informazioni sulla pipeline
Le metriche Apache Beam sono una classe di utilità che produce metriche per la generazione di report sulle proprietà di una pipeline in esecuzione. Quando utilizzi Cloud Monitoring, le metriche di Apache Beam sono disponibili come metriche personalizzate di Cloud Monitoring.
L'esempio seguente mostra le metriche Counter di Apache Beam utilizzate in una sottoclasse DoFn.
Il codice di esempio utilizza due contatori. Un contatore tiene traccia degli errori di analisi JSON (malformedCounter), mentre l'altro contatore tiene traccia del fatto che il messaggio JSON sia valido, ma contenga un payload vuoto (emptyCounter). In Cloud Monitoring, i nomi metrica personalizzata sono custom.googleapis.com/dataflow/malformedJson e custom.googleapis.com/dataflow/emptyPayload. Puoi utilizzare le metriche personalizzate
per creare visualizzazioni e criteri di avviso in Cloud Monitoring.
final TupleTag<String> errorTag = new TupleTag<String>(){};
final TupleTag<MockObject> successTag = new TupleTag<MockObject>(){};
final class ParseEventFn extends DoFn<String, MyObject> {
private final Counter malformedCounter = Metrics.counter(ParseEventFn.class, "malformedJson");
private final Counter emptyCounter = Metrics.counter(ParseEventFn.class, "emptyPayload");
private Gson gsonParser;
@Setup
public setup() {
gsonParser = new Gson();
}
@ProcessElement
public void processElement(ProcessContext c) {
try {
MyObject myObj = gsonParser.fromJson(c.element(), MyObject.class);
if (myObj.getPayload() != null) {
// Output the element if non-empty payload
c.output(successTag, myObj);
}
else {
// Increment empty payload counter
emptyCounter.inc();
}
}
catch (JsonParseException e) {
// Increment malformed JSON counter
malformedCounter.inc();
// Output the element to dead-letter queue
c.output(errorTag, c.element());
}
}
}
Scopri di più
Le pagine seguenti forniscono ulteriori informazioni su come strutturare la pipeline, su quali trasformazioni applicare ai dati e su cosa considerare quando si scelgono i metodi di input e output della pipeline.
Per ulteriori informazioni sulla creazione del codice utente, consulta i requisiti per le funzioni fornite dall'utente.