Il generatore di job è una UI visiva per creare ed eseguire pipeline Dataflow nella console Google Cloud , senza scrivere codice.
L'immagine seguente mostra un dettaglio della UI del generatore di job. In questa immagine, l'utente sta creando una pipeline per leggere da Pub/Sub a BigQuery:
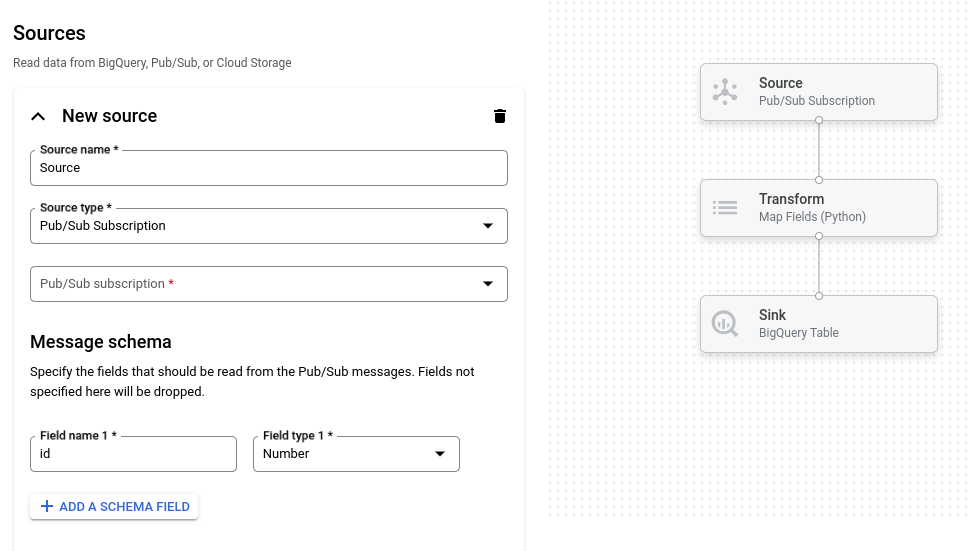
Panoramica
Lo strumento per la creazione dei job supporta la lettura e la scrittura dei seguenti tipi di dati:
- Messaggi Pub/Sub
- Dati della tabella BigQuery
- File CSV, file JSON e file di testo in Cloud Storage
- Dati delle tabelle PostgreSQL, MySQL, Oracle e SQL Server
Supporta le trasformazioni della pipeline, tra cui filtro, mappa, SQL, raggruppamento, unione ed espansione (appiattimento dell'array).
Con il builder dedicato puoi:
- Trasmetti flussi da Pub/Sub a BigQuery con trasformazioni e aggregazione in finestre
- Scrivere dati da Cloud Storage a BigQuery
- Utilizzare la gestione degli errori per filtrare i dati errati (coda dei messaggi non recapitabili)
- Manipolare o aggregare i dati utilizzando SQL con la trasformazione SQL
- Aggiungere, modificare o eliminare campi dai dati con le trasformazioni di mappatura
- Pianificare job batch ricorrenti
Il builder dei job può anche salvare le pipeline come file Apache Beam YAML e caricare le definizioni delle pipeline dai file Beam YAML. Utilizzando questa funzionalità, puoi progettare la pipeline nel builder di job e poi archiviare il file YAML in Cloud Storage o in un repository di controllo del codice sorgente per riutilizzarlo. Le definizioni dei job YAML possono essere utilizzate anche per avviare i job utilizzando gcloud CLI.
Prendi in considerazione lo strumento di creazione dei job per i seguenti casi d'uso:
- Vuoi creare una pipeline rapidamente senza scrivere codice.
- Vuoi salvare una pipeline in YAML per riutilizzarla.
- La pipeline può essere espressa utilizzando le origini, i sink e le trasformazioni supportati.
- Non esiste un modello fornito da Google che corrisponda al tuo caso d'uso.
Esegui un job di esempio
L'esempio di conteggio delle parole è una pipeline batch che legge il testo da Cloud Storage, tokenizza le righe di testo in parole singole ed esegue un conteggio della frequenza per ciascuna parola.
Se il bucket Cloud Storage si trova al di fuori del perimetro di servizio, crea una regola di uscita che consenta l'accesso al bucket.
Per eseguire la pipeline Conteggio parole:
Vai alla pagina Job nella console Google Cloud .
Fai clic su Crea job da modello.
Nel riquadro laterale, fai clic su Generatore di job.
Fai clic su Carica progetti.
Fai clic su Conteggio parole. Il builder dedicato viene compilato con una rappresentazione grafica della pipeline.
Per ogni passaggio della pipeline, il generatore di job mostra una scheda che specifica i parametri di configurazione per quel passaggio. Ad esempio, il primo passaggio legge i file di testo da Cloud Storage. La posizione dei dati di origine è precompilata nella casella Posizione testo.
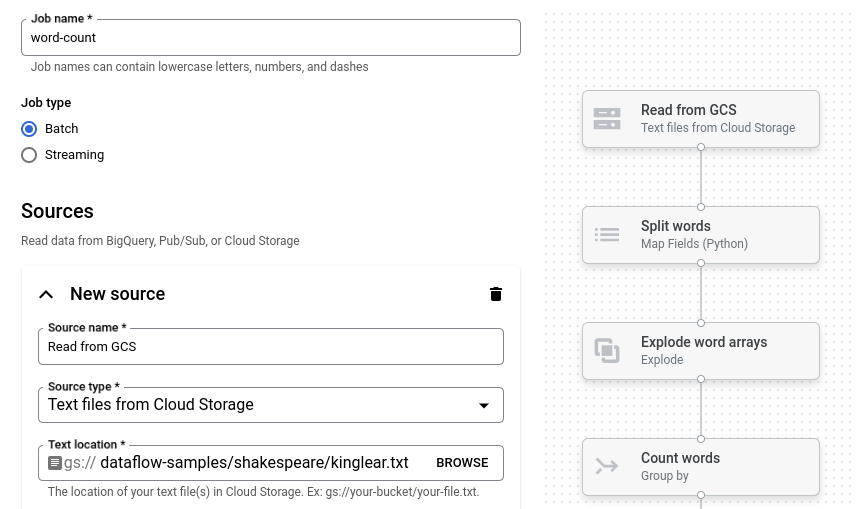
Individua la scheda intitolata Nuovo lavello. Potrebbe essere necessario scorrere.
Nella casella Posizione del testo, inserisci il prefisso del percorso della posizione di Cloud Storage per i file di testo di output.
Fai clic su Esegui job. Il generatore di job crea un job Dataflow e poi passa al grafico del job. Quando il job inizia, il grafico del job mostra una rappresentazione grafica della pipeline. Questa rappresentazione del grafico è simile a quella mostrata nel generatore di job. Man mano che ogni passaggio della pipeline viene eseguito, lo stato viene aggiornato nel grafico dei job.
Il riquadro Informazioni job mostra lo stato generale del job. Se il job viene completato
correttamente, il campo Stato job viene aggiornato a Succeeded.
Passaggi successivi
- Utilizza l'interfaccia di monitoraggio dei job Dataflow.
- Crea un job personalizzato nel builder dedicato.
- Salva e carica le definizioni dei job YAML nel builder dei job.
- Scopri di più su Beam YAML.