本指南說明如何部署、設定及執行使用 SAP OData 外掛程式的資料管道。
您可以使用 SAP 做為來源,透過 開放資料通訊協定 (OData) 在 Cloud Data Fusion 中進行批次式資料擷取作業。SAP OData 外掛程式可協助您設定及執行 SAP OData 目錄服務的資料移轉作業,完全不需要編寫程式碼。
如要進一步瞭解支援的 SAP OData 目錄服務和資料來源,請參閱支援詳細資料。如要進一步瞭解Google Cloud上的 SAP,請參閱 Google Cloud上的 SAP 簡介。
目標
- 設定 SAP ERP 系統 (在 SAP 中啟用資料來源)。
- 在 Cloud Data Fusion 環境中部署外掛程式。
- 從 Cloud Data Fusion 下載 SAP 轉移作業,並在 SAP 中安裝。
- 使用 Cloud Data Fusion 和 SAP OData 建立資料管道,以整合 SAP 資料。
事前準備
如要使用這個外掛程式,您必須具備下列領域的專業知識:
- 在 Cloud Data Fusion 中建構管道
- 使用 IAM 管理存取權
- 設定 SAP Cloud 和內部部署的企業資源規劃 (ERP) 系統
使用者角色
本頁面的工作由 Google Cloud 或 SAP 系統中具有下列角色的使用者執行:
| 使用者類型 | 說明 |
|---|---|
| Google Cloud 管理員 | 獲派此角色的使用者是 Google Cloud 帳戶的管理員。 |
| Cloud Data Fusion 使用者 | 獲派此角色的使用者有權設計及執行資料管道。他們至少會獲得 Data Fusion 檢視者 (
roles/datafusion.viewer) 角色。如果您使用角色式存取權控管,可能需要其他角色。 |
| SAP 管理員 | 獲派此角色的使用者是 SAP 系統的管理員。他們可以從 SAP 服務網站下載軟體。並非 IAM 角色。 |
| SAP 使用者 | 指派此角色的使用者可連線至 SAP 系統。這不是 IAM 角色。 |
OData 擷取作業的必要條件
OData 目錄服務必須在 SAP 系統中啟用。
必須在 OData 服務中填入資料。
SAP 系統的必要條件
在 SAP NetWeaver 7.02 到 SAP NetWeaver 7.31 版本中,OData 和 SAP Gateway 功能會透過下列 SAP 軟體元件提供:
IW_FNDGW_COREIW_BEP
在 SAP NetWeaver 7.40 以上版本中,所有功能都會在元件
SAP_GWFND中提供,且該元件必須在 SAP NetWeaver 中提供。
選用:安裝 SAP 傳輸檔案
為 SAP 負載平衡呼叫所需的 SAP 元件會以 SAP 傳輸檔案的形式提供,並以 zip 檔案形式封存 (一個傳輸要求,包含一個 cofile 和一個資料檔案)。您可以使用這個步驟,根據 SAP 中可用的作業程序,限制對 SAP 的多個並行呼叫。
在 Cloud Data Fusion Hub 中部署外掛程式後,您就可以下載 ZIP 檔案。
將傳輸檔案匯入 SAP 時,系統會建立下列 SAP OData 專案:
OData 專案
/GOOG/GET_STATISTIC/GOOG/TH_WPINFO
ICF 服務節點:
GOOG
如要安裝 SAP 傳輸工具,請按照下列步驟操作:
步驟 1:上傳運算要求檔案
- 登入 SAP 執行個體的作業系統。
- 使用 SAP 交易代碼
AL11取得DIR_TRANS資料夾的路徑。通常路徑為/usr/sap/trans/。 - 將 cofiles 複製到
DIR_TRANS/cofiles資料夾。 - 將資料檔案複製到
DIR_TRANS/data資料夾。 - 將資料和共用檔案的使用者和群組設為
<sid>adm和sapsys。
步驟 2:匯入傳輸要求檔案
SAP 管理員可以使用下列任一選項匯入傳輸要求檔案:
方法 1:使用 SAP 傳輸管理系統匯入傳輸要求檔案
- 以 SAP 管理員身分登入 SAP 系統。
- 輸入交易 STMS。
- 依序點選「總覽」>「匯入」。
- 在「佇列」欄中,按兩下目前的 SID。
- 依序點選「額外」>「其他要求」>「新增」。
- 選取運送要求 ID,然後按一下「繼續」。
- 在匯入佇列中選取運送要求,然後依序點選「要求」>「匯入」。
- 輸入客戶編號。
在「Options」分頁中,選取「Overwrite originals」和「Ignore invalid component version」 (如果有的話)。
(選用) 如要將傳輸重新匯入作業排定在日後執行,請選取「將傳輸要求留在佇列中,以便日後匯入」和「再次匯入傳輸要求」。這對於 SAP 系統升級和備份還原作業非常實用。
按一下「繼續」。
如要驗證匯入作業,請使用任何交易,例如
SE80和SU01。
方法 2:在作業系統層級匯入傳輸要求檔案
- 以 SAP 系統管理員身分登入 SAP 系統。
執行下列指令,將適當要求新增至匯入緩衝區:
tp addtobuffer TRANSPORT_REQUEST_ID SID例如:
tp addtobuffer IB1K903958 DD1請執行下列指令,匯入運輸要求:
tp import TRANSPORT_REQUEST_ID SID client=NNN U1238將
NNN替換為客戶編號。例如:tp import IB1K903958 DD1 client=800 U1238使用任何適當的交易 (例如
SE80和SU01),確認函式模組和授權角色是否已成功匯入。
取得 SAP 目錄服務的篩選欄清單
只有部分資料來源欄可用於篩選條件 (這是 SAP 的設計限制)。
如要取得 SAP 目錄服務的篩選欄清單,請按照下列步驟操作:
- 登入 SAP 系統。
- 前往 t-code
SEGW。 輸入 OData 專案名稱,也就是服務名稱的子字串。例如:
- 服務名稱:
MM_PUR_POITEMS_MONI_SRV - 專案名稱:
MM_PUR_POITEMS_MONI
- 服務名稱:
按一下 Enter 鍵。
前往要篩選的實體,然後選取「屬性」。
您可以使用「屬性」中顯示的欄位做為篩選器。支援的運算包括「相等」和「介於」 (範圍)。

如需運算子語言支援的運算子清單,請參閱 OData 開放原始碼說明文件:URI 慣例 (OData 2.0 版)。
含有篩選條件的 URI 範例:
/sap/opu/odata/sap/MM_PUR_POITEMS_MONI_SRV/C_PurchaseOrderItemMoni(P_DisplayCurrency='USD')/Results/?$filter=(PurchaseOrder eq '4500000000')
設定 SAP ERP 系統
SAP OData 外掛程式會使用 OData 服務,並在擷取資料的每個 SAP 伺服器上啟用這項服務。這項 OData 服務可以是 SAP 提供的標準,或是在 SAP 系統上開發的自訂 OData 服務。
步驟 1:安裝 SAP Gateway 2.0
SAP (Basis) 管理員必須確認 SAP Gateway 2.0 元件是否可在 SAP 來源系統中使用,這取決於 NetWeaver 版本。如要進一步瞭解如何安裝 SAP Gateway 2.0,請登入 SAP ONE Support Launchpad,並參閱 Note 1569624 (需要登入)。
步驟 2:啟用 OData 服務
在來源系統上啟用必要的 OData 服務。詳情請參閱「前端伺服器:啟用 OData 服務」。
步驟 3:建立授權角色
如要連線至 DataSource,請在 SAP 中建立具有必要授權的授權角色,然後將該角色授予 SAP 使用者。
如要在 SAP 中建立授權角色,請按照下列步驟操作:
- 在 SAP GUI 中輸入交易代碼 PFCG,開啟角色維護視窗。
在「角色」欄位中輸入角色名稱。
例如:
ZODATA_AUTH按一下「單一角色」。
「Create Roles」視窗隨即開啟。
在「Description」欄位輸入說明,然後按一下「Save」。
例如
Authorizations for SAP OData plugin。按一下「授權」分頁標籤。視窗標題會變更為「變更角色」。
在「編輯授權資料並產生設定檔」下方,點選 「變更授權資料」。
系統隨即會開啟「選擇範本」視窗。
按一下「不要選取範本」。
「變更角色:授權」視窗隨即開啟。
按一下「手動輸入」。
請提供下列 SAP 授權表格中的授權。
按一下 [儲存]。
如要啟用授權角色,請按一下「產生」圖示。
SAP 授權
| 物件類別 | 物件類別文字 | 授權物件 | 授權物件文字 | 授權 | 文字 | 值 |
|---|---|---|---|---|---|---|
| AAAB | 跨應用程式授權物件 | S_SERVICE | 在外部服務開始時檢查 | SRV_NAME | 程式、交易或函式模組名稱 | * |
| AAAB | 跨應用程式授權物件 | S_SERVICE | 在外部服務開始時檢查 | SRV_TYPE | 檢查標記類型和授權預設值 | HT |
| FI | 財務會計 | F_UNI_HIER | 通用階層存取權 | ACTVT | 活動 | 03 |
| FI | 財務會計 | F_UNI_HIER | 通用階層存取權 | HRYTYPE | 階層類型 | * |
| FI | 財務會計 | F_UNI_HIER | 通用階層存取權 | HRYID | 階層 ID | * |
如要以 Cloud Data Fusion 使用者身分在 Cloud Data Fusion 中設計及執行資料管道,您需要 SAP 使用者憑證 (使用者名稱和密碼),才能設定外掛程式連線至 DataSource。
SAP 使用者必須是 Communications 或 Dialog 類型。為避免使用 SAP 對話方塊資源,建議您使用 Communications 類型。您可以使用 SAP 交易代碼 SU01 建立使用者。
選用步驟:4. 保護連線
您可以透過網路,在私人 Cloud Data Fusion 執行個體和 SAP 之間進行安全通訊。
如要確保連線安全,請按照下列步驟操作:
- SAP 管理員必須產生 X509 憑證。如要產生憑證,請參閱「建立 SSL 伺服器 PSE」一文。
- Google Cloud 管理員必須將 X509 檔案複製到與 Cloud Data Fusion 執行個體相同專案的可讀取 Cloud Storage 值區,並將值區路徑提供給 Cloud Data Fusion 使用者,讓他們在設定外掛程式時輸入該路徑。
- Google Cloud 管理員必須將 X509 檔案的讀取權限授予設計及執行管道的 Cloud Data Fusion 使用者。
選用步驟:步驟 5:建立自訂 OData 服務
您可以在 SAP 中建立自訂 OData 服務,自訂資料擷取方式:
- 如要建立自訂 OData 服務,請參閱「建立 OData 服務 (適用於初學者)」一文。
- 如要使用核心資料服務 (CDS) 檢視畫面建立自訂 OData 服務,請參閱「如何建立 OData 服務,並將 CDS 檢視畫面公開為 OData 服務」。
- 任何自訂 OData 服務都必須支援
$top、$skip和$count查詢。這些查詢可讓外掛程式分割資料,以便依序和平行擷取。如果使用,則必須支援$filter、$expand或$select查詢。
設定 Cloud Data Fusion
請確認 Cloud Data Fusion 執行個體與 SAP 伺服器之間已啟用通訊功能。如為私人執行個體,請設定網路對等連線。與代管 SAP 系統的專案建立網路對等互連之後,您不需要額外設定,即可連線至 Cloud Data Fusion 執行個體。SAP 系統和 Cloud Data Fusion 執行個體都必須位於同一個專案中。
步驟 1:設定 Cloud Data Fusion 環境
如要為外掛程式設定 Cloud Data Fusion 環境,請按照下列步驟操作:
前往執行個體詳細資料:
在 Google Cloud 控制台中,前往 Cloud Data Fusion 頁面。
按一下「Instances」(執行個體) ,然後點選執行個體名稱,前往「Instance details」(執行個體詳細資料) 頁面。
確認執行個體已升級至 6.4.0 以上版本。如果執行個體為舊版,您必須升級。
按一下「View instance」。Cloud Data Fusion UI 開啟後,按一下「Hub」。
依序選取「SAP」分頁標籤 >「SAP OData」。
如果沒有看到「SAP」分頁,請參閱「排解 SAP 整合問題」。
按一下「Deploy SAP OData Plugin」。
外掛程式現在會顯示在 Studio 頁面的「Source」選單中。
步驟 2:設定外掛程式
SAP OData 外掛程式會讀取 SAP 資料來源的內容。
如要篩選記錄,您可以在 SAP OData 屬性頁面中設定下列屬性。
| 屬性名稱 | 說明 |
|---|---|
| 基本版 | |
| 參照名稱 | 用於唯一識別此來源的名稱,用於處理歷程或註解中繼資料。 |
| SAP OData 基礎網址 | SAP Gateway OData 基準網址 (請使用完整的網址路徑,類似 https://ADDRESS:PORT/sap/opu/odata/sap/)。 |
| OData 版本 | 支援的 SAP OData 版本。 |
| 服務名稱 | 您要從中擷取實體的 SAP OData 服務名稱。 |
| 實體名稱 | 要擷取的實體名稱,例如 Results。您可以使用前置字串,例如 C_PurchaseOrderItemMoni/Results。這個欄位支援 Category 和 Entity 參數。示例:
|
| 憑證* | |
| SAP 類型 | 基本 (透過使用者名稱和密碼)。 |
| SAP 登入使用者名稱 | SAP 使用者名稱 建議:如果 SAP 登入使用者名稱會定期變更,請使用 宏。 |
| SAP 登入密碼 | SAP 使用者密碼 建議:針對機密值 (例如密碼) 使用 安全巨集。 |
| SAP X.509 用戶端憑證 (請參閱「 在 SAP NetWeaver Application Server 上使用 ABAP 的 X.509 用戶端憑證」)。 |
|
| GCP 專案 ID | 專案的全域專屬 ID。如果「X.509 憑證 Cloud Storage 路徑」欄位不含巨集值,則必須填入這個欄位。 |
| GCS 路徑 | Cloud Storage 值區路徑,其中包含使用者上傳的 X.509 憑證,可與 SAP 應用程式伺服器相符,以便根據您的需求進行安全通訊 (請參閱「確保連線安全性」步驟)。 |
| 密碼短語 | 與提供的 X.509 憑證相對應的密碼短語。 |
| 「Get Schema」按鈕 | 根據 SAP 的中繼資料產生結構定義,並自動將 SAP 資料類型對應至相應的 Cloud Data Fusion 資料類型 (功能與「Validate」按鈕相同)。 |
| [進階] | |
| 篩選器選項 | 指出欄位必須讀取的值。請使用這個篩選器條件限制輸出資料量。例如:`Price Gt 200` 會選取 `Price` 欄位值大於 `200` 的記錄 (請參閱「取得 SAP 目錄服務可篩選欄位的清單」)。 |
| 選取欄位 | 要保留在擷取資料中的欄位 (例如:Category、Price、Name、Supplier/Address)。 |
| 展開欄位 | 在擷取的輸出資料中展開的複雜欄位清單 (例如:產品/供應商)。 |
| 要略過的資料列數量 | 要略過的列總數 (例如 10)。 |
| 要擷取的資料列數量 | 要擷取的資料列總數。 |
| 要產生的分割數量 | 用於分割輸入資料的切割數量。分割區數量越多,平行處理的程度就越高,但需要的資源和額外負擔也越多。 如果留空,外掛程式會選擇最佳值 (建議)。 |
| 批次大小 | 在每次對 SAP 的網路呼叫中擷取的資料列數量。小型資料庫會導致頻繁的網路呼叫重複相關的額外負擔。檔案大小過大可能會導致資料擷取速度變慢,並導致 SAP 使用過多資源。如果值設為 0,則預設值為 2500,且每個批次要擷取的資料列上限為 5000。 |
| 讀取逾時 | 等待 SAP OData 服務的時間 (以秒為單位)。預設值為 300。如要不設時間限制,請設為 0。 |
支援的 OData 類型
下表顯示 SAP 應用程式中使用的 OData v2 資料類型與 Cloud Data Fusion 資料類型之間的對應關係。
| OData 類型 | 說明 (SAP) | Cloud Data Fusion 資料類型 |
|---|---|---|
| 數字 | ||
| SByte | 帶正負號的 8 位元整數值 | int |
| Byte | 不帶正負號的 8 位元整數值 | int |
| Int16 | 帶正負號的 16 位元整數值 | int |
| Int32 | 帶正負號的 32 位元整數值 | int |
| Int64 | 帶有「L」字元附加的帶號 64 位元整數值: 範例: 64L、-352L |
long |
| 單一 | 精確度為 7 位數的浮點數,可表示值的範圍約為 ± 1.18e -38 到 ± 3.40e +38,並附加字元:'f' (例) 2.0f |
float |
| 雙精度值 | 精確度為 15 位元的浮點數,可表示值的範圍約為 ± 2.23e -308 到 ± 1.79e +308,並附加字元:'d' 示例: 1E+10d、2.029d、2.0d |
double |
| 小數 | 數值具有固定精度和小數位數,描述數值範圍從負 10^255 + 1 到正 10^255 -1,並附加字元:'M' 或 'm' 示例: 2.345M |
decimal |
| 角色 | ||
| Guid | 16 個位元組 (128 位元) 專屬 ID 值,開頭為以下字元:'guid' 示例: guid'12345678-aaaa-bbbb-cccc-ddddeeeeffff' |
string |
| 字串 | 以 UTF-8 編碼的固定或可變長度字元資料 | string |
| 位元組 | ||
| 二進位檔 | 固定或變數長度二進位資料,開頭為 'X' 或 'binary' (兩者皆區分大小寫) 範例: X'23AB'、binary'23ABFF' |
bytes |
| Logical | ||
| 布林值 | 二元值邏輯的數學概念 | boolean |
| 日期/時間 | ||
| 日期/時間 | 日期和時間,值範圍從 1753 年 1 月 1 日上午 12:00:00 到 9999 年 12 月 31 日晚上 11:59:59 | timestamp |
| 時間 | 時段值範圍從 0:00:00.x 到 23:59:59.y,其中 'x' 和 'y' 取決於精確度 | time |
| DateTimeOffset | 日期和時間為偏移量,以世界標準時間為基準,以分鐘為單位,值範圍從 1753 年 1 月 1 日上午 12:00:00 到 9999 年 12 月 31 日晚上 11:59:59 | timestamp |
| 複雜 | ||
| 導覽和非導覽屬性 (多重 = *) | 某種型別的集合,其多重性為一對多。 | array、string、int。 |
| 房源 (多重 = 0.1) | 參照其他複雜類型的一對一多重 | record |
驗證
按一下右上方的「驗證」或「取得結構定義」。
外掛程式會驗證屬性,並根據 SAP 的中繼資料產生結構定義。會自動將 SAP 資料類型對應至 Cloud Data Fusion 資料類型。
執行資料管道
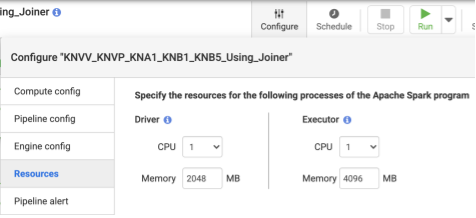
- 部署管道後,請按一下頂端中央面板中的「設定」。
- 選取「資源」。
- 視需要而定,根據整體資料大小和管道中使用的轉換次數,變更 Executor CPU 和 Memory。
- 按一下 [儲存]。
- 如要啟動資料管道,請按一下「Run」。
成效
外掛程式會使用 Cloud Data Fusion 的平行處理功能。您可以參考下列指南設定執行階段環境,為執行階段引擎提供充足的資源,以達到預期的平行處理程度和效能。
最佳化外掛程式設定
建議:除非您熟悉 SAP 系統的記憶體設定,否則請將「Number of Splits to Generate」(要產生的分割數量)和「Batch Size」(批次大小) 留空 (未指定)。
為提升管道執行時的效能,請使用下列設定:
要產生的分割數量:建議使用介於
8和16之間的值。不過,如果在 SAP 端進行適當的設定 (為 SAP 中的作業程序分配適當的記憶體資源),這些值就可能會增加到32,甚至64。這項設定可改善 Cloud Data Fusion 的並行處理能力。執行階段引擎會在擷取記錄時建立指定數量的分區 (和 SAP 連線)。如果可使用設定服務 (在匯入 SAP 傳輸檔案時,外掛程式會隨附此服務),則外掛程式會預設為 SAP 系統的設定。分割作業是 SAP 中可用對話方塊工作程序的 50%。注意:設定服務只能從 S4HANA 系統匯入。
如果無法使用設定服務,預設會使用
7分割。無論是哪種情況,如果您指定不同的值,您提供的值會優先於預設的分割值,但會受到 SAP 中可用的對話方塊程序 (減去兩個分割) 限制。
如果要擷取的記錄數量少於
2500,則分割數量為1。
批次大小:這是在每次對 SAP 的網路呼叫中擷取的記錄數量。較小的批次大小會導致頻繁的網路呼叫,重複相關的額外負擔。根據預設,最小計數為
1000,最大計數為50000。
詳情請參閱「OData 實體限制」。
Cloud Data Fusion 資源設定
建議做法:每個執行緒使用 1 個 CPU 和 4 GB 記憶體 (這個值適用於每個執行緒程序)。請在「Configure」>「Resources」對話方塊中設定這些值。
Dataproc 叢集設定
建議做法:至少分配的 CPU 總數 (跨工作站) 應大於預期的分割數量 (請參閱「外掛程式設定」)。
在 Dataproc 設定中,每個 worker 必須有每個 CPU 分配 6.5 GB 以上的記憶體 (也就是每個 Cloud Data Fusion 執行緒可用的記憶體為 4 GB 以上)。其他設定則可保留預設值。
建議做法:使用永久 Dataproc 叢集,縮短資料管道執行時間 (這樣就能省去可能需要幾分鐘的佈建步驟)。請在 Compute Engine 設定部分設定這項資訊。
設定和吞吐量的範例
以下各節將說明範例開發和實際生產設定與吞吐量。
開發和測試設定範例
- 包含 8 個工作站的 Dataproc 叢集,每個工作站各有 4 個 CPU 和 26 GB 記憶體。最多可產生 28 個分割項目。
- 包含 2 個 worker 的 Dataproc 叢集,每個 worker 有 8 個 CPU 和 52 GB 記憶體。最多可產生 12 個分割。
發布版本設定和吞吐量的範例
- 包含 8 個 worker 的 Dataproc 叢集,每個 worker 都具備 8 個 CPU 和 32 GB 記憶體。最多產生 32 個分割作業 (可用 CPU 的一半)。
- 含有 16 個 worker 的 Dataproc 叢集,每個 worker 都配備 8 個 CPU 和 32 GB 記憶體。最多產生 64 個分割作業 (可用 CPU 的一半)。
SAP S4HANA 1909 實際運作來源系統的輸送量範例
下表列出處理量示例。除非另有指定,否則顯示的總處理量不含篩選器選項。使用篩選器選項時,傳輸量會降低。
| 批量 | 分割 | OData 服務 | 總列數 | 擷取的資料列 | 處理量 (每秒資料列數) |
|---|---|---|---|---|---|
| 1000 | 4 | ZACDOCA_CDS | 5.37 M | 5.37 M | 1069 |
| 2500 | 10 | ZACDOCA_CDS | 5.37 M | 5.37 M | 3384 |
| 5000 | 8 | ZACDOCA_CDS | 5.37 M | 5.37 M | 4630 |
| 5000 | 9 | ZACDOCA_CDS | 5.37 M | 5.37 M | 4817 |
SAP S4HANA 雲端實際運作來源系統的輸送量範例
| 批量 | 分割 | OData 服務 | 總列數 | 擷取的資料列 | 處理量 (GB/小時) |
|---|---|---|---|---|---|
| 2500 | 40 | TEST_04_UOM_ODATA_CDS/ | 201 M | 10 M | 25.48 |
| 5000 | 50 | TEST_04_UOM_ODATA_CDS/ | 201 M | 10 M | 26.78 |
支援詳情
外掛程式支援下列用途。
支援的 SAP 產品和版本
支援的來源包括 SAP S4/HANA 1909 以上版本、SAP 雲端上的 S4/HANA,以及任何可公開 OData 服務的 SAP 應用程式。
包含負載平衡 SAP 呼叫的自訂 OData 服務的傳輸檔案,必須在 S/4HANA 1909 以上版本中匯入。這項服務可協助計算外掛程式可平行讀取的拆分數量 (資料分區) (請參閱「拆分數量」)。
支援 OData 2 版。
我們已在部署於 Google Cloud的 SAP S/4HANA 伺服器上,測試這個外掛程式。
支援使用 SAP OData 目錄服務進行擷取
外掛程式支援下列 DataSource 類型:
- 交易資料
- 透過 OData 公開的 CDS 檢視畫面
主資料
- 屬性
- 文字
- 階層
SAP 附註
在擷取前,不需要 SAP 附註,但 SAP 系統必須提供 SAP Gateway。詳情請參閱附註 1560585 (這個外部網站需要 SAP 登入資訊)。
資料量或記錄寬度的限制
擷取的資料量沒有固定限制。我們在測試中,最多可在單一呼叫中擷取 600 萬列資料列,每列資料的寬度為 1 KB。針對雲端版 SAP S4/HANA,我們已測試在單一呼叫中擷取最多 1 千萬列,記錄寬度為 1 KB。
預期的外掛程式處理量
如果環境是根據「效能」一節中的指南設定,外掛程式每小時可擷取約 38 GB 的資料。實際效能可能會因 Cloud Data Fusion 和 SAP 系統負載或網路流量而異。
差異 (變更資料) 擷取
不支援擷取差異。
錯誤情況
在執行階段,外掛程式會在 Cloud Data Fusion 資料管道記錄中寫入記錄項目。這些項目會在前面加上 CDF_SAP 做為識別。
在設計階段驗證外掛程式設定時,系統會在「Properties」分頁中顯示紅色醒目顯示訊息。
以下清單說明部分錯誤:
| 郵件 ID | 訊息 | 建議做法 |
|---|---|---|
| 無 | Required property 'CONNECTION_PROPERTY' for connection
type 'CONNECTION_PROPERTY_SETTING'. |
輸入實際值或巨集變數。 |
| 無 | Invalid value for property 'PROPERTY_NAME'. |
輸入非負整數 (0 以上,不含小數) 或巨集變數。 |
| CDF_SAP_ODATA_01505 | Failed to prepare the Cloud Data Fusion output schema. Please
check the provided runtime macros value. |
確認提供的巨集值是否正確。 |
| 不適用 | SAP X509 certificated 'STORAGE_PATH' is missing. Please
make sure the required X509 certificate is uploaded to your specified
Cloud Storage bucket 'BUCKET_NAME'. |
確認提供的 Cloud Storage 路徑是否正確。 |
| CDF_SAP_ODATA_01532 | 與 SAP OData 連線問題相關的一般錯誤代碼Failed to call given SAP OData service. Root Cause:
MESSAGE. |
查看訊息中顯示的根本原因,並採取適當行動。 |
| CDF_SAP_ODATA_01534 | 與 SAP OData 服務錯誤相關的一般錯誤代碼。Service validation failed. Root Cause: MESSAGE. |
查看訊息中顯示的根本原因,並採取適當行動。 |
| CDF_SAP_ODATA_01503 | Failed to fetch total available record count from
SAP_ODATA_SERVICE_ENTITY_NAME. Root Cause: MESSAGE.
|
查看訊息中顯示的根本原因,並採取適當行動。 |
| CDF_SAP_ODATA_01506 | No records found to extract in
SAP_ODATA_SERVICE_ENTITY_NAME.
Please ensure that the provided entity contains records. |
查看訊息中顯示的根本原因,並採取適當行動。 |
| CDF_SAP_ODATA_01537 | Failed to process records for
SAP_ODATA_SERVICE_ENTITY_NAME.
Root Cause: MESSAGE. |
查看訊息中顯示的根本原因,並採取適當行動。 |
| CDF_SAP_ODATA_01536 | Failed to pull records from
SAP_ODATA_SERVICE_ENTITY_NAME. Root Cause:
MESSAGE. |
查看訊息中顯示的根本原因,並採取適當行動。 |
| CDF_SAP_ODATA_01504 | Failed to generate the encoded metadata string for the given OData
service SAP_ODATA_SERVICE_NAME. Root Cause:
MESSAGE. |
查看訊息中顯示的根本原因,並採取適當行動。 |
| CDF_SAP_ODATA_01533 | Failed to decode the metadata from the given encoded metadata
string for service SAP_ODATA_SERVICE_NAME. Root Cause:
MESSAGE. |
查看訊息中顯示的根本原因,並採取適當行動。 |
後續步驟
- 進一步瞭解 Cloud Data Fusion。
- 進一步瞭解 Google Cloud上的 SAP。