이 가이드에서는 SAP OData 플러그인을 사용하는 데이터 파이프라인을 배포, 구성, 실행하는 방법을 설명합니다.
개방형 데이터 프로토콜(OData)을 사용하여 Cloud Data Fusion에서 배치 기반 데이터 추출의 소스로 SAP를 사용할 수 있습니다. SAP OData 플러그인을 사용하면 코딩 없이 SAP OData Catalog 서비스에서 데이터 전송을 구성하고 실행할 수 있습니다.
지원되는 SAP OData Catalog 서비스 및 DataSource에 대한 자세한 내용은 지원 세부정보를 참조하세요.Google Cloud기반 SAP에 대한 자세한 내용은 Google Cloud기반 SAP 개요를 참고하세요.
목표
- SAP ERP 시스템을 구성합니다(SAP에서 DataSource 활성화).
- Cloud Data Fusion 환경에 플러그인을 배포합니다.
- Cloud Data Fusion에서 SAP 전송을 다운로드하고 SAP에 설치합니다.
- Cloud Data Fusion 및 SAP ODP를 사용하여 SAP 데이터 통합을 위한 데이터 파이프라인을 만듭니다.
시작하기 전에
이 플러그인을 사용하려면 다음 영역에 대한 도메인 지식이 필요합니다.
- Cloud Data Fusion에서 파이프라인 빌드
- IAM으로 액세스 관리
- SAP Cloud 및 온프레미스 엔터프라이즈 리소스 계획(ERP) 시스템 구성
사용자 역할
이 페이지의 작업은 Google Cloud 또는 SAP 시스템에서 다음 역할을 가진 사용자가 실행합니다.
| 사용자 유형 | 설명 |
|---|---|
| Google Cloud 관리자 | 이 역할이 할당된 사용자는 Google Cloud 계정의 관리자입니다. |
| Cloud Data Fusion 사용자 | 이 역할이 할당된 사용자는 데이터 파이프라인을 설계하고 실행할 수 있는 권한이 있습니다. 이 역할에는 최소한의 Data Fusion 뷰어(roles/datafusion.viewer) 역할이 부여됩니다. 역할 기반 액세스 제어를 사용하는 경우 추가 역할이 필요할 수 있습니다.
|
| SAP 관리자 | 이 역할이 할당된 사용자는 SAP 시스템의 관리자입니다. 사용자는 SAP 서비스 사이트에서 소프트웨어를 다운로드할 수 있습니다. IAM 역할이 아닙니다. |
| SAP 사용자 | 이 역할이 할당된 사용자는 SAP 시스템에 연결할 수 있는 권한이 있습니다. IAM 역할이 아닙니다. |
OData 추출 기본 요건
OData Catalog 서비스는 SAP 시스템에서 활성화되어야 합니다.
OData 서비스에 데이터를 채워야 합니다.
SAP 시스템의 기본 요건
SAP NetWeaver 7.02부터 SAP NetWeaver 버전 7.31까지 OData 및 SAP Gateway 기능은 다음과 같은 SAP 소프트웨어 구성요소와 함께 제공됩니다.
IW_FNDGW_COREIW_BEP
SAP NetWeaver 버전 7.40 이상에서는 모든 기능이
SAP_GWFND구성요소로 제공되며, 이는 SAP NetWeaver에서 사용할 수 있어야 합니다.
선택사항: SAP 전송 파일 설치
SAP에 대한 부하 분산 호출에 필요한 SAP 구성요소는 zip 파일로 보관처리되는 SAP 전송 파일로 전달됩니다.(하나의 cofile 및 하나의 데이터 파일로 구성되는 하나의 전송 요청). 이 단계를 사용하면 SAP에서 사용 가능한 작업 프로세스를 기반으로 SAP에 대한 여러 병렬 호출을 제한할 수 있습니다.
Cloud Data Fusion 허브에서 플러그인을 배포할 때 zip 파일을 다운로드할 수 있습니다.
전송 파일을 SAP로 가져오면 다음 SAP OData 프로젝트가 생성됩니다.
OData 프로젝트
/GOOG/GET_STATISTIC/GOOG/TH_WPINFO
ICF 서비스 노드:
GOOG
SAP 전송을 설치하려면 다음 단계를 따르세요.
1단계: 전송 요청 파일 업로드
- SAP 인스턴스의 운영체제에 로그인합니다.
- SAP 트랜잭션 코드
AL11을 사용해서DIR_TRANS폴더의 경로를 가져옵니다. 일반적으로 경로는/usr/sap/trans/입니다. - cofile을
DIR_TRANS/cofiles폴더에 복사합니다. - 데이터 파일을
DIR_TRANS/data폴더에 복사합니다. - 데이터와 cofile의 사용자 및 그룹을
<sid>adm및sapsys로 설정합니다.
2단계: 전송 요청 파일 가져오기
SAP 관리자는 다음 옵션 중 하나를 사용하여 전송 요청 파일을 가져올 수 있습니다.
옵션 1: SAP 전송 관리 시스템을 사용하여 전송 요청 파일 가져오기
- SAP 시스템에 SAP 관리자로 로그인합니다.
- 트랜잭션 STMS를 입력합니다.
- 개요 > 가져오기를 클릭합니다.
- 대기열 열에서 현재 SID를 더블클릭합니다.
- 기타 > 기타 요청 > 추가를 클릭합니다.
- 전송 요청 ID를 선택하고 계속을 클릭합니다.
- 가져오기 큐에서 전송 요청을 선택한 다음 요청 > 가져오기를 클릭합니다.
- 클라이언트 번호를 입력합니다.
옵션 탭에서 원본 덮어쓰기 및 잘못된 구성요소 버전 무시(가능한 경우)를 선택합니다.
(선택사항) 나중에 전송 다시 가져오기를 예약하려면 나중에 가져올 수 있도록 큐에 전송 요청 두기 및 전송 요청 다시 가져오기를 선택합니다. 이는 SAP 시스템 업그레이드 및 백업 복원에 유용합니다.
계속을 클릭합니다.
가져오기를 확인하려면
SE80및SU01과 같은 트랜잭션을 사용합니다.
옵션 2: 운영체제 수준에서 전송 요청 파일 가져오기
- SAP 시스템에 SAP 시스템 관리자로 로그인합니다.
다음 명령어를 실행하여 가져오기 버퍼에 적절한 요청을 추가합니다.
tp addtobuffer TRANSPORT_REQUEST_ID SID예:
tp addtobuffer IB1K903958 DD1다음 명령어를 실행하여 전송 요청을 가져옵니다.
tp import TRANSPORT_REQUEST_ID SID client=NNN U1238NNN을 클라이언트 번호로 바꿉니다. 예:tp import IB1K903958 DD1 client=800 U1238SE80및SU01과 같은 적절한 트랜잭션을 사용하여 함수 모듈 및 승인 역할을 성공적으로 가져왔는지 확인합니다.
SAP 카탈로그 서비스에 대해 필터링 가능한 열 목록 가져오기
일부 DataSource 열만 필터 조건에 사용할 수 있습니다(SAP의 제한사항).
SAP 카탈로그 서비스에 대해 필터링 가능한 열 목록을 가져오려면 다음 단계를 수행합니다.
- SAP 시스템에 로그인합니다.
- t-code
SEGW로 이동합니다. 서비스 이름의 하위 문자열인 Odata 프로젝트 이름을 입력합니다. 예를 들면 다음과 같습니다.
- 서비스 이름:
MM_PUR_POITEMS_MONI_SRV - 프로젝트 이름:
MM_PUR_POITEMS_MONI
- 서비스 이름:
입력을 클릭합니다.
필터링하려는 항목으로 이동하고 속성을 선택합니다.
속성에 표시된 필드를 필터로 사용할 수 있습니다. 지원되는 작업은 같음과 범위(사이)입니다.

표현식 언어에서 지원되는 연산자 목록은 OData 오픈소스 문서 URI Conventions(OData 버전 2.0)을 참조하세요.
필터가 있는 URI 예시:
/sap/opu/odata/sap/MM_PUR_POITEMS_MONI_SRV/C_PurchaseOrderItemMoni(P_DisplayCurrency='USD')/Results/?$filter=(PurchaseOrder eq '4500000000')
SAP ERP 시스템 구성
SAP OData 플러그인은 데이터가 추출된 각 SAP 서버에서 활성화된 OData 서비스를 사용합니다. 이 OData 서비스는 SAP에서 제공되는 표준 서비스이거나 사용자의 SAP 시스템에서 개발된 커스텀 OData 서비스일 수 있습니다.
1단계: SAP 게이트웨이 2.0 설치
SAP (Basis) 관리자는 NetWeaver 출시 버전에 따라 SAP 소스 시스템에서 SAP 게이트웨이 2.0 구성요소를 사용할 수 있는지 확인해야 합니다. SAP 게이트웨이 2.0 설치에 대한 자세한 내용을 보려면 SAP ONE Support Launchpad에 로그인하고 Note 1569624를 참고하세요(로그인 필요) .
2단계: OData 서비스 활성화
소스 시스템에서 필요한 OData 서비스를 활성화합니다. 자세한 내용은 프런트엔드 서버: OData 서비스 활성화를 참조하세요.
3단계: 승인 역할 만들기
DataSource에 연결하려면 SAP에서 필요한 승인을 사용하여 승인 역할을 만든 다음 SAP 사용자에게 부여합니다.
SAP에서 승인 역할을 만들려면 다음 단계를 따르세요.
- SAP GUI에서 Transaction code PFCG를 입력하여 Role Maintenance 창을 엽니다.
역할 필드에 역할 이름을 입력합니다.
예:
ZODATA_AUTH단일 역할을 클릭합니다.
역할 만들기 창이 열립니다.
Description(설명) 필드에 설명을 입력하고 Save(저장)를 클릭합니다.
예를 들면
Authorizations for SAP OData plugin입니다.승인 탭을 클릭합니다. 창 제목이 Change Roles(역할 변경)로 변경됩니다.
Edit Authorization Data and Generate Profiles(승인 데이터 수정 및 프로필 생성)에서 Change Authorization Data(승인 데이터 변경)를 클릭합니다.
템플릿 선택 창이 열립니다.
템플릿을 선택하지 않음을 클릭합니다.
역할 변경: 승인 창이 열립니다.
직접 만들기를 클릭합니다.
다음 SAP 승인 표에 표시된 승인을 제공합니다.
저장을 클릭합니다.
승인 역할을 활성화하려면 Generate(생성) 아이콘을 클릭합니다.
SAP 승인
| 객체 클래스 | 객체 클래스 텍스트 | 승인 객체 | 승인 객체 텍스트 | 승인 | 텍스트 | 값 |
|---|---|---|---|---|---|---|
| AAAB | 애플리케이션 간 승인 객체 | S_SERVICE | 외부 서비스 시작 시 확인 | SRV_NAME | 프로그램, 트랜잭션 또는 함수 모듈 이름 | * |
| AAAB | 애플리케이션 간 승인 객체 | S_SERVICE | 외부 서비스 시작 시 확인 | SRV_TYPE | 확인 플래그 및 승인 기본값 유형 | HT |
| FI | 재무 회계 | F_UNI_HIER | 범용 계층 구조 액세스 | ACTVT | 활동 | 03 |
| FI | 재무 회계 | F_UNI_HIER | 범용 계층 구조 액세스 | HRYTYPE | 계층 구조 유형 | * |
| FI | 재무 회계 | F_UNI_HIER | 범용 계층 구조 액세스 | HRYID | 계층 구조 ID | * |
Cloud Data Fusion에서 데이터 파이프라인을 설계하고 실행하려면(Cloud Data Fusion 사용자) SAP 사용자 인증 정보(사용자 이름 및 비밀번호)가 있어야 DataSource에 연결할 플러그인을 구성할 수 있습니다.
SAP 사용자는 Communications 또는 Dialog 유형이어야 합니다. SAP 대화상자 리소스를 사용하지 않으려면 Communications 유형을 사용하는 것이 좋습니다. SAP 트랜잭션 코드 SU01을 사용하여 사용자를 만들 수 있습니다.
선택사항: 4단계: 연결 보안
비공개 Cloud Data Fusion 인스턴스와 SAP 사이에 네트워크를 통해 통신을 보호할 수 있습니다.
연결을 보호하려면 다음 단계를 따릅니다.
- SAP 관리자가 X509 인증서를 생성해야 합니다. 인증서를 생성하려면 SSL 서버 PSE 만들기를 참조하세요.
- 관리자는 Google Cloud Cloud Data Fusion 인스턴스와 동일한 프로젝트에서 읽을 수 있는 Cloud Storage 버킷에 X509 파일을 복사하고 플러그인을 구성할 때 버킷 경로를 입력하는 Cloud Data Fusion 사용자에게 버킷 경로를 제공해야 합니다.
- Google Cloud 관리자는 파이프라인을 설계하고 실행하는 Cloud Data Fusion 사용자에게 X509 파일에 대한 읽기 액세스 권한을 부여해야 합니다.
선택사항: 5단계: 커스텀 OData 서비스 만들기
SAP에서 커스텀 OData 서비스를 만들어 데이터 추출 방법을 맞춤설정할 수 있습니다.
- 커스텀 OData 서비스를 만들려면 초보자를 위한 OData 서비스 만들기를 참조하세요.
- 핵심 데이터 서비스(CDS) 뷰를 사용하여 커스텀 OData 서비스를 만들려면 OData 서비스를 만들고 CDS 뷰를 OData 서비스로 노출하는 방법을 참조하세요.
- 모든 커스텀 OData 서비스는
$top,$skip,$count쿼리를 지원해야 합니다. 이러한 쿼리를 통해 플러그인이 순차적 및 병렬 추출을 위해 데이터를 파티션으로 나눌 수 있습니다. 사용된 경우$filter,$expand,$select쿼리도 지원되어야 합니다.
Cloud Data Fusion 설정
Cloud Data Fusion 인스턴스와 SAP 서버 간에 통신이 사용 설정되어 있는지 확인합니다. 비공개 인스턴스의 경우 네트워크 피어링을 설정합니다. SAP 시스템이 호스팅되는 프로젝트와 네트워크 피어링이 설정되면 Cloud Data Fusion 인스턴스에 연결하는 데 추가 구성이 필요하지 않습니다. SAP 시스템과 Cloud Data Fusion 인스턴스는 동일한 프로젝트 내에 있어야 합니다.
1단계: Cloud Data Fusion 환경 설정
플러그인에 맞게 Cloud Data Fusion 환경을 구성하려면 다음 안내를 따르세요.
인스턴스 세부정보로 이동합니다.
Google Cloud 콘솔에서 Cloud Data Fusion 페이지로 이동합니다.
인스턴스를 클릭한 후 인스턴스 이름을 클릭하여 인스턴스 세부정보 페이지로 이동합니다.
인스턴스가 버전 6.4.0 이상으로 업그레이드되었는지 확인합니다. 인스턴스가 이전 버전인 경우 업그레이드해야 합니다.
인스턴스 보기를 클릭합니다. Cloud Data Fusion UI가 열리면 허브를 클릭합니다.
SAP 탭 > SAP OData를 선택합니다.
SAP 탭이 표시되지 않으면 SAP 통합 문제 해결을 참조하세요.
SAP OData 플러그인 배포를 클릭합니다.
이제 스튜디오 페이지의 소스 메뉴에 플러그인이 표시됩니다.
2단계: 플러그인 구성
SAP OData 플러그인이 SAP DataSource의 콘텐츠를 읽습니다.
레코드를 필터링하려면 SAP OData 속성 페이지에서 다음 속성을 구성할 수 있습니다.
| 속성 이름 | 설명 |
|---|---|
| Basic | |
| 참조 이름 | 계보 또는 주석 추가 메타데이터에 대해 이 소스를 고유하게 식별하는 데 사용되는 이름입니다. |
| SAP OData 기본 URL | SAP Gateway OData 기본 URL (https://ADDRESS:PORT/sap/opu/odata/sap/와 비슷하게 전체 URL 경로 사용)
|
| OData 버전 | 지원되는 SAP OData 버전 |
| 서비스 이름 | 항목을 추출할 SAP OData 서비스의 이름 |
| 항목 이름 | 추출되는 항목 이름(예: Results). C_PurchaseOrderItemMoni/Results와 같은 프리픽스를 사용할 수 있습니다. 이 필드는 카테고리 및 항목 매개변수를 지원합니다. 예를 들면 다음과 같습니다.
|
| 사용자 인증 정보* | |
| SAP 유형 | 기본(사용자 이름 및 비밀번호 사용) |
| SAP 로그온 사용자 이름 | SAP 사용자 이름 권장: SAP 로그온 사용자 이름이 주기적으로 변경되는 경우 매크로를 사용합니다. |
| SAP 로그온 비밀번호 | SAP 사용자 비밀번호 권장: 비밀번호와 같은 민감한 값에는 보안 매크로를 사용합니다. |
| SAP X.509 클라이언트 인증서 ( ABAP용 SAP NetWeaver 애플리케이션 서버에서 X.509 클라이언트 인증서 사용 참조) |
|
| GCP 프로젝트 ID | 프로젝트의 전역 고유 식별자입니다. X.509 인증서 Cloud Storage 경로 필드에 매크로 값이 포함되지 않은 경우 이 필드가 필수입니다. |
| GCS 경로 | 요구사항에 따른 보안 호출의 SAP 애플리케이션 서버에 해당하는 사용자 업로드 X.509 인증서가 포함된 Cloud Storage 버킷 경로(연결 보호 단계를 참조하세요.) |
| 암호 | 제공된 X.509 인증서에 해당하는 암호 |
| Get Schema(스키마 가져오기) 버튼 | SAP의 메타데이터를 기반으로 SAP에서 스키마를 생성하고 SAP 데이터 유형을 해당 Cloud Data Fusion 데이터 유형에 자동으로 매핑합니다(Validate(유효성 검사) 버튼과 동일한 기능). |
| 고급 | |
| 필터링 옵션 | 필드를 읽어야 하는 값을 나타냅니다. 이 필터 조건을 사용하여 출력 데이터 볼륨을 제한합니다. 예를 들어 `Price Gt 200`은 `Price` 필드 값이 `200`을 초과하는 레코드를 선택합니다. (SAP 카탈로그 서비스에 대해 필터링 가능한 열 목록 가져오기를 참조하세요.) |
| 필드 선택 | 추출된 데이터에 보존할 필드입니다(예: 카테고리, 가격, 이름, 공급업체/주소). |
| 필드 확장 | 추출된 출력 데이터에서 확장할 복합 필드 목록(예: 제품/공급업체) |
| 건너뛸 행 수 | 건너뛸 총 행 수입니다(예: 10). |
| 가져올 행 수 | 추출할 총 행 수 |
| 생성할 분할 수 | 입력 데이터를 분할하는 데 사용되는 분할 수입니다. 분할 수가 많을수록 동시 로드 수준이 늘어나지만 리소스와 오버헤드가 더 많이 필요합니다. 비워두면 플러그인이 최적의 값을 선택합니다(권장). |
| 배치 크기 | SAP에 대한 각 네트워크 호출에서 가져올 행 수입니다. 크기가 작으면 네트워크 호출이 자주 발생하여 관련 오버헤드가 반복됩니다. 크기가 크면 데이터 검색 속도가 느려지고 SAP에서 리소스가 과도하게 사용될 수 있습니다.
값이 0으로 설정된 경우 기본값이 2500이고 각 배치에서 가져올 행 수가가 5000으로 제한됩니다. |
| 읽기 제한 시간 | SAP OData 서비스를 기다리는 시간(초)입니다. 기본값은 300입니다. 시간 제한이 없는 경우 0로 설정합니다. |
지원되는 OData 유형
다음 표에서는 SAP 애플리케이션과 Cloud Data Fusion 데이터 유형에 사용되는 OData v2 데이터 유형 간의 매핑을 보여줍니다.
| OData 유형 | 설명(SAP) | Cloud Data Fusion 데이터 유형 |
|---|---|---|
| 숫자 | ||
| SByte | 부호 있는 8비트 정수 값 | int |
| 바이트 | 부호 없는 8비트 정수 값 | int |
| Int16 | 부호 있는 16비트 정수 값 | int |
| Int32 | 부호 있는 32비트 정수 값 | int |
| Int64 | 문자 'L'이 추가된 부호 있는 64비트 정수 값입니다. 예: 64L, -352L |
long |
| 단일 | 대략 ±1.18e -38 ~ ± 3.40e +38 범위의 값을 나타낼 수 있는 7자리 정밀도의 부동 소수점 수이며 문자 'f'가 추가됩니다. 예: 2.0f |
float |
| 실수 | 대략 ±2.23e -308 ~ ±1.79e +308 범위의 값을 나타낼 수 있는 15자리 정밀도의 부동 소수점 수이며 문자 'd'가 추가됩니다. 예: 1E+10d, 2.029d, 2.0d |
double |
| 십진수 | 음수 10^255 + 1부터 양수 10^255 -1 범위의 숫자 값을 설명하는 고정된 정밀도 및 비율이 있는 숫자 값이며 'M' 또는 'm' 문자가 추가됩니다. 예: 2.345M |
decimal |
| 문자 | ||
| Guid | 16바이트(128비트) 고유 식별자 값으로, 문자 'guide'로 시작합니다. 예: guid'12345678-aaaa-bbbb-cccc-ddddeeeeffff' |
string |
| 문자열 | UTF-8로 인코딩된 고정 또는 가변 길이 문자 데이터 | string |
| 바이트 | ||
| 바이너리 | 'X' 또는 '바이너리'로 시작하는 고정 또는 가변 길이 바이너리 데이터(둘 다 대소문자를 구분합니다.) 예: X'23AB', binary'23ABFF' |
bytes |
| 논리 | ||
| 불리언 | 이진 값 논리의 수학 개념 | boolean |
| 날짜/시간 | ||
| 날짜/시간 | 값이 1753년 1월 1일 오전 12:00:00부터 9999년 12월 31일 오후 11:59:59까지인 날짜 및 시간입니다. | timestamp |
| 시간 | 0:00:00.x~23:59:59.y 사이의 값이 포함된 일 중 시간입니다. 여기서 'x'와 'y'는 정밀도에 따라 달라집니다. | time |
| DateTimeOffset | 날짜 및 시간은 오프셋으로(GMT 기준, 분) 1753년 1월 1일 오전 12:00:00부터 9999년 12월 31일 오후 11:59:59까지입니다. | timestamp |
| 단지 | ||
| 탐색 및 비탐색 속성(다중성 = *) | 일대다 다중 유형으로 구성된 유형의 컬렉션 | array,string,int. |
| 속성(다중성 = 0.1) | 일대일 다중성을 갖는 다른 복잡한 유형에 대한 참조 | record |
유효성 검사
오른쪽 상단에서 유효성 검사 또는 스키마 가져오기를 클릭합니다.
플러그인은 속성의 유효성을 검사하고 SAP의 메타데이터를 기반으로 스키마를 생성합니다. SAP 데이터 유형을 해당하는 Cloud Data Fusion 데이터 유형에 자동으로 매핑합니다.
데이터 파이프라인 실행
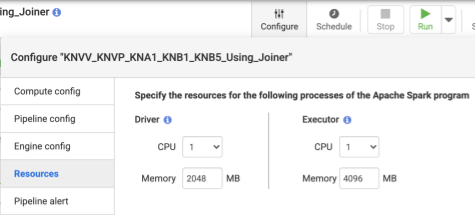
- 파이프라인을 배포한 후 상단 중앙 패널에서 구성을 클릭합니다.
- 리소스를 선택합니다.
- 필요한 경우 파이프라인에 사용되는 전체 데이터 크기와 변환 수를 기반으로 실행자 CPU와 메모리를 변경합니다.
- 저장을 클릭합니다.
- 데이터 파이프라인을 시작하려면 실행을 클릭합니다.
성능
플러그인은 Cloud Data Fusion의 동시 로드 기능을 사용합니다. 다음 가이드라인은 런타임 환경을 구성하여 원하는 수준의 동시 로드와 성능을 얻기 위해 충분한 리소스를 런타임 엔진에 제공하는 데 도움이 됩니다.
플러그인 구성 최적화
권장: SAP 시스템의 메모리 설정에 익숙하지 않은 경우 생성할 분할 수 및 배치 크기를 빈 칸(미지정)으로 둡니다.
파이프라인 실행 시 성능을 높이려면 다음 구성을 사용합니다.
생성할 분할 수:
8~16사이의 값이 권장됩니다. 하지만 SAP 측의 적절한 구성에 따라32또는 심지어64까지 증가할 수 있습니다(SAP의 작업 프로세스에 대해 적절한 메모리 리소스 할당). 이 구성은 Cloud Data Fusion 측의 동시 로드를 향상시켜 줍니다. 런타임 엔진은 레코드를 추출하는 동안 지정된 수의 파티션(및 SAP 연결)을 만듭니다.구성 서비스(SAP 전송 파일을 가져올 때 플러그인과 함께 제공됨)를 사용할 수 있으면 플러그인이 기본적으로 SAP 시스템 구성으로 지정됩니다. 분할은 SAP에서 사용 가능한 대화상자 작업 프로세스의 50%입니다. 참고: 구성 서비스는 S4HANA 시스템에서만 가져올 수 있습니다.
구성 서비스를 사용할 수 없는 경우 기본값은
7개 분할입니다.어느 경우든 다른 값을 지정하면 제공한 값이 기본 분할 값보다 우선합니다(단, SAP에서 사용 가능한 대화상자 프로세스에 의해 제한되고 2개의 분할을 뺀다는 점 제외).
추출할 레코드 수가
2500보다 작으면 분할 수가1입니다.
배치 크기: SAP에 대한 모든 네트워크 호출에서 가져올 레코드 수입니다. 배치 크기가 작을수록 네트워크 호출이 자주 발생하여 관련 오버헤드가 반복됩니다. 기본적으로 최솟값 수는
1000이고 최댓값은50000입니다.
자세한 내용은 OData 항목 제한을 참조하세요.
Cloud Data Fusion 리소스 설정
권장: 실행자당 1 CPU와 4 GB의 메모리를 사용합니다(이 값은 각 실행자 프로세스에 적용됨). 구성 > 리소스 대화상자에서 설정합니다.
Dataproc 클러스터 설정
권장: 작업자 간에 총 CPU를 원래 분할 수보다 많이 할당합니다(플러그인 구성 참조).
각 작업자는 Dataproc 설정에서 메모리가 CPU당 6.5GB 이상 할당되어야 합니다. 즉, Cloud Data Fusion 실행자당 4GB 이상을 사용할 수 있어야 합니다. 다른 설정은 기본값으로 둘 수 있습니다.
권장: 영구 Dataproc 클러스터를 사용하여 데이터 파이프라인 런타임을 줄입니다. 그러면 몇 분 이상 걸릴 수 있는 프로비저닝 단계가 제거됩니다. Compute Engine 구성 섹션에서 이를 설정합니다.
샘플 구성 및 처리량
다음 섹션에서는 샘플 개발 및 프로덕션 구성과 처리량을 설명합니다.
샘플 개발 및 테스트 구성
- 각각 4개의 CPU와 26GB의 메모리를 사용하는 8개의 작업자가 있는 Dataproc 클러스터. 최대 28개의 분할을 생성합니다.
- 각각 8개의 CPU와 52GB의 메모리를 사용하는 2개의 작업자가 있는 Dataproc 클러스터. 최대 12개의 분할을 생성합니다.
샘플 프로덕션 구성 및 처리량
- 각각 8개의 CPU와 32GB의 메모리를 사용하는 8개의 작업자가 있는 Dataproc 클러스터. 최대 32개의 분할을 생성합니다(사용 가능한 CPU의 절반).
- 각각 8개의 CPU와 32GB의 메모리를 사용하는 16개의 작업자가 있는 Dataproc 클러스터. 최대 64개의 분할을 생성합니다(사용 가능한 CPU의 절반).
SAP S4HANA 1909 프로덕션 소스 시스템의 샘플 처리량
다음 표에서는 샘플 처리량을 보여줍니다. 특별히 지정되지 않은 한 표시된 처리량은 필터 옵션을 포함하지 않습니다. 필터 옵션을 사용하면 처리량이 줄어듭니다.
| 배치 크기 | 분할 | OData 서비스 | 전체 행 수 | 추출된 행 | 처리량(초당 행 수) |
|---|---|---|---|---|---|
| 1000 | 4 | ZACDOCA_CDS | 537만 개 | 537만 개 | 1069 |
| 2500 | 10 | ZACDOCA_CDS | 537만 개 | 537만 개 | 3384 |
| 5000 | 8 | ZACDOCA_CDS | 537만 개 | 537만 개 | 4630 |
| 5000 | 9 | ZACDOCA_CDS | 537만 개 | 537만 개 | 4817 |
SAP S4HANA 클라우드 프로덕션 소스 시스템의 샘플 처리량
| 배치 크기 | 분할 | OData 서비스 | 전체 행 수 | 추출된 행 | 처리량(GB/시간) |
|---|---|---|---|---|---|
| 2500 | 40 | TEST_04_UOM_ODATA_CDS/ | 2억 100만개 | 1,000만 개 | 25.48 |
| 5000 | 50 | TEST_04_UOM_ODATA_CDS/ | 2억 100만개 | 1,000만 개 | 26.78 |
지원 세부정보
이 플러그인은 다음 사용 사례를 지원합니다.
지원되는 SAP 제품 및 버전
지원되는 소스로는 SAP S4/HANA 1909 이상, SAP 클라우드 기반 S4/HANA, OData 서비스를 노출할 수 있는 SAP 애플리케이션이 있습니다.
SAP에 대한 호출을 부하 분산하는 커스텀 OData 서비스가 포함된 전송 파일을 S4/HANA 1909 이상에서 가져와야 합니다. 이 서비스는 플러그인에서 동시에 읽을 수 있는 분할 수(데이터 파티션)를 계산하는데 도움이 됩니다.(분할 수 참조)
OData 버전 2가 지원됩니다.
플러그인은 Google Cloud에 배포된 SAP S/4HANA 서버로 테스트되었습니다.
SAP OData Catalog 서비스 추출 지원
플러그인은 다음 DataSource 유형을 지원합니다.
- 거래 데이터
- OData를 통해 노출된 CDS 뷰
마스터 데이터
- 속성
- 텍스트
- 계층 구조
SAP Note
추출 전에 SAP Note가 필요하지 않지만 SAP 시스템에는 사용 가능한 SAP 게이트웨이가 있어야 합니다. 자세한 내용은 Note 1560585를 참조하세요. 이 외부 사이트에는 SAP 로그인이 필요합니다.
데이터 볼륨 또는 레코드 너비 제한
추출되는 데이터 볼륨에는 정의된 한도가 없습니다. 1KB 레코드 너비를 사용해서 한 번의 호출에서 최대 6백만 개의 행을 추출하여 테스트했습니다. 클라우드 SAP S4/HANA에서는 1KB 레코드 너비를 사용해서 한 번의 호출에서 최대 1억 개의 행을 추출하여 테스트했습니다.
예상 플러그인 처리량
성능 섹션의 가이드라인에 따라 구성된 환경의 경우 플러그인이 시간당 약 38GB를 추출할 수 있습니다. 실제 성능은 Cloud Data Fusion 및 SAP 시스템 로드 또는 네트워크 트래픽에 따라 달라질 수 있습니다.
델타(변경된 데이터) 추출
델타 추출은 지원되지 않습니다.
오류 시나리오
런타임 시 플러그인은 Cloud Data Fusion 데이터 파이프라인 로그에 로그 항목을 작성합니다. 이 항목에는 식별을 위해 CDF_SAP 프리픽스가 붙습니다.
설계 시 플러그인 설정을 검증하면 메시지가 속성 탭에 표시되고 빨간색으로 강조 표시됩니다.
다음 목록에는 이러한 오류 중 일부가 설명되어 있습니다.
| 메시지 ID | 메시지 | 권장 조치 |
|---|---|---|
| 없음 | Required property 'CONNECTION_PROPERTY' for connection
type 'CONNECTION_PROPERTY_SETTING'. |
실제 값 또는 매크로 변수를 입력하세요. |
| 없음 | Invalid value for property 'PROPERTY_NAME'. |
음수가 아닌 정수 (소수점 없는 0 이상의 값) 또는 매크로 변수를 입력합니다. |
| CDF_SAP_ODATA_01505 | Failed to prepare the Cloud Data Fusion output schema. Please
check the provided runtime macros value. |
제공된 매크로 값이 올바른지 확인합니다. |
| 해당 사항 없음 | SAP X509 certificated 'STORAGE_PATH' is missing. Please
make sure the required X509 certificate is uploaded to your specified
Cloud Storage bucket 'BUCKET_NAME'. |
제공된 Cloud Storage 경로가 올바른지 확인합니다. |
| CDF_SAP_ODATA_01532 | SAP OData 연결 문제와 관련된 일반 오류 코드Failed to call given SAP OData service. Root Cause:
MESSAGE. |
메시지에 표시된 근본 원인을 확인하고 적절한 조치를 취합니다. |
| CDF_SAP_ODATA_01534 | SAP OData 서비스 오류와 관련된 일반 오류 코드입니다.Service validation failed. Root Cause: MESSAGE. |
메시지에 표시된 근본 원인을 확인하고 적절한 조치를 취합니다. |
| CDF_SAP_ODATA_01503 | Failed to fetch total available record count from
SAP_ODATA_SERVICE_ENTITY_NAME. Root Cause: MESSAGE.
|
메시지에 표시된 근본 원인을 확인하고 적절한 조치를 취합니다. |
| CDF_SAP_ODATA_01506 | No records found to extract in
SAP_ODATA_SERVICE_ENTITY_NAME.
Please ensure that the provided entity contains records. |
메시지에 표시된 근본 원인을 확인하고 적절한 조치를 취합니다. |
| CDF_SAP_ODATA_01537 | Failed to process records for
SAP_ODATA_SERVICE_ENTITY_NAME.
Root Cause: MESSAGE. |
메시지에 표시된 근본 원인을 확인하고 적절한 조치를 취합니다. |
| CDF_SAP_ODATA_01536 | Failed to pull records from
SAP_ODATA_SERVICE_ENTITY_NAME. Root Cause:
MESSAGE. |
메시지에 표시된 근본 원인을 확인하고 적절한 조치를 취합니다. |
| CDF_SAP_ODATA_01504 | Failed to generate the encoded metadata string for the given OData
service SAP_ODATA_SERVICE_NAME. Root Cause:
MESSAGE. |
메시지에 표시된 근본 원인을 확인하고 적절한 조치를 취합니다. |
| CDF_SAP_ODATA_01533 | Failed to decode the metadata from the given encoded metadata
string for service SAP_ODATA_SERVICE_NAME. Root Cause:
MESSAGE. |
메시지에 표시된 근본 원인을 확인하고 적절한 조치를 취합니다. |
다음 단계
- Cloud Data Fusion 자세히 알아보기
- Google Cloud의 SAP에 대해 자세히 알아보세요.