이 페이지에서는 기존 Dataproc 클러스터에 대해 Cloud Data Fusion에서 파이프라인을 실행하는 방법을 설명합니다.
기본적으로 Cloud Data Fusion은 파이프라인마다 임시 클러스터를 만듭니다. 파이프라인 실행 시작 시 클러스터를 만든 후 파이프라인 실행이 완료되면 삭제합니다. 이 동작은 리소스가 필요할 때만 생성되도록 설정하여 비용을 절약하지만, 다음 시나리오에서는 이러한 기본 동작이 적합하지 않을 수 있습니다.
모든 파이프라인의 새 클러스터를 만드는 데 걸리는 시간이 사용 사례에 실용적이지 않은 경우
조직에서 중앙 집중식으로 클러스터 생성을 관리해야 하는 경우, 예를 들어 모든 Dataproc 클러스터에 대해 특정 정책을 적용하려는 경우
이러한 시나리오에서는 대신 다음 단계를 수행하여 기존 클러스터에 대해 파이프라인을 실행합니다.
시작하기 전에
필요한 사항은 다음과 같습니다.
Cloud Data Fusion 인스턴스
기존 Dataproc 클러스터.
Cloud Data Fusion 버전 6.2에서 파이프라인을 실행하는 경우에는 Hadoop 2.x로 실행되는 이전 Dataproc 이미지 버전(예: 1.5-debian10)을 사용하거나 최신 Cloud Data Fusion 버전으로 업그레이드하세요.
기존 클러스터에 연결
Cloud Data Fusion 버전 6.2.1 이상에서는 새로운 Compute Engine 프로필을 만들 때 기존 Dataproc 클러스터에 연결할 수 있습니다.
인스턴스로 이동합니다.
Google Cloud 콘솔에서 Cloud Data Fusion 페이지로 이동합니다.
Cloud Data Fusion Studio에서 인스턴스를 열려면 인스턴스를 클릭한 다음 인스턴스 보기를 클릭합니다.
시스템 관리자를 클릭합니다.
Configuration 탭을 클릭합니다.
시스템 컴퓨팅 프로필을 클릭합니다.
새 프로필 만들기를 클릭합니다. 프로비저닝 도구 페이지가 열립니다.
기존 Dataproc을 클릭합니다.
프로필, 클러스터, 모니터링 정보를 입력합니다.
만들기를 클릭합니다.
커스텀 프로필을 사용하도록 파이프라인 구성
인스턴스로 이동합니다.
Google Cloud 콘솔에서 Cloud Data Fusion 페이지로 이동합니다.
Cloud Data Fusion Studio에서 인스턴스를 열려면 인스턴스를 클릭한 다음 인스턴스 보기를 클릭합니다.
스튜디오 페이지에서 파이프라인으로 이동합니다.
구성을 클릭합니다.
컴퓨팅 구성을 클릭합니다.
생성한 프로필을 클릭합니다.
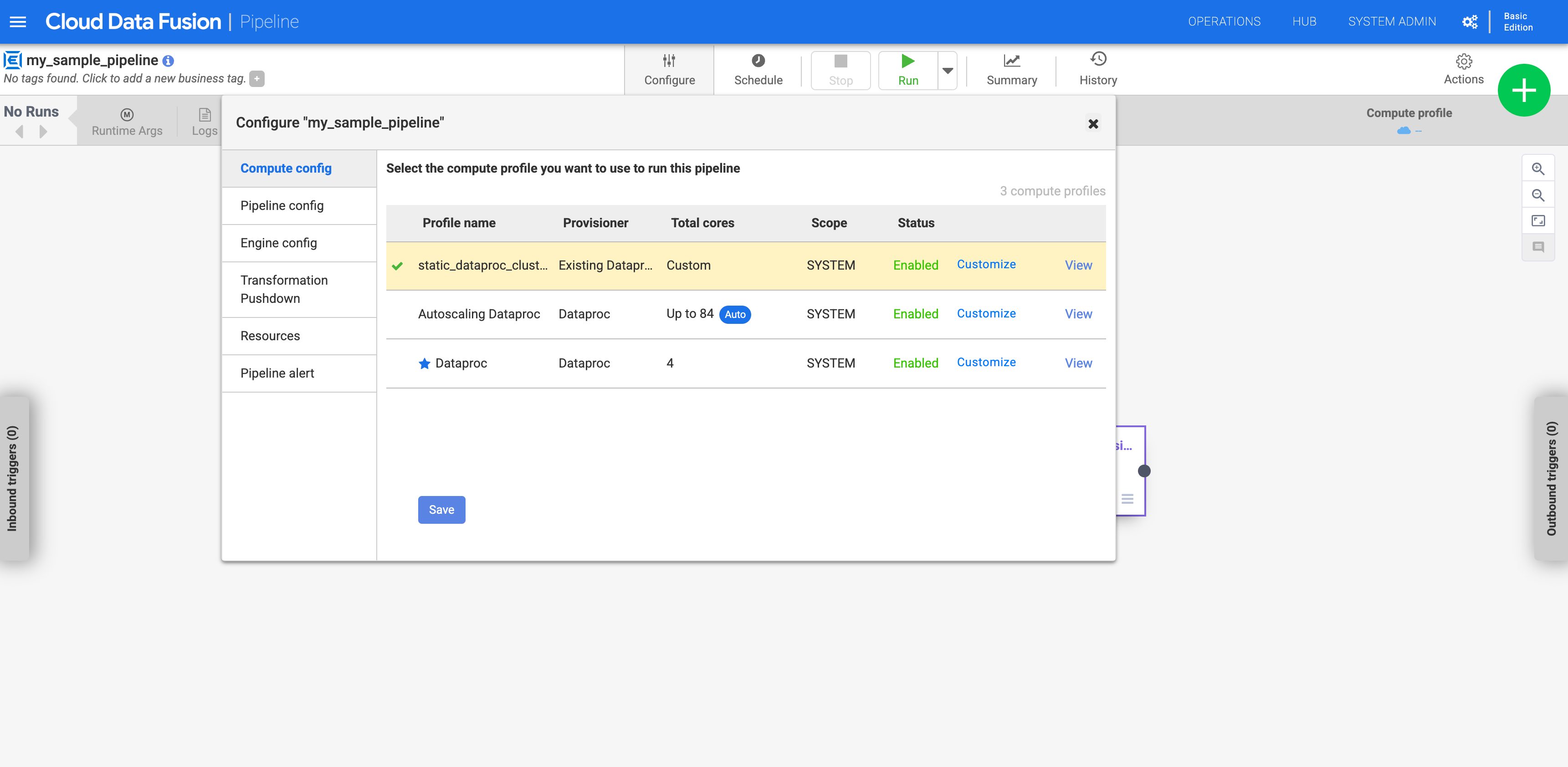
그림 1: 커스텀 프로필 클릭 파이프라인을 실행합니다. 기존 Dataproc 클러스터에 대해 실행됩니다.