Esta página descreve como configurar o pipeline de dados para ler dados de uma tabela do Microsoft SQL Server.
Antes de começar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Cloud Data Fusion, BigQuery, Cloud Storage, and Dataproc APIs.
- Crie uma instância do Cloud Data Fusion.
- O banco de dados do SQL Server precisa aceitar conexões do Cloud Data Fusion. Por motivos de segurança, use uma instância particular do Cloud Data Fusion.
Abra sua instância do Cloud Data Fusion
No console do Google Cloud, acesse a página Instâncias do Cloud Data Fusion.
Na coluna Ações da instância, clique em Ver instância para abrir a instância no Cloud Data Fusion.
Armazenar a senha do SQL Server como uma chave segura
Adicione a senha do SQL Server como uma chave segura na instância do Cloud Data Fusion.
No Cloud Data Fusion, clique em Administrador do sistema.
Clique na guia Configuração.
Clique em Fazer chamadas HTTP.

Selecione PUT.
No campo do caminho, digite
namespaces/NAMESPACE_ID/securekeys/password.No campo Corpo, digite
{"data":"password"}. Substitua password pela sua senha do SQL Server.Clique em Send.
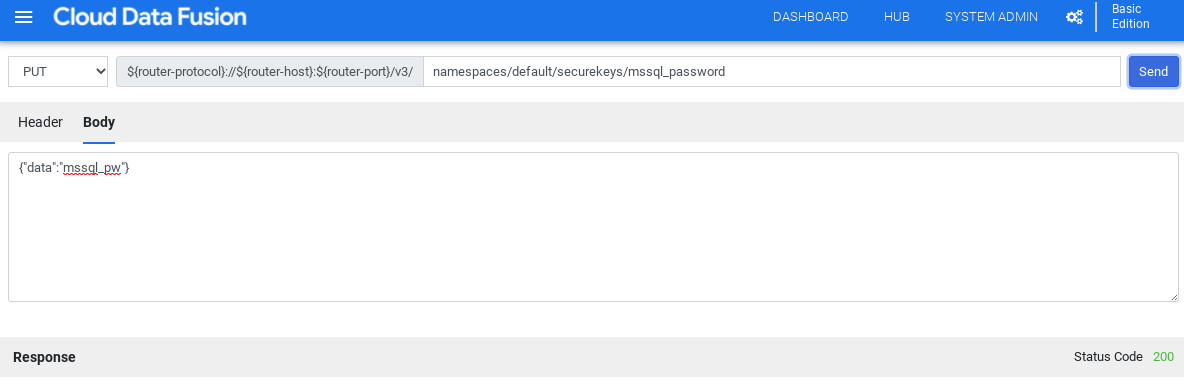
A resposta precisa ter o código de status 200 para continuar.
Acessar o driver JDBC para SQL Server
Você pode acessar o driver no Hub ou no Pipeline Studio do Cloud Data Fusion.
Hub
Na interface do Cloud Data Fusion, clique em Hub.
Na barra de pesquisa, digite
SQL Server JDBC Drivere selecione o motorista.Clique em Fazer download. Siga as etapas de download mostradas.
Clique em Implantar. Faça upload do arquivo JAR da etapa anterior.
Clique em Concluir.
Pipeline Studio
Acesse Microsoft.com.
Escolha o download e clique em Fazer o download.
No Cloud Data Fusion, clique em menu Menu e acesse a página Pipeline Studio.
Clique em Adicionar.
Para o driver, clique em Fazer upload.
Selecione o arquivo JAR, localizado na pasta
jre7.Clique em Próxima.
Para configurar o driver, digite um Nome e um Nome da classe.
Clique em Concluir.
Implantar o plug-in do SQL Server
No Cloud Data Fusion, clique em Hub.
Na barra de pesquisa, digite
SQL Server Plugins.Clique em Plug-ins do servidor SQL.
Clique em Implantar.
Clique em Finish.
Clique em Criar um pipeline.
Conectar-se ao SQL Server
É possível se conectar ao SQL Server pelo Cloud Data Fusion no Wrangler ou no Pipeline Studio.
Wrangler
No Cloud Data Fusion, clique em menu Menu e acesse a página Wrangler.
Clique em Adicionar conexão.
A janela Adicionar conexão será aberta.
Clique em SQL Server para verificar se o driver está instalado.

Insira os detalhes nos campos de conexão obrigatórios. No campo Senha, selecione a chave segura armazenada anteriormente. Isso garante que sua senha seja recuperada usando o Cloud KMS.
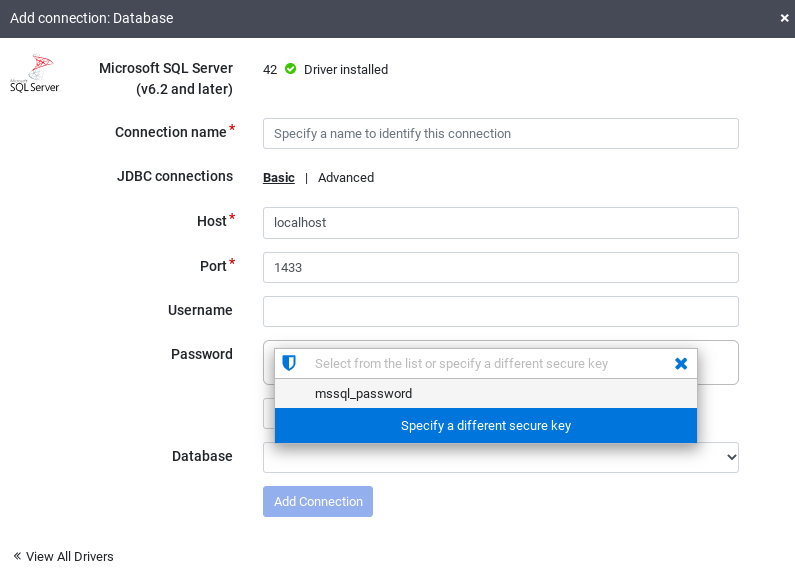
Para verificar se uma conexão pode ser estabelecida com o banco de dados, clique em Testar conexão.
Clique em Adicionar conexão.
Depois que o banco de dados do SQL Server estiver conectado e você tiver criado um pipeline que leia da tabela do SQL Server, será possível aplicar transformações e gravar a saída em um coletor.
Pipeline Studio
Abra sua instância do Cloud Data Fusion e acesse a página Pipeline Studio.
Abra o menu Origem e clique em SQL Server.

No nó SQL Server, clique em Propriedades.
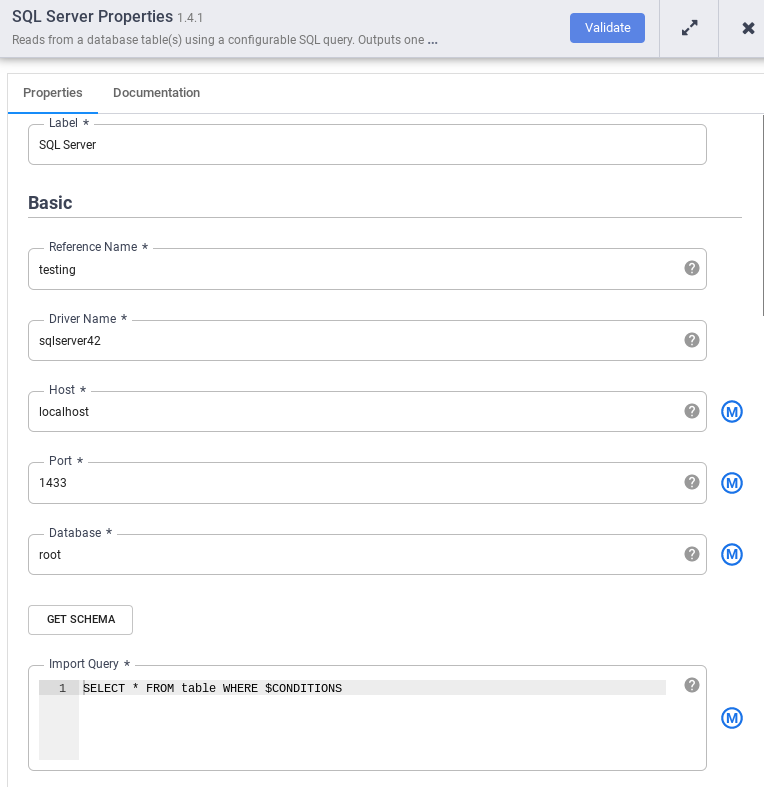
No campo Nome da referência, insira um nome que identifique a origem do SQL Server.
No campo Banco de dados, insira o nome do banco de dados a ser conectado.
No campo Importar consulta, insira a consulta a ser executada. Por exemplo,
SELECT * FROM table WHERE $CONDITIONS.Clique em Validar.
Clique em Fechar .
Depois que o banco de dados do SQL Server estiver conectado e você tiver criado um pipeline que leia da tabela do SQL Server, adicione as transformações desejadas e grave a saída em um coletor.
A seguir
- Saiba como ler dados de várias tabelas do SQL Server.
- Saiba mais sobre o Cloud Data Fusion.
- Siga um dos tutoriais.