このページでは、Cloud Data Fusion で Spark ではなく BigQuery への変換を実行する方法について説明します。
詳細については、Transformation Pushdown の概要をご覧ください。
始める前に
変換のプッシュダウンは、バージョン 6.5.0 以降で使用できます。パイプラインが以前の環境で実行されている場合は、最新バージョンにインスタンスをアップグレードできます。
パイプラインで Transformation Pushdown を有効にする
Console
デプロイされたパイプラインで Transformation Pushdown を有効にするには、次の手順に従います。
インスタンスに移動します:
Google Cloud コンソールで、Cloud Data Fusion のページに移動します。
Cloud Data Fusion Studio でインスタンスを開くには、[インスタンス]、[インスタンスを表示] の順にクリックします。
[メニュー >] [リスト] をクリックします。
[デプロイされたパイプライン] タブが開きます。
デプロイするパイプラインをクリックして、[Pipeline Studio] を開きます。
[設定] > [Transformation Pushdown] をクリックします。
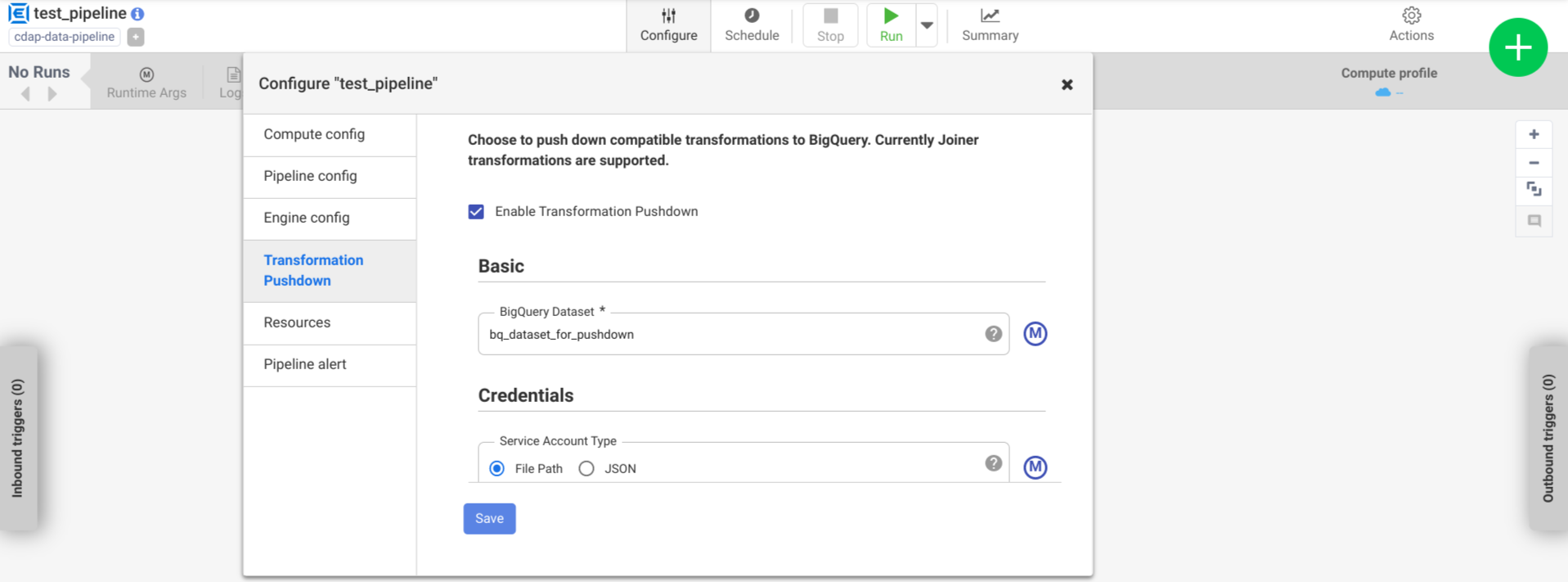
[Transformation Pushdown を有効にする] をクリックします。
[データセット] フィールドに、BigQuery データセットの名前を入力します。
省略可: マクロを使用するには、[M] をクリックします。詳細については、データセットをご覧ください。
省略可: 必要に応じてオプションを構成します。
[保存] をクリックします。
オプションの構成
.| プロパティ | マクロをサポートする | サポートされている Cloud Data Fusion のバージョン | 説明 |
|---|---|---|---|
| 接続を使用 | × | 6.7.0 以降 | 既存の接続を使用するかどうか。 |
| 接続 | ○ | 6.7.0 以降 | 接続の名前です。 この接続により、プロジェクトとサービス アカウント情報が提供されます。 省略可: マクロ関数 ${conn(connection_name)} を使用します。 |
| データセットのプロジェクト ID | ○ | 6.5.0 | データセットが BigQuery ジョブを実行するプロジェクトとは異なるプロジェクトにある場合は、データセットのプロジェクト ID を入力します。値が指定されていない場合、デフォルトでは、ジョブが実行されるプロジェクト ID が使用されます。 |
| プロジェクト ID | ○ | 6.5.0 | Google Cloud プロジェクト ID。 |
| サービス アカウントの種類 | ○ | 6.5.0 | 次のいずれかのオプションを選択します。
|
| サービス アカウント ファイルのパス | ○ | 6.5.0 | 認証に使用するサービス アカウント キーへのローカル ファイル システム上のパス。Dataproc クラスタで実行する場合は auto-detect に設定されます。他のクラスタで実行する場合、クラスタ内の各ノードにそのファイルが存在する必要があります。デフォルトは auto-detect です。 |
| サービス アカウント JSON | ○ | 6.5.0 | サービス アカウントの JSON ファイルの内容。 |
| 一時バケット名 | ○ | 6.5.0 | 一時データを格納する Cloud Storage バケット。 存在しない場合は自動的に作成されますが、自動的に削除されることはありません。Cloud Storage データは、BigQuery に読み込まれた後に削除されます。この値が指定されていない場合、一意のバケットが作成され、パイプラインの実行が完了すると削除されます。サービス アカウントには、構成されたプロジェクトにバケットを作成する権限が必要です。 |
| ロケーション | ○ | 6.5.0 | BigQuery データセットが作成されるロケーション。
データセットまたは一時バケットがすでに存在する場合、この値は無視されます。デフォルトは US マルチリージョンです。 |
| 暗号鍵の名前 | ○ | 6.5.1/0.18.1 | プラグインによって作成されたバケット、データセット、テーブルに書き込むデータを暗号化する顧客管理の暗号鍵(CMEK)。バケット、データセット、テーブルがすでに存在する場合は、この値は無視されます。 |
| 完了後に BigQuery テーブルを保持する | ○ | 6.5.0 | デバッグと検証の目的で、パイプラインの実行中に作成されたすべての BigQuery 一時テーブルを保持するかどうか。デフォルトは No です。 |
| 一時テーブルの TTL(時間) | ○ | 6.5.0 | BigQuery 一時テーブルのテーブル TTL を時間単位で設定します。これは、パイプラインがキャンセルされ、クリーンアップ プロセスが中断された場合(実行クラスタが突然シャットダウンされた場合など)に、フェイルセーフとして役立ちます。この値を 0 に設定すると、テーブル TTL が無効になります。デフォルトは 72(3 日)です。 |
| ジョブの優先度 | ○ | 6.5.0 | BigQuery ジョブの実行に使用される優先度。次のいずれかのオプションを選択します。
|
| 強制プッシュダウンのステージ | ○ | 6.7.0 | 常に BigQuery で実行されるサポートされているステージ。ホスト名は、それぞれ別の行に入力する必要があります。 |
| プッシュダウンをスキップするステージ | ○ | 6.7.0 | BigQuery で実行されないサポートされているステージ。ホスト名は、それぞれ別の行に入力する必要があります。 |
| BigQuery Storage Read API を使用する | ○ | 6.7.0 | パイプラインの実行中に BigQuery からレコードを抽出する際に BigQuery Storage Read API を使用するかどうか。このオプションを使用すると、変換プッシュダウンのパフォーマンスを向上させることができますが、追加の費用が発生します。これを行うには、実行環境に Scala 2.12 がインストールされている必要があります。 |
ログでパフォーマンスの変化をモニタリングする
パイプラインのランタイム ログには、BigQuery で実行される SQL クエリを示すメッセージが含まれます。パイプラインのどのステージが BigQuery に push されるかをモニタリングできます。
次の例は、パイプラインの実行が開始されたときのログエントリを示しています。ログは、パイプラインの JOIN オペレーションが BigQuery にプッシュダウンされて実行されたことを示しています。
INFO [Driver:i.c.p.g.b.s.BigQuerySQLEngine@190] - Validating join for stage 'Users' can be executed on BigQuery: true
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@131] - Starting push for dataset 'UserProfile'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@131] - Starting push for dataset 'UserDetails'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@292] - Starting join for dataset 'Users'
INFO [Driver:i.c.p.g.b.s.BigQuerySQLEngine@190] - Validating join for stage 'UserPurchases' can be executed on BigQuery: true
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@131] - Starting push for dataset 'Purchases'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@292] - Starting join for dataset 'UserPurchases'
INFO [Driver:i.c.p.g.b.s.BigQuerySQLEngine@190] - Validating join for stage 'MostPopularNames' can be executed on BigQuery: true
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@131] - Starting push for dataset 'FirstNameCounts'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@292] - Starting join for dataset 'MostPopularNames'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@193] - Starting pull for dataset 'MostPopularNames'
次の例は、プッシュダウン実行に関与する各データセットに割り当てられるテーブル名を示しています。
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@145] - Executing Push operation for dataset Purchases stored in table <TABLE_ID>
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@145] - Executing Push operation for dataset UserDetails stored in table <TABLE_ID>
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@145] - Executing Push operation for dataset FirstNameCounts stored in table <TABLE_ID>
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@145] - Executing Push operation for dataset UserProfile stored in table <TABLE_ID>
実行が進むと、ログにプッシュ ステージの完了と、最終的に JOIN オペレーションの実行が表示されます。例:
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@133] - Completed push for dataset 'UserProfile'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@133] - Completed push for dataset 'UserDetails'
DEBUG [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@235] - Executing join operation for dataset Users
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQueryJoinDataset@118] - Creating table `<TABLE_ID>` using job: <JOB_ID> with SQL statement: SELECT `UserDetails`.id AS `id` , `UserDetails`.first_name AS `first_name` , `UserDetails`.last_name AS `last_name` , `UserDetails`.email AS `email` , `UserProfile`.phone AS `phone` , `UserProfile`.profession AS `profession` , `UserProfile`.age AS `age` , `UserProfile`.address AS `address` , `UserProfile`.score AS `score` FROM `your_project.your_dataset.<DATASET_ID>` AS `UserProfile` LEFT JOIN `your_project.your_dataset.<DATASET_ID>` AS `UserDetails` ON `UserProfile`.id = `UserDetails`.id
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQueryJoinDataset@151] - Created BigQuery table `<TABLE_ID>
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@245] - Executed join operation for dataset Users
すべてのステージが完了すると、Pull オペレーションが完了したことを示すメッセージが表示されます。これは、BigQuery エクスポート プロセスがトリガーされ、このエクスポート ジョブの開始後にレコードの読み取りがパイプライン内に入ることを示します。例:
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@196] - Completed pull for dataset 'MostPopularNames'
パイプラインの実行中にエラーが発生した場合は、ログにエラーが記述されます。
リソースの使用率、実行時間、エラーの原因など、BigQuery JOIN オペレーションの実行に関する詳細は、次のジョブ ID を使用して BigQuery ジョブデータを表示できます。これは ジョブのログに表示されます。
パイプラインの指標を確認する
BigQuery で実行されるパイプラインの部分に対して Cloud Data Fusion が提供する指標の詳細については、BigQuery プッシュダウン パイプラインの指標をご覧ください。
次のステップ
- Cloud Data Fusion の Transformation Pushdown の詳細を確認する。