Questa pagina descrive considerazioni e procedure per la migrazione dei dati da un cluster Apache HBase a un'istanza Bigtable suGoogle Cloud.
La procedura descritta in questa pagina richiede di mettere offline l'applicazione. Se vuoi eseguire la migrazione senza tempi di inattività, consulta le indicazioni per la migrazione online in Eseguire la replica da HBase a Bigtable.
Per eseguire la migrazione dei dati a Bigtable da un cluster HBase ospitato su un Google Cloud servizio, come Dataproc o Compute Engine, consulta Migrazione di HBase ospitato su Google Cloud a Bigtable.
Prima di iniziare questa migrazione, devi considerare le implicazioni sul rendimento, la progettazione dello schema Bigtable, l'approccio all'autenticazione e all'autorizzazione e il set di funzionalità Bigtable.
Considerazioni precedenti alla migrazione
Questa sezione suggerisce alcune cose da rivedere e su cui riflettere prima di iniziare la migrazione.
Prestazioni
In un carico di lavoro tipico, Bigtable offre prestazioni altamente prevedibili. Prima di eseguire la migrazione dei dati, assicurati di comprendere i fattori che influiscono sul rendimento di Bigtable.
Progettazione dello schema di Bigtable
Nella maggior parte dei casi, puoi utilizzare lo stesso schema di progettazione in Bigtable come in HBase. Se vuoi modificare lo schema o se il tuo caso d'uso sta cambiando, rivedi i concetti illustrati in Progettazione dello schema prima di eseguire la migrazione dei dati.
Autenticazione e autorizzazione
Prima di progettare controllo dell'accesso per Bigtable, esamina i processi di autenticazione e autorizzazione HBase esistenti.
Bigtable utilizza i meccanismi standard di Google Cloudper l'autenticazione e Identity and Access Management per fornire controllo dell'accesso dell'accesso, quindi devi convertire l'autorizzazione esistente su HBase in IAM. Puoi mappare i gruppi Hadoop esistenti che forniscono meccanismicontrollo dell'accessoo per HBase a service account diversi.
Bigtable ti consente di controllare l'accesso a livello di progetto, istanza e tabella. Per saperne di più, consulta Controllo dell'accesso.
Requisito di tempo di inattività
L'approccio di migrazione descritto in questa pagina prevede la disattivazione dell'applicazione per la durata della migrazione. Se la tua attività non può tollerare tempi di inattività durante la migrazione a Bigtable, consulta le indicazioni per la migrazione online in Eseguire la replica da HBase a Bigtable.
Migrazione di HBase a Bigtable
Per eseguire la migrazione dei dati da HBase a Bigtable, esporta uno snapshot HBase per ogni tabella in Cloud Storage e poi importa i dati in Bigtable. Questi passaggi riguardano un singolo cluster HBase e sono descritti in dettaglio nelle sezioni successive.
- Interrompere l'invio di scritture al cluster HBase.
- Acquisisci snapshot delle tabelle del cluster HBase.
- Esporta i file snapshot in Cloud Storage.
- Calcola gli hash ed esportali in Cloud Storage.
- Crea tabelle di destinazione in Bigtable.
- Importa i dati HBase da Cloud Storage in Bigtable.
- Convalida i dati importati.
- L'itinerario scrive in Bigtable.
Prima di iniziare
Crea un bucket Cloud Storage per archiviare gli snapshot. Crea il bucket nella stessa posizione in cui prevedi di eseguire il job Dataflow.
Crea un'istanza Bigtable per archiviare le nuove tabelle.
Identifica il cluster Hadoop che stai esportando. Puoi eseguire i job per la migrazione direttamente sul cluster HBase o su un cluster Hadoop separato con connettività di rete a Namenode e Datanode del cluster HBase.
Installa e configura il connettore Cloud Storage su ogni nodo del cluster Hadoop, nonché sull'host da cui viene avviato il job. Per i passaggi di installazione dettagliati, consulta Installazione del connettore Cloud Storage.
Apri una shell dei comandi su un host che può connettersi al cluster HBase e al progetto Bigtable. Qui completerai i passaggi successivi.
Scarica lo strumento di traduzione dello schema:
wget BIGTABLE_HBASE_TOOLS_URLSostituisci
BIGTABLE_HBASE_TOOLS_URLcon l'URL dell'ultima versione diJAR with dependenciesdisponibile nel repository Maven dello strumento. Il nome del file è simile ahttps://repo1.maven.org/maven2/com/google/cloud/bigtable/bigtable-hbase-1.x-tools/1.24.0/bigtable-hbase-1.x-tools-1.24.0-jar-with-dependencies.jar.Per trovare l'URL o scaricare manualmente il file JAR:
- Vai al repository.
- Fai clic sul numero di versione più recente.
- Identifica il
JAR with dependencies file(di solito in alto). - Fai clic con il tasto destro del mouse e copia l'URL oppure fai clic per scaricare il file.
Scarica lo strumento di importazione:
wget BIGTABLE_BEAM_IMPORT_URLSostituisci
BIGTABLE_BEAM_IMPORT_URLcon l'URL dell'ultima versione dishaded JARdisponibile nel repository Maven dello strumento. Il nome del file è simile ahttps://repo1.maven.org/maven2/com/google/cloud/bigtable/bigtable-beam-import/1.24.0/bigtable-beam-import-1.24.0-shaded.jar.Per trovare l'URL o scaricare manualmente il file JAR:
- Vai al repository.
- Fai clic sul numero di versione più recente.
- Fai clic su Download.
- Passa il mouse sopra shaded.jar.
- Fai clic con il tasto destro del mouse e copia l'URL oppure fai clic per scaricare il file.
Imposta le seguenti variabili di ambiente:
#Google Cloud export PROJECT_ID=PROJECT_ID export INSTANCE_ID=INSTANCE_ID export REGION=REGION export CLUSTER_NUM_NODES=CLUSTER_NUM_NODES #JAR files export TRANSLATE_JAR=TRANSLATE_JAR export IMPORT_JAR=IMPORT_JAR #Cloud Storage export BUCKET_NAME="gs://BUCKET_NAME" export MIGRATION_DESTINATION_DIRECTORY="$BUCKET_NAME/hbase-migration-snap" #HBase export ZOOKEEPER_QUORUM=ZOOKEPER_QUORUM export ZOOKEEPER_PORT=2181 export ZOOKEEPER_QUORUM_AND_PORT="$ZOOKEEPER_QUORUM:$ZOOKEEPER_PORT" export MIGRATION_SOURCE_DIRECTORY=MIGRATION_SOURCE_DIRECTORYSostituisci quanto segue:
PROJECT_ID: il Google Cloud progetto in cui si trova l'istanzaINSTANCE_ID: l'identificatore dell'istanza Bigtable in cui importare i datiREGION: una regione che contiene uno dei cluster nella tua istanza Bigtable. Esempio:northamerica-northeast2CLUSTER_NUM_NODES: il numero di nodi nell'istanza BigtableTRANSLATE_JAR: il nome e il numero di versione del file JARbigtable hbase toolsche hai scaricato da Maven. Il valore dovrebbe avere un aspetto simile abigtable-hbase-1.x-tools-1.24.0-jar-with-dependencies.jar.IMPORT_JAR: il nome e il numero di versione del file JARbigtable-beam-importche hai scaricato da Maven. Il valore dovrebbe avere un aspetto simile abigtable-beam-import-1.24.0-shaded.jar.BUCKET_NAME: il nome del bucket Cloud Storage in cui memorizzi gli snapshotZOOKEEPER_QUORUM: l'host Zookeeper a cui si connetterà lo strumento, nel formatohost1.myownpersonaldomain.comMIGRATION_SOURCE_DIRECTORY: la directory sull'host HBase che contiene i dati che vuoi migrare, nel formatohdfs://host1.myownpersonaldomain.com:8020/hbase
(Facoltativo) Per verificare che le variabili siano impostate correttamente, esegui il comando
printenvper visualizzare tutte le variabili di ambiente.
Interrompere l'invio di scritture a HBase
Prima di acquisire snapshot delle tabelle HBase, interrompi l'invio di scritture al cluster HBase.
Acquisire snapshot delle tabelle HBase
Quando il cluster HBase non acquisisce più dati, crea uno snapshot di ogni tabella che prevedi di migrare a Bigtable.
Inizialmente, uno snapshot ha un footprint di archiviazione minimo sul cluster HBase, ma nel tempo potrebbe raggiungere le stesse dimensioni della tabella originale. Lo snapshot non consuma risorse della CPU.
Esegui il seguente comando per ogni tabella, utilizzando un nome univoco per ogni snapshot:
echo "snapshot 'TABLE_NAME', 'SNAPSHOT_NAME'" | hbase shell -n
Sostituisci quanto segue:
TABLE_NAME: il nome della tabella HBase da cui esporti i dati.SNAPSHOT_NAME: il nome del nuovo snapshot
Esporta gli snapshot HBase in Cloud Storage
Dopo aver creato gli snapshot, devi esportarli. Quando esegui job di esportazione su un cluster HBase di produzione, monitora il cluster e altre risorse HBase per assicurarti che i cluster rimangano in buono stato.
Per ogni istantanea che vuoi esportare, esegui il seguente comando:
hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot \
-Dhbase.zookeeper.quorum=$ZOOKEEPER_QUORUM_AND_PORT -snapshot SNAPSHOT_NAME \
-copy-from $MIGRATION_SOURCE_DIRECTORY \
-copy-to $MIGRATION_DESTINATION_DIRECTORY/data
Sostituisci SNAPSHOT_NAME con il nome dello snapshot da
esportare.
Calcolare ed esportare gli hash
Successivamente, crea hash da utilizzare per la convalida al termine della migrazione.
HashTable è uno strumento di convalida fornito da HBase che calcola gli hash per gli intervalli di righe e li esporta in file. Puoi eseguire un job sync-table sulla tabella di destinazione per confrontare gli hash e avere la certezza dell'integrità dei dati migrati.
Esegui il comando seguente per ogni tabella esportata:
hbase org.apache.hadoop.hbase.mapreduce.HashTable --batchsize=32000 --numhashfiles=20 \
TABLE_NAME $MIGRATION_DESTINATION_DIRECTORY/hashtable/TABLE_NAME
Sostituisci quanto segue:
TABLE_NAME: il nome della tabella HBase per cui hai creato uno snapshot ed esportato
Crea tabelle di destinazione
Il passaggio successivo consiste nel creare una tabella di destinazione nell'istanza Bigtable per ogni snapshot esportato. Utilizza un account con
l'autorizzazione bigtable.tables.create per l'istanza.
Questa guida utilizza lo
strumento di traduzione dello schema Bigtable,
che crea automaticamente la tabella. Tuttavia, se non vuoi che lo schema Bigtable corrisponda esattamente allo schema HBase, puoi creare una tabella utilizzando lo strumento a riga di comando cbt o la console Google Cloud .
Lo strumento di traduzione dello schema Bigtable acquisisce lo schema della tabella HBase, inclusi il nome della tabella, le famiglie di colonne, i criteri di garbage collection e le suddivisioni. Poi crea una tabella simile in Bigtable.
Per ogni tabella che vuoi importare, esegui il comando seguente per copiare lo schema da HBase a Bigtable.
java \
-Dgoogle.bigtable.project.id=$PROJECT_ID \
-Dgoogle.bigtable.instance.id=$INSTANCE_ID \
-Dgoogle.bigtable.table.filter=TABLE_NAME \
-Dhbase.zookeeper.quorum=$ZOOKEEPER_QUORUM \
-Dhbase.zookeeper.property.clientPort=$ZOOKEEPER_PORT \
-jar $TRANSLATE_JAR
Sostituisci TABLE_NAME con il nome della tabella HBase
che stai importando. Lo strumento di traduzione dello schema utilizza questo nome per la nuova tabella Bigtable.
Se vuoi, puoi anche sostituire TABLE_NAME con un'espressione regolare, ad esempio ".*", che acquisisce tutte le tabelle che vuoi creare, quindi esegui il comando una sola volta.
Importa i dati HBase in Bigtable utilizzando Dataflow
Una volta che hai una tabella pronta per la migrazione dei dati, puoi importare e convalidare i dati.
Tabelle non compresse
Se le tabelle HBase non sono compresse, esegui il seguente comando per ogni tabella di cui vuoi eseguire la migrazione:
java -jar $IMPORT_JAR importsnapshot \
--runner=DataflowRunner \
--project=$PROJECT_ID \
--bigtableInstanceId=$INSTANCE_ID \
--bigtableTableId=TABLE_NAME \
--hbaseSnapshotSourceDir=$MIGRATION_DESTINATION_DIRECTORY/data \
--snapshotName=SNAPSHOT_NAME \
--stagingLocation=$MIGRATION_DESTINATION_DIRECTORY/staging \
--tempLocation=$MIGRATION_DESTINATION_DIRECTORY/temp \
--maxNumWorkers=$(expr 3 \* $CLUSTER_NUM_NODES) \
--region=$REGION
Sostituisci quanto segue:
TABLE_NAME: il nome della tabella HBase che stai importando. Lo strumento di traduzione dello schema utilizza questo nome per la nuova tabella Bigtable. I nuovi nomi delle tabelle non sono supportati.SNAPSHOT_NAME: il nome che hai assegnato allo snapshot della tabella che stai importando
Dopo aver eseguito il comando, lo strumento ripristina lo snapshot HBase nel bucket Cloud Storage, quindi avvia il job di importazione. Il completamento della procedura di ripristino dello snapshot può richiedere diversi minuti, a seconda delle dimensioni dello snapshot.
Tieni presente i seguenti suggerimenti durante l'importazione:
- Per migliorare il rendimento del caricamento dei dati, assicurati di impostare
maxNumWorkers. Questo valore contribuisce a garantire che il job di importazione disponga di una potenza di calcolo sufficiente per essere completato in un periodo di tempo ragionevole, ma non così elevata da sovraccaricare l'istanza Bigtable.- Se non utilizzi l'istanza Bigtable anche per un altro carico di lavoro, moltiplica il numero di nodi nell'istanza Bigtable per 3 e utilizza questo numero per
maxNumWorkers. - Se utilizzi l'istanza per un altro carico di lavoro contemporaneamente all'importazione dei dati HBase, riduci il valore di
maxNumWorkersin modo appropriato.
- Se non utilizzi l'istanza Bigtable anche per un altro carico di lavoro, moltiplica il numero di nodi nell'istanza Bigtable per 3 e utilizza questo numero per
- Utilizza il tipo di worker predefinito.
- Durante l'importazione, devi monitorare l'utilizzo della CPU dell'istanza Bigtable. Se l'utilizzo della CPU nell'istanza Bigtable è troppo elevato, potresti dover aggiungere altri nodi. Possono essere necessari fino a 20 minuti prima che il cluster fornisca il vantaggio in termini di prestazioni dei nodi aggiuntivi.
Per ulteriori informazioni sul monitoraggio dell'istanza Bigtable, consulta Monitoraggio.
Tabelle compresse con Snappy
Se importi tabelle compresse con Snappy, devi utilizzare un'immagine container personalizzata nella pipeline Dataflow. L'immagine container personalizzata che utilizzi per importare dati compressi in Bigtable fornisce il supporto della libreria di compressione nativa di Hadoop. Per utilizzare Dataflow Runner v2, devi disporre dell'SDK Apache Beam versione 2.30.0 o successive e della versione 2.3.0 o successive della libreria client HBase per Java.
Per importare tabelle compresse con Snappy, esegui lo stesso comando che esegui per le tabelle non compresse, ma aggiungi la seguente opzione:
--enableSnappy=true
Convalida i dati importati in Bigtable
Per convalidare i dati importati, devi eseguire il job sync-table. Il job
sync-table calcola gli hash per gli intervalli di righe in Bigtable,
poi li confronta con l'output di HashTable che hai calcolato in precedenza.
Per eseguire il job sync-table, esegui questo comando nella shell dei comandi:
java -jar $IMPORT_JAR sync-table \
--runner=dataflow \
--project=$PROJECT_ID \
--bigtableInstanceId=$INSTANCE_ID \
--bigtableTableId=TABLE_NAME \
--outputPrefix=$MIGRATION_DESTINATION_DIRECTORY/sync-table/output-TABLE_NAME-$(date +"%s") \
--stagingLocation=$MIGRATION_DESTINATION_DIRECTORY/sync-table/staging \
--hashTableOutputDir=$MIGRATION_DESTINATION_DIRECTORY/hashtable/TABLE_NAME \
--tempLocation=$MIGRATION_DESTINATION_DIRECTORY/sync-table/dataflow-test/temp \
--region=$REGION
Sostituisci TABLE_NAME con il nome della tabella HBase
che stai importando.
Al termine del job sync-table, apri la pagina Dettagli job Dataflow e
controlla la sezione Contatori personalizzati per il job. Se il job di importazione
importa correttamente tutti i dati, il valore di ranges_matched è
un valore e quello di ranges_not_matched è 0.
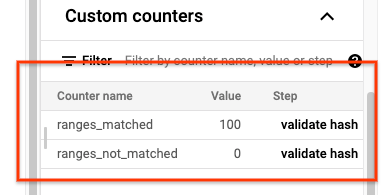
Se ranges_not_matched mostra un valore, apri la pagina Log, scegli
Log dei worker e filtra per Mancata corrispondenza nell'intervallo. L'output leggibile
dalle macchine di questi log viene archiviato in Cloud Storage nella destinazione
di output che crei nell'opzione outputPrefix sync-table.
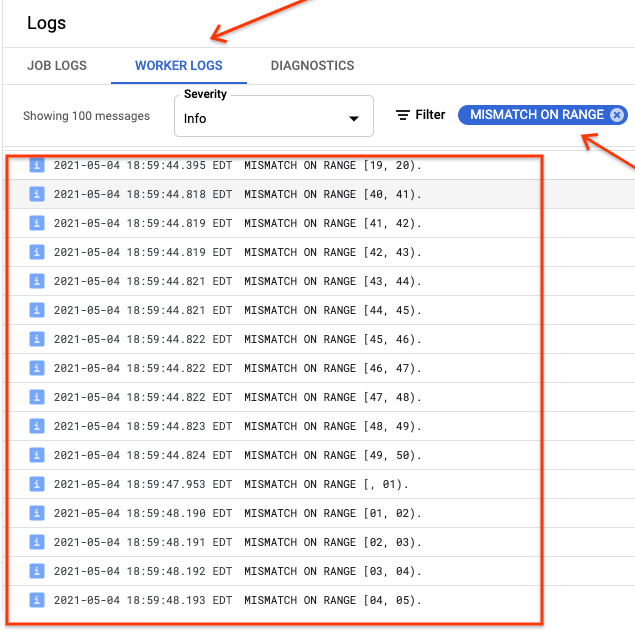
Puoi riprovare il job di importazione o scrivere uno script per leggere i file di output e determinare dove si sono verificate le mancate corrispondenze. Ogni riga nel file di output è un record JSON serializzato di un intervallo non corrispondente.
Il percorso scrive in Bigtable
Dopo aver convalidato i dati per ogni tabella del cluster, puoi configurare le applicazioni per indirizzare tutto il traffico a Bigtable, quindi ritirare l'istanza HBase.
Al termine della migrazione, puoi eliminare gli snapshot nell'istanza HBase.
Passaggi successivi
- Scopri di più su Cloud Storage.