語音轉錄功能可將串流音訊資料即時轉換為轉錄文字。Agent Assist 會根據文字提供建議,因此必須先轉換音訊資料才能使用。您也可以搭配 Conversational Insights 使用轉錄的串流音訊,即時收集有關服務專員對話的資料 (例如主題建模)。
如要轉錄串流音訊以搭配 Agent Assist 使用,有兩種方法:使用 SIPREC 功能,或以音訊資料做為酬載發出 gRPC 呼叫。本頁說明如何使用 gRPC 呼叫轉錄串流音訊資料。
語音轉錄功能會使用 Speech-to-Text 串流語音辨識。 Speech-to-Text 提供多種辨識模型,包括標準版和強化版。語音轉錄功能僅支援 GA 層級,且必須搭配電話模型使用。
必要條件
- 在 中建立專案。Google Cloud
- 啟用 Dialogflow API。
- 請與 Google 代表聯絡,確認您的帳戶有權存取語音轉文字強化模型。
建立對話設定檔
如要建立對話設定檔,請使用 Agent Assist 控制台,或直接在 ConversationProfile 資源上呼叫 create 方法。
如要進行語音轉錄,建議您在對話中傳送音訊資料時,將 ConversationProfile.stt_config 設為預設 InputAudioConfig。
![]()
在對話執行階段取得轉錄稿
如要在對話執行階段取得轉錄稿,您需要為對話建立參與者,並傳送每位參與者的音訊資料。
建立參與者
參與者分為三種類型。如要進一步瞭解這些角色的詳細資訊,請參閱參考說明文件。在 participant 上呼叫 create 方法,然後指定 role。只有END_USER或HUMAN_AGENT參與者可以撥打StreamingAnalyzeContent,這是取得轉錄稿的必要條件。
傳送音訊資料並取得轉錄稿
您可以使用 StreamingAnalyzeContent 將參與者的音訊傳送至 Google 並取得轉錄稿,並使用下列參數:
串流中的第一個要求必須是
InputAudioConfig。(這裡設定的欄位會覆寫ConversationProfile.stt_config中的對應設定。) 請勿傳送任何音訊輸入內容,直到第二個要求為止。audioEncoding必須設為AUDIO_ENCODING_LINEAR_16或AUDIO_ENCODING_MULAW。model:這是要用於轉錄音訊的 Speech-to-Text 模型。將這個欄位設為telephony。變體不會影響轉錄品質,因此您可以保留未指定的語音模型變體,或選擇「使用最佳可用變體」。singleUtterance應設為false,才能獲得最佳轉錄品質。如果singleUtterance為false,則不應預期END_OF_SINGLE_UTTERANCE,但您可以在StreamingAnalyzeContentResponse.recognition_result內依附isFinal==true,以半關閉串流。- 選用其他參數:下列參數為選用。如要存取這些參數,請與您的 Google 代表聯絡。
languageCode:音訊的language_code。預設值為en-US。alternativeLanguageCodes:這是預先發布版功能。 音訊中可能偵測到的其他語言。 Agent Assist 會使用language_code欄位,在音訊開頭自動偵測語言,並在後續所有對話回合中預設使用該語言。alternativeLanguageCodes欄位可讓您指定更多選項,供 Agent Assist 選擇。phraseSets:Speech-to-Text 模型改編phraseSet資源名稱。如要搭配語音轉錄使用模型調整功能,請先使用 Speech-to-Text API 建立phraseSet,然後在此指定資源名稱。
傳送含有音訊酬載的第二個要求後,您應該會開始從串流接收一些
StreamingAnalyzeContentResponses。- 當您看到
is_final設為true時,可以半關閉串流 (或停止以某些語言 (例如 Python) 傳送StreamingAnalyzeContentResponse.recognition_result)。 - 半關閉串流後,伺服器會傳回包含最終轉錄稿的回應,以及可能的 Dialogflow 建議或 Agent Assist 建議。
- 當您看到
最終轉錄稿會顯示在下列位置:
StreamingAnalyzeContentResponse.message.content。- 如果啟用 Pub/Sub 通知,您也可以在 Pub/Sub 中查看轉錄稿。
關閉先前的串流後,再開始新的串流。
- 重新傳送音訊:系統會根據新串流的開始時間,重新傳送上次回應
speech_end_offset後產生的音訊資料,以確保StreamingAnalyzeContent轉錄品質。is_final=true
- 重新傳送音訊:系統會根據新串流的開始時間,重新傳送上次回應
下圖說明串流的運作方式。
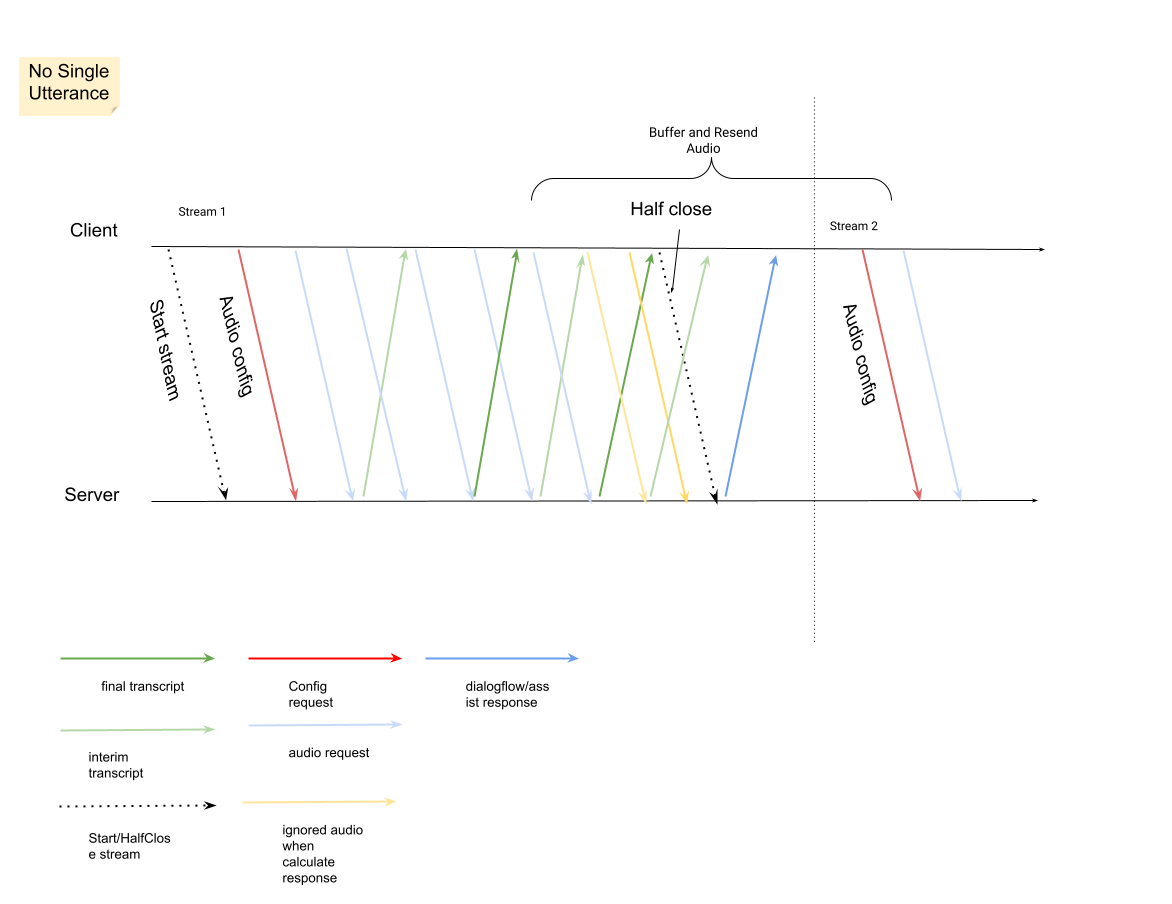
串流辨識要求程式碼範例
下列程式碼範例說明如何傳送串流轉錄要求:
Python
如要向 Agent Assist 進行驗證,請設定應用程式預設憑證。 詳情請參閱「為本機開發環境設定驗證」。