CCAI 转写功能可让您实时将流式音频数据转换为转写文本。Agent Assist 会根据文本提供建议,因此必须先转换音频数据,然后才能使用。您还可以将转写的流式音频与 CCAI Insights 搭配使用,以收集有关客服人员对话的实时数据(例如主题建模)。
您可以通过以下两种方式转写流式音频以用于 CCAI:使用 SIPREC 功能,或通过将音频数据作为载荷进行 gRPC 调用。本页面介绍了如何使用 gRPC 调用转录流式音频数据。
CCAI 转写功能使用 Speech-to-Text 流式语音识别。Speech-to-Text 提供多种识别模型,包括标准模型和增强型模型。只有在与增强型手机通话模型搭配使用时,CCAI 转写功能才在正式版 (GA) 级别受支持。
前提条件
- 在 Google Cloud中创建项目。
- 启用 Dialogflow API。
- 请与您的 Google 代表联系,确保您的账号有权访问增强版语音转写模型。
创建对话配置文件
如需创建对话配置文件,请使用 Agent Assist 控制台或直接对 ConversationProfile 资源调用 create 方法。
对于 CCAI 转写,我们建议您在对话中发送音频数据时,将 ConversationProfile.stt_config 配置为默认 InputAudioConfig。
![]()
在对话运行时获取转录
如需在对话运行时获取转写,您需要为对话创建参与者,并为每个参与者发送音频数据。
创建参与者
参与者分为三种类型。
如需详细了解这些角色的作用,请参阅参考文档。对 participant 调用 create 方法并指定 role。只有 END_USER 或 HUMAN_AGENT 参与者才能调用 StreamingAnalyzeContent,而这是获取转写内容所必需的。
发送音频数据并获取转写内容
您可以使用 StreamingAnalyzeContent 将参与者的音频发送给 Google 并获取转写内容,并使用以下参数:
数据流中的第一个请求必须是
InputAudioConfig。(此处配置的字段会替换ConversationProfile.stt_config中的相应设置。)在第二个请求之前,请勿发送任何音频输入。audioEncoding需要设置为AUDIO_ENCODING_LINEAR_16或AUDIO_ENCODING_MULAW。model:这是您要用于转写音频的 Speech-to-Text 模型。 将此字段设置为telephony。变体不会影响转写质量,因此您可以不指定语音模型变体,也可以选择使用最佳可用变体。- 应将
singleUtterance设置为false,以获得最佳转写质量。如果singleUtterance为false,则不应预期END_OF_SINGLE_UTTERANCE,但可以依赖StreamingAnalyzeContentResponse.recognition_result内的isFinal==true来半关闭流。 - 可选的其他参数:以下参数是可选的。如需获取这些参数的访问权限,请与您的 Google 代表联系。
languageCode:音频的language_code。默认值为en-US。alternativeLanguageCodes:音频中可能检测到的其他语言。Agent Assist 使用language_code字段在音频开始时自动检测语言,并在所有后续对话轮次中坚持使用该语言。借助alternativeLanguageCodes字段,您可以为 Agent Assist 指定更多选项供其选择。phraseSets:Speech-to-Text 模型自适应phraseSet资源名称。如需将模型自适应与 CCAI 转写搭配使用,您必须先使用 Speech-to-Text API 创建phraseSet,并在此处指定资源名称。
在发送包含音频载荷的第二个请求后,您应该开始从数据流中接收一些
StreamingAnalyzeContentResponses。- 当您看到
StreamingAnalyzeContentResponse.recognition_result中的is_final设置为true时,可以半关闭流(或在某些语言(如 Python)中停止发送)。 - 在您半关闭流后,服务器会发回包含最终转写的响应,以及可能的 Dialogflow 建议或 Agent Assist 建议。
- 当您看到
您可以在以下位置找到最终转写内容:
StreamingAnalyzeContentResponse.message.content。- 如果您启用 Pub/Sub 通知,还可以在 Pub/Sub 中查看转写内容。
在上一个数据流关闭后,启动新的数据流。
- 音频重新发送:在包含
is_final=true的响应的最后speech_end_offset之后生成,且从新数据流开始时间到结束时间的音频数据需要重新发送到StreamingAnalyzeContent,以获得最佳转写质量。
- 音频重新发送:在包含
下图展示了流的工作方式。
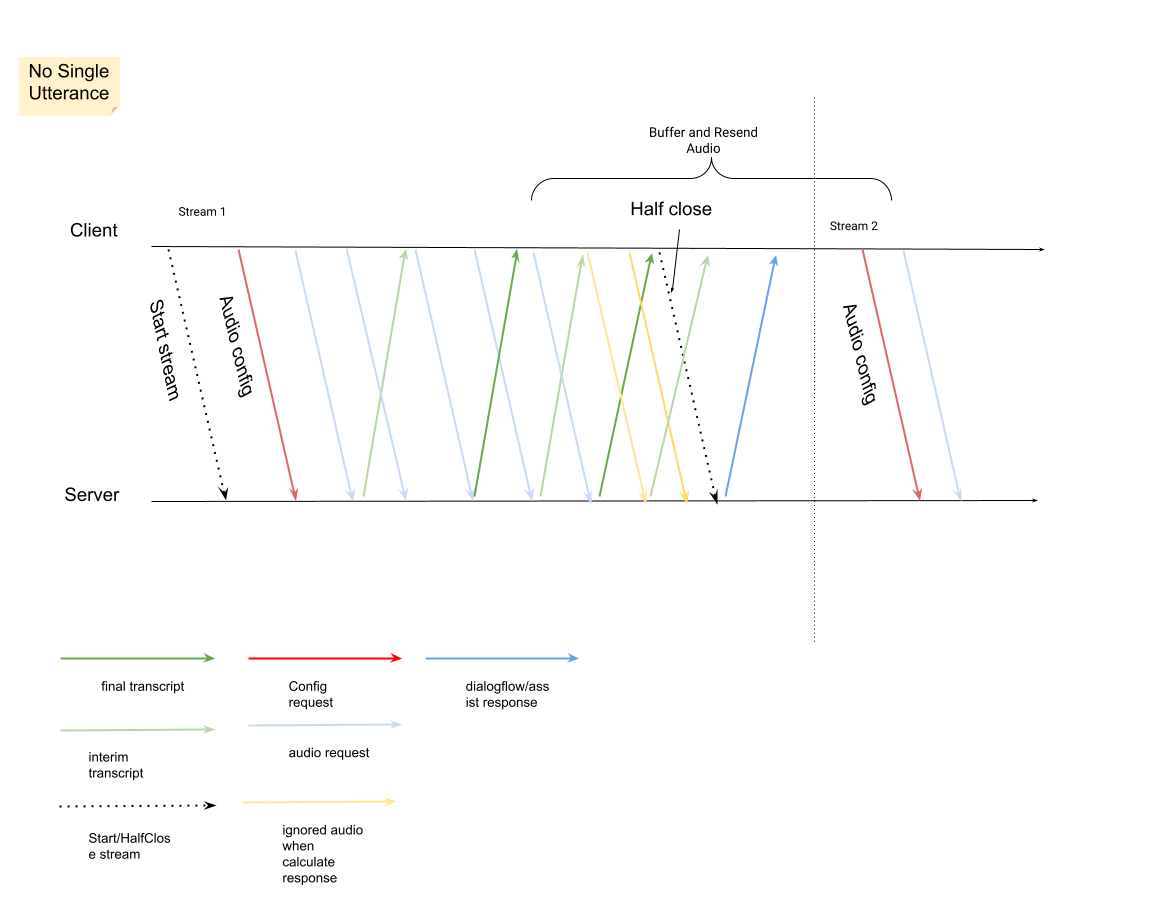
流式识别请求代码示例
以下代码示例演示了如何发送流式转写请求:
Python
如需向 Agent Assist 进行身份验证,请设置应用默认凭据。 如需了解详情,请参阅为本地开发环境设置身份验证。