In diesem Dokument wird beschrieben, wie Sie Google Cloud Managed Service for Prometheus mit verwalteter Erfassung einrichten. Die Einrichtung ist ein minimales Beispiel für eine funktionierende Aufnahme, bei der eine Prometheus-Bereitstellung verwendet wird, die eine Beispielanwendung überwacht und erfasste Messwerte in Monarch speichert.
Dieses Dokument enthält Anleitungen für folgende Aufgaben:
- Umgebung und Befehlszeilentools einrichten
- Verwaltete Erfassung für Ihren Cluster einrichten
- Ressource für das Ziel-Scraping und die Messwertaufnahme konfigurieren
- Vorhandene benutzerdefinierte prometheus-operator-Ressourcen migrieren
Wir empfehlen die Verwendung der verwalteten Erfassung. Sie vereinfacht die Bereitstellung, Skalierung, Fragmentierung, Konfiguration und Wartung der Collectors. Die verwaltete Sammlung wird für GKE und alle anderen Kubernetes-Umgebungen unterstützt.
Die verwaltete Sammlung führt Prometheus-basierte Collector als Daemonset aus und sorgt für Skalierbarkeit, indem nur Ziele auf gemeinsamen Knoten extrahiert werden. Sie konfigurieren die Collectors mit einfachen benutzerdefinierten Ressourcen, um Exporteure mithilfe der Pull-Sammlung zu extrahieren. Anschließend erfassen die Collectors die extrahierten Daten per Push im zentralen Datenspeicher in Monarch. Google Cloud greift nie direkt auf Ihren Cluster zu, um Messwertdaten abzurufen oder zu extrahieren. Ihre Collectors übertragen Daten anGoogle Cloud. Weitere Informationen zur verwalteten und selbst bereitgestellten Datenerfassung finden Sie unter Datenerfassung mit verwaltetem Dienst für Prometheus und Aufnahme und Abfrage mit verwalteter und selbst bereitgestellter Sammlung.
Vorbereitung
In diesem Abschnitt wird die Konfiguration beschrieben, die für die in diesem Dokument beschriebenen Aufgaben erforderlich ist.
Projekte und Tools einrichten
Zum Verwenden von Google Cloud Managed Service for Prometheus benötigen Sie folgende Ressourcen:
Ein Google Cloud -Projekt mit aktivierter Cloud Monitoring API.
Wenn Sie kein Google Cloud -Projekt haben, gehen Sie so vor:
Wechseln Sie in der Google Cloud -Console zu Neues Projekt:
Geben Sie im Feld Projektname einen Namen für Ihr Projekt ein und klicken Sie dann auf Erstellen.
Wechseln Sie zu Billing (Abrechnung):
Wählen Sie das Projekt aus, das Sie gerade erstellt haben, falls es nicht bereits oben auf der Seite ausgewählt wurde.
Sie werden aufgefordert, ein vorhandenes Zahlungsprofil auszuwählen oder ein neues Zahlungsprofil zu erstellen.
Die Monitoring API ist für neue Projekte standardmäßig aktiviert.
Wenn Sie bereits ein Google Cloud -Projekt haben, muss die Monitoring API aktiviert sein:
Gehen Sie zu APIs & Dienste:
Wählen Sie Ihr Projekt aus.
Klicken Sie auf APIs und Dienste aktivieren.
Suchen Sie nach „Monitoring“.
Klicken Sie in den Suchergebnissen auf "Cloud Monitoring API".
Wenn "API aktiviert" nicht angezeigt wird, klicken Sie auf die Schaltfläche Aktivieren.
Einen Kubernetes-Cluster. Wenn Sie keinen Kubernetes-Cluster haben, folgen Sie der Anleitung in der Kurzanleitung für GKE.
Sie benötigen außerdem die folgenden Befehlszeilentools:
gcloudkubectl
Die Tools gcloud und kubectl sind Teil der Google Cloud CLI. Informationen zur Installation finden Sie unter Komponenten der Google Cloud-Befehlszeile verwalten. Führen Sie den folgenden Befehl aus, um die installierten gloud CLI-Komponenten aufzurufen:
gcloud components list
Konfigurierung Ihrer Umgebung
Führen Sie die folgende Konfiguration aus, um zu vermeiden, dass Sie Ihre Projekt-ID oder den Clusternamen wiederholt eingeben müssen:
Konfigurieren Sie die Befehlszeilentools so:
Konfigurieren Sie die gcloud CLI so, dass sie auf die ID IhresGoogle Cloud -Projekts verweist:
gcloud config set project PROJECT_ID
Konfigurieren Sie die
kubectl-Befehlszeile für die Verwendung Ihres Clusters:kubectl config set-cluster CLUSTER_NAME
Weitere Informationen zu diesen Tools finden Sie hier:
Namespace einrichten
Erstellen Sie den Kubernetes-Namespace NAMESPACE_NAME für Ressourcen, die Sie als Teil der Beispielanwendung erstellen:
kubectl create ns NAMESPACE_NAME
Verwaltete Erfassung einrichten
Sie können die verwaltete Erfassung sowohl auf GKE- als auch auf Nicht-GKE-Kubernetes-Clustern verwenden.
Nachdem die verwaltete Erfassung aktiviert wurde, werden die clusterinternen Komponenten ausgeführt aber es werden noch keine Messwerte generiert. Diese Komponenten werden von PodMonitoring- oder ClusterPodMonitoring-Ressourcen benötigt, um die Messwertendpunkte ordnungsgemäß zu extrahieren. Sie müssen entweder diese Ressourcen mit gültigen Messwertendpunkten bereitstellen oder eines der in GKE integrierten verwalteten Messwertpakete aktivieren, z. B. Kube-Statusmesswerte. Informationen zur Fehlerbehebung finden Sie unter Probleme mit der Datenaufnahme.
Wenn Sie die verwaltete Sammlung aktivieren, werden folgende Komponenten in Ihrem Cluster installiert:
- Das
gmp-operator-Deployment, das den Kubernetes-Operator für Managed Service for Prometheus bereitstellt. - Das
rule-evaluator-Deployment, das zum Konfigurieren und Ausführen von Benachrichtigungen- und Aufzeichnungsregeln genutzt wird. - Das
collector-DaemonSet, das die Sammlung horizontal skaliert, indem Messwerte nur aus Pods extrahiert werden, die auf demselben Knoten wie jeder einzelne Collector ausgeführt werden. - Das StatefulSet
alertmanager, das zum Senden von ausgelösten Benachrichtigungen an Ihre bevorzugten Benachrichtigungskanäle konfiguriert ist.
Eine Referenzdokumentation zum Operator des Verwalteten Diensts für Prometheus finden Sie auf der Seite „Manifeste“.
Verwaltete Erfassung aktivieren: GKE
Die verwaltete Erfassung ist standardmäßig für Folgendes aktiviert:
GKE Autopilot-Cluster mit GKE-Version 1.25 oder höher.
GKE Standard-Clustern mit GKE-Version 1.27 oder höher. Sie können diese Standardeinstellung beim Erstellen des Clusters überschreiben; siehe Verwalteten Erfassung deaktivieren.
Bei Ausführung in einer GKE-Umgebung, die die verwaltete Sammlung nicht standardmäßig aktiviert hat, sehen sie Verwaltete Sammlung manuell aktivieren
Die verwaltete Erfassung in GKE wird automatisch aktualisiert, wenn neue Clusterkomponenten veröffentlicht werden.
Die verwaltete Sammlung in GKE verwendet Berechtigungen, die dem Standard-Compute Engine-Dienstkonto gewährt wurden. Wenn Sie eine Richtlinie haben, die das
Standardberechtigungen für das Standardknotendienstkonto verändern, müssen Sie möglicherweise
die Rolle Monitoring Metric Writer hinzufügen, um fortzufahren.
Verwaltete Sammlung manuell aktivieren
Bei Ausführung in einer GKE-Umgebung, in der keine standardmäßige Aktivierung von verwaltete Sammlung erfolgt, können Sie die verwaltete Sammlung so aktivieren:
- Das Dashboard Bulk-Aktivierung von verwalteten Prometheus-Clustern in Cloud Monitoring.
- Die Seite Kubernetes Engine in der Google Cloud Console.
- Google Cloud CLI. Zur Verwendung der gcloud-Befehlszeile müssen Sie die GKE-Version 1.21.4-gke.300 oder höher ausführen.
Terraform für Google Kubernetes Engine Wenn Sie Terraform verwenden möchten, um Managed Service for Prometheus zu aktivieren, müssen Sie die GKE-Version 1.21.4-gke.300 oder höher ausführen.
Dashboard „Bulk-Aktivierung von verwalteten Prometheus-Clustern“
Mit dem Dashboard Bulk-Aktivierung von verwalteten Prometheus-Clustern in Cloud Monitoring können Sie Folgendes tun:
- Ermitteln Sie, ob Managed Service for Prometheus auf Ihrem Clustern aktiviert ist und ob Sie eine verwaltete oder selbst bereitgestellte Sammlung verwenden.
- Verwaltete Erfassung für Cluster in Ihrem Projekt aktivieren
- Andere Informationen zu Ihren Clustern ansehen
So rufen Sie das Dashboard Bulk-Aktivierung von verwalteten Prometheus-Clustern auf:
-
Öffnen Sie in der Google Cloud Console die Seite Dashboards
 :
:
Wenn Sie diese Seite über die Suchleiste suchen, wählen Sie das Ergebnis aus, dessen Zwischenüberschrift Monitoring ist.
Suchen Sie in der Filterleiste nach dem Eintrag Bulk-Aktivierung von verwalteten Prometheus-Clustern und wählen Sie ihn aus.
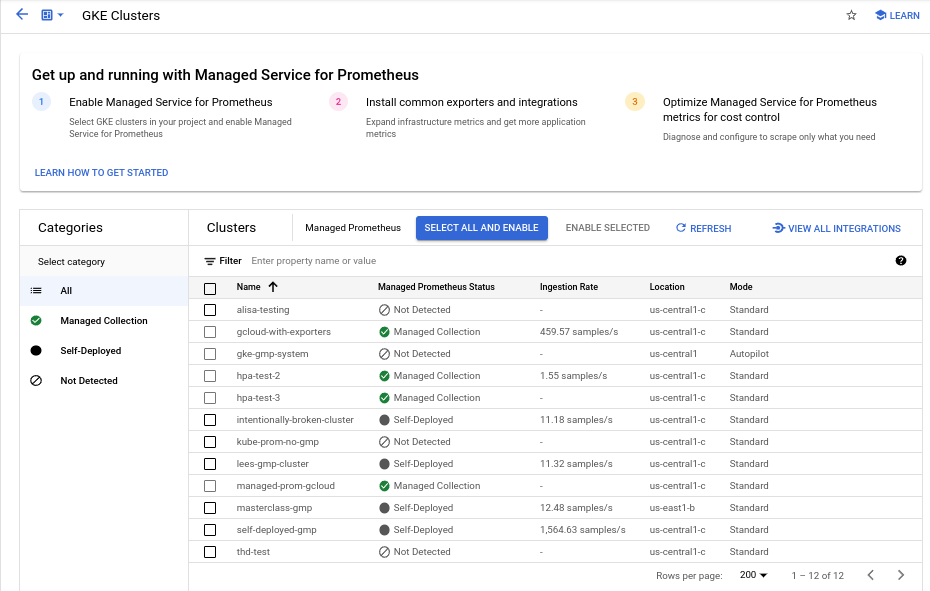
So aktivieren Sie die verwaltete Sammlung auf einem oder mehreren GKE-Clustern über das Dashboard Bulk-Aktivierung von verwalteten Prometheus-Clustern:
Klicken Sie auf das Kästchen für jeden GKE-Cluster, für den Sie die verwaltete Sammlung aktivieren möchten.
Wählen Sie Auswahl aktivieren aus.
Kubernetes Engine-UI
Mit der Google Cloud Console können Sie Folgendes tun:
- Die verwaltete Erfassung in einem vorhandenen GKE-Cluster aktivieren.
- Einen neuen GKE-Cluster mit aktivierter verwalteter Erfassung erstellen.
So aktualisieren Sie einen vorhandenen Cluster:
-
Rufen Sie in der Google Cloud Console die Seite Kubernetes-Cluster auf:
Wenn Sie diese Seite über die Suchleiste finden, wählen Sie das Ergebnis aus, dessen Zwischenüberschrift Kubernetes Engine lautet.
Klicken Sie auf den Namen des Clusters.
Suchen Sie in der Liste Features die Option Verwalteter Dienst für Prometheus. Wenn es als deaktiviert aufgeführt ist, klicken Sie auf edit Bearbeiten und wählen Sie dann Verwalteten Dienst für Prometheus aktivieren aus.
Klicken Sie auf Änderungen speichern.
So erstellen Sie einen Cluster mit aktivierter verwalteter Erfassung:
-
Rufen Sie in der Google Cloud Console die Seite Kubernetes-Cluster auf:
Wenn Sie diese Seite über die Suchleiste finden, wählen Sie das Ergebnis aus, dessen Zwischenüberschrift Kubernetes Engine lautet.
Klicken Sie auf Erstellen.
Klicken Sie für die Option Standard auf Konfigurieren.
Klicken Sie im Navigationsbereich auf Features.
Wählen Sie im Abschnitt Vorgänge die Option Verwalteten Dienst für Prometheus aktivieren aus.
Klicken Sie auf Speichern.
gcloud-CLI
Mit der gcloud CLI können Sie Folgendes tun:
- Die verwaltete Erfassung in einem vorhandenen GKE-Cluster aktivieren.
- Einen neuen GKE-Cluster mit aktivierter verwalteter Erfassung erstellen.
Die Verarbeitung dieser Befehle kann bis zu fünf Minuten dauern.
Legen Sie zuerst Ihr Projekt fest:
gcloud config set project PROJECT_ID
Führen Sie zum Aktualisieren eines vorhandenen Clusters einen der folgenden update-Befehle aus, je nachdem, ob Ihr Cluster zonal oder regional ist:
gcloud container clusters update CLUSTER_NAME --enable-managed-prometheus --zone ZONE
gcloud container clusters update CLUSTER_NAME --enable-managed-prometheus --region REGION
Führen Sie den folgenden Befehl aus, um einen Cluster mit aktivierter verwalteter Erfassung zu erstellen:
gcloud container clusters create CLUSTER_NAME --zone ZONE --enable-managed-prometheus
GKE Autopilot
Die verwaltete Erfassung ist in GKE Autopilot-Clustern mit GKE-Version 1.25 oder höher standardmäßig aktiviert. Sie können die verwaltete Erfassung nicht deaktivieren.
Wenn Ihr Cluster die verwaltete Sammlung beim Upgrade auf Version 1.25 nicht automatisch aktiviert, können Sie dies manuell aktivieren. Führen Sie dazu den Aktualisierungsbefehl im Abschnitt der gcloud CLI aus.
Terraform
Eine Anleitung zum Konfigurieren der verwalteten Erfassung mit Terraform finden Sie in der Terraform-Registry für google_container_cluster.
Allgemeine Informationen zur Verwendung von Google Cloud mit Terraform finden Sie unter Terraform mit Google Cloud.
Verwaltete Sammlung deaktivieren
Wenn Sie die verwaltete Sammlung in Ihren Clustern deaktivieren möchten, können Sie eine der folgenden Methoden verwenden:
Kubernetes Engine-UI
Mit der Google Cloud Console können Sie Folgendes tun:
- Die verwaltete Erfassung in einem vorhandenen GKE-Cluster deaktivieren.
- Automatische Aktivierung der verwalteten Sammlung beim Erstellen Neuen GKE-Standardclusters überschreiben, der GKE-Version 1.27 oder höher ausführt.
So aktualisieren Sie einen vorhandenen Cluster:
-
Rufen Sie in der Google Cloud Console die Seite Kubernetes-Cluster auf:
Wenn Sie diese Seite über die Suchleiste finden, wählen Sie das Ergebnis aus, dessen Zwischenüberschrift Kubernetes Engine lautet.
Klicken Sie auf den Namen des Clusters.
Suchen Sie in der Abschnitt Features die Option Verwalteter Dienst für Prometheus. Klicken Sie auf edit Bearbeiten und entfernen Sie das Häkchen aus Verwalteten Dienst für Prometheus aktivieren.
Klicken Sie auf Änderungen speichern.
So überschreiben Sie die automatische Aktivierung der verwalteten Erfassung beim Erstellen eines neuen GKE-Standardclusters (Version 1.27 oder höher):
-
Rufen Sie in der Google Cloud Console die Seite Kubernetes-Cluster auf:
Wenn Sie diese Seite über die Suchleiste finden, wählen Sie das Ergebnis aus, dessen Zwischenüberschrift Kubernetes Engine lautet.
Klicken Sie auf Erstellen.
Klicken Sie für die Option Standard auf Konfigurieren.
Klicken Sie im Navigationsbereich auf Features.
Entfernen Sie im Abschnitt Vorgänge das Häkchen aus Verwalteten Dienst für Prometheus aktivieren.
Klicken Sie auf Speichern.
gcloud-CLI
Mit der gcloud CLI können Sie Folgendes tun:
- Die verwaltete Erfassung in einem vorhandenen GKE-Cluster deaktivieren.
- Automatische Aktivierung der verwalteten Sammlung beim Erstellen Neuen GKE-Standardclusters überschreiben, der GKE-Version 1.27 oder höher ausführt.
Die Verarbeitung dieser Befehle kann bis zu fünf Minuten dauern.
Legen Sie zuerst Ihr Projekt fest:
gcloud config set project PROJECT_ID
Führen Sie einen der folgenden update-Befehle aus, je nachdem, ob Ihr Cluster zonal oder regional ist, um die verwaltete Sammlung in einem vorhandenen Cluster zu deaktivieren.
gcloud container clusters update CLUSTER_NAME --disable-managed-prometheus --zone ZONE
gcloud container clusters update CLUSTER_NAME --disable-managed-prometheus --region REGION
So überschreiben Sie die automatische Aktivierung der verwalteten Erfassung beim Erstellen eines neuen GKE-Standardclusters (Version 1.27 oder höher):
gcloud container clusters create CLUSTER_NAME --zone ZONE --no-enable-managed-prometheus
GKE Autopilot
Sie können die verwaltete Erfassung in GKE Autopilot-Clustern mit GKE-Version 1.25 oder höher nicht deaktivieren.
Terraform
Um die verwaltete Sammlung zu deaktivieren, legen Sie das Attribut enabled in der
managed_prometheus-Konfigurationsblock auf false fest. Weitere
Informationen zu diesem Konfigurationsblock finden Sie
unter Terraform-Registry für google_container_cluster.
Allgemeine Informationen zur Verwendung von Google Cloud mit Terraform finden Sie unter Terraform mit Google Cloud.
Verwaltete Erfassung aktivieren: Nicht-GKE-Kubernetes
Wenn Sie eine Umgebung außerhalb der GKE-Umgebung verwenden, können Sie die verwaltete Erfassung so aktivieren:
- Die
kubectlCLI: Lokale VMware- oder Bare-Metal-Bereitstellungen mit Version 1.12 oder höher.
kubectl CLI
Führen Sie die folgenden Befehle aus, um verwaltete Collectors zu installieren, wenn Sie einen Nicht-GKE-Kubernetes-Cluster verwenden:
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/prometheus-engine/v0.15.3/manifests/setup.yaml kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/prometheus-engine/v0.15.3/manifests/operator.yaml
Lokal
Informationen zum Konfigurieren der verwalteten Erfassung für lokale Cluster finden Sie in der Dokumentation zu Ihrer Distribution:
Beispielanwendung bereitstellen
Die Beispielanwendung gibt Folgendes aus:
der Zählermesswert example_requests_total und den example_random_numbers
Histogramm-Messwert (unter anderem) am Port metrics. Das Manifest
für die Anwendung definiert drei Replikate.
Führen Sie den folgenden Befehl aus, um die Beispielanwendung bereitzustellen:
kubectl -n NAMESPACE_NAME apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/prometheus-engine/v0.15.3/examples/example-app.yaml
PodMonitoring-Ressource konfigurieren
Zur Aufnahme der von der Beispielanwendung ausgegebenen Messwertdaten verwendet Managed Service for Prometheus Ziel-Extraktion. Ziel-Extraktion und Messwertaufnahme werden mit benutzerdefinierten Ressourcen von Kubernetes konfiguriert. Der verwaltete Dienst verwendet benutzerdefinierte PodMonitoring-Ressourcen (CRs).
Eine PodMonitoring-CR scrapt Ziele nur in dem Namespace, in dem die CR bereitgestellt wird.
Wenn Sie Ziele in mehreren Namespaces scrapen möchten, stellen Sie in jedem Namespace dieselbe PodMonitoring-CR bereit. Sie können prüfen, ob die Ressource PodMonitoring im gewünschten Namespace installiert ist. Führen Sie dazu kubectl get podmonitoring -A aus.
Eine Referenzdokumentation zu allen CRs für Managed Service for Prometheus finden Sie in der Referenz zu prometheus-engine/doc/api.
Das folgende Manifest definiert die PodMonitoring-Ressource prom-example im Namespace NAMESPACE_NAME. Die Ressource verwendet einen Kubernetes-Labelselektor, um alle Pods im Namespace zu finden, die das Label app.kubernetes.io/name mit dem Wert prom-example haben.
Die übereinstimmenden Pods werden an einem Port mit dem Namen metrics alle 30 Sekunden über den /metrics-HTTP-Pfad extrahiert.
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: prom-example
spec:
selector:
matchLabels:
app.kubernetes.io/name: prom-example
endpoints:
- port: metrics
interval: 30s
Führen Sie folgenden Befehl aus, um diese Ressource anzuwenden:
kubectl -n NAMESPACE_NAME apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/prometheus-engine/v0.15.3/examples/pod-monitoring.yaml
Ihr verwalteter Collector extrahiert jetzt Daten aus den übereinstimmenden Pods. Sie können den Status Ihres Scraping-Ziels anzeigen. Aktivieren Sie dazu die Zielstatusfunktion.
Verwenden Sie die Ressource ClusterPodMonitoring, um die horizontale Sammlung zu konfigurieren, die für eine Reihe von Pods in allen Namespaces gilt. Die Ressource ClusterPodMonitoring bietet die gleiche Schnittstelle wie die Ressource PodMonitoring, beschränkt die erkannten Pods jedoch nicht auf einen bestimmten Namespace.
Wenn Sie GKE ausführen, können Sie Folgendes lesen:
- Informationen zum Abfragen der von der Beispielanwendung aufgenommenen Messwerte mit PromQL in Cloud Monitoring finden Sie unter Abfrage mit Cloud Monitoring.
- Informationen zum Abfragen der von der Beispielanwendung aufgenommenen Messwerte mit Grafana finden Sie unter Abfrage mit Grafana oder einem beliebigen Prometheus API-Nutzer.
- Informationen zum Filtern exportierter Messwerte und zum Anpassen Ihrer prom-operator-Ressourcen finden Sie unter Weitere Themen für die verwaltete Erfassung.
Wenn die Ausführung außerhalb von GKE erfolgt, müssen Sie ein Dienstkonto erstellen und es zum Schreiben Ihrer Messwertdaten autorisieren. Dies wird im folgenden Abschnitt beschrieben.
Anmeldedaten explizit angeben
Bei der Ausführung in GKE ruft der erfassende Prometheus-Server automatisch Anmeldedaten aus der Umgebung anhand des Dienstkontos des Knotens ab. In Nicht-GKE-Kubernetes-Clustern müssen Anmeldedaten explizit über die OperatorConfig-Ressource im gmp-public-Namespace bereitgestellt werden.
Legen Sie den Kontext auf Ihr Zielprojekt fest:
gcloud config set project PROJECT_ID
Erstellen Sie ein Dienstkonto:
gcloud iam service-accounts create gmp-test-sa
Gewähren Sie die erforderlichen Berechtigungen für das Dienstkonto:
gcloud projects add-iam-policy-binding PROJECT_ID\ --member=serviceAccount:gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/monitoring.metricWriter
Erstellen Sie einen Schlüssel für das Dienstkonto und laden Sie ihn herunter:
gcloud iam service-accounts keys create gmp-test-sa-key.json \ --iam-account=gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com
Fügen Sie dem Nicht-GKE-Cluster die Schlüsseldatei als Secret hinzu:
kubectl -n gmp-public create secret generic gmp-test-sa \ --from-file=key.json=gmp-test-sa-key.json
Öffnen Sie die OperatorConfig-Ressource zum Bearbeiten:
kubectl -n gmp-public edit operatorconfig config
Fügen Sie der Ressource den fett formatierten Text hinzu:
apiVersion: monitoring.googleapis.com/v1 kind: OperatorConfig metadata: namespace: gmp-public name: config collection: credentials: name: gmp-test-sa key: key.jsonruleshinzuzufügen, damit die Auswertung verwalteter Regeln funktioniert.Speichern Sie die Datei und schließen Sie den Editor. Nachdem die Änderung angewendet wurde, werden die Pods neu erstellt und beginnen mit der Authentifizierung beim Messwert-Backend mit dem angegebenen Dienstkonto.
Weitere Themen für die verwaltete Erfassung
In diesem Abschnitt wird Folgendes beschrieben:
- Aktivieren Sie für eine einfachere Fehlerbehebung die Zielstatusfunktion.
- Ziel-Extraktion mit Terraform konfigurieren.
- Daten filtern, die Sie für den verwalteten Dienst exportieren
- Kubelet- und cAdvisor-Messwerte extrahieren
- Vorhandene prom-operator-Ressourcen zur Verwendung mit dem verwalteten Dienst konvertieren
- Verwaltete Sammlung außerhalb von GKE ausführen
Zielstatusfeature aktivieren
Managed Service for Prometheus bietet eine Möglichkeit, zu prüfen, ob Ihre Ziele von den Collectors richtig erkannt und gescrapt werden. Dieser Zielstatusbericht soll ein Tool zur Behebung akuter Probleme sein. Wir empfehlen dringend, diese Funktion nur zu aktivieren, um akute Probleme zu untersuchen. Wenn die Berichterstellung zum Zielstatus in großen Clustern aktiviert bleibt, kann es sein, dass der Operator nicht mehr genügend Arbeitsspeicher hat und in einer Absturzschleife hängen bleibt.
Sie können den Status Ihrer Ziele in Ihren PodMonitoring- oder ClusterPodMonitoring-Ressourcen prüfen. Legen Sie dazu den Wert
features.targetStatus.enabledin der OperatorConfig-Ressource auftruefest, wie im Folgenden gezeigt:apiVersion: monitoring.googleapis.com/v1 kind: OperatorConfig metadata: namespace: gmp-public name: config features: targetStatus: enabled: trueNach einigen Sekunden wird das Feld
Status.Endpoint Statusesauf jedem gültige PodMonitoring- oder ClusterPodMonitoring-Ressource angezeigt, wenn konfiguriert.Wenn Sie eine PodMonitoring-Ressource mit dem Namen
prom-exampleim NamespaceNAMESPACE_NAMEhaben, können Sie den Status mit dem folgenden Befehl prüfen:kubectl -n NAMESPACE_NAME describe podmonitorings/prom-example
Die Ausgabe sieht in etwa so aus:
API Version: monitoring.googleapis.com/v1 Kind: PodMonitoring ... Status: Conditions: ... Status: True Type: ConfigurationCreateSuccess Endpoint Statuses: Active Targets: 3 Collectors Fraction: 1 Last Update Time: 2023-08-02T12:24:26Z Name: PodMonitoring/custom/prom-example/metrics Sample Groups: Count: 3 Sample Targets: Health: up Labels: Cluster: CLUSTER_NAME Container: prom-example Instance: prom-example-589ddf7f7f-hcnpt:metrics Job: prom-example Location: REGION Namespace: NAMESPACE_NAME Pod: prom-example-589ddf7f7f-hcnpt project_id: PROJECT_ID Last Scrape Duration Seconds: 0.020206416 Health: up Labels: ... Last Scrape Duration Seconds: 0.054189485 Health: up Labels: ... Last Scrape Duration Seconds: 0.006224887Die Ausgabe enthält die folgenden Statusfelder:
Status.Conditions.Statusist „true“, wenn der Managed Service for Prometheus das PodMonitoring oder ClusterPodMonitoring bestätigt und verarbeitet.Status.Endpoint Statuses.Active Targetsgibt die Anzahl der Scraping-Ziele an, die Managed Service for Prometheus auf allen Collectors für diese PodMonitoring-Ressource zählt. In der Beispielanwendung hat dieprom-exampleBereitstellung drei Replikate mit einem einzigen Messwertziel. Der Wert ist also3. Wenn es fehlerhafte Ziele gibt, wird das FeldStatus.Endpoint Statuses.Unhealthy Targetsangezeigt.Status.Endpoint Statuses.Collectors Fractionzeigt den Wert1an (d. h. 100 %), wenn alle verwalteten Collectors über Managed Service for Prometheus erreichbar sind.Status.Endpoint Statuses.Last Update Timezeigt den Zeitpunkt der letzten Aktualisierung an. Wenn die letzte Aktualisierungszeit erheblich länger ist als die gewünschte Zeit des Extraktionsintervalls, kann der Unterschied auf Probleme mit Ihrem Ziel oder Cluster hinweisen.- Im Feld
Status.Endpoint Statuses.Sample Groupswerden Beispielziele angezeigt, die gruppiert sind nach gemeinsamen Ziellabels, die vom Collector eingeschleust wurden. Dieser Wert ist nützlich für Debugging in Situationen, in denen Ihre Ziele nicht erkannt werden. Wenn alle Ziele fehlerfrei sind und erfasst werden, ist der erwartete Wert fürHealthFeldupund der Wert fürLast Scrape Duration Secondsist die übliche Dauer für ein typisches Ziel.
Weitere Informationen zu diesen Feldern finden Sie im API-Dokument für Managed Service for Prometheus.
Eines der folgenden Probleme kann auf ein Problem mit Ihrer Konfiguration hinweisen:
- In Ihrer PodMonitoring-Ressource ist kein
Status.Endpoint Statuses-Feld vorhanden. - Der Wert des Felds
Last Scrape Duration Secondsist zu alt. - Es werden zu wenige Ziele angezeigt.
- Der Wert des Felds
Healthgibt an, dass das Zieldownist.
Weitere Informationen zur Fehlerbehebung bei der Zielerkennung finden Sie in der Dokumentation zur Fehlerbehebung unter Probleme bei der Datenaufnahme.
Autorisierten Extraktionsendpunkt konfigurieren
Wenn für Ihr Scrape-Ziel eine Autorisierung erforderlich ist, können Sie den Collector so einrichten, dass er den richtigen Autorisierungstyp verwendet und alle relevanten Secrets bereitstellt.
Google Cloud Managed Service for Prometheus unterstützt die folgenden Autorisierungstypen:
mTLS
mTLS wird häufig in Zero-Trust-Umgebungen wie Istio Service Mesh oder Cloud Service Mesh konfiguriert.
Wenn Sie das Scraping von Endpunkten aktivieren möchten, die mit mTLS gesichert sind, legen Sie das Feld
Spec.Endpoints[].Schemein Ihrer PodMonitoring-Ressource aufhttpsfest. Obwohl dies nicht empfohlen wird, können Sie das FeldSpec.Endpoints[].tls.insecureSkipVerifyin Ihrer PodMonitoring-Ressource auftruesetzen, um die Überprüfung der Zertifizierungsstelle zu überspringen. Alternativ können Sie Managed Service for Prometheus so konfigurieren, dass Zertifikate und Schlüssel aus Secret-Ressourcen geladen werden.Die folgende Secret-Ressource enthält beispielsweise Schlüssel für das Client- (
cert), das private Schlüssel- (key) und das Zertifizierungsstellen-Zertifikat (ca):kind: Secret metadata: name: secret-example stringData: cert: ******** key: ******** ca: ********
Gewähren Sie dem Collector für Managed Service for Prometheus die Berechtigung für den Zugriff auf diese Secret-Ressource:
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: secret-example-read rules: - resources: - secrets apiGroups: [""] verbs: ["get", "list", "watch"] resourceNames: ["secret-example"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: gmp-system:collector:secret-example-read namespace: default roleRef: name: secret-example-read kind: Role apiGroup: rbac.authorization.k8s.io subjects: - name: collector namespace: gmp-system kind: ServiceAccount
In GKE Autopilot-Clustern sieht das so aus:
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: secret-example-read rules: - resources: - secrets apiGroups: [""] verbs: ["get", "list", "watch"] resourceNames: ["secret-example"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: gmp-system:collector:secret-example-read namespace: default roleRef: name: secret-example-read kind: Role apiGroup: rbac.authorization.k8s.io subjects: - name: collector namespace: gke-gmp-system kind: ServiceAccount
Wenn Sie eine PodMonitoring-Ressource konfigurieren möchten, die die vorherige Secret-Ressource verwendet, fügen Sie der Ressource die Abschnitte
schemeundtlshinzu:apiVersion: monitoring.googleapis.com/v1 kind: PodMonitoring metadata: name: prom-example spec: selector: matchLabels: app.kubernetes.io/name: prom-example endpoints: - port: metrics interval: 30s scheme: https tls: ca: secret: name: secret-example key: ca cert: secret: name: secret-example key: cert key: secret: name: secret-example key: keyEine Referenzdokumentation zu allen mTLS-Optionen für Managed Service for Prometheus finden Sie in der API-Referenzdokumentation.
BasicAuth
Wenn Sie Endpunkte, die mit BasicAuth gesichert sind, extrahieren möchten, legen Sie das Feld
Spec.Endpoints[].BasicAuthin Ihrer PodMonitoring-Ressource mit Ihrem Nutzernamen und Passwort fest. Informationen zu anderen HTTP-Autorisierungsheadertypen finden Sie unter HTTP-Autorisierungsheader.Die folgende Secret-Ressource enthält beispielsweise einen Schlüssel zum Speichern des Passworts:
kind: Secret metadata: name: secret-example stringData: password: ********
Gewähren Sie dem Collector für Managed Service for Prometheus die Berechtigung für den Zugriff auf diese Secret-Ressource:
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: secret-example-read rules: - resources: - secrets apiGroups: [""] verbs: ["get", "list", "watch"] resourceNames: ["secret-example"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: gmp-system:collector:secret-example-read namespace: default roleRef: name: secret-example-read kind: Role apiGroup: rbac.authorization.k8s.io subjects: - name: collector namespace: gmp-system kind: ServiceAccount
In GKE Autopilot-Clustern sieht das so aus:
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: secret-example-read rules: - resources: - secrets apiGroups: [""] verbs: ["get", "list", "watch"] resourceNames: ["secret-example"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: gmp-system:collector:secret-example-read namespace: default roleRef: name: secret-example-read kind: Role apiGroup: rbac.authorization.k8s.io subjects: - name: collector namespace: gke-gmp-system kind: ServiceAccount
Wenn Sie eine PodMonitoring-Ressource konfigurieren möchten, die die vorherige Secret-Ressource und den Nutzernamen
fooverwendet, fügen Sie Ihrer Ressource einenbasicAuth-Abschnitt hinzu:apiVersion: monitoring.googleapis.com/v1 kind: PodMonitoring metadata: name: prom-example spec: selector: matchLabels: app.kubernetes.io/name: prom-example endpoints: - port: metrics interval: 30s basicAuth: username: foo password: secret: name: secret-example key: passwordEine Referenzdokumentation zu allen BasicAuth-Optionen für Managed Service for Prometheus finden Sie in der API-Referenzdokumentation.
HTTP-Autorisierungsheader
Wenn Sie Endpunkte, die mit HTTP-Autorisierungsheadern gesichert sind, per Scraping erfassen möchten, legen Sie das Feld
Spec.Endpoints[].Authorizationin Ihrer PodMonitoring-Ressource mit dem Typ und den Anmeldedaten fest. Verwenden Sie für BasicAuth-Endpunkte stattdessen die BasicAuth-Konfiguration.Die folgende Secret-Ressource enthält beispielsweise einen Schlüssel zum Speichern der Anmeldedaten:
kind: Secret metadata: name: secret-example stringData: credentials: ********
Gewähren Sie dem Collector für Managed Service for Prometheus die Berechtigung für den Zugriff auf diese Secret-Ressource:
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: secret-example-read rules: - resources: - secrets apiGroups: [""] verbs: ["get", "list", "watch"] resourceNames: ["secret-example"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: gmp-system:collector:secret-example-read namespace: default roleRef: name: secret-example-read kind: Role apiGroup: rbac.authorization.k8s.io subjects: - name: collector namespace: gmp-system kind: ServiceAccount
In GKE Autopilot-Clustern sieht das so aus:
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: secret-example-read rules: - resources: - secrets apiGroups: [""] verbs: ["get", "list", "watch"] resourceNames: ["secret-example"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: gmp-system:collector:secret-example-read namespace: default roleRef: name: secret-example-read kind: Role apiGroup: rbac.authorization.k8s.io subjects: - name: collector namespace: gke-gmp-system kind: ServiceAccount
Wenn Sie eine PodMonitoring-Ressource konfigurieren möchten, die die vorherige Secret-Ressource und den Typ
Bearerverwendet, fügen Sie Ihrer Ressource einenauthorization-Abschnitt hinzu:apiVersion: monitoring.googleapis.com/v1 kind: PodMonitoring metadata: name: prom-example spec: selector: matchLabels: app.kubernetes.io/name: prom-example endpoints: - port: metrics interval: 30s authorization: type: Bearer credentials: secret: name: secret-example key: credentialsEine Referenzdokumentation zu allen Optionen für den HTTP-Autorisierungsheader für Managed Service for Prometheus finden Sie in der API-Referenzdokumentation.
OAuth 2
Wenn Sie Endpunkte, die mit OAuth 2 gesichert sind, extrahieren möchten, müssen Sie das Feld
Spec.Endpoints[].OAuth2in Ihrer PodMonitoring-Ressource festlegen.Die folgende Secret-Ressource enthält beispielsweise einen Schlüssel zum Speichern des Client-Secrets:
kind: Secret metadata: name: secret-example stringData: clientSecret: ********
Gewähren Sie dem Collector für Managed Service for Prometheus die Berechtigung für den Zugriff auf diese Secret-Ressource:
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: secret-example-read rules: - resources: - secrets apiGroups: [""] verbs: ["get", "list", "watch"] resourceNames: ["secret-example"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: gmp-system:collector:secret-example-read namespace: default roleRef: name: secret-example-read kind: Role apiGroup: rbac.authorization.k8s.io subjects: - name: collector namespace: gmp-system kind: ServiceAccount
In GKE Autopilot-Clustern sieht das so aus:
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: secret-example-read rules: - resources: - secrets apiGroups: [""] verbs: ["get", "list", "watch"] resourceNames: ["secret-example"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: gmp-system:collector:secret-example-read namespace: default roleRef: name: secret-example-read kind: Role apiGroup: rbac.authorization.k8s.io subjects: - name: collector namespace: gke-gmp-system kind: ServiceAccount
Wenn Sie eine PodMonitoring-Ressource konfigurieren möchten, die die vorherige Secret-Ressource mit der Client-ID
foound der Token-URLexample.com/tokenverwendet, ändern Sie die Ressource, um den Abschnittoauth2hinzuzufügen:apiVersion: monitoring.googleapis.com/v1 kind: PodMonitoring metadata: name: prom-example spec: selector: matchLabels: app.kubernetes.io/name: prom-example endpoints: - port: metrics interval: 30s oauth2: clientID: foo clientSecret: secret: name: secret-example key: password tokenURL: example.com/tokenEine Referenzdokumentation zu allen OAuth 2-Optionen für Managed Service for Prometheus finden Sie in der API-Referenzdokumentation.
Ziel-Scraping mit Terraform konfigurieren
Sie können die Erstellung und Verwaltung von PodMonitoring- und ClusterPodMonitoring-Ressourcen automatisieren. Verwenden Sie dazu den
kubernetes_manifest-Terraform-Ressourcentyp oder denkubectl_manifest-Terraform-Ressourcentyp, mit denen Sie beliebige benutzerdefinierte Ressourcen angeben können.Allgemeine Informationen zur Verwendung von Google Cloud mit Terraform finden Sie unter Terraform mit Google Cloud.
Exportierte Messwerte filtern
Wenn Sie viele Daten erheben, möchten Sie möglicherweise verhindern, dass einige Zeitreihen an Managed Service for Prometheus gesendet werden, um Kosten niedrig zu halten. Dazu können Sie Prometheus-Relabeling-Regeln mit einer
keep-Aktion für eine Zulassungsliste oder einerdrop-Aktion für eine Sperrliste verwenden. Bei der verwalteten Sammlung befindet sich diese Regel im AbschnittmetricRelabelingIhrer PodMonitoring oder ClusterPodMonitoring-Ressource.Die folgende Regel zur Labelerstellung für Messwerte filtert beispielsweise alle Messwerte heraus, die mit
foo_bar_,foo_baz_oderfoo_qux_beginnen:metricRelabeling: - action: drop regex: foo_(bar|baz|qux)_.+ sourceLabels: [__name__]Auf der Cloud Monitoring-Seite Messwertverwaltung können Sie den Betrag steuern, den Sie für abrechenbare Messwerte ausgeben, ohne die Beobachtbarkeit zu beeinträchtigen. Die Seite Messwertverwaltung enthält die folgenden Informationen:
- Aufnahmevolumen für byte- und probenbasierte Abrechnung für Messwertdomains und einzelne Messwerte
- Daten zu Labels und zur Kardinalität von Messwerten
- Anzahl der Lesevorgänge für jeden Messwert
- Nutzung von Messwerten in Benachrichtigungsrichtlinien und benutzerdefinierten Dashboards
- Fehlerrate beim Schreiben von Messwerten
Auf der Seite Messwertverwaltung können Sie auch nicht benötigte Messwerte ausschließen, um unnötige Kosten bei der Datenaufnahme zu vermeiden. Weitere Informationen zur Seite Messwertverwaltung finden Sie unter Messwertnutzung ansehen und verwalten.
Weitere Vorschläge zur Kostensenkung finden Sie unter Kostenkontrollen und Attribution.
Scraping von Kubelet- und cAdvisor-Messwerten
Das Kubelet stellt Messwerte über sich selbst und cAdvisor-Messwerte zu Containern bereit, die auf seinem Knoten ausgeführt werden. Sie können die verwaltete Sammlung so konfigurieren, dass sie Kubelet- und cAdvisor-Messwerte extrahiert, indem Sie die OperatorConfig-Ressource bearbeiten. Eine Anleitung hierzu finden Sie in der Exporteurdokumentation für Kubelet und cAdvisor.
Vorhandene prometheus-operator-Ressourcen konvertieren
Normalerweise können Sie Ihre vorhandenen Prometheus-Operator-Ressourcen in verwaltete Dienste für von Prometheus verwaltete Sammlungs-PodMonitoring- und ClusterPodMonitoring-Ressourcen konvertieren.
Beispielsweise definiert die ServiceMonitor-Ressource das Monitoring für eine Reihe von Diensten. Die PodMonitoring-Ressource stellt eine Teilmenge der Felder bereit, die von der ServiceMonitor-Ressource bereitgestellt werden. Sie können eine ServiceMonitor-CR in eine PodMonitoring-CR konvertieren, indem Sie die Felder wie in der folgenden Tabelle beschrieben zuordnen:
monitoring.coreos.com/v1
ServiceMonitorKompatibilität
monitoring.googleapis.com/v1
PodMonitoring.ServiceMonitorSpec.SelectorIdentisch .PodMonitoringSpec.Selector.ServiceMonitorSpec.Endpoints[].TargetPortwird.Portzugeordnet
.Path: kompatibel
.Interval: kompatibel
.Timeout: kompatibel.PodMonitoringSpec.Endpoints[].ServiceMonitorSpec.TargetLabelsPodMonitor muss Folgendes angeben:
.FromPod[].From-Pod-Label
.FromPod[].To-Ziellabel.PodMonitoringSpec.TargetLabelsDas folgende Beispiel zeigt eine ServiceMonitor-CR. Der fett formatierte Inhalt wird bei der Konvertierung ersetzt und der kursive Inhalt wird direkt zugeordnet:
apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: name: example-app spec: selector: matchLabels: app: example-app endpoints: - targetPort: web path: /stats interval: 30s targetLabels: - fooIm Folgenden finden Sie die analoge PodMonitoring-CR, unter der Annahme, dass Ihr Dienst und seine Pods mit
app=example-appgekennzeichnet sind. Wenn diese Annahme nicht zutrifft, müssen Sie die Labelselektoren der zugrunde liegenden Service-Ressource verwenden.Der fett formatierte Inhalt wurde bei der Konvertierung ersetzt:
apiVersion: monitoring.googleapis.com/v1 kind: PodMonitoring metadata: name: example-app spec: selector: matchLabels: app: example-app endpoints: - port: web path: /stats interval: 30s targetLabels: fromPod: - from: foo # pod label from example-app Service pods. to: fooSie können Ihre vorhandenen Prometheus-Operator-Ressourcen und Bereitstellungskonfigurationen weiterhin verwenden, indem Sie selbst bereitgestellte Collectors anstelle von verwalteten Collectors verwenden. Sie können Messwerte abfragen, die von beiden Collector-Typen gesendet werden. Daher möchten Sie möglicherweise selbst bereitgestellte Collectors für Ihre vorhandenen Prometheus-Bereitstellungen verwenden, während Sie verwaltete Collectors für neue Prometheus-Bereitstellungen verwenden.
Reservierte Labels
Managed Service for Prometheus fügt allen erfassten Messwerten automatisch die folgenden Labels hinzu: Diese Labels werden verwendet, um eine Ressource in Monarch eindeutig zu identifizieren:
project_id: Die Kennung des Google Cloud -Projekts, das Ihrem Messwert zugeordnet ist.location: Der physische Standort (Google Cloud -Region), an dem die Daten gespeichert werden. Dieser Wert ist in der Regel die Region Ihres GKE-Clusters. Wenn Daten aus einer AWS- oder lokalen Bereitstellung erhoben werden, ist der Wert möglicherweise die nächstgelegene Google Cloud -Region.cluster: Der Name des Kubernetes-Clusters, der Ihrem Messwert zugeordnet ist.namespace: Der Name des Kubernetes-Namespace, der Ihrem Messwert zugeordnet ist.job: Das Joblabel des Prometheus-Ziels, sofern bekannt. Kann für Ergebnisse der Regelauswertung leer sein.instance: Das Instanzlabel des Prometheus-Ziels, sofern bekannt. Kann für Ergebnisse der Regelauswertung leer sein.
Obwohl die Ausführung in Google Kubernetes Engine nicht empfohlen wird, können Sie die Labels
project_id,locationundclusterüberschreiben, indem Sie sie alsargsin die Deployment-Ressource innerhalb vonoperator.yamlhinzufügen. Wenn Sie reservierte Labels als Messwertlabels verwenden, werden diese von Managed Service for Prometheus automatisch neu beschriftet. Dazu wird das Präfixexported_hinzugefügt. Dieses Verhalten entspricht der Vorgehensweise von Upstream-Prometheus beim Bearbeiten von Konflikten mit reservierten Labels.Konfigurationen komprimieren
Wenn Sie viele PodMonitoring-Ressourcen haben, kann der ConfigMap-Speicherplatz knapp werden. Aktivieren Sie dazu die
gzip-Komprimierung in Ihrer OperatorConfig-Ressource:apiVersion: monitoring.googleapis.com/v1 kind: OperatorConfig metadata: namespace: gmp-public name: config features: config: compression: gzipVertikales Pod-Autoscaling (VPA) für die verwaltete Sammlung aktivieren
Wenn in Ihrem Cluster OOM-Fehler (Out of Memory) für die Collector-Pods auftreten oder die Standardressourcenanforderungen und ‑limits für die Collectors anderweitig nicht Ihren Anforderungen entsprechen, können Sie mit dem vertikalen Pod-Autoscaling Ressourcen dynamisch zuweisen.
Wenn Sie das Feld
scaling.vpa.enabled: truefür dieOperatorConfig-Ressource festlegen, stellt der Operator einVerticalPodAutoscaler-Manifest im Cluster bereit, mit dem die Ressourcenanfragen und ‑limits der Collector-Pods automatisch auf Grundlage der Nutzung festgelegt werden können.Führen Sie den folgenden Befehl aus, um VPA für Collector-Pods in Managed Service for Prometheus zu aktivieren:
kubectl -n gmp-public patch operatorconfig/config -p '{"scaling":{"vpa":{"enabled":true}}}' --type=mergeWenn der Befehl erfolgreich abgeschlossen wird, richtet der Operator das vertikale Pod-Autoscaling für die Collector-Pods ein. Fehler aufgrund fehlenden Speichers führen zu einer sofortigen Erhöhung der Ressourcenlimits. Wenn keine OOM-Fehler auftreten, erfolgt die erste Anpassung der Ressourcenanforderungen und ‑limits der Collector-Pods in der Regel innerhalb von 24 Stunden.
Diese Fehlermeldung kann angezeigt werden, wenn Sie versuchen, die Sprachsteuerung zu aktivieren:
vertical pod autoscaling is not available - install vpa support and restart the operatorUm diesen Fehler zu beheben, müssen Sie zuerst das vertikale Pod-Autoscaling auf Clusterebene aktivieren:
Rufen Sie in derGoogle Cloud Console die Seite Kubernetes Engine – Cluster auf.
Rufen Sie in der Google Cloud Console die Seite Kubernetes-Cluster auf:
Wenn Sie diese Seite über die Suchleiste finden, wählen Sie das Ergebnis aus, dessen Zwischenüberschrift Kubernetes Engine lautet.
Wählen Sie den Cluster aus, den Sie ändern möchten.
Bearbeiten Sie im Abschnitt Automatisierung den Wert der Option Vertikales Pod-Autoscaling.
Klicken Sie das Kästchen Vertikales Pod-Autoscaling aktivieren an und klicken Sie dann auf Änderungen speichern. Durch diese Änderung wird Ihr Cluster neu gestartet. Der Operator wird im Rahmen dieses Prozesses neu gestartet.
Wiederholen Sie den folgenden Befehl:
kubectl -n gmp-public patch operatorconfig/config -p '{"scaling":{"vpa":{"enabled":true}}}' --type=merge, um VPA für Managed Service for Prometheus zu aktivieren.
Um zu bestätigen, dass die
OperatorConfig-Ressource erfolgreich bearbeitet wurde, öffnen Sie sie mit dem Befehlkubectl -n gmp-public edit operatorconfig config. Wenn der Vorgang erfolgreich ist, enthält die DateiOperatorConfigden folgenden fett formatierten Abschnitt:apiVersion: monitoring.googleapis.com/v1 kind: OperatorConfig metadata: namespace: gmp-public name: config scaling: vpa: enabled: trueWenn Sie das vertikale Pod-Autoscaling bereits auf Clusterebene aktiviert haben und weiterhin den
vertical pod autoscaling is not available - install vpa support and restart the operator-Fehler sehen, muss dergmp-operator-Pod möglicherweise die Clusterkonfiguration neu bewerten. Wenn Sie einen Standardcluster verwenden, führen Sie den folgenden Befehl aus, um den Pod neu zu erstellen:kubectl -n gmp-system rollout restart deployment/gmp-operator
Nachdem der
gmp-operator-Pod neu gestartet wurde, folge der Anleitung oben, um denOperatorConfignoch einmal zu patchen.Wenn Sie einen Autopilot-Cluster verwenden, wenden Sie sich an den Support, um Unterstützung beim Neustarten des Clusters zu erhalten.
Vertikales Pod-Autoscaling funktioniert am besten, wenn eine gleichmäßige Anzahl von Stichproben aufgenommen wird, die gleichmäßig auf die Knoten verteilt sind. Wenn die Metrikenlast unregelmäßig oder sprunghaft ist oder sich die Metrikenlast zwischen den Knoten stark unterscheidet, ist VPA möglicherweise keine effiziente Lösung.
Weitere Informationen finden Sie unter Vertikales Pod-Autoscaling in GKE.
statsd_exporter und andere Exporter konfigurieren, die Messwerte zentral erfassen
Wenn Sie den statsd_exporter für Prometheus, Envoy für Istio, den SNMP-Exporter, das Prometheus Pushgateway, kube-state-metrics oder einen ähnlichen Exporter verwenden, der Messwerte im Namen anderer Ressourcen in Ihrer Umgebung weiterleitet und meldet, müssen Sie einige kleine Änderungen vornehmen, damit Ihr Exporter mit Managed Service for Prometheus funktioniert.
Eine Anleitung zum Konfigurieren dieser Exporter finden Sie in dieser Anmerkung im Abschnitt zur Fehlerbehebung.
Bereinigen
So deaktivieren Sie die verwaltete Erfassung, die mit
gcloudoder der GKE-UI bereitgestellt wurde:Führen Sie dazu diesen Befehl aus:
gcloud container clusters update CLUSTER_NAME --disable-managed-prometheus
Verwenden Sie die GKE-UI:
Wählen Sie in der Google Cloud -Console Kubernetes Engine und dann Cluster aus.
Suchen Sie den Cluster, für den Sie die verwaltete Erfassung deaktivieren möchten, und klicken Sie auf den Namen.
Scrollen Sie auf dem Tab Details nach unten zu Features und ändern Sie den Zustand mithilfe der Schaltfläche „Bearbeiten“ in Deaktiviert.
Wenn Sie die mit Terraform bereitgestellte verwaltete Erfassung deaktivieren möchten, geben Sie
enabled = falseim Abschnittmanaged_prometheusder Ressourcegoogle_container_clusteran.Führen Sie den folgenden Befehl aus, um die mit
kubectlbereitgestellte verwaltete Erfassung zu deaktivieren:kubectl delete -f https://raw.githubusercontent.com/GoogleCloudPlatform/prometheus-engine/v0.15.3/manifests/operator.yaml
Wenn Sie die verwaltete Erfassung deaktivieren, sendet der Cluster keine neuen Daten mehr an Managed Service for Prometheus. Durch diese Aktion werden keine bereits im System gespeicherten Messwertdaten gelöscht.
Durch das Deaktivieren der verwalteten Sammlung werden auch der
gmp-public-Namespace und alle darin enthaltenen Ressourcen gelöscht, einschließlich aller in diesem Namespace installierten Exporter.Verwaltete Sammlung außerhalb von GKE ausführen
In GKE-Umgebungen können Sie eine verwaltete Sammlung ohne weitere Konfiguration ausführen. In anderen Kubernetes-Umgebungen müssen Sie Anmeldedaten explizit angeben, einen
project-id-Wert für Ihre Messwerte und einenlocation-Wert (Google Cloud -Region), in dem Ihre Messwerte gespeichert werden, sowie einencluster-Wert, um den Namen des Clusters zu speichern, in dem der Collector ausgeführt wird.Da
gcloudnicht außerhalb von Google Cloud -Umgebungen funktioniert, müssen Sie stattdessen kubectl bereitstellen. Anders als beigcloudwird beim Bereitstellen einer verwalteten Sammlung mitkubectlder Cluster nicht automatisch aktualisiert, wenn eine neue Version verfügbar ist. Denken Sie daran, die Releaseseite auf neue Versionen zu prüfen und manuell ein Upgrade durch Ausführen der Befehlekubectlmit der neuen Version durchzuführen.Sie können einen Dienstkontoschlüssel angeben. Ändern Sie dazu die Ressource OperatorConfig in
operator.yamlwie unter Anmeldedaten explizit angeben beschrieben. Sie könnenproject-id-,location- undcluster-Werte angeben. Fügen Sie diese dazu der Deployment-Ressource inoperator.yamlalsargshinzu.Wir empfehlen die Auswahl von
project-idbasierend auf Ihrem geplanten Mandantenmodell für Lesevorgänge. Wählen Sie ein Projekt aus, um Messwerte basierend darauf zu speichern, wie Sie Lesevorgänge später über Messwertbereiche organisieren möchten. Wenn dies für Sie nicht relevant ist, können Sie alles in einem Projekt ablegen.Für
locationempfehlen wir, die Google Cloud -Region auszuwählen, die Ihrer Bereitstellung am nächsten ist. Je weiter die ausgewählte Google Cloud Region von Ihrer Bereitstellung entfernt ist, desto mehr Schreiblatenz haben Sie und desto mehr sind Sie von potenziellen Netzwerkproblemen betroffen. Sehen Sie sich diese Liste der Regionen in mehreren Clouds an. Wenn es Ihnen nicht wichtig ist, können Sie alles in einer einzigen Google Cloud Region zusammenfassen. Sie könnenglobalnicht als Standort verwenden.Für
clusterempfehlen wir, den Namen des Clusters auszuwählen, in dem der Operator bereitgestellt ist.Bei korrekter Konfiguration sollte OperatorConfig so aussehen:
apiVersion: monitoring.googleapis.com/v1 kind: OperatorConfig metadata: namespace: gmp-public name: config collection: credentials: name: gmp-test-sa key: key.json rules: credentials: name: gmp-test-sa key: key.jsonIhre Bereitstellungsressource sollte so aussehen:
apiVersion: apps/v1 kind: Deployment ... spec: ... template: ... spec: ... containers: - name: operator ... args: - ... - "--project-id=PROJECT_ID" - "--cluster=CLUSTER_NAME" - "--location=REGION"In diesem Beispiel wird davon ausgegangen, dass Sie die Variable
REGIONauf einen Wert wieus-central1gesetzt haben.Für die Ausführung von Managed Service for Prometheus außerhalb von Google Cloud fallen Gebühren für die Datenübertragung an. Für die Übertragung von Daten in Google Cloudfallen Gebühren an. Es können Gebühren für die Übertragung von Daten aus einer anderen Cloud anfallen. Sie können diese Kosten minimieren, indem Sie die Gzip-Komprimierung über die OperatorConfig aktivieren. Fügen Sie der Ressource den fett formatierten Text hinzu:
apiVersion: monitoring.googleapis.com/v1 kind: OperatorConfig metadata: namespace: gmp-public name: config collection: compression: gzip ...Weitere Informationen zu benutzerdefinierten Ressourcen für verwaltete Sammlungen
Eine Referenzdokumentation zu allen benutzerdefinierten Ressourcen für Managed Service for Prometheus finden Sie in der Referenz zu prometheus-engine/doc/api reference.
Nächste Schritte
- PromQL in Cloud Monitoring zum Abfragen von Prometheus-Messwerten verwenden
- Prometheus-Messwerte mit Grafana abfragen
- Verwenden Sie PromQL-Benachrichtigungen in Cloud Monitoring.
- Richten Sie die verwaltete Regelauswertung ein.
- Richten Sie häufig verwendete Exporteure ein.