このページでは、Cloud Run で NFS ファイル共有をボリュームとしてマウントする方法について説明します。オンプレミスまたは Compute Engine VM でホストされている独自の NFS サーバーなど、任意の NFS サーバーを使用できます。NFS サーバーをまだ使用していない場合は、 Google Cloudのフルマネージド NFS サービスである Filestore をおすすめします。
NBD、9P、CIFS / Samba、Ceph のネットワーク ファイル システムを使用する場合は、NBD、9P、CIFS / Samba、Ceph のネットワーク ファイル システムを使用するをご覧ください。
Cloud Run で NFS ファイル共有をボリュームとしてマウントすると、ファイル共有がコンテナ ファイル システム内のファイルとして提示されます。ファイル共有をボリュームとしてマウントした後、プログラミング言語のファイル システム オペレーションとライブラリを使用して、ローカル ファイル システム上のディレクトリと同じようにアクセスします。
使用できないパス
Cloud Run では、/dev、/proc、/sys、またはそのサブディレクトリにボリュームをマウントすることはできません。
制限事項
NFS ボリュームに書き込むには、コンテナを root として実行する必要があります。コンテナでファイル システムからの読み取りを行うだけの場合は、任意のユーザーとして実行できます。
Cloud Run は NFS ロックをサポートしていません。NFS ボリュームは、ロックなしモードで自動的にマウントされます。
始める前に
Cloud Run で NFS サーバーをボリュームとしてマウントするには、次のものが必要です。
- VPC ネットワーク。このネットワークで NFS サーバーまたは Filestore インスタンスが実行されます。
- VPC ネットワークで実行される NFS サーバー。ここで、Cloud Run ジョブが VPC ネットワークに接続されます。NFS サーバーがまだない場合は、Filestore インスタンスを作成してサーバーを作成します。
- Cloud Run ジョブは、NFS サーバーが実行されている VPC ネットワークに接続されます。最高のパフォーマンスを得るには、VPC コネクタではなくダイレクト VPC を使用します。
- 既存のプロジェクトを使用している場合は、VPC ファイアウォール構成で Cloud Run が NFS サーバーにアクセスできることを確認してください(新しいプロジェクトから開始する場合は、デフォルトで true になります)。NFS サーバーとして Filestore を使用している場合は、Filestore のドキュメントに従って下り(外向き)ファイアウォール ルールを作成し、Cloud Run が Filestore にアクセスできるようにします。
必要なロール
Cloud Run ジョブの構成に必要な権限を取得するには、ジョブに対する次の IAM ロールを付与するよう管理者に依頼してください。
-
Cloud Run ジョブに対する Cloud Run デベロッパー ロール(
roles/run.developer) - サービス ID に対するサービス アカウント ユーザー ロール(
roles/iam.serviceAccountUser)
Cloud Run に関連付けられている IAM ロールと権限のリストについては、Cloud Run IAM ロールと Cloud Run IAM 権限をご覧ください。Cloud Run ジョブがGoogle Cloud API(Cloud クライアント ライブラリなど)と連携している場合は、サービス ID の構成ガイドをご覧ください。ロールの付与の詳細については、デプロイ権限とアクセスの管理をご覧ください。
NFS ボリュームをマウントする
複数の NFS サーバー、Filestore インスタンス、または他のボリューム タイプを異なるマウントパスにマウントできます。
複数のコンテナを使用している場合は、まずボリュームを指定してから、各コンテナのボリューム マウントを指定します。
コンソール
Google Cloud コンソールで、Cloud Run の [ジョブ] ページに移動します。
メニューから [ジョブ] を選択し、[コンテナをデプロイ] をクリックして、ジョブの初期設定ページに入力します。既存のジョブを構成する場合は、ジョブをクリックして [編集] をクリックします。
[コンテナ、ボリューム、接続、セキュリティ] をクリックして、ジョブのプロパティ ページを開きます。
[ボリューム] タブをクリックします。
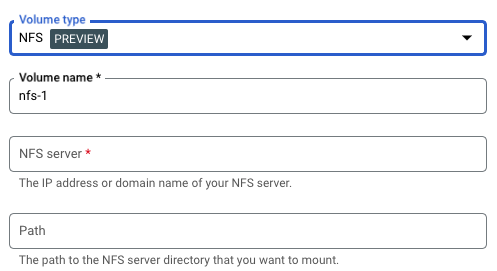
- [ボリューム] で、次の操作を行います。
- [ボリュームを追加] をクリックします。
- [ボリュームのタイプ] プルダウンで、ボリューム タイプとして [NFS] を選択します。
- [ボリューム名] フィールドに、ボリュームに使用する名前を入力します。
- [NFS サーバー] フィールドに、NFS ファイル共有のドメイン名または場所(
IP_ADDRESS形式)を入力します。 - [パス] フィールドに、マウントする NFS サーバー ディレクトリのパスを入力します。
- [完了] をクリックします。
- [コンテナ] タブをクリックし、ボリュームをマウントするコンテナを開いて、コンテナを編集します。
- [ボリュームのマウント] タブをクリックします。
- [ボリュームをマウント] をクリックします。
- メニューから NFS ボリュームを選択します。
- ボリュームをマウントするパスを指定します。
- [ボリュームをマウント] をクリックします。
- [ボリューム] で、次の操作を行います。
[作成] または [更新] をクリックします。
gcloud
ボリュームを追加してマウントするには:
gcloud run jobs update JOB \ --add-volume name=VOLUME_NAME,type=nfs,location=IP_ADDRESS:NFS_PATH \ --add-volume-mount volume=VOLUME_NAME,mount-path=MOUNT_PATH
次のように置き換えます。
- JOB は、ジョブの名前に置き換えます。
- VOLUME_NAME は、ボリュームに付ける名前に置き換えます。
- IP_ADDRESS は、NFS ファイル共有の場所に置き換えます。
- NFS_PATH は、NFS ファイル共有のパスに置き換えます。
- MOUNT_PATH は、このボリュームをマウントするコンテナ ファイル システム内のパスに置き換えます。
ボリュームを読み取り専用ボリュームとしてマウントするには:
--add-volume name VOLUME_NAME,type=nfs,location=IP_ADDRESS:NFS_PATH,readonly=true
複数のコンテナを使用している場合は、まずボリュームを指定してから、各コンテナのボリューム マウントを指定します。
gcloud run jobs update JOB \ --add-volume name=VOLUME_NAME,type=nfs,location=IP_ADDRESS:NFS_PATH \ --container CONTAINER_1 \ --add-volume-mount volume= VOLUME_NAME,mount-path=MOUNT_PATH \ --container CONTAINER_2 \ --add-volume-mount volume=VOLUME_NAME,mount-path=MOUNT_PATH2
YAML
新しいジョブを作成する場合は、この手順をスキップします。既存のジョブを更新する場合は、その YAML 構成をダウンロードします。
gcloud run jobs describe JOB_NAME --format export > job.yaml
必要に応じて、MOUNT_PATH、VOLUME_NAME、IP_ADDRESS、NFS_PATH を更新します。複数のボリュームをマウントしている場合は、属性はその倍数になります。
apiVersion: run.googleapis.com/v1 kind: Job metadata: name: JOB_NAME spec: metadata: template: metadata: annotations: run.googleapis.com/execution-environment: gen2 spec: template: spec: containers: - image: IMAGE_URL volumeMounts: - name: VOLUME_NAME mountPath: MOUNT_PATH volumes: - name: VOLUME_NAME nfs: server: IP_ADDRESS path: NFS_PATH readonly: IS_READ_ONLY
次のように置き換えます。
- JOB は、Cloud Run ジョブの名前に置き換えます。
- MOUNT_PATH は、ボリュームをマウントする相対パス(
/mnt/my-volumeなど)に置き換えます。 - VOLUME_NAME は、ボリュームに付ける名前に置き換えます。VOLUME_NAME 値は、ボリュームをボリューム マウントにマッピングするために使用されます。
- IP_ADDRESS は、NFS ファイル共有のアドレスに置き換えます。
- NFS_PATH は、NFS ファイル共有のパスに置き換えます。
- ボリュームを読み取り専用にする場合は IS_READ_ONLY を
Trueに置き換えます。書き込み可能にするにはFalseに置き換えます。
次のコマンドを使用して、ジョブを作成または更新します。
gcloud run jobs replace job.yaml
Terraform
Terraform 構成を適用または削除する方法については、基本的な Terraform コマンドをご覧ください。
Terraform 構成のgoogle_cloud_run_v2_job リソースに次の内容を追加します。resource "google_cloud_run_v2_job" "default" {
name = "JOB_NAME"
location = "REGION"
template {
template {
containers {
image = "us-docker.pkg.dev/cloudrun/container/hello"
volume_mounts {
name = "VOLUME_NAME"
mount_path = "MOUNT_PATH"
}
}
vpc_access {
network_interfaces {
network = "default"
subnetwork = "default"
}
}
volumes {
name = "VOLUME_NAME"
nfs {
server = google_filestore_instance.default.networks[0].ip_addresses[0]
path = "NFS_PATH"
read_only = IS_READ_ONLY
}
}
}
}
}
resource "google_filestore_instance" "default" {
name = "cloudrun-job"
location = "REGION"
tier = "BASIC_HDD"
file_shares {
capacity_gb = 1024
name = "share1"
}
networks {
network = "default"
modes = ["MODE_IPV4"]
}
}
次のように置き換えます。
- JOB_NAME: Cloud Run ジョブの名前。
- REGION は、 Google Cloud リージョンに置き換えます。例:
europe-west1 - MOUNT_PATH は、ボリュームをマウントする相対パス(
/mnt/nfs/filestoreなど)に置き換えます。 - VOLUME_NAME は、ボリュームに付ける名前に置き換えます。VOLUME_NAME 値は、ボリュームをボリューム マウントにマッピングするために使用されます。
- NFS_PATH は、NFS ファイル共有のパスに置き換えます(スラッシュで始まるパス、例:
/share1)。 - ボリュームを読み取り専用にする場合は IS_READ_ONLY を
Trueに置き換えます。書き込み可能にするにはFalseに置き換えます。
ボリュームの読み取りと書き込み
Cloud Run のボリューム マウント機能を使用する場合、ローカル ファイル システムでファイルの読み取りと書き込みに使用するプログラミング言語のライブラリを使用して、マウントされたボリュームにアクセスします。
これは、ローカル ファイル システムにデータが保存されることを想定し、通常のファイル システム オペレーションを使用してデータにアクセスする既存のコンテナを使用している場合に特に便利です。
次のスニペットは、mountPath が /mnt/my-volume に設定されたボリューム マウントを前提としています。
Node.js
ファイル システム モジュールを使用してボリューム /mnt/my-volume に新しいファイルを作成するか、既存のファイルに追加します。
var fs = require('fs');
fs.appendFileSync('/mnt/my-volume/sample-logfile.txt', 'Hello logs!', { flag: 'a+' });Python
ボリューム /mnt/my-volume に保存されているファイルに書き込みます。
f = open("/mnt/my-volume/sample-logfile.txt", "a")Go
os パッケージを使用して、ボリューム /mnt/my-volume に新しいファイルを作成します。
f, err := os.Create("/mnt/my-volume/sample-logfile.txt")Java
Java.io.File クラスを使用して、ボリューム /mnt/my-volume にログファイルを作成します。
import java.io.File;
File f = new File("/mnt/my-volume/sample-logfile.txt");NFS のトラブルシューティング
問題が発生した場合は、次の点を確認してください。
- Cloud Run サービスが、NFS サーバーのある VPC ネットワークに接続されている。
- Cloud Run が NFS サーバーにアクセスすることを妨げるファイアウォール ルールがない。
- コンテナで NFS サーバーに書き込みを行う場合は、root として実行されていること。
コンテナの起動時間と NFS ボリュームのマウント
NFS ボリューム マウントを使用すると、コンテナの起動前にボリューム マウントが開始されるため、Cloud Run コンテナのコールド スタート時間がわずかに長くなる可能性があります。コンテナは、NFS が正常にマウントされた場合にのみ起動します。
NFS は、サーバーとの接続を確立してファイル ハンドルを取得した後にのみ、ボリュームを正常にマウントします。Cloud Run がサーバーに接続できない場合、Cloud Run ジョブは起動しません。
また、Cloud Run のすべてのマウントの合計タイムアウトが 30 秒であるため、ネットワークの遅延がコンテナの起動時間に影響する可能性があります。NFS のマウントに 30 秒以上かかると、Cloud Run ジョブの開始に失敗します。
NFS のパフォーマンス特性
複数の NFS ボリュームを作成すると、すべてのボリュームが並列でマウントされます。
NFS はネットワーク ファイル システムであるため、帯域幅の制限が適用されるため、帯域幅の制限により、ファイル システムへのアクセスに影響する可能性があります。
NFS ボリュームに書き込むと、データがフラッシュされるまで書き込みは Cloud Run メモリに保存されます。データは、次の状況でフラッシュされます。
- アプリケーションが sync(2)、msync(2)、または fsync(3) を使用してファイルデータを明示的にフラッシュする。
- アプリケーションが close(2) でファイルを閉じる。
- メモリ不足のため、システム メモリ リソースの再利用が強制的に実行される。
詳細については、Linux のドキュメントで NFS の説明をご覧ください。
ボリュームとボリューム マウントを消去して削除する
すべてのボリュームとマウントを消去できます。または、個々のボリュームとボリューム マウントを削除することもできます。
すべてのボリュームとボリューム マウントを消去する
単一コンテナのジョブからすべてのボリュームとボリューム マウントを消去するには、次のコマンドを実行します。
gcloud run jobs update JOB \ --clear-volumes --clear-volume-mounts
複数のコンテナがある場合は、サイドカー CLI 規則に沿ってボリュームとボリューム マウントを消去します。
gcloud run jobs update JOB \ --clear-volumes \ --clear-volume-mounts \ --container=container1 \ --clear-volumes \ -–clear-volume-mounts \ --container=container2 \ --clear-volumes \ -–clear-volume-mounts
個々のボリュームとボリューム マウントを削除する
ボリュームを削除するには、そのボリュームを使用するすべてのボリューム マウントも削除する必要があります。
個々のボリュームまたはボリューム マウントを削除するには、remove-volume フラグと remove-volume-mount フラグを使用します。
gcloud run jobs update JOB \ --remove-volume VOLUME_NAME --container=container1 \ --remove-volume-mount MOUNT_PATH \ --container=container2 \ --remove-volume-mount MOUNT_PATH