このドキュメントでは、 Google Cloudによって割り当てられた割り当てをモニタリングするアラート ポリシーとグラフを作成する方法について、いくつかの例を示しながら説明します。Google Cloud には、プロジェクトまたは組織によって消費されるリソースの追跡や制限に使用できるさまざまな割り当てがあります。数量に基づく割り当てと頻度に基づく割り当てに関する情報など、割り当ての詳細については、Cloud Quotas の概要をご覧ください。
始める前に
このページは、時系列データとその操作に精通していることを前提としています。詳細については、次のリソースをご覧ください。
- 時系列データの操作については、フィルタリングと集計をご覧ください。
- ゲージ、デルタ、累積という用語の定義については、指標の種類をご覧ください。
- 時系列の結合に使用する関数の詳細については、
AlignerとReducerをご覧ください。
割り当て管理
Cloud Monitoring では、次の 2 つの方法で割り当てを管理します。
コンシューマー割り当て: このタイプの割り当てでは、モニタリング対象リソースは
consumer_quotaです。このリソースの指標は、serviceruntime指標のサブセットです。このページに挙げた例の多くはコンシューマー割り当てです。
リソース固有の割り当て: 一部のサービスでは、割り当てにリソース固有の指標を持つモニタリング対象リソースを提供しています。これらの指標タイプは 3 つのグループで表示され、次の命名形式に従います。
service/quota/quota-type/exceededservice/quota/quota-type/limitservice/quota/quota-type/usage
たとえば、Compute Engine には
compute.googleapis.com/VpcNetworkリソースがあります。このリソースに関連付けられている割り当て関連の指標は、compute指標のcompute.googleapis.com/quotaサブセットです。「VPC ネットワークあたりのインスタンス数」の割り当てに関連する指標タイプは次の 3 つです。quota/instances_per_vpc_network/exceededquota/instances_per_vpc_network/limitquota/instances_per_vpc_network/usage
割り当て指標と上限名を特定する
割り当て使用量に関する元データ(特にコンシューマー割り当ての場合)には、多数の異なる割り当て情報が含まれている可能性があります。グラフまたはアラート ポリシーの特定の割り当て情報を抽出するには、割り当てデータのサブセットを特定する必要があります。
ソースによっては、割り当てデータに、必要な情報を分離するために使用できるラベルが含まれている場合があります。これらのラベルには次のものがあります。
- 割り当て指標: 割り当て指標は、割り当てのタイプを示す識別子です。指標リストで説明されている指標タイプの一つではありません。たとえば、コンシューマー割り当てデータはすべて、
quota/allocation/usageのようなserviceruntime.googleapis.com指標タイプとして記述されます。この指標タイプには、割り当て対使用量のデータなどで特定の割り当てをフィルタリングするときに使用できるquota_metricラベルがあります。 - 上限名: 上限名は、特定の割り当てタイプに対する上限を示します。1 つの割り当てに複数の上限を設定できます。たとえば、読み取り呼び出しの割り当てとして、
readsPerMinuteとreadsPerDayという上限名を付け、1 分あたりの上限が 100、1 日あたりの上限が 1,000 という 2 つ上限を設定できます。割り当て関連の指標タイプには、この値としてlimit_nameフィールドが含まれる場合があります。
quota_metric ラベルはすべての serviceruntime.googleapis.com/quota 指標タイプに含まれますが、limit_name ラベルを含むのはその中の一部のみです。リソース固有の割り当て指標タイプには、limit_name ラベルが含まれます。
すべての Google Cloud サービスが割り当て指標をサポートしているわけではありません。サービスが割り当て指標をサポートしているかどうかを判断し、割り当て固有のラベルの値を特定するには、次の操作を行います。
-
Google Cloud コンソールで、[割り当てとシステム上限] ページに移動します。
このページを検索バーで検索する場合は、小見出しが「IAM と管理」の結果を選択します。
view_column(列を表示)をクリックし、割り当て表示に次の列を追加します。
- 指標: この列には
quota_metricラベルの値が表示されます。 - 上限名: この列には
limit_nameラベルの値が表示されます。 - モニタリング対象リソース: データを入力すると、割り当ては一覧表示されたモニタリング対象リソースを使用します。空の場合、割り当てのモニタリング対象リソースは
consumer_quotaです。
- 指標: この列には
目的の割り当てを見つけます。
たとえば、Compute Engine API のサブネットワーク割り当てでは、指標は
compute.googleapis.com/subnetworksとして、上限名はSUBNETWORKS-per-projectとして一覧表示されます。また、モニタリング対象リソースは一覧表示されません。したがって、この割り当てのモニタリング対象リソースはconsumer_quotaです。
例: 特定のコンシューマー割り当て指標の使用状況を表示する
Compute Engine の合計ディスク ストレージ割り当てをリージョン別に表示するグラフを作成することが目標です。このコンシューマー割り当ての例では、quota/allocation/usage データを取得した後、特定の割り当て指標の割り当て使用量が表示されるようにデータをフィルタリングします。
Google Cloud コンソールで、[Cloud Monitoring] を選択し、[Metrics Explorer] を選択します。
ツールバーで、期間メニューを開き、[過去 14 日間] を選択します。
[ウィジェット タイプ] メニューを開き、[積み上げ棒グラフ] を選択します。
数量に基づく割り当て使用量を表示するように Metrics Explorer を構成します。
- [指標を選択] をクリックし、filter_list(フィルタバー)に「
allocation」と入力します。 - リソースに [Consumer Quota] を選択します。
- 指標カテゴリの [割り当て] を選択します。
- 指標の [Allocation quota usage] を選択し、[適用] をクリックします。
- [集計] メニューを開き、[未集計] を選択します。
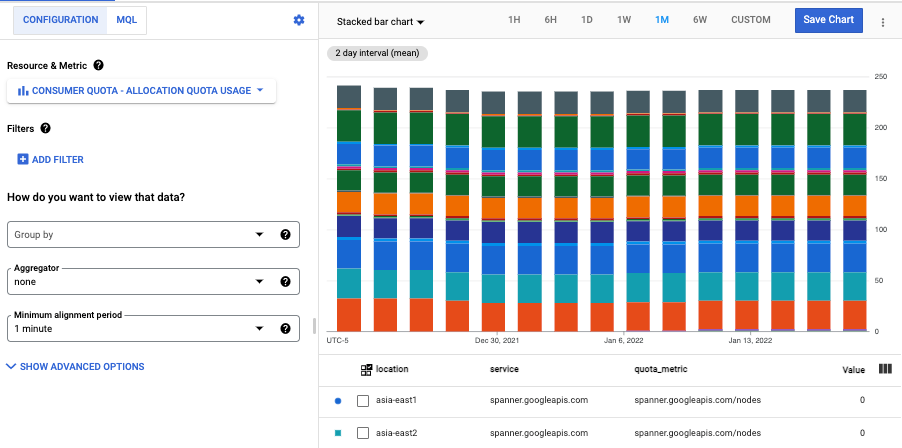
グラフには、割り当て使用量が 6 週間の棒グラフとして表示されます。凡例を表示すると、グラフに複数のサービスの割り当て使用量が表示されます。
Cloud Monitoring API を使用する場合、同等のフィルタ値は次のとおりです。
metric.type="serviceruntime.googleapis.com/quota/allocation/usage" resource.type="consumer_quota"このフィルタ値を表示するには、[リソースの種類] メニューを開き、[ダイレクト フィルタモード] を選択します。
- [指標を選択] をクリックし、filter_list(フィルタバー)に「
グラフを Compute Engine サービスに制限するには、フィルタ
service = compute.googleapis.comを追加します。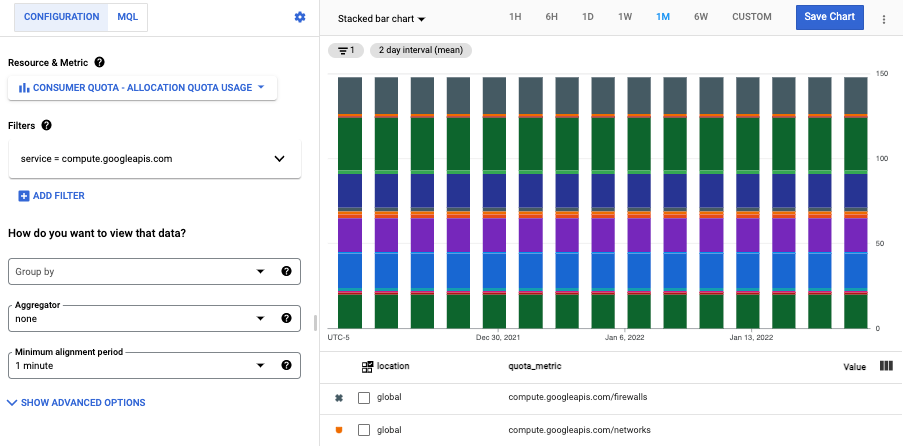
Cloud Monitoring API を使用する場合、同等のフィルタ値は次のとおりです。
metric.type="serviceruntime.googleapis.com/quota/allocation/usage" resource.type="consumer_quota" resource.label.service="compute.googleapis.com"Compute Engine 割り当てに割り当てられている割り当て使用量の時系列がグラフに表示されます。凡例には、表示されている各時系列の
quota_metricラベルの値が表示されます。この値は特定の割り当てを示します。たとえば、compute.googleapis.com/disks_total_storageは時系列が Compute Engine の合計ディスク ストレージ割り当て用であることを示します。グラフには、使用状況を記録した割り当ての割り当て使用量のみが表示されます。たとえば、プロジェクトに Compute Engine リソースがない場合、
compute.googleapis.comサービスをフィルタリングすると、データのないグラフが作成されます。Compute Engine の合計ディスク ストレージの割り当て使用量を表示するグラフを作成するには、フィルタ
quota_metric = compute.googleapis.com/disks_total_storageを使用します。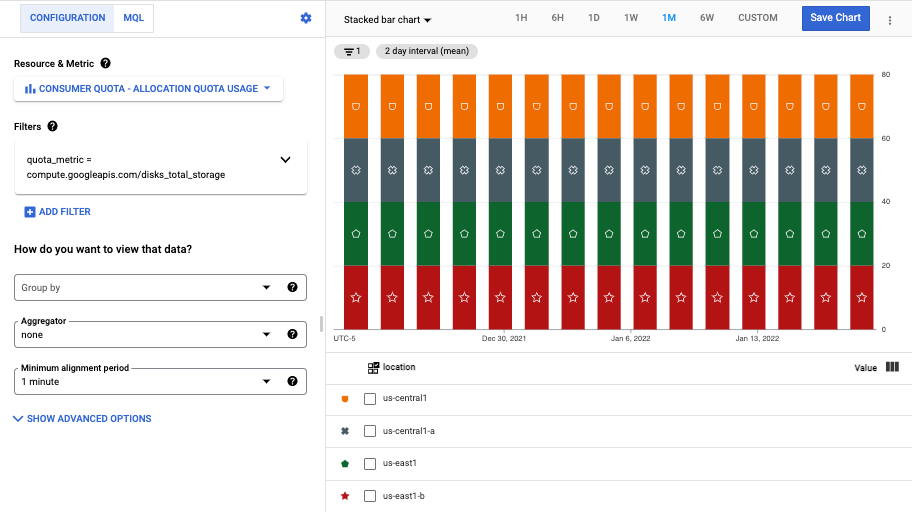
Cloud Monitoring API を使用する場合、同等のフィルタ値は次のとおりです。
metric.type="serviceruntime.googleapis.com/quota/allocation/usage" resource.type="consumer_quota" metric.label.quota_metric="compute.googleapis.com/disks_total_storage"前のグラフでは、リージョン
us-central1とus-east1の時系列と、ゾーンus-central1-aを含む複数のゾーンの時系列が表示されています。ゾーンのデータを表示せずにリージョンのデータのみを表示するようにグラフを改良するには、
locationラベルに基づくフィルタを追加します。この例で、両方のリージョンがus-で始まり1で終わる場合、正規表現location =~ ^us.*1$を使用するフィルタが正常に機能します。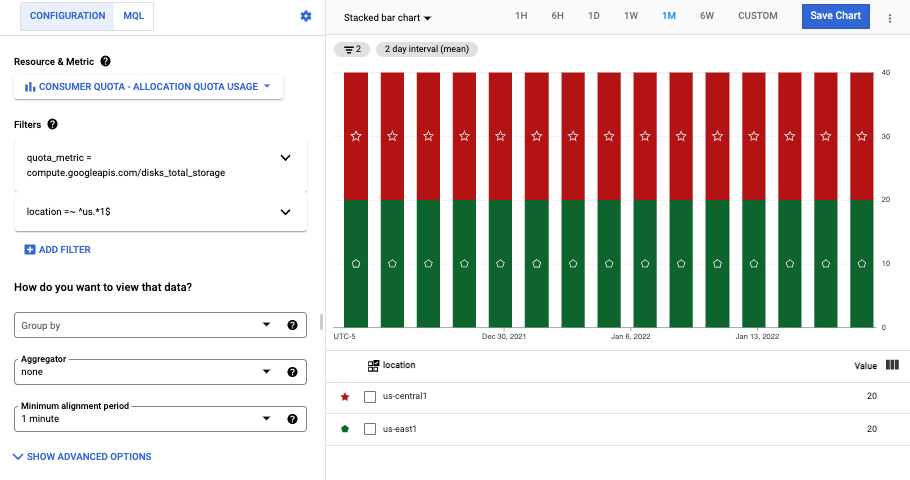
コンシューマー割り当ての場合、quota_metric ラベルの値は、サービスとモニタリング対象の特定の割り当て使用量の両方を識別します。特定の割り当て指標をモニタリングするグラフまたはアラート ポリシーを作成するときに、この情報を使用します。
Cloud Monitoring のアラート ポリシー
アラート ポリシーは、割り当て上限の 85% に達した場合などに通知を受け取れるよう Monitoring を構成する方法です。
アラート ポリシーとは、次のような条件と通知情報の集合です。
- 条件では、モニタリング対象、そのリソースの時系列データの結合方法、インシデントの生成のタイミングを記述します。アラート ポリシーには少なくとも 1 つの条件が必要です。
- 通知チャンネルは、インシデントが発生したときの通知先と通知方法を指定します。たとえば、特定のユーザーまたはグループにメールを送信するようにアラート ポリシーを構成できます。
アラート ポリシー条件を作成するには、次の 2 つの方法があります。
Monitoring フィルタを使用してデータを選択して操作する。たとえば、グラフィカル インターフェースを使用してアラート ポリシーの条件を作成するときに、フィルタを作成します。割り当て指標の操作に示す例では、フィルタを使用してグラフのデータを選択します。Monitoring API へのリクエストでフィルタを使用することもできます。
PromQL を使用してデータを選択して操作する。PromQL はテキストベースのクエリ言語です。PromQL コードエディタを使用すると、フィルタベースの手法では作成できないクエリを作成できます。比率ベースのアラート ポリシーを作成する場合は、PromQL を使用することをおすすめします。詳細については、PromQL アラート ポリシーの例をご覧ください。
このページでは、両方の手法について説明します。どちらかの手法でもグラフを作成することもできます。
フィルタ アラート ポリシーの例
このセクションの各サブセクションには、アラート ポリシーの JSON 表現と、 Google Cloud コンソールでポリシーを構成する方法を説明する 2 つの表があります。
- 最初の表は、モニタリング対象とデータの結合方法を示しています。
- 2 番目の表は、インシデントが生成されるタイミングを示しています。
以下の例は、フィルタベースのアプローチを対象としています。
これらのポリシーでは比率を計算しません。比率ベースの例については、PromQL アラート ポリシーの例をご覧ください。
quota/exceeded エラーのアラート
Google Cloud プロジェクトのいずれかのサービスが割り当て超過エラーを報告している場合に通知するアラート ポリシーを作成できます。このタイプのポリシーは、 Google Cloud コンソールまたは Cloud Monitoring API を使用して作成できます。
Google Cloud コンソールの使用
このサブセクションの以降の内容は、アラート ポリシーの条件ダイアログについて説明します。
次の表の設定を使用して、[新しい条件] ダイアログを完成させます。これらの設定では、 Google Cloud プロジェクトのすべてのサービスの serviceruntime 指標 /quota/exceeded の時系列データのモニタリングと、割り当て上限によるデータのグループ化を指定します。
| [新しい条件] ダイアログの フィールド |
値 |
|---|---|
| リソースと指標 | [リソース] メニューで、[Consumer Quota] を選択します。 [指標カテゴリ] メニューで、[割り当て] を選択します。 [指標] メニューで [Quota exceeded error] を選択します。 ( metric.type は serviceruntime.googleapis.com/quota/exceeded、resource.type は consumer_quota です)。
|
| フィルタ |
フィルタを追加することで、モニタリングするサービスのデータのみがグラフに表示されます。たとえば、Identity and Access Management サービスをモニタリングするには、以下のフィルタを追加します。service = iam.googleapis.com。 フィルタ フィールドが空の場合、利用可能なすべての指標データがグラフに含まれます。 |
| ローリング ウィンドウ | 1 m を選択 |
| ローリング ウィンドウ関数 | count true を選択
この指標は この指標では、 |
| 時系列全体 時系列集計 |
データがグループ化されると、集計フィールドは自動的に |
| 時系列全体 時系列のグループ化の基準 |
このオプションでは、 |
次の設定を使用して、[トリガーの設定] ダイアログを完成させます。これらの設定では、割り当て超過エラーの数が 1 分間に 0 個を超えると、アラート ポリシーがアラートを作成します。ここでは、値 0 が選択されています。これは、割り当て超過エラーは予期せず、割り当てを増やす必要があること、または API リクエストを減らすためにサービスを変更する必要があることを示しているためです。より高いしきい値を使用することもできます。
| [トリガーの設定] ダイアログの フィールド |
値 |
|---|---|
| 条件タイプ | Threshold |
| Alert trigger | Any time series violates |
| しきい値の位置 | Above threshold |
| しきい値 | 0 |
| 再テスト ウィンドウ | 1 分 |
Cloud Monitoring API の使用
このアラート ポリシーは、API メソッド alertPolicies.create を使用して作成できます。Cloud Monitoring API は、Google Cloud CLI またはクライアント ライブラリを使用して、直接呼び出すことができます。詳細については、ポリシーの作成をご覧ください。
JSON または YAML のアラート ポリシーの表現の詳細については、サンプル ポリシーをご覧ください。
JSON 形式のこのアラート ポリシーの表現は以下のとおりです。
{
"combiner": "OR",
"conditions": [
{
"conditionThreshold": {
"aggregations": [
{
"alignmentPeriod": "60s",
"crossSeriesReducer": "REDUCE_SUM",
"groupByFields": [
"metric.label.quota_metric"
],
"perSeriesAligner": "ALIGN_COUNT_TRUE"
}
],
"comparison": "COMPARISON_GT",
"duration": "60s",
"filter": "metric.type=\"serviceruntime.googleapis.com/quota/exceeded\" resource.type=\"consumer_quota\"",
"trigger": {
"count": 1
}
},
"displayName": "Quota exceeded error by label.quota_metric SUM",
}
],
"displayName": "Quota exceeded policy",
}
絶対値 quota/allocation/usage でのアラート
Google Cloud プロジェクトの特定のサービスの割り当て量の使用率の割り当てがユーザー指定のしきい値を超えた場合に通知するアラート ポリシーを作成できます。このタイプのポリシーは、 Google Cloud コンソールまたは Cloud Monitoring API を使用して作成できます。
Google Cloud コンソールの使用
このサブセクションの以降の内容は、アラート ポリシーの条件ダイアログについて説明します。
次の表の設定を使用して、[新しい条件] ダイアログを完成させます。これらの設定では、 Google Cloud プロジェクトの 1 つのサービスの serviceruntime 指標 /quota/allocation/usage の時系列データのモニタリングと、割り当て上限によるデータのグループ化を指定します。
| [新しい条件] ダイアログの フィールド |
値 |
|---|---|
| リソースと指標 | [リソース] メニューで、[Consumer Quota] を選択します。 [指標カテゴリ] メニューで、[割り当て] を選択します。 [指標] メニューで、[Allocation quota usage] を選択します。 ( metric.type は serviceruntime.googleapis.com/quota/allocation/usage、resource.type は consumer_quota です)。
|
| フィルタ |
フィルタを追加することで、モニタリングするサービスのデータのみがグラフに表示されます。たとえば、Identity and Access Management サービスをモニタリングするには、以下のフィルタを追加します。service = iam.googleapis.com。 フィルタ フィールドが空の場合、利用可能なすべての指標データがグラフに含まれます。 |
| ローリング ウィンドウ | 1440 m を選択期間はこの指標のサンプリング間隔に一致します。 |
| ローリング ウィンドウ関数 | next older を選択この |
| 時系列全体 時系列集計 |
データがグループ化されると、集計フィールドは自動的に |
| 時系列全体 時系列のグループ化の基準 |
このオプションでは、 |
次の設定を使用して、[トリガーの設定] ダイアログを完成させます。これらの設定により、時系列の値が 1,440 分あたり 2.5 を超える場合に、アラート ポリシーでアラートが作成されます。1,440 分は、ローリング ウィンドウと一致します。2.5 は、テストシステムの通常値よりわずかに高いため、この例では 2.5 が選択されています。モニタリングするサービスに基づいて、指標の値の想定範囲を把握したうえで、しきい値を選択する必要があります。
| [トリガーの設定] ダイアログの フィールド |
値 |
|---|---|
| 条件タイプ | Threshold |
| Alert trigger | Any time series violates |
| しきい値の位置 | Above threshold |
| しきい値 | 2.5 |
| 再テスト ウィンドウ | 1,440 分 |
Cloud Monitoring API の使用
このアラート ポリシーは、API メソッド alertPolicies.create を使用して作成できます。Cloud Monitoring API は、Google Cloud CLI またはクライアント ライブラリを使用して、直接呼び出すことができます。詳細については、ポリシーの作成をご覧ください。
JSON または YAML のアラート ポリシーの表現の詳細については、サンプル ポリシーをご覧ください。
JSON 形式のこのアラート ポリシーの表現は以下のとおりです。
{
"combiner": "OR",
"conditions": [
{
"conditionThreshold": {
"aggregations": [
{
"alignmentPeriod": "86400s",
"crossSeriesReducer": "REDUCE_SUM",
"groupByFields": [
"metric.label.quota_metric"
],
"perSeriesAligner": "ALIGN_NEXT_OLDER"
}
],
"comparison": "COMPARISON_GT",
"duration": "86400s",
"filter": "metric.type=\"serviceruntime.googleapis.com/quota/allocation/usage\" resource.type=\"consumer_quota\" resource.label.\"service\"=\"iam.googleapis.com\"",
"thresholdValue": 2.5,
"trigger": {
"count": 1
}
},
"displayName": "Allocation quota usage for iam.googleapis.com by label.quota_metric SUM",
}
],
"displayName": "Absolute quota usage policy",
}
PromQL アラート ポリシーの例
PromQL は、Monitoring フィルタを使用して作成できるものより強力で柔軟なクエリを構築できるテキストベースのクエリ言語です。比率ベースのアラート ポリシーを設定する場合は、PromQL を使用することをおすすめします。たとえば PromQL では、レートに基づく割り当ての使用量の比率を設定できます。これは、ゲージ指標(上限)とデルタ指標(レート)の比率を計算する必要があります。
PromQL ベースのアラート ポリシーを作成するには、 Google Cloud コンソールまたは Monitoring API を使用します。
Google Cloud コンソール: アラートの条件を作成する場合は、PromQL コードエディタを使用します。PromQL コードエディタを表示するには、[アラート ポリシーを作成] ダイアログのツールバーで [PromQL] をクリックします。このエディタの使用の詳細については、PromQL のコードエディタを使用するをご覧ください。
Monitoring API:
alertPolicies.createメソッドを使用して、PrometheusQueryLanguageConditionタイプの条件を指定します。この条件タイプは、PromQL クエリをフィールド値として受け取ります。PromQL で Monitoring API を使用する方法の詳細については、PromQL ベースのアラート ポリシーを作成するをご覧ください。
PromQL に固有の情報については、Cloud Monitoring の PromQL をご覧ください。PromQL ベースのアラート ポリシーの詳細については、PromQL ベースのアラート ポリシーをご覧ください。
レートに基づく割り当てと割り当て上限の比率をモニタリングするアラート ポリシー
次の PromQL クエリパターンは、特定のリソース サービスの 1 分あたりのレートが指定の上限の 80% を超えたときに通知を送信するアラート ポリシーを記述しています。
(
sum by (project_id, quota_metric, location) (increase({"serviceruntime.googleapis.com/quota/rate/net_usage", monitored_resource="consumer_quota", service="sample.googleapis.com"}[1m]))
/
max by (project_id, quota_metric, location) ({"serviceruntime.googleapis.com/quota/limit", monitored_resource="consumer_quota", service="sample.googleapis.com", limit_name="Limit"})
) > 0.8
このクエリパターンを使用するには、次の変更を行います。
sample.googleapis.comは、モニタリングするサービスに置き換えます。limit_nameのLimitは、追跡する上限に置き換えます。上限名の検索については、割り当て指標と上限名の特定をご覧ください。1mは、クエリに適したウィンドウに置き換えます。
フィルタを使用してこのクエリを作成することはできません。
ワイルドカードを使用してレートに基づく割り当ての比率をモニタリングするアラート ポリシー
PromQL では、ワイルドカード、正規表現、ブール論理を使用したフィルタリングがサポートされています。たとえば、PromQL を使用して、複数の上限を追跡し、しきい値を超えた場合に警告を出すアラート ポリシーを作成できます。
次の PromQL クエリパターンは、1 分または 1 日あたりのリソース サービスの使用率が 80% を超えたときに通知を送信するアラート ポリシーを記述するものです。
(
sum by (project_id, quota_metric, location) (increase({"serviceruntime.googleapis.com/quota/rate/net_usage", monitored_resource="consumer_quota", service=~".*"}[1m]))
/
max by (project_id, quota_metric, location) ({"serviceruntime.googleapis.com/quota/limit", monitored_resource="consumer_quota", service=~".*", limit_name=~".*PerMinute.*"})
)
or
(
sum by (project_id, quota_metric, location) (increase({"serviceruntime.googleapis.com/quota/rate/net_usage", monitored_resource="consumer_quota", service=~".*"}[23h]))
/
max by (project_id, quota_metric, location) ({"serviceruntime.googleapis.com/quota/limit", monitored_resource="consumer_quota", service=~".*", limit_name=~".*PerDay.*"})
) > 0.8
上記のクエリでは日単位整列指定子の引数が 1 日ではなく 23 時間に設定されています。PromQL に必要なデータは 23 時間 30 分のみですが、計算の目的で、整列指定子はアライメント期間に 1 時間を追加します。[1d] を使用している場合、条件には 25 時間分のデータが必要なため、条件を保存できません。
このクエリパターンを使用するには、次の変更を行います。
service=~の正規表現を、追跡するサービスの正規表現に置き換えます。- 1 つ目の比率では、次のようになります。
limit_name=~の.*PerMinute.*を、追跡する最初の上限グループの正規表現に置き換えます。上限名の検索については、割り当て指標と上限名の特定をご覧ください。1mは、上限に適したウィンドウに置き換えます。
- 2 つ目の比率では、次のようになります。
limit_name=~の.*PerDay.*を、追跡する 2 番目の上限グループの正規表現に置き換えます。23hは、上限に適したウィンドウに置き換えます。
フィルタを使用してこのクエリを作成することはできません。
1 つの上限に対する数量に基づく割り当ての使用量についての比率アラート
次の PromQL クエリパターンは、特定のリソース サービスの 1 日の数量に基づく割り当て使用量が特定の上限の 80% を超えたときにモニタリングするアラートを記述します。
(
max by (project_id, quota_metric, location) ({"serviceruntime.googleapis.com/quota/allocation/usage", monitored_resource="consumer_quota", service="sample.googleapis.com"})
/
min by (project_id, quota_metric, location) ({"serviceruntime.googleapis.com/quota/limit", monitored_resource="consumer_quota", service="sample.googleapis.com", limit_name="Limit"})
) > 0.8
このクエリパターンを使用するには、次の変更を行います。
sample.googleapis.comは、モニタリングするサービスに置き換えます。limit_nameのLimitは、追跡する上限に置き換えます。上限名の検索については、割り当て指標と上限名の特定をご覧ください。
例: 任意のリージョンでの CPU 使用率 75%
次のクエリで、Compute Engine VM インスタンスの CPU 使用量が、任意のリージョンで上限の 75% を超えたときにトリガーするアラート ポリシーを作成します。
(
max by (project_id, quota_metric, location) ({"serviceruntime.googleapis.com/quota/allocation/usage", monitored_resource="consumer_quota", service="compute.googleapis.com"})
/
min by (project_id, quota_metric, location) ({"serviceruntime.googleapis.com/quota/limit", monitored_resource="consumer_quota", service="compute.googleapis.com", limit_name="CPUS-per-project-region"})
) > 0.75
このコンシューマー割り当てポリシーでは、Compute Engine API の「CPU」割り当てで CPUS-per-project-region の上限名を使用します。上限名の検索については、割り当て指標と上限名の特定をご覧ください。
いずれかのサービスの数量に基づく割り当てをモニタリングするアラート ポリシー
PromQL では、ワイルドカード、正規表現、ブール論理を使用したフィルタリングがサポートされています。たとえば、PromQL を使用して、複数の上限やサービスを追跡するアラートを作成し、しきい値を超えた場合に警告することが可能です。
次の PromQL クエリは、いずれかのリソース サービスの 1 日あたりの数量に基づく割り当て使用量が、割り当て上限の 80% を超えたときにモニタリングするアラートを記述します。
(
max by (project_id, quota_metric, location) ({"serviceruntime.googleapis.com/quota/allocation/usage", monitored_resource="consumer_quota"})
/
min by (project_id, quota_metric, location) ({"serviceruntime.googleapis.com/quota/limit", monitored_resource="consumer_quota"})
) > 0.8
このクエリをそのまま使用することも、追跡するサービスの正規表現でサービスをフィルタすることもできます。特定のサービスでフィルタリングし、上限フィルタでワイルドカードを使用することもできます。
例: 特定のゾーンの CPU 使用率が 50% を超えた
次のクエリで、Compute Engine VM インスタンスの CPU 使用率が任意の us-central1 ゾーンの上限の 50% を超えるとトリガーされるアラート ポリシーを作成します。このクエリは、limit データを上限名とリソース ロケーションでフィルタリングします。
(
max by (project_id, quota_metric, location) ({"serviceruntime.googleapis.com/quota/allocation/usage", monitored_resource="consumer_quota", service="compute.googleapis.com"})
/
min by (project_id, quota_metric, location) ({"serviceruntime.googleapis.com/quota/limit", monitored_resource="consumer_quota", service="compute.googleapis.com", limit_name="CPUS-per-project-zone", location=~"us-central1-.*"})
)
> 0.5
このコンシューマー割り当てポリシーでは、Compute Engine API の「CPU」割り当てで CPUS-per-project-zone の上限名を使用します。上限名の検索については、割り当て指標と上限名の特定をご覧ください。
リソース固有の割り当てを使用する比率アラート
PromQL を使用すると、リソース固有の割り当て関連指標の比率を設定できます。この場合、サービス固有のモニタリング対象リソースを指定して、リソース固有の割り当て関連指標のペアに占める比率を計算します。
次のクエリパターンは、割り当ての使用量が上限の 80% を超えたことをモニタリングするアラートを記述します。
(
max by (resource_label_1, ..., resource_label_n, metric_label_1, ..., metric_label_n) ({"sample.googleapis.com/quota/samplemetric/usage", monitored_resource="sample.googleapis.com/SampleResource"})
/
min by (resource_label_1, ..., resource_label_n, metric_label_1, ..., metric_label_n) ({"sample.googleapis.com/quota/samplemetric/limit", monitored_resource="sample.googleapis.com/SampleResource"})
) > 0.8
このクエリパターンを使用するには、次の変更を行います。
sample.googleapis.comは、モニタリングするサービスに置き換えます。SampleResourceは、関連するモニタリング対象リソースに置き換えます。samplemetricは、一連の指標タイプの文字列に置き換えます。by (...)オペレーションで、リソースラベルと指標ラベルをそれぞれ一覧表示します。
例: 任意のリージョンでの CPU 使用率 75%
次の PromQL クエリは、任意のネットワーク ID の Compute Engine の instances_per_vpc_network 割り当てが 80% を超えたときにモニタリングするアラート ポリシーを設定します。
(
max by (resource_container, limit_name, location, network_id) ({"compute.googleapis.com/quota/instances_per_vpc_network/usage", monitored_resource="compute.googleapis.com/VpcNetwork"})
/
min by (resource_container, limit_name, location, network_id) ({"compute.googleapis.com/quota/instances_per_vpc_network/limit", monitored_resource="compute.googleapis.com/VpcNetwork"})
) > 0.8
このクエリでは consumer_quota ではなくリソースタイプ compute.googleapis.com/VpcNetwork が使用されており、2 つの compute.googleapis.com/quota/instances_per_vpc_network 指標(usage と limit)の比率が取られます。
例: 特定のモデルの Dialogflow 割り当て使用量
一部の使用量割り当ては DELTA タイプの指標です。このような指標の比率アラートは、異なる方法で構築する必要があります。
たとえば、次の PromQL クエリは、特定のリージョンの特定のモデルで Dialogflow の ConversationalAgentLLMTokensPerMinutePerBaseModelPerRegion 割り当ての使用量が 80% を超えたときにモニタリングするアラート ポリシーを設定します。
sum(
rate(
{"__name__"="dialogflow.googleapis.com/quota/ConversationalAgentLLMTokenConsumption/usage",
"limit_name"="ConversationalAgentLLMTokensPerMinutePerBaseModelPerRegion",
"monitored_resource"="dialogflow.googleapis.com/Location",
"location"="us-central1",
"base_model"="gemini-2.0-flash-lite-001"
}[1m]
) * 60
) by (limit_name, location, base_model)
/
sum(
max_over_time(
{"__name__"="dialogflow.googleapis.com/quota/ConversationalAgentLLMTokenConsumption/limit",
"limit_name"="ConversationalAgentLLMTokensPerMinutePerBaseModelPerRegion",
"monitored_resource"="dialogflow.googleapis.com/Location",
"location"="us-central1",
"base_model"="gemini-2.0-flash-lite-001"
}[1m]))
by (limit_name, location, base_model)
> .8
このクエリでは consumer_quota ではなくリソースタイプ dialogflow.googleapis.com/Location が使用されており、2 つの dialogflow.googleapis.com/quota/ConversationalAgentLLMTokenConsumption 指標(usage と limit)の比率が取られます。
グラフの例
グラフには、時系列データが表示されます。Metrics Explorer を使用して、グラフを作成できます。Metrics Explorer では、不要になったグラフの破棄や、ダッシュボードへの保存ができます。ダッシュボード ビューでは、グラフをダッシュボードに追加できます。
割り当てデータを表示するグラフのみを構成する場合は、「新しい条件」表の設定を使用できます。アラートの条件では、グラフ作成ツールと異なる表記を使用します。グラフ作成ツールのカスタム ダッシュボードには、Metrics Explorer のグラフや構成グラフが含まれています。| [新しい条件] ダイアログの フィールド名 |
グラフ |
|---|---|
| ローリング ウィンドウ関数 | 選択した指標と集計設定に基づいて最適に構成されます。 アライメント関数を指定するには、次の操作を行います。
|
| ローリング ウィンドウ | 最小間隔 (アクセスするには、[add クエリ要素を追加] をクリックします) |
| 時系列のグループ化の基準 (「時系列全体」セクション) |
[集計] 要素の 2 番目のメニュー |
| 時系列集計 (「時系列全体」セクション) |
[集計] 要素の最初のメニュー |
quota/rate/net_usage の時系列
Google Cloud プロジェクトのすべてのサービスで、データが割り当て指標の名前でグループ化され、使用率が表示されるように、serviceruntime 指標 quota/rate/net_usage の時系列データを表示するには、次の設定を使用します。
| [新しい条件] ダイアログの フィールド |
値 |
|---|---|
| リソースと指標 | [リソース] メニューで、[Consumer Quota] を選択します。 [指標カテゴリ] メニューで、[割り当て] を選択します。 [指標] メニューで [Rate quota usage] を選択します。 ( metric.type は serviceruntime.googleapis.com/quota/rate/net_usage、resource.type は consumer_quota です)。
|
| フィルタ |
フィルタを追加することで、モニタリングするサービスのデータのみがグラフに表示されます。たとえば、Identity and Access Management サービスをモニタリングするには、以下のフィルタを追加します。service = iam.googleapis.com。 フィルタ フィールドが空の場合、利用可能なすべての指標データがグラフに含まれます。 |
| ローリング ウィンドウ | 1 m を選択1 分間の期間が、この指標のサンプリング間隔と一致します。 |
| ローリング ウィンドウ関数 | rate を選択
整列指定子を |
| 時系列全体 時系列集計 |
データがグループ化されると、集計フィールドは自動的に |
| 時系列全体 時系列のグループ化の基準 |
このオプションでは、 |
quota/instances_per_vpc_network/limit の時系列
Google Cloud プロジェクトのすべてのネットワークについて compute.googleapis.com 指標 quota/instances_per_vpc_network/limit の時系列データを表示するには、次の設定を使用します。
| [新しい条件] ダイアログの フィールド |
値 |
|---|---|
| リソースと指標 | [リソースの種類] メニューで、[VPC ネットワーク] を選択します。 [指標カテゴリ] メニューで、[割り当て] を選択します。 [指標] メニューで [Instances per VPC Network quota limit] を選択します。 ( metric.type は compute.googleapis.com/quota/instances_per_vpc_network/limit、resource.type は compute.googleapis.com/VpcNetwork です)。
|
| フィルタ | 空白のまま |
| ローリング ウィンドウ | 1 m を選択期間はこの指標のサンプリング間隔に一致します。 |
| ローリング ウィンドウ関数 | mean を選択 |
| 時系列全体 時系列集計 |
none のまま |
| 時系列全体 時系列のグループ化の基準 |
空白のまま |
quota/instances_per_vpc_network/usage の時系列
Google Cloud プロジェクトのネットワークのうちの 1 つについて、compute.googleapis.com 指標 quota/instances_per_vpc_network/usage の時系列データを表示するには、次の設定を使用します。
| [新しい条件] ダイアログの フィールド |
値 |
|---|---|
| リソースと指標 | [リソースの種類] メニューで、[VPC ネットワーク] を選択します。 [指標カテゴリ] メニューで、[割り当て] を選択します。 [指標] メニューで [Instances per VPC Network quota usage] を選択します。 ( metric.type は compute.googleapis.com/quota/instances_per_vpc_network/usage、resource.type は compute.googleapis.com/VpcNetwork です)。
|
| 指標 | [指標] メニューで [compute.googleapis.com/quota/instances_per_vpc_network/usage] を選択します。 |
| フィルタ |
すべてのデータのサブセットのみがグラフに表示されるよう、フィルタを追加します。たとえば、特定のネットワークの使用状況を表示するには、次のフィルタを追加します。 network_id = identifier フィルタ フィールドが空の場合、利用可能なすべての指標データがグラフに含まれます。 |
| ローリング ウィンドウ | 1 m を選択期間はこの指標のサンプリング間隔に一致します。 |
| ローリング ウィンドウ関数 | mean を選択 |
| 時系列全体 時系列集計 |
none のまま |
| 時系列全体 時系列のグループ化の基準 |
空白のまま |
PromQL グラフ
PromQL コードエディタを使用して、PromQL クエリでグラフを作成できます。たとえば、PromQL アラート ポリシーの例に表示されているクエリをコードエディタに入力できます。各クエリの末尾にある比較演算子(> 0.8 など)は省略できます。これは、アラート ポリシーの条件を作成する場合にのみ適用されます。グラフでは、比較演算子で条件を設定しても何も行われません。
詳細については、PromQL のコードエディタを使用するをご覧ください。