Questa pagina fornisce una panoramica della replica tra regioni per Memorystore for Redis Cluster.
Per istruzioni sulla gestione della replica tra regioni, vedi Utilizzare la replica tra regioni.
La replica tra regioni consente di creare cluster secondari da un cluster principale per rendere il cluster disponibile per le letture in regioni diverse. I cluster secondari forniscono anche ridondanza per gli scenari di ripristino di emergenza in caso di interruzioni a livello di regione.
I concetti chiave di questa pagina includono:
- Cluster principale. Un cluster di lettura e scrittura in un'unica regione.
- Cluster secondari. Un cluster secondario è un cluster di sola lettura che esegue la replica dal cluster primario in modo asincrono. Per informazioni sulla promozione e sul distacco dei secondari, consulta le sezioni Switchover e Distacco di Come utilizzare la replica tra regioni.
- Nodo replicatore. Un nodo nello shard del cluster primario che viene replicato in un nodo follower nel cluster secondario. Qualsiasi nodo primario o di replica nello shard può svolgere il ruolo di replicatore.
- Nodi follower. Nodi nel cluster secondario che eseguono la replica da un nodo replicatore nel cluster primario. Solo i nodi primari nel cluster secondario possono avere il ruolo di follower.
- Conteggio shard e assegnazione slot. I cluster primario e secondario hanno lo stesso numero di shard e assegnazioni di slot.
Vantaggi
I vantaggi della replica tra regioni su Memorystore for Redis Cluster includono:
- Ripristino di emergenza. Se la regione del cluster primario non è più disponibile, puoi eseguire il failover o scollegare un cluster secondario in un'altra regione per gestire le richieste di lettura e scrittura. I cluster secondari sono sempre pronti a gestire le richieste di lettura senza emettere un comando di switchover o distacco.
- Dati distribuiti geograficamente. La distribuzione geografica dei dati li avvicina a te e riduce la latenza di lettura.
- Bilanciamento del carico geografico per il traffico di lettura. In caso di connessioni lente o sovraccariche in una regione, puoi instradare il traffico verso un'altra regione.
Funzionamento
Questa sezione spiega un importante comportamento della replica tra regioni di cui devi essere a conoscenza.
- Scalabilità della capacità dell'istanza. Quando ridimensioni la capacità dell'istanza del cluster primario, i cluster secondari vengono scalati automaticamente in modo che corrispondano al cluster primario.
- Scalabilità del numero di repliche. Puoi scalare il conteggio delle repliche per i cluster primari e secondari in modo indipendente in base alle esigenze del tuo workload. Gli aggiornamenti al conteggio delle repliche sono locali e non vengono propagati ad altri cluster all'interno della raccolta di cluster di replica tra regioni.
- Passaggio durante una potenziale interruzione. Puoi eseguire un failover per promuovere un cluster secondario, anche se il cluster primario non è disponibile a causa di un'interruzione. In questo scenario, il cluster primario non disponibile alla fine diventa un cluster secondario quando l'interruzione viene risolta.
- Creazione del cluster secondario online. Quando aggiungi un cluster secondario a un cluster primario, il cluster primario rimane online. La VM principale gestisce le richieste mentre la VM secondaria viene creata e replica i dati.
- Cluster secondari. Puoi avere fino a due secondari. Possono trovarsi in tutte le regioni disponibili. Se vuoi, possono trovarsi in regioni diverse tra loro. Un cluster esistente non può essere reso secondario. Solo i nuovi cluster possono essere aggiunti come cluster secondari a un cluster esistente.
- Impostazioni sincronizzate. La maggior parte delle impostazioni viene sincronizzata automaticamente tra i cluster primario e secondario. Per ulteriori informazioni su queste impostazioni, vedi Impostazioni del cluster.
- Prezzi. Ai clienti che utilizzano la replica tra regioni verranno addebitati i costi per tutti i cluster secondari di cui è stato eseguito il provisioning per la replica tra regioni. Per ogni nodo e replica di cui è stato eseguito il deployment sul cluster secondario, ai clienti viene addebitato l'importo previsto per qualsiasi altro cluster primario. Inoltre, i clienti sostengono costi di networking per il trasferimento di dati tra cluster in regioni diverse.
- Aggiornamento di manutenzione. Per garantire la compatibilità con la replica tra regioni, durante la creazione del cluster secondario, il cluster primario potrebbe essere sottoposto a un aggiornamento di manutenzione se non esegue già la versione software richiesta. Questo processo di aggiornamento potrebbe introdurre una latenza aggiuntiva durante la creazione del cluster secondario. Per saperne di più sulla manutenzione, consulta Informazioni sulla manutenzione.
Come utilizzare la replica tra regioni
L'utilizzo della replica tra regioni di Memorystore for Redis Cluster comporta le seguenti attività:
- Crea un cluster secondario. Crea un cluster secondario che esegue la replica continua dal cluster primario.
- Visualizza un cluster secondario. Puoi visualizzare informazioni su un cluster secondario, inclusi il nome del cluster primario e l'altro cluster secondario nel gruppo di replica.
Scollega i cluster secondari. Lo scollegamento dei cluster secondari è un'operazione in cui i cluster secondari vengono scollegati dal cluster principale. In questo modo, diventano cluster indipendenti e completamente funzionali che consentono operazioni di lettura e scrittura. Dopo un'operazione di scollegamento, i cluster secondari non replicano più i dati dal cluster principale a cui erano precedentemente associati. Sia il cluster primario originale sia i cluster appena scollegati (ex secondari) funzionano come cluster indipendenti senza alcuna relazione tra loro.
Esistono due scenari principali per il distacco dei cluster secondari:
- Migrazione regionale. Esegui una migrazione pianificata delle risorse Memorystore for Redis Cluster dalla regione primaria a un'altra regione.
- Ripristino di emergenza. Attiva rapidamente le risorse Memorystore for Redis Cluster in una regione secondaria nel caso in cui le risorse nella regione principale non siano più disponibili. Se i cluster secondari non sono stati completamente sincronizzati con il cluster primario, potrebbe verificarsi una perdita di dati.
Esegui il cambio dei cluster. Un failover consente di invertire i ruoli del cluster primario e secondario. Puoi eseguire un failover per testare la configurazione di ripristino di emergenza, durante uno scenario di ripristino di emergenza reale o per eseguire la migrazione del tuo workload. Al termine del cambio, la direzione della replica viene invertita e il vecchio cluster secondario è in grado di accettare sia letture che scritture, mentre il vecchio cluster primario passa alla modalità di sola lettura.
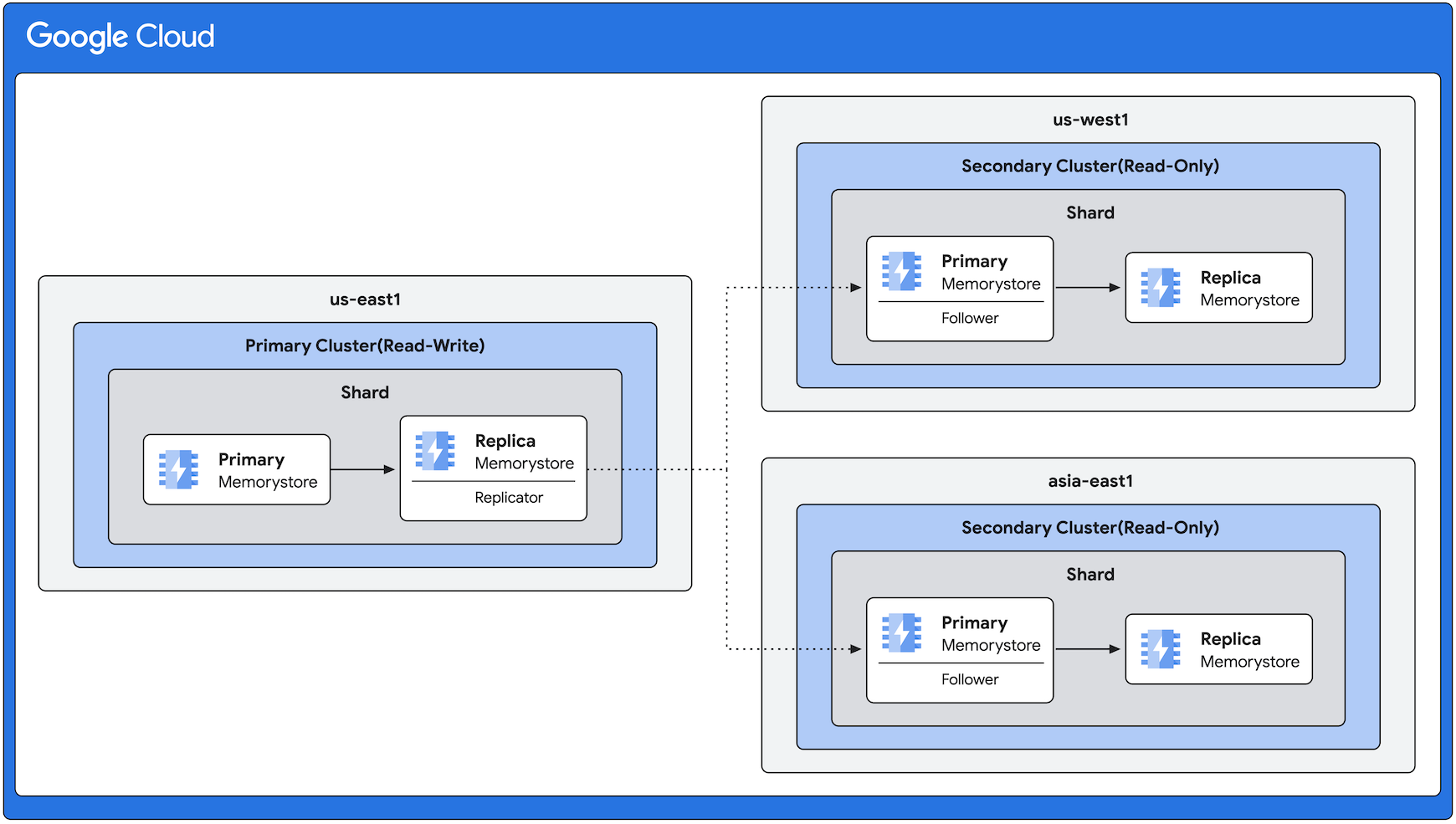
Esempio di architettura di replica tra regioni
Il seguente diagramma mostra un cluster principale nella regione us-east1 con cluster secondari in us-west1 e asia-east1. La direzione della replica è sempre da us-east1 alle altre regioni. Tieni presente che, anche se il seguente diagramma mostra lo stesso numero di repliche in tutte le regioni, la funzionalità di replica tra regioni ti offre la flessibilità di avere un numero variabile di repliche in base ai tuoi requisiti.
Impostazioni cluster
Questa sezione spiega quali impostazioni sono richieste, copiate e sostituite per i cluster primari e secondari che utilizzano la replica tra regioni. Spiega inoltre quali impostazioni sono configurate sull'istanza primaria e quali sono configurate localmente.
Parametri obbligatori per la creazione di un cluster secondario
- Progetto Google Cloud. Questo è il progetto in cui si trova il cluster primario e in cui verrà creato il cluster secondario.
- Regione. Questa è la regione in cui vuoi posizionare il cluster secondario.
- Configurazione di Private Service Connect. Questa è la configurazione di rete per il tuo cluster.
- Cluster principale. Quando crei il cluster secondario, devi indicare un cluster primario. Qualsiasi cluster diverso da un cluster secondario può essere utilizzato come cluster primario. Se non hai un cluster primario, devi prima crearne uno.
Impostazioni copiate dall'istanza principale durante la creazione dell'istanza
Durante la creazione del cluster secondario, quest'ultimo copia le seguenti impostazioni dal cluster primario:
- Numero di shard
- Modalità di autenticazione IAM
- Modalità di crittografia dei dati in transito
- Configurazioni del motore Redis
- Versione del motore Redis
- Tipo di nodo
- Modalità Persistenza
Override consentito durante la creazione dell'istanza
Le seguenti impostazioni consentono di eseguire l'override del valore predefinito durante la creazione dell'istanza.
- Configurazione della distribuzione delle zone
- Numero repliche
- Periodi di manutenzione
- Protezione da eliminazione
- Backup automatici
Aggiornare le impostazioni del cluster
Quando aggiorni le impostazioni del cluster, alcune impostazioni possono essere modificate solo sul cluster primario e le modifiche vengono sincronizzate automaticamente con i cluster secondari. Altre impostazioni possono essere modificate indipendentemente sui cluster primario e secondario e vengono applicate solo localmente e non sincronizzate con gli altri cluster.
Imposta su principale
Le seguenti impostazioni devono essere modificate sul nodo primario e l'aggiornamento viene sincronizzato con il nodo secondario:
Imposta in locale
Puoi configurare queste impostazioni localmente:
- Protezione da eliminazione
- Numero repliche
- Periodi di manutenzione
- Endpoint del cluster
- Backup automatici
Best practice per il cambio di fornitore
Quando esegui un cambio, ti consigliamo di seguire le istruzioni riportate in questa sezione in modo che l'applicazione possa tenere traccia delle scritture e inviarle al cluster appropriato.
- Impedisci alla tua applicazione di scrivere nel cluster primario.
Determina il cluster secondario da promuovere (se sono presenti più cluster secondari tra cui scegliere). Di seguito sono riportati alcuni fattori che potrebbero aiutarti a determinare quale secondario promuovere:
La vicinanza dell'applicazione al cluster. Ciò potrebbe influire sulla latenza di scrittura.
Il cluster più aggiornato in termini di dati.
Il cluster più vicino in termini di impostazioni ai cluster principali.
Attendi il completamento dell'operazione di switchover.
Aggiorna l'applicazione per inviare le scritture al cluster appena promosso che hai scelto nel passaggio 2.