This page provides an overview of cross-region replication for Memorystore for Redis Cluster.
For instructions on managing cross-region replication, see Work with cross-region replication.
Cross-region replication lets you create secondary clusters from a primary cluster to make your cluster available for reads in different regions. Secondary clusters also provide redundancy for disaster recovery scenarios in case of regional outages.
Key concepts in this page include the following:
- Primary cluster. A read-write cluster in a single region.
- Secondary cluster(s). A secondary cluster is a read-only cluster that replicates from the primary cluster asynchronously. For information about promoting and detaching secondaries, see the switchover and detach sections of How to work with cross-region replication.
- Replicator node. A node in the primary cluster's shard that replicates to a follower node in the secondary cluster. Any primary or replica node in the shard can serve the role of a replicator.
- Follower nodes. Nodes in the secondary cluster that replicate from a replicator node in the primary cluster. Only primary nodes in the secondary cluster can have the role of a follower.
- Shard count and slot assignment. Primary and secondary clusters have the same number of shards and slot assignments.
Benefits
The benefits of cross-region replication on Memorystore for Redis Cluster include the following:
- Disaster recovery. In the event the primary cluster's region becomes unavailable, you can switchover to or detach a secondary cluster in another region to serve read and write requests. The secondary clusters are always ready to serve read requests without issuing a switchover or detach command.
- Geographically distributed data. Distributing the data geographically brings the data closer to you and decreases read latency.
- Geographic load balancing for read traffic. In the event of slow or overloaded connections in one region, you can route traffic to another region.
Feature behavior
This section explains important cross-region replication behavior that you should be aware of.
- Scaling instance capacity. When you scale the instance capacity of the primary cluster, secondary clusters are automatically scaled to match the primary.
- Scaling replica count. You can scale the replica count for primary and secondary clusters independently based on your workload needs. Updates to replica count are local only and don't propagate to other clusters within the Cross-Region Replication collection of clusters.
- Switchover during a potential outage. You can perform a switchover to promote a secondary cluster, even if the primary cluster is unavailable due to an outage. In this scenario, the unavailable primary eventually becomes a secondary cluster when the outage is resolved.
- Online secondary cluster creation. When adding a secondary cluster to a primary cluster, the primary cluster stays online. The primary serves requests while the secondary is created and replicates data.
- Secondary clusters. You can have up to two secondaries. They can be located in all available regions. If you want, they can all be located in different regions from each other. An existing cluster cannot be made a secondary cluster. Only new clusters can be added as secondary clusters to an existing cluster.
- Synchronized settings. Most settings are automatically synchronized between primary and secondary clusters. For more information about these settings, see Cluster settings.
- Pricing. Customers using cross-region replication will be charged for any secondary clusters provisioned for cross-region replication. For each node and replica deployed on the secondary cluster, customers are be charged as per any other primary cluster. Additionally, customers incur networking charges for data transfer between clusters in different regions.
- Maintenance update. To ensure compatibility with cross-region replication, while creating your secondary cluster your primary cluster may undergo a maintenance update if it's not already running the required software version. This update process may introduce some additional latency when creating your secondary cluster. For more information about maintenance, see About maintenance.
How to work with cross-region replication
Working with Memorystore for Redis Cluster cross-region replication involves the following tasks:
- Create a secondary cluster. You create a secondary cluster that continuously replicates from your primary cluster.
- View a secondary cluster. You can view information about a secondary cluster, including the primary cluster name and the other secondary cluster in the replication group.
Detach secondary clusters. Detaching secondary clusters is an operation in which you decouple secondary clusters from their primary cluster. This makes them fully functional, independent clusters that allow both reads and writes. After a detach operation, the secondary clusters no longer replicate data from the primary cluster with which they were associated formerly. Both the original primary cluster and the newly detached clusters (former secondaries) function as independent clusters with no relationship to one another.
There are two main scenarios for detaching secondary clusters:
- Regional migration. Perform a planned migration of the Memorystore for Redis Cluster resources from their primary region to another region.
- Disaster recovery. Rapidly activate the Memorystore for Redis Cluster resources in a secondary region in the event that the resources in the primary region become unavailable. If the secondary clusters were not fully caught up to the primary cluster, some data loss might occur.
Switchover your clusters. A switchover lets you reverse the roles of your primary and secondary cluster. You can perform a switchover for testing your disaster recovery setup, during a real disaster recovery scenario, or to perform a migration of your workload. When you complete the switchover, the direction of replication is reversed and the old secondary cluster is able to accept both reads and writes while the old primary cluster switches to read-only.
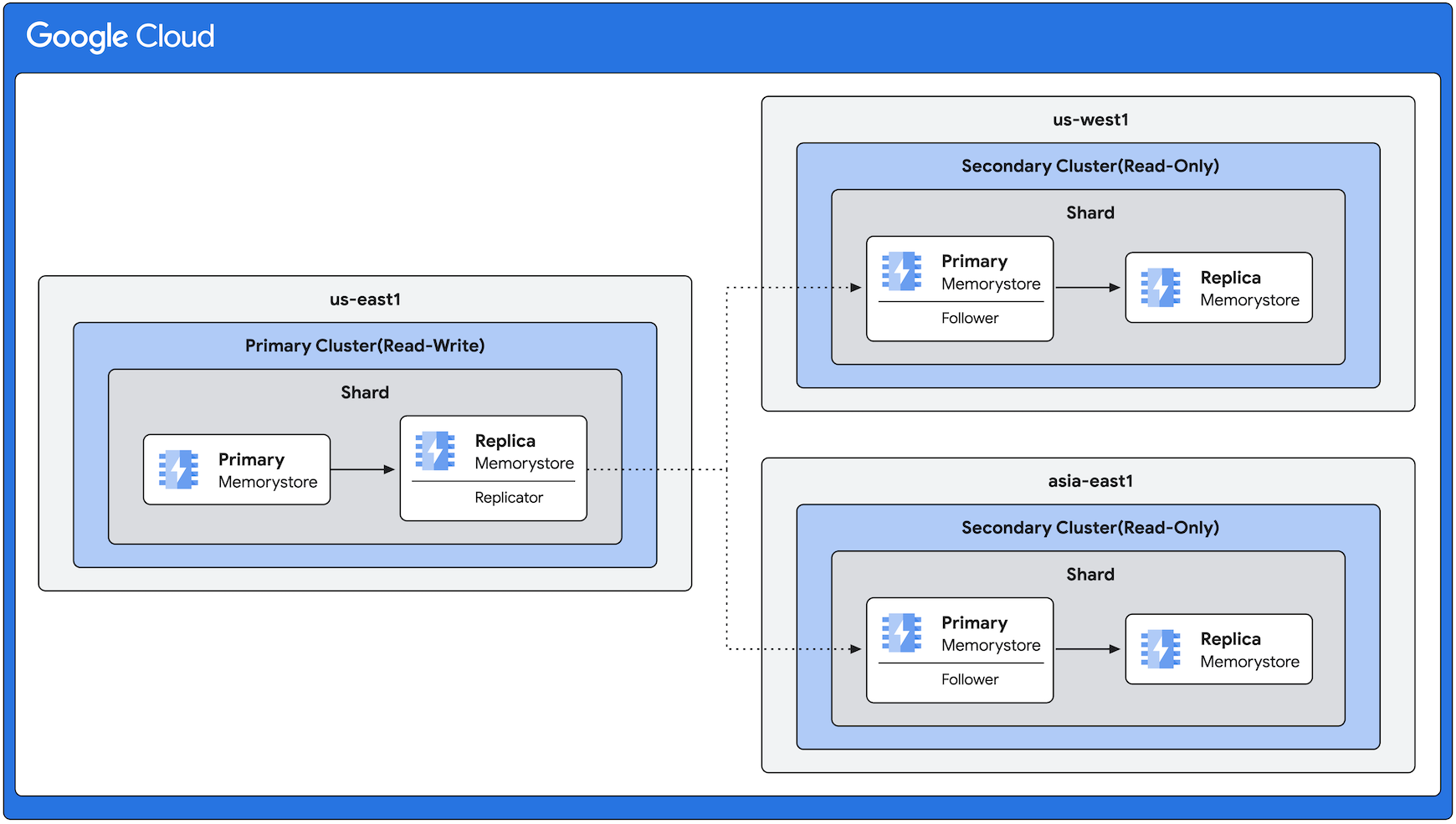
Cross-region replication architecture example
The following diagram shows a primary cluster in region us-east1 with secondary clusters in us-west1 and asia-east1. The direction of replication is always from us-east1 to the other regions. Note that even though the following diagram shows the same number of replicas in all regions, the cross-region replication feature gives you the flexibility to have varying numbers of replicas according to your requirements.
Cluster settings
This section explains which settings are required, copied, overridden for primary and secondary clusters that use cross-region replication. It also explains which settings are configured on the primary, and which are configured locally.
Required parameters for creating a secondary cluster
- Google Cloud project. This is the project where your primary cluster is located, and also where the secondary cluster will be created.
- Region. This is the region where you want to place your secondary cluster.
- Private Service Connect configuration. This is the networking setup for your cluster.
- Primary cluster. You are required to indicate a primary cluster for your secondary cluster when creating the secondary. Any cluster other than a secondary cluster can be used as a primary cluster. If you don't have a primary cluster, you should create it first.
Settings copied from the primary during instance creation
During secondary cluster creation, the secondary copies the following settings from the primary cluster:
- Shard count
- IAM auth mode
- In-transit encryption mode
- Redis engine configurations
- Redis engine version
- Node type
- Persistence mode
Override allowed during instance creation
The following settings allow an override of the default during instance creation.
- Zone distribution configuration
- Replica count
- Maintenance Windows
- Deletion protection
- Automated backups
Update cluster settings
When updating cluster settings, some settings can only be changed on the primary and the changes are automatically synced to the secondary clusters eventually. Other settings can be changed independently on primary and secondary clusters, and these are applied only locally, and not synced to the other clusters.
Set on primary
The following settings must be changed on the primary, and the update is synced to the secondary:
Set locally
You configure these settings locally:
Switchover best practices
When performing a switchover, we recommend following the instructions in this section so your application can keep track of writes, and send writes to the appropriate cluster.
- Stop your application from writing to the primary cluster.
Determine the secondary cluster to promote (if there are multiple secondaries to choose from). Some factors that could help in determining which secondary to promote are as follows:
The proximity of your application to the cluster. This could affect write latency.
The cluster that is most caught up in terms of data.
The cluster that is closest in terms of settings to primary clusters.
Wait for the switchover operation to complete.
Update the application to send the writes to the newly promoted cluster you chose in step 2.