This page explains how Memorystore for Redis Cluster architecture supports and provides high availability (HA). This page also explains recommended configurations that contribute to improved instance performance and stability.
For more information about region-specific considerations, see Geography and regions.
High availability
Memorystore for Redis Cluster is built on a highly available architecture where your clients directly access managed Memorystore for Redis Cluster VMs. Your clients do this by connecting to individual shard network addresses, as described in Connect to a Memorystore for Redis Cluster instance.
Connecting directly to shards provides the following benefits:
Direct connection avoids any single point of failure because each shard is designed to fail independently. For example, if traffic from multiple clients overloads a slot (keyspace chunk), shard failure limits the impact to the shard responsible for serving the slot.
Direct connection avoids intermediate hops, which minimizes round-trip time (client latency) between your client and the Redis VM.
Recommended configurations
We recommend creating highly available multi-zone instances as opposed to single-zone instances because of the better reliability they provide. However, if you choose to provision an instance without replicas, we recommend choosing a single-zone instance. For more information, see Choose a single-zone instance if your instance doesn't use replicas.
To enable high availability for your instance, you must provision at least 1 replica node for every shard. You can do this when Creating the instance, or you can Scale the replica count to at least 1 replica per shard. Replicas provide Automatic failover during planned maintenance and unexpected shard failure.
You should configure your client according to the guidance in Redis client best practices. Using recommended best practices allows your OSS Redis client to automatically and gracefully handle the role (automatic failovers), and slot assignment changes (node replacement, consumer scale out/in) for your cluster without any downtime.
Replicas
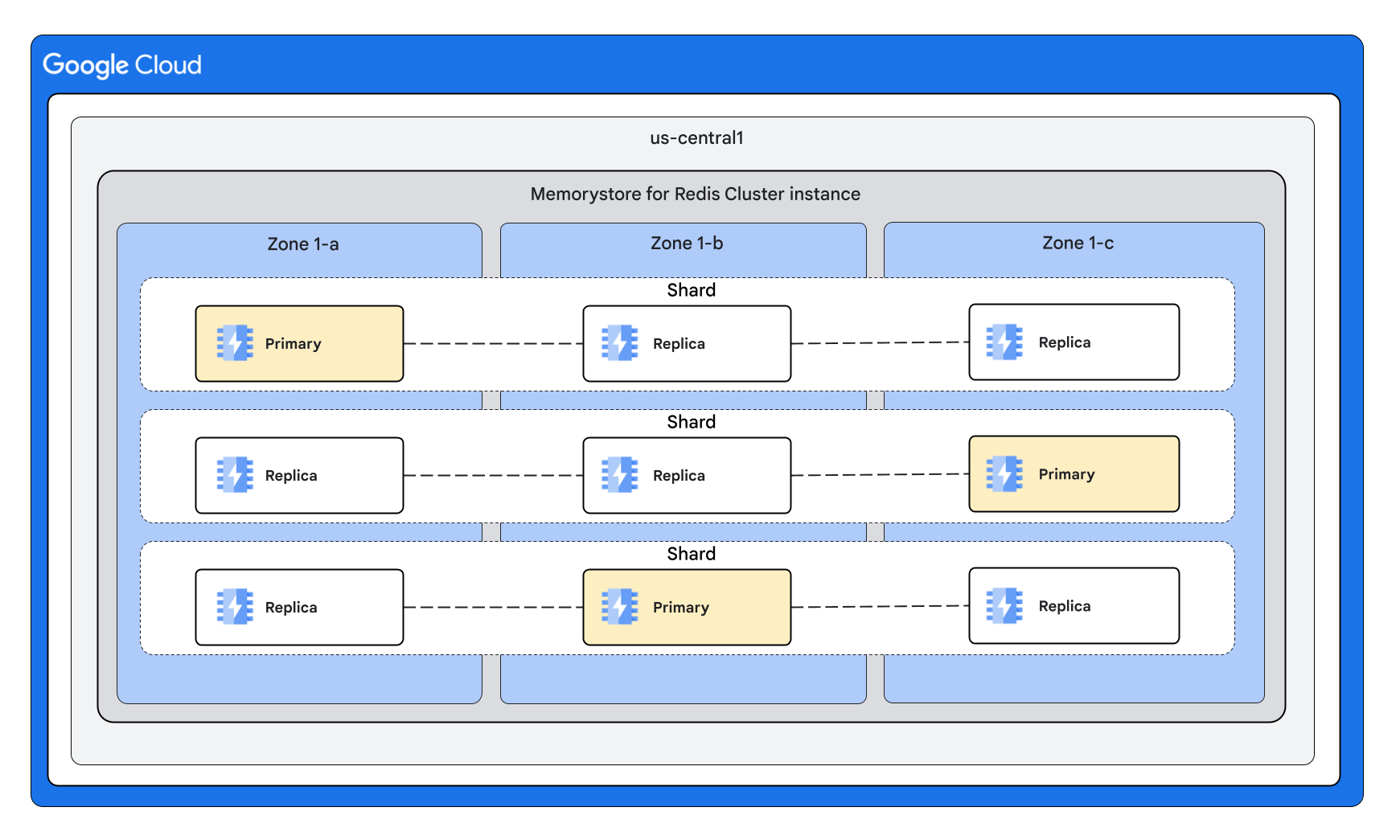
A highly available Memorystore for Redis Cluster instance is a regional resource. This means that the primary and the replica VMs of shards are distributed across multiple zones to safeguard against a zonal outage. Memorystore for Redis Cluster supports instances with 0-5 replicas per node.
You can use replicas to increase read throughput by scaling reads.
To do this, you must use the READONLY command to establish a connection
that allows your client to read from replicas. For more details about reading
from replicas, see Scale with Redis Cluster.
Cluster shape with 0 replicas per node
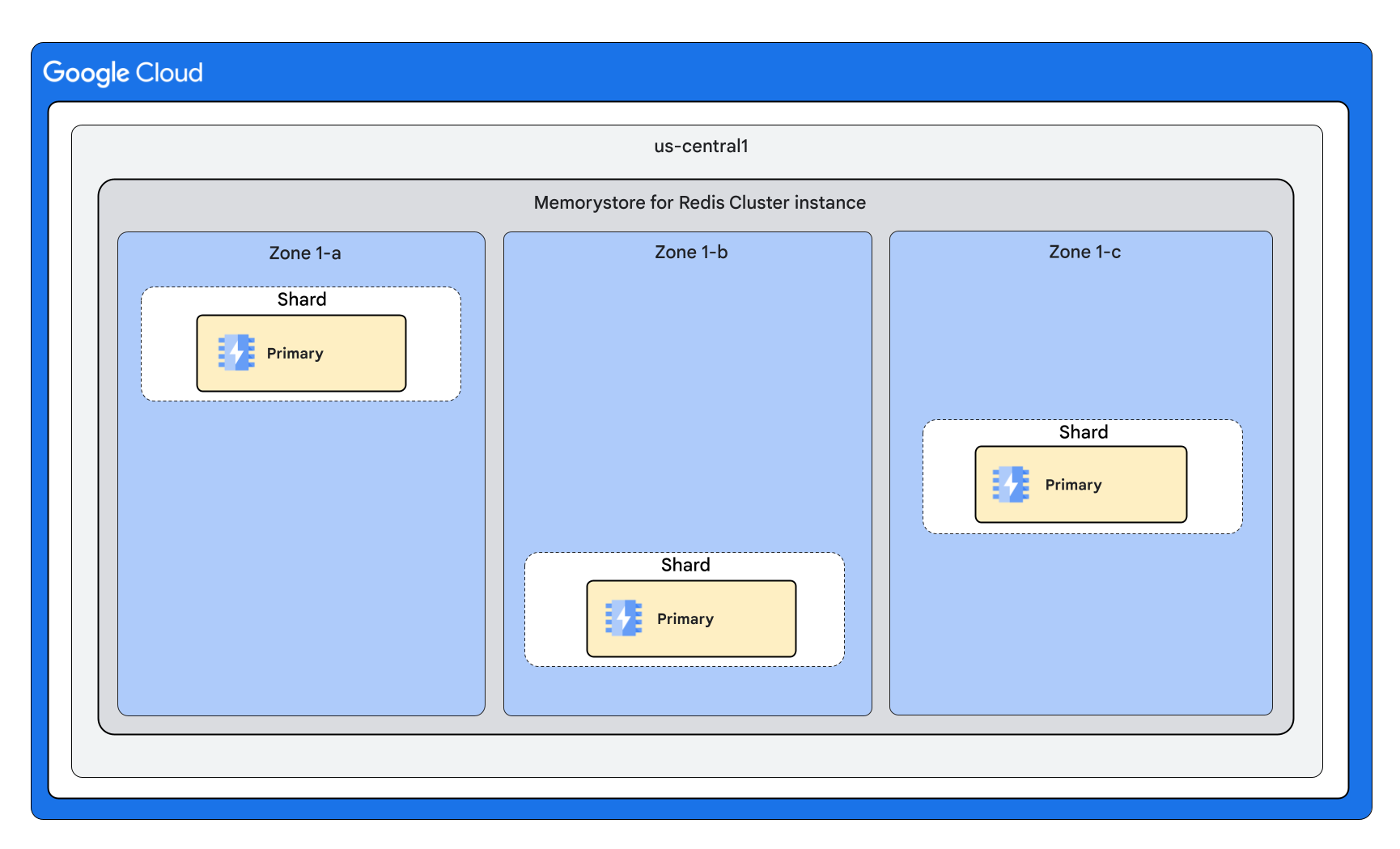
Cluster shape with 1 replica per node
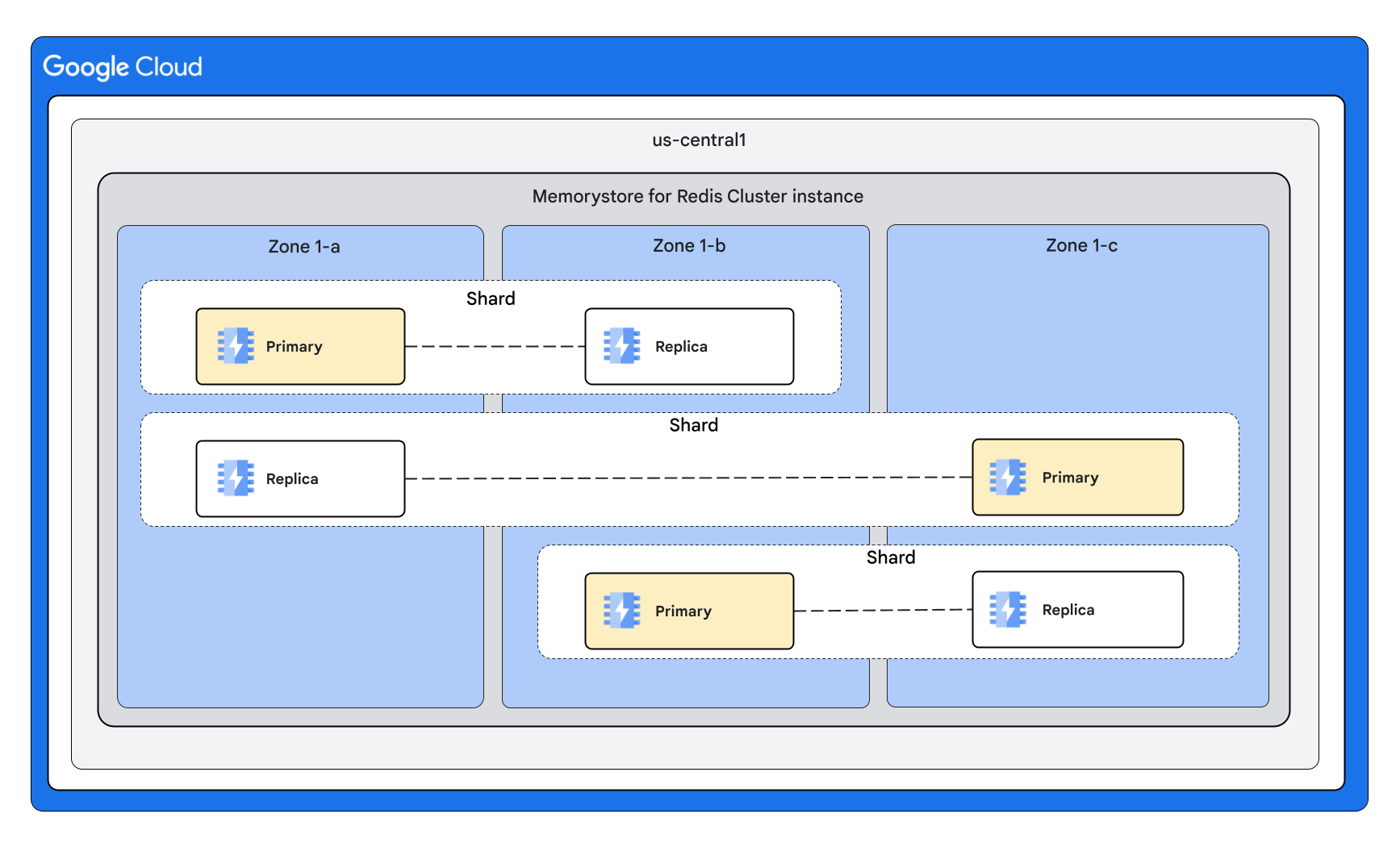
Cluster shape with multiple replicas per node
Automatic failover
Automatic failovers within a shard can occur due to maintenance or an unexpected failure of the primary node. During a failover a replica is promoted to be the primary. You can configure replicas explicitly. The service can also temporarily provision extra replicas during internal maintenance to avoid any downtime.
Automatic failovers prevent data-loss during maintenance updates. For details about automatic failover behavior during maintenance, see Automatic failover behavior during maintenance.
Failover and node repair duration
Automatic failovers can take time on the order of tens of seconds for unplanned events such as a primary node process crash, or a hardware failure. During this time the system detects the failure, and elects a replica to be the new primary.
Node repair can take time on the order of minutes for the service to replace the failed node. This is true for all primary and replica nodes. For instances that aren't highly available (no replicas provisioned), repairing a failed primary node also takes time on the order of minutes.
Client behavior during an unplanned failover
Client connections are likely to be reset depending on the nature of the failure. After automatic recovery, connections should be retried with exponential backoff to avoid overloading primary and replica nodes.
Clients using replicas for read throughput should be prepared for a temporary degradation in capacity until the failed node is automatically replaced.
Lost writes
During a failover resulting from an unexpected failure, acknowledged writes may be lost due to the asynchronous nature of Redis's replication protocol.
Client applications can leverage the Redis WAIT command to improve real world data safety. It is a best-effort approach that comes with trade-offs as explained in Redis WAIT command documentation.
Keyspace impact of a single zone outage
This section describes the impact of a single zone outage on a Memorystore for Redis Cluster instance.
Multi-zone instances
HA instances: If a zone has an outage, the entire keyspace is available for reads and writes, but since some read replicas are unavailable, the read capacity is reduced. We strongly recommend over-provisioning cluster capacity so that the instance has enough read capacity, in the rare event of a single zone outage. Once the outage is over, replicas in the affected zone are restored and the read capacity of the cluster returns to its configured value. For more information, see Patterns for scalable and reliable apps.
Non-HA instances (no replicas): If a zone has a outage, the portion of the keyspace that is provisioned in the affected zone undergoes a data flush, and is unavailable for writes or reads for the duration of the outage. Once the outage is over, primaries in the affected zone are restored and the capacity of the cluster returns to its configured value.
Single-zone instances
- Both HA and Non-HA instances: If the zone that the instance is provisioned in has an outage, the cluster is unavailable and data is flushed. If a different zone has an outage, the cluster continues to serve read and write requests. Once the outage is over, the configured capacity of the cluster is restored.
Best practices
This section describes best practices for high availability and replicas.
Add a replica
Adding a replica requires an RDB snapshot. RDB snapshots use a process fork and 'copy-on-write' mechanism to take a snapshot of node data. Depending on the pattern of writes to nodes, the used memory of the nodes grows as pages touched by the writes are copied. The memory footprint can be up to double the size of the data in the node.
To ensure that nodes have sufficient memory to complete the snapshot, keep or
set maxmemory at 80% of
the node capacity so that 20% is reserved for overhead. This memory overhead, in
addition to monitoring snapshots, helps you manage your workload to have
successful snapshots. Also, when you add replicas, lower write traffic as much
as possible. For more information, see Monitor a cluster that has a high write load.