Diese Seite bietet einen Überblick über die regionenübergreifende Replikation für Memorystore for Redis Cluster.
Eine Anleitung zum Verwalten der regionsübergreifenden Replikation finden Sie unter Regionsübergreifende Replikation nutzen.
Mit der regionenübergreifenden Replikation können Sie sekundäre Cluster aus einem primären Cluster erstellen, damit Ihr Cluster in verschiedenen Regionen für Lesevorgänge verfügbar ist. Sekundäre Cluster bieten auch Redundanz für Notfallwiederherstellungsszenarien im Falle von regionalen Ausfällen.
Die wichtigsten Konzepte auf dieser Seite sind:
- Primärer Cluster: Ein Lese-/Schreib-Cluster in einer einzelnen Region.
- Sekundäre Cluster: Ein sekundärer Cluster ist ein schreibgeschützter Cluster, dessen Daten asynchron aus dem primären Cluster repliziert werden. Informationen zum Hochstufen und Trennen von sekundären Instanzen finden Sie in den Abschnitten Switchover und Detach unter Mit regionenübergreifender Replikation arbeiten.
- Replikator-Knoten: Ein Knoten im Shard des primären Clusters, der auf einen Follower-Knoten im sekundären Cluster repliziert wird. Jeder primäre Knoten oder Replikatknoten im Shard kann die Rolle eines Replikators übernehmen.
- Follower-Knoten: Knoten im sekundären Cluster, die von einem Replikator-Knoten im primären Cluster repliziert werden. Nur primäre Knoten im sekundären Cluster können die Rolle eines Followers haben.
- Shard-Anzahl und Slot-Zuweisung: Primäre und sekundäre Cluster haben dieselbe Anzahl von Shards und Slotzuweisungen.
Vorteile
Die regionsübergreifende Replikation in Memorystore for Redis Cluster bietet unter anderem folgende Vorteile:
- Notfallwiederherstellung: Wenn die Region des primären Clusters nicht mehr verfügbar ist, können Sie zu einem sekundären Cluster in einer anderen Region wechseln oder ihn trennen, um Lese- und Schreibanfragen zu verarbeiten. Die sekundären Cluster sind immer bereit, Leseanfragen zu verarbeiten, ohne dass ein Switchover- oder Detach-Befehl ausgegeben werden muss.
- Geografisch verteilte Daten: Durch die geografische Verteilung der Daten werden die Daten näher an Sie herangebracht und die Leselatenz verringert.
- Geografisches Load-Balancing für Lesetraffic. Bei langsamen oder überlasteten Verbindungen in einer Region können Sie den Traffic in eine andere Region weiterleiten.
Funktionsweise
In diesem Abschnitt werden wichtige Verhaltensweisen bei der regionenübergreifenden Replikation erläutert, die Sie kennen sollten.
- Instanzkapazität skalieren: Wenn Sie die Instanzkapazität des primären Clusters skalieren, werden sekundäre Cluster automatisch entsprechend skaliert.
- Anzahl der Replikate skalieren: Sie können die Anzahl der Replikate für primäre und sekundäre Cluster unabhängig voneinander an die Anforderungen Ihrer Arbeitslast anpassen. Aktualisierungen der Anzahl der Replikate sind nur lokal und werden nicht auf andere Cluster in der Sammlung von Clustern für die regionsübergreifende Replikation übertragen.
- Umschaltung bei einem potenziellen Ausfall: Sie können einen Wechsel ausführen, um einen sekundären Cluster hochzustufen, auch wenn der primäre Cluster aufgrund eines Ausfalls nicht verfügbar ist. In diesem Szenario wird der nicht verfügbare primäre Cluster schließlich zu einem sekundären Cluster, wenn der Ausfall behoben ist.
- Onlineerstellung des sekundären Clusters: Wenn Sie einem primären Cluster einen sekundären Cluster hinzufügen, bleibt der primäre Cluster online. Die primäre Instanz verarbeitet Anfragen, während die sekundäre Instanz erstellt wird und Daten repliziert.
- Sekundäre Cluster: Sie können bis zu zwei sekundäre Bereiche haben. Sie können sich in allen verfügbaren Regionen befinden. Sie können sich auch alle in verschiedenen Regionen befinden. Ein vorhandener Cluster kann nicht zu einem sekundären Cluster gemacht werden. Nur neue Cluster können einem vorhandenen Cluster als sekundäre Cluster hinzugefügt werden.
- Synchronisierte Einstellungen: Die meisten Einstellungen werden automatisch zwischen primären und sekundären Clustern synchronisiert. Weitere Informationen zu diesen Einstellungen finden Sie unter Clustereinstellungen.
- Preise Kunden, die die regionenübergreifende Replikation verwenden, werden für alle sekundären Cluster in Rechnung gestellt, die für die regionenübergreifende Replikation bereitgestellt werden. Für jeden Knoten und jedes Replikat, das im sekundären Cluster bereitgestellt wird, werden Kunden wie bei jedem anderen primären Cluster in Rechnung gestellt. Außerdem fallen für Kunden Netzwerkgebühren für die Datenübertragung zwischen Clustern in verschiedenen Regionen an.
- Wartungsupdate: Um die Kompatibilität mit der regionenübergreifenden Replikation zu gewährleisten, kann es sein, dass Ihr primärer Cluster während der Erstellung des sekundären Clusters ein Wartungsupdate erhält, wenn darauf noch nicht die erforderliche Softwareversion ausgeführt wird. Bei der Erstellung des sekundären Clusters kann es durch diesen Aktualisierungsprozess zu zusätzlicher Latenz kommen. Weitere Informationen zur Wartung finden Sie unter Wartung.
Regionsübergreifende Replikation nutzen
Die Verwendung der regionenübergreifenden Replikation mit Memorystore for Redis Cluster umfasst die folgenden Aufgaben:
- Sekundären Cluster erstellen Sie erstellen einen sekundären Cluster, dessen Daten kontinuierlich aus Ihrem primären Cluster repliziert werden.
- Sekundären Cluster ansehen: Sie können Informationen zu einem sekundären Cluster aufrufen, einschließlich des Namens des primären Clusters und des anderen sekundären Clusters in der Replikationsgruppe.
Sekundäre Cluster trennen: Wenn Sie sekundäre Cluster trennen, werden sie vom primären Cluster abgekoppelt. Dadurch werden sie zu voll funktionsfähigen, unabhängigen Clustern, die sowohl Lese- als auch Schreibvorgänge zulassen. Nach dem Trennen replizieren die sekundären Cluster keine Daten mehr aus dem primären Cluster, mit dem sie zuvor verknüpft waren. Sowohl der ursprüngliche primäre Cluster als auch die neu getrennten Cluster (ehemalige sekundäre Cluster) fungieren als unabhängige Cluster ohne Beziehung zueinander.
Es gibt zwei Hauptszenarien für das Trennen sekundärer Cluster:
- Regionale Migration: Sie führen eine geplante Migration der Memorystore for Redis Cluster-Ressourcen von ihrer primären Region in eine andere Region aus.
- Notfallwiederherstellung: Im Falle eines Ausfalls der Ressourcen in der primären Region können Sie die Memorystore for Redis Cluster-Ressourcen in einer sekundären Region schnell aktivieren. Wenn die sekundären Cluster nicht vollständig mit dem primären Cluster synchronisiert wurden, kann es zu Datenverlusten kommen.
Cluster wechseln: Mit einem Switchover können Sie die Rollen Ihres primären und sekundären Clusters umkehren. Sie können einen Switchover ausführen, um Ihre Notfallwiederherstellungseinrichtung zu testen, während eines echten Notfallwiederherstellungsszenarios oder um eine Migration Ihrer Arbeitslast durchzuführen. Wenn Sie den Switchover abschließen, wird die Richtung der Replikation umgekehrt. Der alte sekundäre Cluster kann sowohl Lese- als auch Schreibvorgänge akzeptieren, während der alte primäre Cluster auf schreibgeschützt umgestellt wird.
Beispiel für die Architektur der regionsübergreifenden Replikation
Das folgende Diagramm zeigt einen primären Cluster in der Region us-east1 mit sekundären Clustern in us-west1 und asia-east1. Die Replikation erfolgt immer von us-east1 in die anderen Regionen. Im folgenden Diagramm ist zwar die gleiche Anzahl von Replikaten in allen Regionen zu sehen, aber mit der regionenübergreifenden Replikation können Sie die Anzahl der Replikate je nach Bedarf variieren.
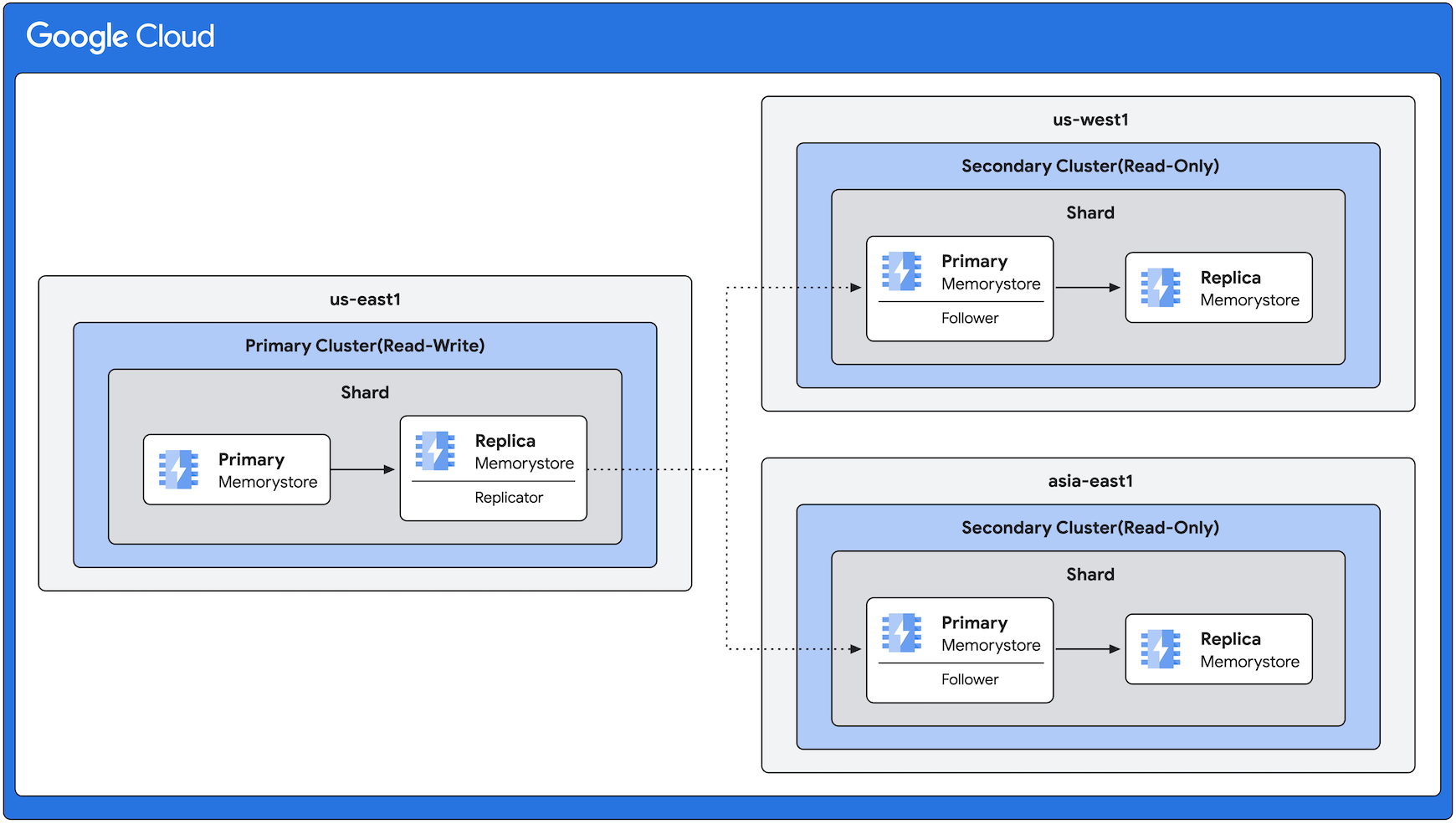
Clustereinstellungen
In diesem Abschnitt wird erläutert, welche Einstellungen für primäre und sekundäre Cluster, die die regionenübergreifende Replikation verwenden, erforderlich sind, kopiert oder überschrieben werden. Außerdem wird erläutert, welche Einstellungen auf dem primären Gerät und welche lokal konfiguriert werden.
Erforderliche Parameter zum Erstellen eines sekundären Clusters
- Google Cloud-Projekt Dies ist das Projekt, in dem sich Ihr primärer Cluster befindet und in dem auch der sekundäre Cluster erstellt wird.
- Region Dies ist die Region, in der Sie den sekundären Cluster platzieren möchten.
- Private Service Connect-Konfiguration: Dies ist die Netzwerkeinrichtung für Ihren Cluster.
- Primärer Cluster: Beim Erstellen des sekundären Clusters müssen Sie einen primären Cluster für ihn angeben. Jeder Cluster außer einem sekundären Cluster kann als primärer Cluster verwendet werden. Wenn Sie keinen primären Cluster haben, sollten Sie ihn zuerst erstellen.
Einstellungen, die beim Erstellen der Instanz von der primären Instanz kopiert wurden
Beim Erstellen eines sekundären Clusters werden die folgenden Einstellungen aus dem primären Cluster kopiert:
- Shard-Anzahl
- IAM-Authentifizierungsmodus
- Modus für die Verschlüsselung während der Übertragung
- Konfigurationen der Redis-Engine
- Redis-Engine-Version
- Knotentyp
- Persistenzmodus
Überschreiben während der Instanzerstellung zulässig
Mit den folgenden Einstellungen kann der Standardwert bei der Instanzerstellung überschrieben werden.
- Konfiguration der Zonenverteilung
- Anzahl der Replikate
- Wartungsfenster
- Löschschutz
- Automatische Sicherungen
Clustereinstellungen aktualisieren
Beim Aktualisieren von Clustereinstellungen können einige Einstellungen nur im primären Cluster geändert werden. Die Änderungen werden dann automatisch mit den sekundären Clustern synchronisiert. Andere Einstellungen können unabhängig voneinander in primären und sekundären Clustern geändert werden. Sie werden nur lokal angewendet und nicht mit den anderen Clustern synchronisiert.
Auf primär festlegen
Die folgenden Einstellungen müssen auf der primären Instanz geändert werden. Die Aktualisierung wird mit der sekundären Instanz synchronisiert:
Lokal eingerichtet
Sie konfigurieren diese Einstellungen lokal:
Best Practices für die Umstellung
Wenn Sie einen Wechsel durchführen, empfehlen wir, die Anleitung in diesem Abschnitt zu befolgen, damit Ihre Anwendung Schreibvorgänge verfolgen und an den entsprechenden Cluster senden kann.
- Beenden Sie das Schreiben von Daten in den primären Cluster durch Ihre Anwendung.
Bestimmen Sie den sekundären Cluster, der hochgestuft werden soll (falls mehrere sekundäre Cluster zur Auswahl stehen). Die folgenden Faktoren können Ihnen bei der Entscheidung helfen, welche sekundäre Aktion Sie bewerben sollten:
Die Nähe Ihrer Anwendung zum Cluster. Das kann sich auf die Schreiblatenz auswirken.
Der Cluster, der in Bezug auf Daten am aktuellsten ist.
Der Cluster, der den primären Clustern in Bezug auf die Einstellungen am nächsten ist.
Führen Sie einen Switchover für den sekundären Cluster durch.
Warten Sie, bis der Switchover-Vorgang abgeschlossen ist.
Aktualisieren Sie die Anwendung, damit die Schreibvorgänge an den neu hochgestuften Cluster gesendet werden, den Sie in Schritt 2 ausgewählt haben.