概览
Looker 会使用汇总感知逻辑在数据库中查找最小、最有效的可用表来运行查询,同时仍保持准确性。
对于数据库中的超大型表,Looker 开发者可以创建较小的数据汇总表,按各种属性组合进行分组。汇总表充当汇总表或摘要表,Looker 可以在查询时尽可能使用这些表,而不是使用原始的大型表。如果以战略性方式实现,聚合感知功能可将平均查询速度提高几个数量级。
例如,您可能有一个 PB 级的数据表,其中包含您网站上发生的每笔订单对应的一行数据。您可以根据此数据库创建包含每日销售总额的汇总表。如果您的网站每天收到 1,000 份订单,那么您的每日汇总表将比原始表少 999 行,以表示每一天。您可以创建另一个包含每月销售总额的汇总表,这样效率会更高。这样一来,如果用户运行每日或每周销售额查询,Looker 将使用每日销售总额表。如果用户运行有关年销售额的查询,而您没有年汇总表,Looker 将使用次优选择,在本例中即为月销售额汇总表。
Looker 会尽可能使用最小的汇总表来回答用户的问题。例如:
- 对于有关每月总销售额的查询,Looker 会使用基于每月销售额的汇总表 (
sales_monthly_aggregate_table)。 - 对于有关每天每笔销售交易总额的查询,没有相应粒度的汇总表,因此 Looker 会从原始数据库表 (
orders_database) 获取查询结果。(不过,如果用户经常运行此类查询,您可以为其创建汇总表。) - 对于有关每周销售额的查询,由于没有每周汇总表,因此 Looker 会使用次优选择,即基于每日销售额 (
sales_daily_aggregate_table) 的汇总表。
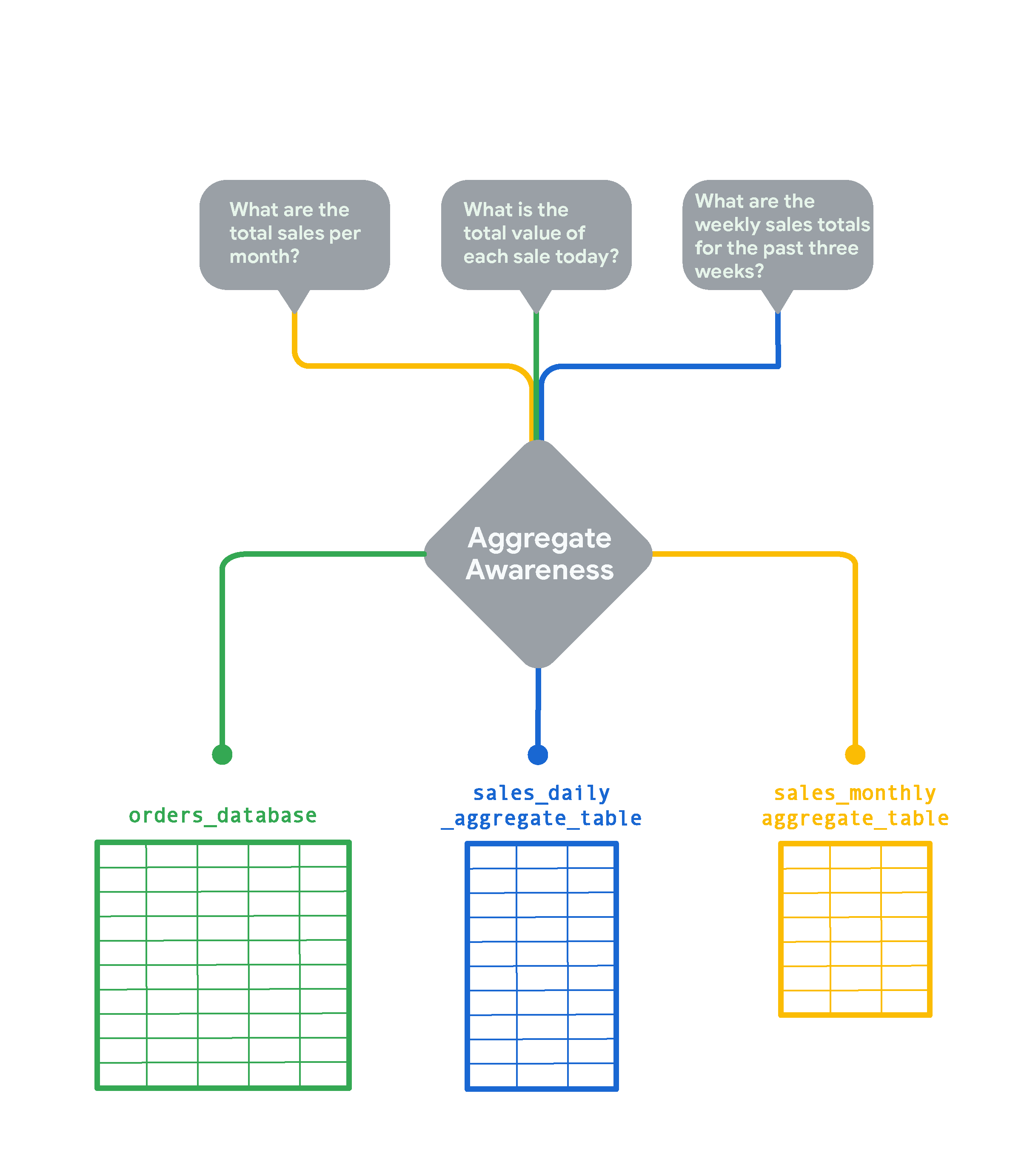
Looker 将使用汇总感知逻辑,查询尽可能小的汇总表来回答用户的问题。只有在查询需要比汇总表所能提供的更精细的粒度时,才会使用原始表。
无需在单独的探索中联接或添加汇总表。Looker 会动态调整探索查询的 FROM 子句,以访问最适合该查询的汇总表。这意味着,您的下钻会得到保留,并且可以整合探索。借助汇总感知功能,一个探索可以自动利用汇总表,但仍可在需要时深入分析精细数据。
您还可以利用汇总表大幅提升信息中心的性能,尤其是在处理查询庞大数据集的图块时。如需了解详情,请参阅 aggregate_table 参数文档页面上的从信息中心获取汇总表 LookML 部分。
向项目添加汇总表
Looker 开发者可以创建战略性汇总表,从而最大限度地减少数据库中大型表所需的查询数量。必须将汇总表持久化到数据库,以便它们可用于汇总感知。因此,汇总表是一种永久性派生表 (PDT)。
汇总表是使用 LookML 项目中 explore 参数下的 aggregate_table 参数定义的。
以下是 LookML 中包含汇总表的 explore 示例:
explore: orders {
label: "Sales Totals"
join: order_items {
sql_on: ${orders.id} = ${order_items.id} ;;
}
aggregate_table: sales_monthly {
materialization: {
datagroup_trigger: orders_datagroup
}
query: {
dimensions: [created_month]
measures: [order_items.total_sales]
}
}
# other explore parameters
}
如需创建汇总表,您可以从头开始编写 LookML,也可以从探索或从信息中心获取汇总表 LookML。如需详细了解 aggregate_table 参数及其子参数,请参阅 aggregate_table 参数文档页面。
设计汇总表
若要使探索查询使用汇总表,汇总表必须能够为探索查询提供准确的数据。如果满足以下所有条件,Looker 就可以使用汇总表来执行探索查询:
- 探索查询的字段是汇总表字段的子集(请参阅本页面的字段因素部分)。或者,对于时间范围,探索查询的时间范围可以从汇总表中的时间范围派生出来(请参阅此页面上的时间范围因素部分)。
- 探索查询包含汇总感知功能支持的衡量类型(请参阅本页上的衡量类型因素部分),或者探索查询具有完全匹配的汇总表(请参阅本页上的创建与探索查询完全匹配的汇总表部分)。
- 探索查询的时区与汇总表使用的时区一致(请参阅本页面上的时区因素部分)。
- 探索查询的过滤条件引用了汇总表中可作为维度的字段,或者探索查询的每个过滤条件都与汇总表中的过滤条件相匹配(请参阅本页面的过滤条件因素部分)。
确保汇总表能够为探索查询提供准确数据的一种方法是,创建一个与探索查询完全匹配的汇总表。如需了解详情,请参阅本页中的创建与探索查询完全匹配的汇总表部分。
实地因素
若要将汇总表用于探索查询,该汇总表必须包含探索查询所需的所有维度和度量,包括探索查询中用于过滤条件的字段。如果探索查询包含汇总表中没有的维度或度量,Looker 将无法使用汇总表,而是使用基表。
例如,如果查询按维度 A 和 B 分组,按指标 C 汇总,并按维度 D 过滤,则汇总表必须至少包含 A、B 和 D 作为维度,以及 C 作为指标。
汇总表也可以包含其他字段,但必须至少包含探索查询字段,才能用于优化。时间范围维度是一个例外,因为可以从更精细的时间范围推导出更粗略的时间范围。
考虑到这些字段,汇总表仅适用于定义它的探索。在某个探索下定义的汇总表不会用于对其他探索的查询。
时间范围因素
Looker 的汇总感知逻辑能够从一个时间段推导出另一个时间段。只要汇总表的时间范围粒度比探索查询的粒度更精细(或相同),就可以将汇总表用于查询。例如,基于每日数据的汇总表可用于需要其他时间范围的探索查询,例如每日、每月和每年数据的查询,甚至每月第几天、每年第几天和每年第几周数据的查询。但由于汇总表的数据粒度不够精细,无法满足探索查询的要求,因此无法将年度汇总表用于需要小时级数据的探索查询。
时间范围子集也是如此。例如,如果您有一个过滤了过去 3 个月数据的汇总表,而用户查询的数据过滤条件为过去 2 个月,Looker 将能够使用该汇总表来处理相应查询。
此外,对于包含时间范围过滤条件的查询,也适用相同的逻辑:只要汇总表的时间范围粒度比探索查询中使用的时间范围过滤条件更精细(或相同),就可以将汇总表用于包含时间范围过滤条件的查询。例如,具有“每日”时间范围维度的汇总表可用于按天、周或月进行过滤的探索查询。
衡量类型因素
若要使探索查询使用汇总表,汇总表中的度量必须能够为探索查询提供准确的数据。
因此,系统仅支持某些类型的指标,如下一部分中所述:
如果探索查询使用任何其他类型的度量,Looker 将使用原始表(而非汇总表)来返回结果。唯一的例外情况是,探索查询与汇总表查询完全匹配,如创建与探索查询完全匹配的汇总表部分中所述。
否则,Looker 将使用原始表(而非汇总表)来返回结果。
具有支持的衡量类型的衡量
汇总认知度可用于使用以下衡量类型的指标的探索查询:
若要将汇总表用于探索查询,Looker 必须能够对汇总表的度量进行操作,以便在探索查询中提供准确的数据。例如,具有 type: sum 的指标可用于实现汇总感知,因为您可以对多个总和求和:将每周总和的汇总表相加即可得到准确的每月总和。同样,也可以使用具有 type: max 的指标,因为每日最大值的汇总表可用于查找准确的每周最大值。
对于具有 type: average 的度量,Looker 支持汇总感知,因为 Looker 会使用总和和计数数据从汇总表中准确得出平均值。
使用 SQL 表达式定义的度量
汇总认知度还可以与在 sql 参数中使用表达式定义的指标搭配使用。如果使用 SQL 表达式定义,系统还支持以下衡量指标类型:
对于定义为其他指标组合的指标,系统支持汇总感知功能,例如以下示例:
measure: total_revenue_in_dollars {
type: number
sql: ${total_revenue_in_dollars} - ${inventory_item.total_cost_in_dollars} ;;
}
对于在 sql 参数中定义了计算的度量,系统也支持汇总感知,例如以下度量:
measure: wholesale_value {
type: number
sql: (${order_items.total_sale_price} * 0.60) ;;
}
对于在 sql 参数中定义了 MIN、MAX 和 COUNT 操作的指标,系统支持聚合感知功能,例如以下指标:
measure: most_recent_order_date {
type: date
sql: MAX(${users.created_at_raw})
}
引用 LookML 字段的度量
当 sql 表达式用于度量时,汇总感知支持以下类型的字段引用:
- 使用
${view_name.field_name}格式的引用,表示其他视图中的字段 - 使用
${field_name}格式的引用,表示同一视图中的字段
对于使用 ${TABLE}.column_name 格式(表示表中的列)定义的指标,不支持汇总感知。(如需大致了解如何在 LookML 中使用引用,请参阅纳入 SQL 并引用 LookML 对象文档页面。)
例如,使用此 sql 参数定义的指标在汇总表中不受支持,因为它使用 ${TABLE}.column_name 格式:
measure: wholesale_value {
type: number
sql: (${TABLE}.total_sale_price * 0.60) ;;
}
如果您想在汇总表中包含此度量,可以改为创建以 ${TABLE}.column_name 格式定义的维度,然后创建引用该维度的度量,如下所示:
dimension: total_sale_price {
sql: (${TABLE}.total_sale_price) ;;
}
measure: wholesale_value {
type: number
sql: (${total_sale_price} * 0.60) ;;
}
现在,您可以在汇总表中使用 wholesale_value 指标了。
用于近似计算不同值的度量
一般来说,汇总感知不支持去重计数,因为如果您尝试汇总去重计数,则无法获得准确的数据。例如,如果您要统计网站上的不同用户数,那么可能有一位用户在相隔三周的时间内两次访问了该网站。如果您尝试应用每周汇总表来获取网站上每月不重复用户的数量,那么在每月不重复用户数量查询中,该用户会被统计两次,导致数据不正确。
一种解决方法是创建一个与探索查询完全匹配的汇总表,如本页面的创建与探索查询完全匹配的汇总表部分中所述。当探索查询与汇总表查询相同时,去重计数指标确实会提供准确的数据,因此可用于汇总感知。
另一种方法是使用近似值来表示不同值的数量。对于支持 HyperLogLog 草图的方言,Looker 可以利用 HyperLogLog 算法来近似计算汇总表的不同计数。
众所周知,HyperLogLog 算法的误差约为 2%。allow_approximate_optimization: yes 参数要求 Looker 开发者确认可以使用近似数据来衡量指标,以便可以根据汇总表大致计算指标。
如需了解详情,请参阅 allow_approximate_optimization 参数文档页面,并查看支持使用 HyperLogLog 统计不同值的方言列表。
时区因素
在许多情况下,数据库管理员会使用 UTC 作为数据库的时区。不过,许多用户可能不在 UTC 时区。Looker 提供了多种时区转换选项,以便用户能够以自己的时区获取查询结果:
- 查询时区:此设置适用于数据库连接上的所有查询。如果所有用户都位于同一时区,您可以设置单个查询时区,以便将所有查询从数据库时区转换为查询时区。
- 用户自选时区:可为用户单独分配和选择时区。在这种情况下,查询会从数据库时区转换为各个用户的时区。
如需详细了解这些选项,请参阅使用时区设置文档页面。
这些概念对于了解汇总感知非常重要,因为为了让汇总表可用于包含日期维度或日期过滤条件的查询,汇总表上的时区必须与原始查询所用的时区设置相匹配。
如果未指定 timezone 值,汇总表会使用数据库时区。如果存在以下任一情况,数据库连接也会使用数据库时区:
如果满足上述任一条件,您可以省略汇总表的 timezone 参数。
否则,应定义汇总表的时区以匹配可能的查询,以便更可能使用汇总表:
- 如果您的数据库连接使用单个查询时区,则应将汇总表的
timezone值与查询时区值相匹配。 - 如果您的数据库连接使用特定于用户的时区,您应创建相同的汇总表,但每个表的
timezone值都不同,以匹配用户的可能时区。
过滤因素
在汇总表中添加过滤条件时,请务必谨慎。对汇总表应用过滤条件可能会将结果范围缩小到汇总表无法使用的程度。例如,假设您创建了一个用于统计每日订单数量的汇总表,并且该汇总表仅过滤来自澳大利亚的太阳镜订单。如果用户运行探索查询来获取全球太阳镜的每日订单数量,Looker 将无法使用该探索查询的汇总表,因为该汇总表仅包含澳大利亚的数据。汇总表过滤的数据过于狭窄,无法供“探索”查询使用。
此外,还要注意 Looker 开发者可能已在探索中内置的过滤条件,例如:
access_filters:应用特定于用户的数据限制。always_filter:要求用户在探索查询中添加一组特定的过滤条件。用户可以更改查询的默认过滤条件值,但无法完全移除过滤条件。conditionally_filter:定义一组默认过滤条件,如果用户应用了“探索”中定义的第二个列表中的至少一个过滤条件,则可以替换这些默认过滤条件。
这些过滤条件类型基于特定字段。如果您的探索包含这些过滤条件,您必须在 aggregate_table 的 dimensions 参数中添加这些过滤条件的字段。
例如,以下探索包含基于 orders.region 字段的访问权限过滤条件:
explore: orders {
access_filter: {
field: orders.region
user_attribute: region
}
}
如需创建将用于此探索的汇总表,该汇总表必须包含访问权限过滤条件所依据的字段。在下一个示例中,访问过滤条件基于字段 orders.region,并且此字段也作为维度包含在汇总表中:
explore: orders {
access_filter: {
field: orders.region # <-- orders.region field
user_attribute: region
}
aggregate_table: sales_monthly {
materialization: {
datagroup_trigger: orders_datagroup
}
query: {
dimensions: [orders.created_day, orders.region] # <-- orders.region field
measures: [orders.total_sales]
timezone: America/Los_Angeles
}
}
}
由于汇总表查询包含 orders.region 维度,因此 Looker 可以动态过滤汇总表中的数据,以匹配探索查询中的过滤条件。因此,即使探索具有访问权限过滤条件,Looker 仍可将汇总表用于探索的查询。
这也适用于使用配置了 bind_filters 的原生派生表的探索查询。bind_filters 参数会将探索查询中的指定过滤条件传递到原生派生表子查询中。对于汇总感知,如果您的探索查询需要使用 bind_filters 的原生派生表,则只有当探索查询中原生派生表的 bind_filters 参数中使用的所有字段在探索查询中和在汇总表中具有完全相同的过滤条件值时,探索查询才能使用汇总表。
创建与探索查询完全匹配的汇总表
确保聚合表可用于探索查询的一种方法是,创建一个与探索查询完全匹配的聚合表。如果探索查询和汇总表都使用相同的度量、维度、过滤条件、时区和其他参数,那么根据定义,汇总表的结果将适用于探索查询。如果汇总表与探索查询完全匹配,Looker 便能够使用包含任何类型度量的汇总表。
您可以使用探索的齿轮菜单中的获取 LookML 选项,基于探索创建汇总表。您还可以使用信息中心的齿轮状菜单中的 Get LookML 选项,为信息中心中的所有图块创建完全匹配。
确定查询使用哪个汇总表
具有 see_sql 权限的用户可以使用探索的 SQL 标签页中的注释来查看查询将使用哪个汇总表。SQL 标签页注释也会显示在开发模式中,因此开发者可以测试新的汇总表,了解 Looker 如何使用这些表,然后再将新表推送到生产环境。
例如,根据前面显示的每月汇总表示例,您可以前往“探索”并运行查询,以获取年度销售总额。然后,您可以点击 SQL 标签页,查看 Looker 创建的查询的详细信息。如果您处于开发模式,Looker 会显示注释来指明它用于查询的汇总表。
从 SQL 标签页上的以下注释中,我们可以看到 Looker 正在为此查询使用 sales_monthly 汇总表,以及有关为何未将其他汇总表用于该查询的信息:
-- use existing orders::sales_monthly in sandbox_scratch.LR$LB4151619827209021_orders$sales_monthly
-- Did not use orders::sales_weekly; it does not include the following fields in the query: orders.created_month
-- Did not use orders::sales_daily; orders::sales_monthly was a better fit for optimization.
-- Did not use orders::sales_last_3_days; contained filters not in the query: orders.created_date
如需了解您可能会在 SQL 标签页中看到的评论以及有关如何解决这些评论的建议,请参阅本页面的问题排查部分。
计算节省估算值,以便了解总体情况
如果您的数据库连接支持费用估算,并且查询可以使用汇总表,则“探索”窗口会显示使用汇总表而不是直接查询数据库所节省的计算量。在运行查询之前,探索中的运行按钮旁边会显示汇总感知节省。
在运行查询之前,如果您想查看将使用哪个汇总表来执行查询,可以点击 SQL 标签页,如本帮助页面中的确定将使用哪个汇总表来执行查询部分所述。
查询运行后,“探索”窗口会在运行按钮旁边显示用于回答查询的汇总表。
对于已启用费用估算的数据库连接,系统会显示汇总的感知节省费用。如需了解详情,请参阅“在 Looker 中探索数据” 文档页面。
Looker 将新数据与汇总表进行并集运算
对于具有时间过滤条件的汇总表,Looker 可以将新数据并入汇总表中。您可能有一个包含过去三天数据的汇总表,但该汇总表可能是昨天构建的。汇总表中会缺少今天的信息,因此您不应使用它来查询最近的每日信息。
不过,Looker 仍然可以使用该汇总表中的数据来执行查询,因为 Looker 会针对最新数据运行查询,然后将这些结果与汇总表中的结果进行并集运算。
在以下情况下,Looker 可以将新数据与汇总表的数据进行并集运算:
- 汇总表具有时间过滤条件。
- 汇总表包含一个基于与时间过滤条件相同的时间字段的维度。
例如,以下汇总表具有基于 orders.created_date 字段的维度,并且具有基于同一字段的时间过滤条件 ("3 days"):
aggregate_table: sales_last_3_days {
query: {
dimensions: [orders.created_date]
measures: [order_items.total_sales]
filters: [orders.created_date: "3 days"] # <-- time filter
timezone: America/Los_Angeles
}
...
}
如果此汇总表是昨天构建的,Looker 将检索尚未包含在汇总表中的最新数据,然后将新结果与汇总表中的结果进行并集运算。这意味着,您的用户将获得最新数据,同时仍能通过汇总感知优化效果。
如果您处于开发模式,可以点击探索的 SQL 标签页,查看 Looker 用于查询的汇总表,以及 Looker 用于引入未包含在汇总表中的新数据的 UNION 语句。
汇总表必须持久存在
为了让系统能够感知汇总,您的汇总表必须持久保留在数据库中。持久性策略在汇总表的 materialization 参数中指定。由于汇总表是一种永久性派生表 (PDT),因此汇总表与 PDT 具有相同的要求。如需了解详情,请参阅 Looker 中的派生表文档页面。
如果您的 方言支持增量 PDT,您可以在项目中创建增量 PDT。Looker 通过将最新数据附加到表中来构建增量 PDT,而不是重新构建整个表。由于汇总表本身就是一种 PDT,因此您也可以创建增量汇总表。如需详细了解增量 PDT,请参阅增量 PDT 文档页面。如需查看增量汇总表的示例,请参阅 increment_key 参数文档页面。
拥有 develop 权限的用户可以替换持久性设置,并为查询重建所有汇总表,以获取最新数据。如需重新构建查询的表,请从探索操作齿轮菜单中选择重新构建派生表并运行选项。
您必须等待探索查询加载完毕,然后才能使用此选项。
重新构建派生表并运行选项会重新构建查询中引用的所有派生表,以及查询中的表所依赖的任何派生表。这包括汇总表,汇总表本身就是一种永久性派生表。
对于启动重建派生表并运行选项的用户,查询将等待表重建完成后再加载结果。其他用户的查询仍将使用现有表。重建持久性表后,所有用户都将使用重建后的表。
如需详细了解重建派生表并运行选项,请参阅 Looker 中的派生表文档页面。
问题排查
如确定查询使用哪个汇总表部分中所述,如果您处于开发模式,则可以在探索中运行查询,然后点击 SQL 标签页查看有关查询所用汇总表的注释(如果有)。
SQL 标签页还包含有关为什么未将汇总表用于查询的注释(如果适用)。对于未使用的汇总表,注释将以以下内容开头:
Did not use [explore name]::[aggregate table name];
例如,以下注释说明了为什么未将 order_items 探索中定义的 sales_daily 汇总表用于查询:
-- Did not use order_items::sales_daily; query contained the following filters
that were neither included as fields nor exactly matched by filters in the aggregate table:
order_items.created_year.
在这种情况下,查询中的过滤条件阻止了汇总表的使用。
下表列出了一些可能导致无法使用汇总表的其他原因,以及您可以采取的措施来提高汇总表的可用性。
| 不使用汇总表的原因 | 说明和可能的步骤 |
|---|---|
| 探索中没有此类字段。 | 存在 LookML 验证类型错误。这很可能是因为汇总表未正确定义,或者汇总表的 LookML 中存在拼写错误。可能的原因是字段名称不正确等。如需解决此问题,请验证汇总表中的维度和指标是否与探索中的字段名称一致。如需详细了解如何定义汇总表,请参阅 aggregate_table 参数文档页面。 |
| 汇总表不包含查询中的以下字段。 | 若要将汇总表用于探索查询,该汇总表必须包含探索查询所需的所有维度和度量,包括探索查询中用于过滤条件的字段。如果探索查询包含汇总表中没有的维度或度量,Looker 将无法使用汇总表,而是使用基表。如需了解详情,请参阅本页的字段因素部分。时间范围维度是一个例外,因为可以从更精细的时间范围推导出更粗略的时间范围。如需解决此问题,请验证探索查询的字段是否包含在汇总表定义中。 |
| 查询包含以下过滤条件,这些过滤条件既未作为字段包含在内,也未与汇总表中的过滤条件完全匹配。 | “探索”查询中的过滤条件会阻止 Looker 使用汇总表。 如需解决此问题,您可以执行以下任一操作:
|
| 相应查询包含以下无法汇总的指标。 | 查询包含一个或多个不支持汇总感知功能的指标类型,例如去重计数、中位数或百分位数。如需解决此问题,请检查查询中每个度量的类型,并确保其属于支持的度量类型。此外,如果您的探索包含联接,请验证您的度量是否未通过扇出联接转换为不同的度量(对称汇总)。如需了解相关说明,请参阅本页面上的包含联接的探索的对称汇总部分。 |
| 其他汇总表更适合进行优化。 | 查询有多个可行的汇总表,但 Looker 找到了一个更优的汇总表来代替。在这种情况下,您无需执行任何操作。 |
Looker 未进行任何分组(因为存在 primary_key 或 cancel_grouping_fields 参数),因此无法汇总查询。 |
查询引用的维度使其无法包含 GROUP BY 子句,因此 Looker 无法使用任何汇总表来执行该查询。
如需解决此问题,请验证视图的 primary_key 参数和探索的 cancel_grouping_fields 参数是否已正确设置。 |
| 汇总表中包含查询中没有的过滤条件。 | 汇总表具有查询中没有的非时间过滤条件。如需解决此问题,您可以从汇总表中移除过滤条件。如需了解详情,请参阅本页的过滤系数部分。 |
某个字段在探索查询中被定义为仅限过滤条件的字段,但列在汇总表的 dimensions 参数中。 |
汇总表的 dimensions 参数列出了一个仅在探索查询中定义为 filter 字段的字段。如需解决此问题,请从汇总表的 dimensions 列表中移除相应字段。如果汇总表需要此字段,请将其添加到汇总表查询中的 filters 列表中。 |
| 优化器无法确定未使用汇总表的原因。 | 此注释专用于特殊情况。如果您经常使用的探索查询出现此情况,可以创建一个与该探索查询完全匹配的汇总表。您可以从探索中获取汇总表 LookML,如 aggregate_table 参数页面中所述。 |
注意事项
具有联接的探索的对称聚合
需要注意的一点是,在联接多个数据库表的探索中,Looker 可以将 SUM、COUNT 和 AVERAGE 类型的度量分别呈现为 SUM DISTINCT、COUNT DISTINCT 和 AVERAGE DISTINCT。Looker 这样做是为了避免扇出误算。例如,count 指标会呈现为 count_distinct 指标类型。这是为了避免联接的扇出误算,也是 Looker 对称聚合功能的一部分。如需了解 Looker 的此功能,请参阅有关对称汇总的最佳实践页面。
对称聚合功能可防止误算,但有时也会导致无法使用聚合表,因此请务必了解。
对于聚合感知功能支持的衡量类型,这适用于 sum、count 和 average。如果满足以下条件,Looker 会将这些类型的度量呈现为 DISTINCT:
如需了解这些类型的联接,请参阅 relationship 参数文档页面。
如果您发现汇总表未被使用,原因就在于此,那么您可以创建一个与探索查询完全匹配的汇总表,以便在包含联接的探索中使用这些衡量类型。如需了解详情,请参阅此页面上的创建与探索查询完全匹配的汇总表部分。
此外,如果您使用的 SQL 方言支持 HyperLogLog 概略图,则可以向指标添加 allow_approximate_optimization: yes 参数。如果使用 allow_approximate_optimization: yes 定义了计数度量,即使该度量呈现为去重计数,Looker 也可以将其用于汇总认知度。
如需了解详情,请参阅 allow_approximate_optimization 参数文档页面,并查看哪些 SQL 方言支持 HyperLogLog 概略图的列表。
针对汇总感知功能的方言支持
能否使用汇总感知功能取决于 Looker 连接所用的数据库方言。在最新版 Looker 中,以下方言支持汇总感知:
| 方言 | 是否支持? |
|---|---|
| Actian Avalanche | 是 |
| Amazon Athena | 是 |
| Amazon Aurora MySQL | 是 |
| Amazon Redshift | 是 |
| Amazon Redshift 2.1+ | 是 |
| Amazon Redshift Serverless 2.1+ | 是 |
| Apache Druid | 否 |
| Apache Druid 0.13+ | 否 |
| Apache Druid 0.18+ | 否 |
| Apache Hive 2.3+ | 是 |
| Apache Hive 3.1.2+ | 是 |
| Apache Spark 3+ | 是 |
| ClickHouse | 否 |
| Cloudera Impala 3.1+ | 是 |
| Cloudera Impala 3.1+ with Native Driver | 是 |
| Cloudera Impala with Native Driver | 是 |
| DataVirtuality | 否 |
| Databricks | 是 |
| Denodo 7 | 否 |
| Denodo 8 & 9 | 否 |
| Dremio | 否 |
| Dremio 11+ | 否 |
| Exasol | 是 |
| Google BigQuery Legacy SQL | 是 |
| Google BigQuery Standard SQL | 是 |
| Google Cloud PostgreSQL | 是 |
| Google Cloud SQL | 否 |
| Google Spanner | 否 |
| Greenplum | 是 |
| HyperSQL | 否 |
| IBM Netezza | 是 |
| MariaDB | 是 |
| Microsoft Azure PostgreSQL | 是 |
| Microsoft Azure SQL Database | 是 |
| Microsoft Azure Synapse Analytics | 是 |
| Microsoft SQL Server 2008+ | 是 |
| Microsoft SQL Server 2012+ | 是 |
| Microsoft SQL Server 2016 | 是 |
| Microsoft SQL Server 2017+ | 是 |
| MongoBI | 否 |
| MySQL | 是 |
| MySQL 8.0.12+ | 是 |
| Oracle | 是 |
| Oracle ADWC | 是 |
| PostgreSQL 9.5+ | 是 |
| PostgreSQL pre-9.5 | 是 |
| PrestoDB | 是 |
| PrestoSQL | 是 |
| SAP HANA | 是 |
| SAP HANA 2+ | 是 |
| SingleStore | 是 |
| SingleStore 7+ | 是 |
| Snowflake | 是 |
| Teradata | 是 |
| Trino | 是 |
| Vector | 是 |
| Vertica | 是 |
对增量构建汇总表的方言支持
为了让 Looker 支持 Looker 项目中的增量汇总表,您的数据库方言也必须支持增量汇总表。下表显示了在最新版 Looker 中哪些方言支持增量构建 PDT:
| 方言 | 是否支持? |
|---|---|
| Actian Avalanche | 否 |
| Amazon Athena | 否 |
| Amazon Aurora MySQL | 否 |
| Amazon Redshift | 是 |
| Amazon Redshift 2.1+ | 是 |
| Amazon Redshift Serverless 2.1+ | 是 |
| Apache Druid | 否 |
| Apache Druid 0.13+ | 否 |
| Apache Druid 0.18+ | 否 |
| Apache Hive 2.3+ | 否 |
| Apache Hive 3.1.2+ | 否 |
| Apache Spark 3+ | 否 |
| ClickHouse | 否 |
| Cloudera Impala 3.1+ | 否 |
| Cloudera Impala 3.1+ with Native Driver | 否 |
| Cloudera Impala with Native Driver | 否 |
| DataVirtuality | 否 |
| Databricks | 是 |
| Denodo 7 | 否 |
| Denodo 8 & 9 | 否 |
| Dremio | 否 |
| Dremio 11+ | 否 |
| Exasol | 否 |
| Google BigQuery Legacy SQL | 否 |
| Google BigQuery Standard SQL | 是 |
| Google Cloud PostgreSQL | 是 |
| Google Cloud SQL | 否 |
| Google Spanner | 否 |
| Greenplum | 是 |
| HyperSQL | 否 |
| IBM Netezza | 否 |
| MariaDB | 否 |
| Microsoft Azure PostgreSQL | 是 |
| Microsoft Azure SQL Database | 否 |
| Microsoft Azure Synapse Analytics | 是 |
| Microsoft SQL Server 2008+ | 否 |
| Microsoft SQL Server 2012+ | 否 |
| Microsoft SQL Server 2016 | 否 |
| Microsoft SQL Server 2017+ | 否 |
| MongoBI | 否 |
| MySQL | 是 |
| MySQL 8.0.12+ | 是 |
| Oracle | 否 |
| Oracle ADWC | 否 |
| PostgreSQL 9.5+ | 是 |
| PostgreSQL pre-9.5 | 是 |
| PrestoDB | 否 |
| PrestoSQL | 否 |
| SAP HANA | 否 |
| SAP HANA 2+ | 否 |
| SingleStore | 否 |
| SingleStore 7+ | 否 |
| Snowflake | 是 |
| Teradata | 否 |
| Trino | 否 |
| Vector | 否 |
| Vertica | 是 |